今天介绍一个Python库 【filestools】 ,是由一位大家很熟悉的大佬开发的。 filestools库目前包含四个工具包,这4个功能我真的超级喜欢,分别是: Ⅰ 树形目录显示; Ⅱ 文本文件差异比较
今天介绍一个Python库【filestools】,是由一位大家很熟悉的大佬开发的。
Ⅰ 树形目录显示; Ⅱ 文本文件差异比较; Ⅲ 图片加水印; Ⅳ 将curl网络请求命令转换成requests库请求代码;
pip install filestools -i https://pypi.org/simple/ -U1. 树形目录显示
# 这样即可将C盘,切换到D盘 C:\Users\Administrator>D: # 使用cd命令,可以切换到指定盘的指定目录 C:\Users\Administrator>cd C:\Users\Administrator\Desktop\python三剑客\加盟店爬虫
如果你的系统,本地python优先级高于系统环境的优先级,直接执行tree命令; 如果你的系统,由于系统环境的优先级高于本地python,除了可以调整环境变量顺序修改优先级外,还可以使用tree2命令,与tree一致。但是你此时执行tree命令,看不见效果;


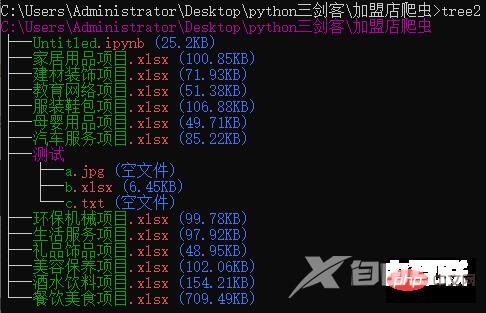
from treedir.tree import tree_dir tree_dir(r"C:\Users\Administrator\Desktop\python三剑客\加盟店爬虫", m_level=7, no_calc=False)
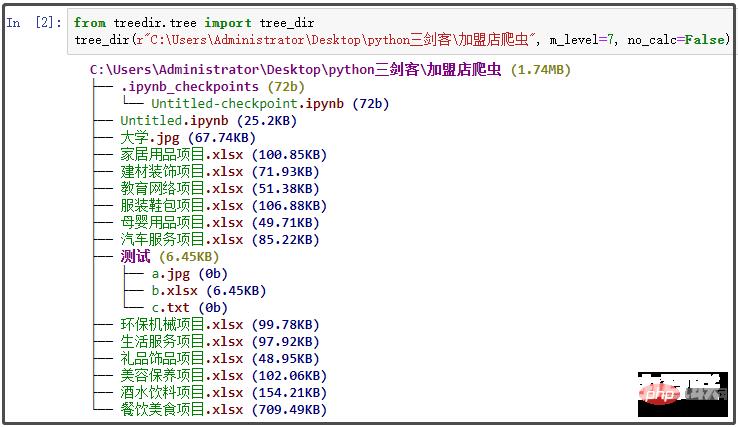
path:递归显示的目录路径,默认为当前目录; m_level:递归展示的最大层数,默认为7层; no_calc:指定该参数后,对于超过递归显示的最大层数的文件夹,不再继续递归计算文件夹大小;
a.txt文件,经过一段时间后,我对其中的内容做了修改,得到了最后的b.txt。
from filediff.diff import file_diff_compare
file_diff_compare("a.txt", "b.txt")html网页文件。
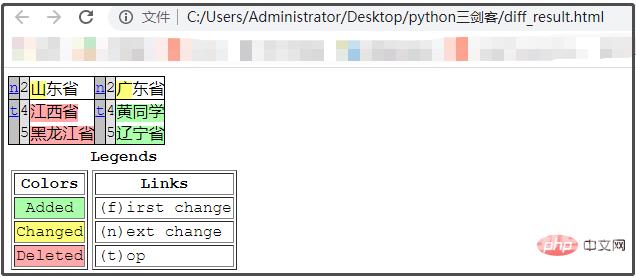
黄色表示改动过的内容,绿色表示新添加过的内容,红色表示已经删除过的内容。from filediff.diff import file_diff_compare file_diff_compare(file1, file2, diff_out='diff_result.html', max_width=70, numlines=0, show_all=False, no_browser=False)
file1 / file2:待比较的两个文件,必须文本文件; diff_out:差异结果保存的文件名(网页格式),默认值diff_result.html; max_width:每行超过多少字符就自动换行,默认值70; numlines:在差异行基础上前后显示多少行,默认是0; show_all:只要设置这个参数就表示显示全部原始数据,此时-n参数无效,默认不显示全部; no_browser:设置这个参数,在生成结果后,不会自动打开游览器。当设置为False后,会自动打开浏览器;
图片加水印代码,给图片加水印调用的是add_mark()函数。from watermarker.marker import add_mark # 注意:有些参数是默认参数,你可以随意修改的; add_mark(file, mark, out='output', color='#8B8B1B', size=30, opacity=0.15, space=75, angle=30)
file:待添加水印的照片; mark:使用哪些字作为水印; out:添加水印后保存的位置; color:水印字体的颜色,默认颜色#8B8B1B; size:水印字体的大小,默认50; opacity:水印字体的透明度,默认0.15; space:水印字体之间的间隔, 默认75个空格; angle:水印字体的旋转角度,默认30度;
from watermarker.marker import add_mark add_mark(file=r"C:\Users\Administrator\Desktop\大学.jpg", out=r"C:\Users\Administrator\Desktop\python三剑客\加盟店爬虫", mark="黄同学", opacity=0.2, angle=30, space=30)
大学.jpg添加一个黄同学水印,保存的位置在加盟店爬虫文件夹下,透明度是0.2,旋转角度是30°,字体之间的间隔是30。

Ⅰ 先在谷歌游览器中,复制网络抓到的网络请求为cURL(bash); Ⅱ 通过curl2py命令将其转换为python代码;
实习网的Python岗位为例,进行说明。http://www.shixi.com/search/index?key=python
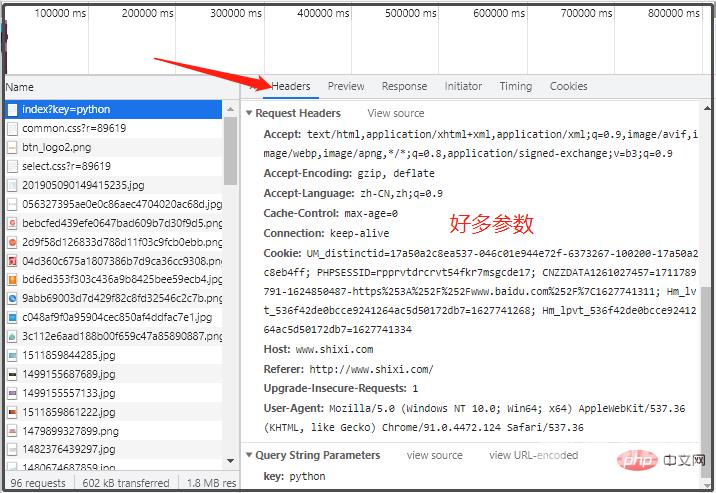
可以看到: 这里有各种不同的请求url,然后 -H后面是该请求对应的各种参数。我们需要请求哪个链接,就复制对应的curl。
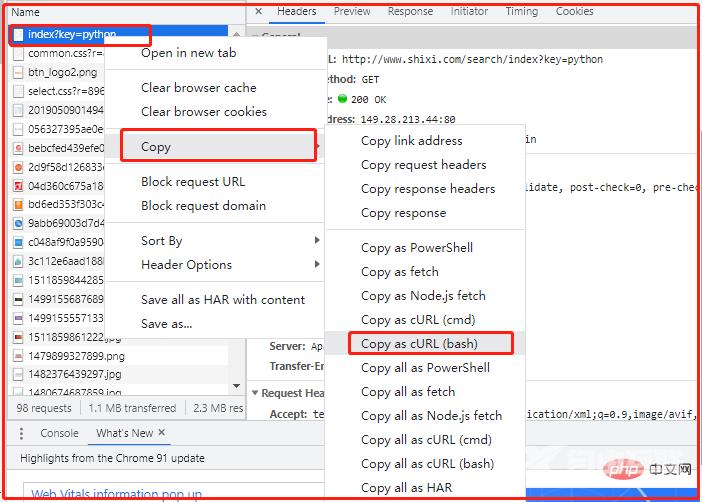
curl 'http://www.shixi.com/search/index?key=python' \ -H 'Connection: keep-alive' \ -H 'Cache-Control: max-age=0' \ -H 'Upgrade-Insecure-Requests: 1' \ -H 'User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36' \ -H 'Accept: text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9' \ -H 'Referer: http://www.shixi.com/' \ -H 'Accept-Language: zh-CN,zh;q=0.9' \ -H 'Cookie: UM_distinctid=17a50a2c8ea537-046c01e944e72f-6373267-100200-17a50a2c8eb4ff; PHPSESSID=rpprvtdrcrvt54fkr7msgcde17; CNZZDATA1261027457=1711789791-1624850487-https%253A%252F%252Fwww.baidu.com%252F%7C1627741311; Hm_lvt_536f42de0bcce9241264ac5d50172db7=1627741268; Hm_lpvt_536f42de0bcce9241264ac5d50172db7=1627741334' \ --compressed \ --insecure
from curl2py.curlParseTool import curlCmdGenPyScript curl_cmd = """curl 'http://www.shixi.com/search/index?key=python' \ -H 'Connection: keep-alive' \ -H 'Cache-Control: max-age=0' \ -H 'Upgrade-Insecure-Requests: 1' \ -H 'User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36' \ -H 'Accept: text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9' \ -H 'Referer: http://www.shixi.com/' \ -H 'Accept-Language: zh-CN,zh;q=0.9' \ -H 'Cookie: UM_distinctid=17a50a2c8ea537-046c01e944e72f-6373267-100200-17a50a2c8eb4ff; PHPSESSID=rpprvtdrcrvt54fkr7msgcde17; CNZZDATA1261027457=1711789791-1624850487-https%253A%252F%252Fwww.baidu.com%252F%7C1627741311; Hm_lvt_536f42de0bcce9241264ac5d50172db7=1627741268; Hm_lpvt_536f42de0bcce9241264ac5d50172db7=1627741334' \ --compressed \ --insecure""" output = curlCmdGenPyScript(curl_cmd) print(output)
