目录 1、pandas中重复索引问题 2、pandas删除重复数据行 3、drop_duplicates()函数的语法 附:pandas数据处理取出重复数据 方法: 总结 1、pandas中重复索引问题 df = df[~df.index.duplicated()] 2、panda
- 1、pandas中重复索引问题
- 2、pandas删除重复数据行
- 3、drop_duplicates()函数的语法
- 附:pandas数据处理——取出重复数据
- 方法:
- 总结
df = df[~df.index.duplicated()]2、pandas删除重复数据行
# 首先导入常用的两个包
import pandas as pd
import numpy as np
# 1.删除完全重复的行
df.drop_duplicates()
2.按k列进行去重,对于重复项,保留第一次出现的值
df.drop_duplicates('k',keep='first')
3、k2和k1两列进行去重
df.drop_duplicates(['k2','k1'], keep='first')
"""
keep:{‘first', ‘last', False}, 默认值 ‘first'
first:保留第一次出现的重复行,删除后面的重复行。
last:删除前面的重复项,保留最后一次出现的重复行。
False:删除所有重复项
"""
3、drop_duplicates()函数的语法
df.drop_duplicates(subset=['A','B','C'],keep='first',inplace=True)
参数说明如下:
- subset:表示要进去重的列名,默认为 None。
- keep:有三个可选参数,分别是 first、last、False,默认为 first,表示只保留第一次出现的重复项,删除其余重复项,last 表示只保留最后一次出现的重复项,False 则表示删除所有重复项。
- inplace:布尔值参数,默认为 False 表示删除重复项后返回一个副本,若为 Ture 则表示直接在原数据上删除重复项。
平常我们用pandas做重复数据处理时,常常调用到drop_duplicates方法来去除重。
现在我不想完全去除重复,而是把重复数据输出,现有数据如下所示:
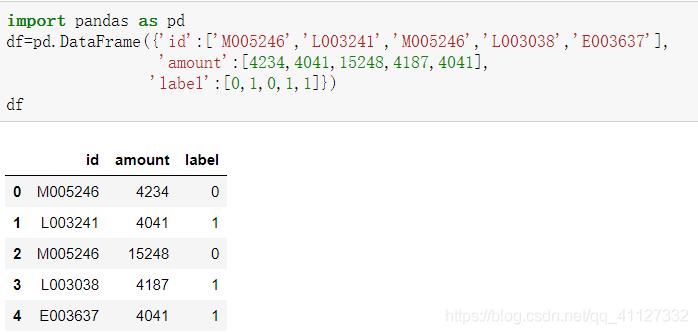
重复数据保留一个,duplicate_bool输出的是bool类型值,通过判断bool==True,取出重复行。
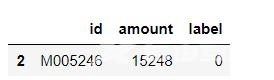
duplicate_bool = df.duplicated(subset=['id'], keep='first') repeat=df.loc[duplicate_bool == True] repeat复制
输出:
到此这篇关于pandas删除重复数据的文章就介绍到这了,更多相关pandas删除重复数据内容请搜索自由互联以前的文章或继续浏览下面的相关文章希望大家以后多多支持自由互联!
【文章转自高防服务器 http://www.558idc.com 复制请保留原URL】