背景:各个企业的记账系统,都超级复杂,超级重要,每一笔帐,对应的就是钱。而账务系统区别与前端在线业务系统,又有其处理记账过程中锁的问题,事务量较大等问题。考验开发水平的同时,也考验着后端的基础架构部门,运维部门。以下有脱敏部分,但实际经验都是来源于我们的生产系统。目前我们的账务系统,在面对高并发提交下的log file sync问题,以及索引分裂问题。我们逐渐去优化它。
如下是我们生产系统账务的耗时情况

阶段一:账务系统的耗时一直在往上彪,面对前端业务的考验,协同开发部门,一切群策群力,解决耗时高的问题。
1,_use_adaptive_log_file_sync 数据库将log file自适应关闭。
2,加大redo组容量,扩大redo组成员。2G-5G-8G,成员由10组,加大致15组。
3,更换高性能存储和服务器
上图耗时监控图中蓝色箭头处,就是做了以上动作后,耗时未降,反而升高。按正常来说,以上动作绝对是有明显的性能提升的。这里我们思考一下?
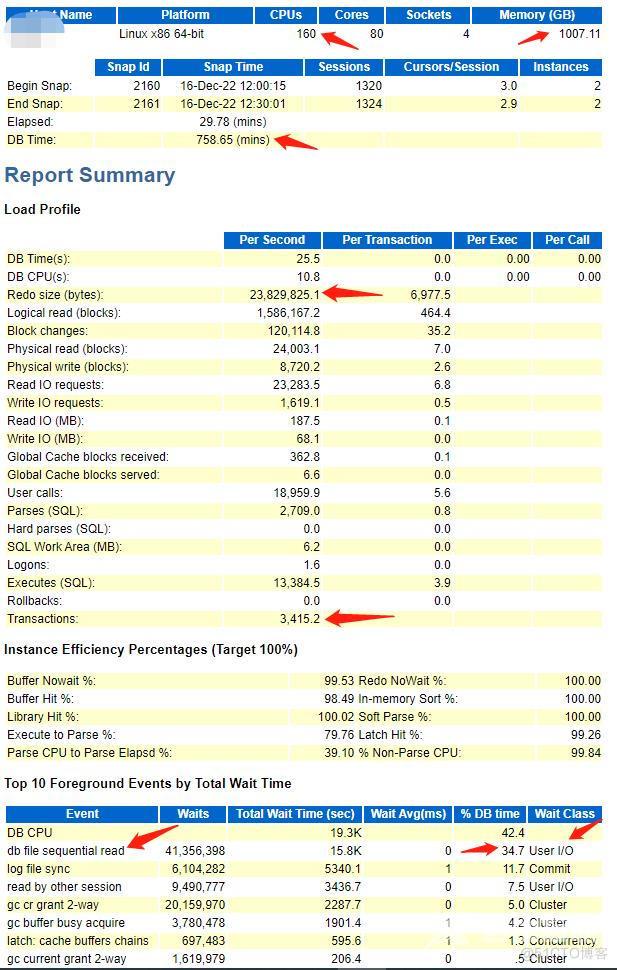
图上所示,REDO每秒23M/S,TPS每秒3415,CPU 160,物理内存1TB,等待事件log file sync确实是没了。但是凸显的是db file sequential read。很奇怪哈,因为这套库本人特别了解,历经三代,由早的REDO 512M2 MEMBER10历经六年优化到现在,一直致力于解决commit过多的问题,目前log file sync没了,出来的是顺序读,这里有什么不同点呢?回顾迁移时候,库的不一样,发现我们有一些幂等表,由迁库前的周分区表,变至日分区。而我们的分区,都是一年维护一年半的分区,举个例子。
yjf.partition分区表 P20230308 values less then (20230308)..... P20240808 values less then (20240808)...PMAX
这里的区别就是我们的分区数量由周一年+的分区数416个月分区数量=64个分区数量,变成了日分区一年+的分区数30*16=480个分区数量。这里需要注意幂等表在我们的生产环境中数量是做了水平拆分的,数量可观,所以,周边日,是一个外因素。而该数据库系统,也从此前仅有的log file sync变成了db file sequential read。
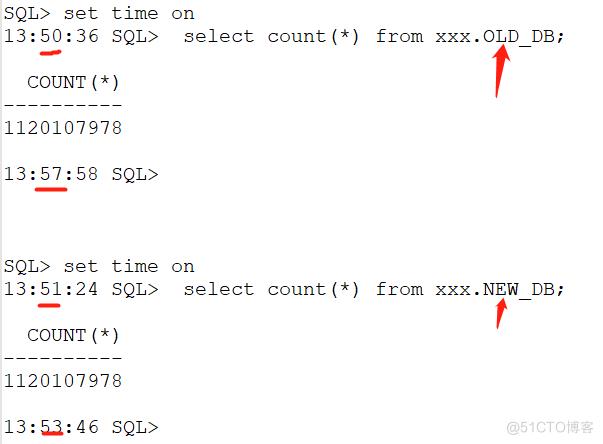
从400GB大表count速度来看,我们的新库新存储上的性能有明显的效果,老库需要7min、新库是它的一半时间。这里时间节点先做定格。
阶段二:有一些跑批流程上的耗时明显增加(尤其是重大节假日)如下是在春节左右的一段优化工作,从一个DBTIME的告警开始的~
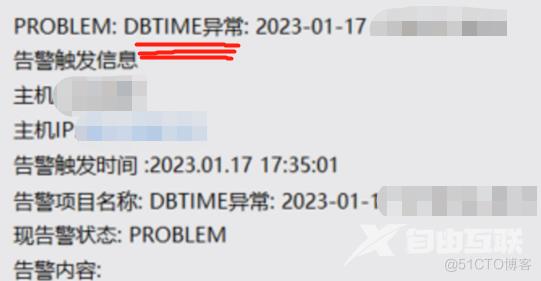
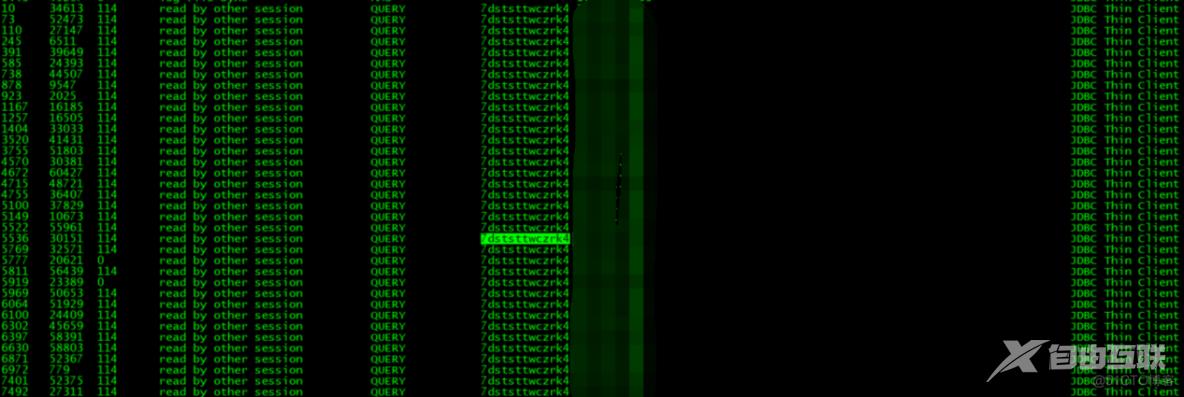
我们的跑批任务是一个小时一次,做一些资金的sum运算,在这个跑批任务里面,包含多种运算逻辑。那么在无法击破单个SQL带来的影响外,我们只能从SQL整体逻辑下手,对比不同。
1,发现跑批流程中的其他SQL,按SQL去优化查询效果
2,排除其他影响这个库以外的慢SQL,因为有DG备库,可以切至DG备库执行(高峰时间该库DG延迟约10s+)
3,排除统计信息不准,带来的SQL执行计划异常
4,补偿应急方案的联动其他部门一起应对此问题
如下是基于以上的优化后的一些效果,如跑批SQL前后耗时比对--来自AWR报告
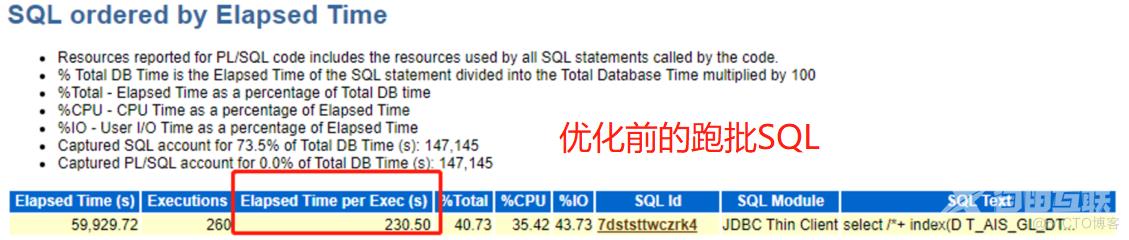
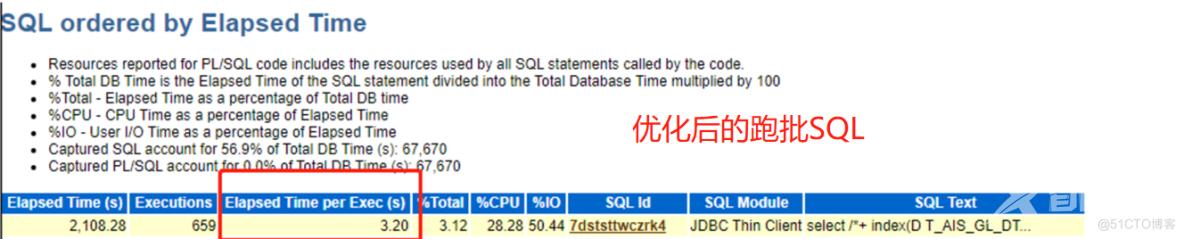
阶段三:刨根问底协同开发继续深化优化可能怀疑的方向
1,添加时间裁剪,在查询条件中,印证优化SQL
2,开发疑问某个特殊标识的商户查询速度快的疑问
3,索引分裂的解决思路
在PLSQL中分别执行了未加时间裁剪的跑批SQL,虽然是走了执行计划,但是还是partition range all
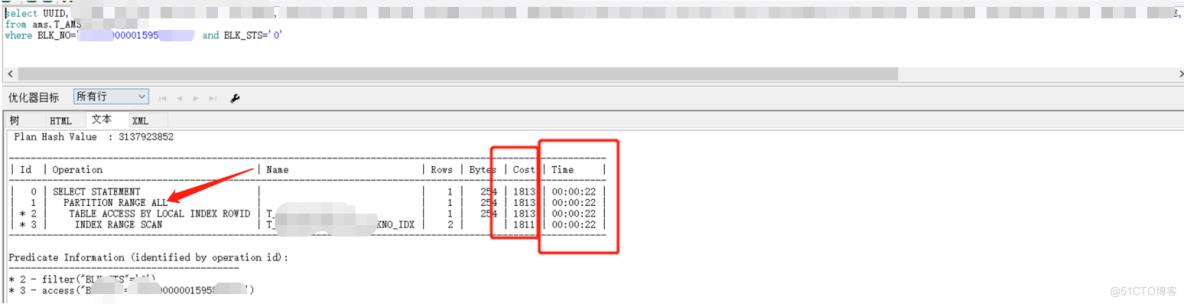
而我们添加了时间字段后,执行计划有了变化,执行时间也有体会(因业务逻辑,不能准确判断是哪一天,故使用between and)
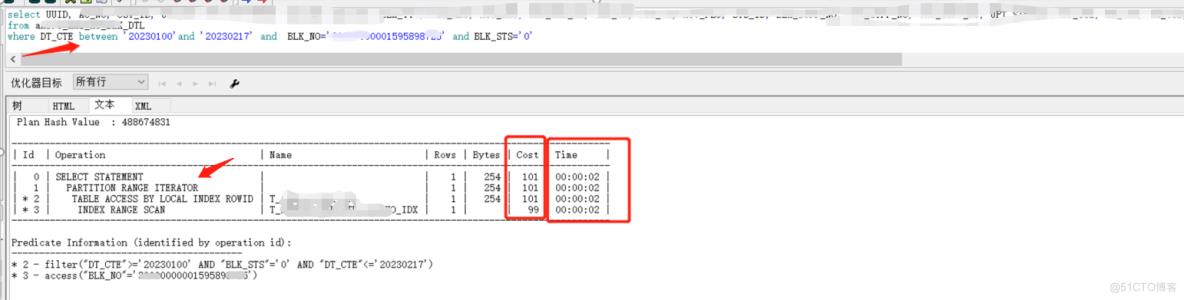
开发大佬反馈说,在查询书写方式一模一样的情况下,只是商户的值不一样。为什么会有查询效率的变化呢?这里其实可以使用10046去追踪一下看看哪里不同。
SQL> oradebug setmypid
Statement processed.
SQL> alter session set events '10046 trace name context forever ,level 12' ;
SQL> SELECT UUID, ORDER_NO, TCD, STS, RET_MSG,TRAN_DT FROM XXX.T_XXX_IDEMPOTENT_10 WHERE ORDER_NO = '100000' AND TXC = '101999';
SQL> alter session set events '10046 trace name context off' ;
SQL> oradebug tracefile_name
按上面的方法,分别执行不同的ORDER_NO ID,然后生成10046,然后去解读其中不一样的地方。
[oracle@nzwdb1 ~]$ tkprof /u01/app/oracle/diag/rdbms/nzwdb/nzwdb1/trace/nzwdb1_ora_356639.trc /tmp/yjf.tkp sys=no waits=yes
[oracle@nzwdb1 ~]$ tkprof /u01/app/oracle/diag/rdbms/nzwdb/nzwdb1/trace/nzwdb1_ora_358493.trc /tmp/zwman.txt
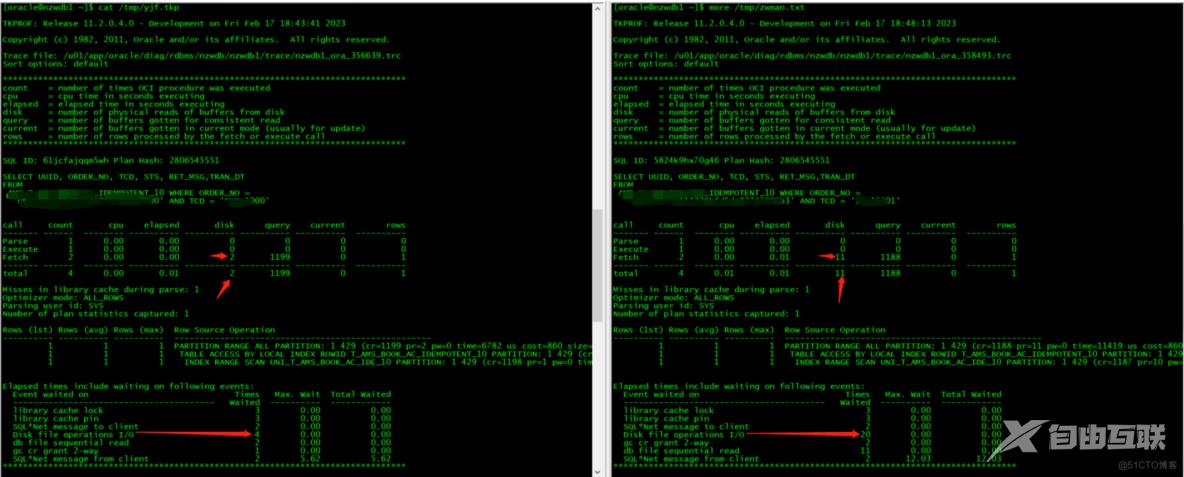

索引分裂的解决思路,我们的索引分裂,是91,还是55呢?这个问题,相信很多的DBA或者开发无法回答,如果不了解生成业务系统以及逻辑的话,我们从AWR里面可以清楚的获得

当然也可以通过如下SQL,获得分裂信息
select n.name, s.value
from v$sysstat s, v$statname n
where s.statistic# = n.statistic#
and n.name like '%split%';
55分裂的发生一般跟表插入的值比较随机,不是按照递增的去插,比较随机。
91分裂的发生主要发生在序列字段,自增字段。
leaf node 50-50 splits 当插入到索引叶子块中的索引键值不是该块中的最大值时(包括块中已删除的索引键值), 将发生 50/50 split分裂, 这意味着有一半索引记录仍存在当前块,而另一半数据移动到新的叶子块中。
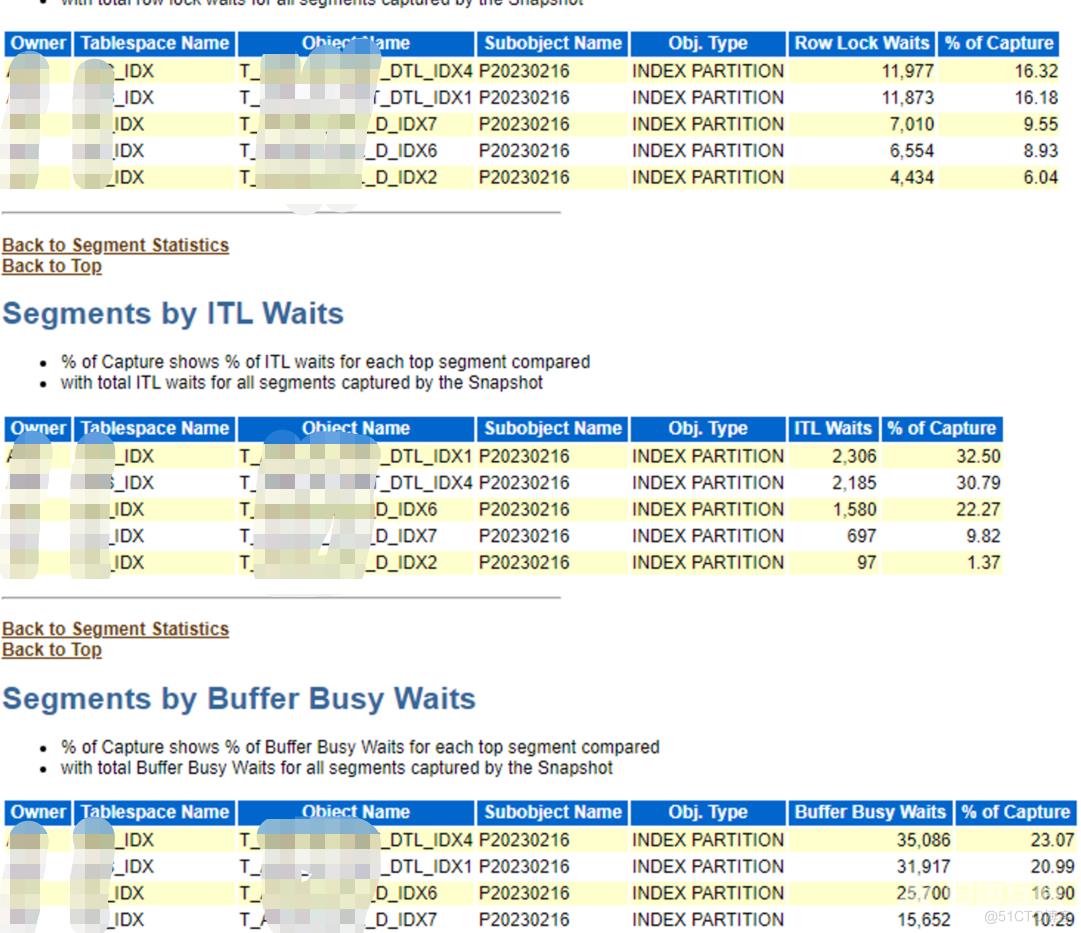
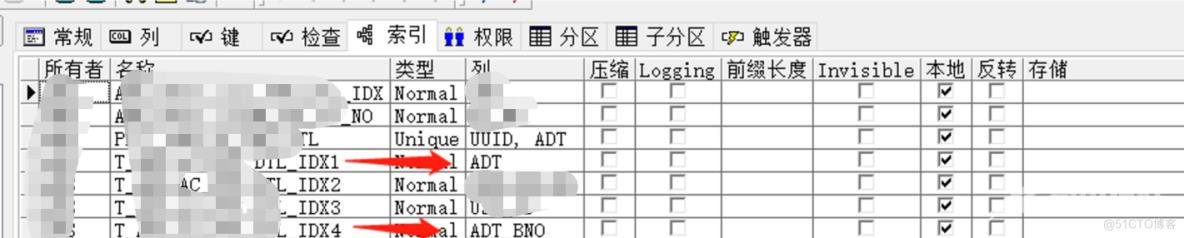
从AWR里面,我们可以清楚的看到是IDX1和IDX4争用严重、同时在生产上,会有ITL事务槽的等待,那这就简单了,我们生产规范这种大表的PCTFREE是默认上线在初始化参数上是调整到20的。
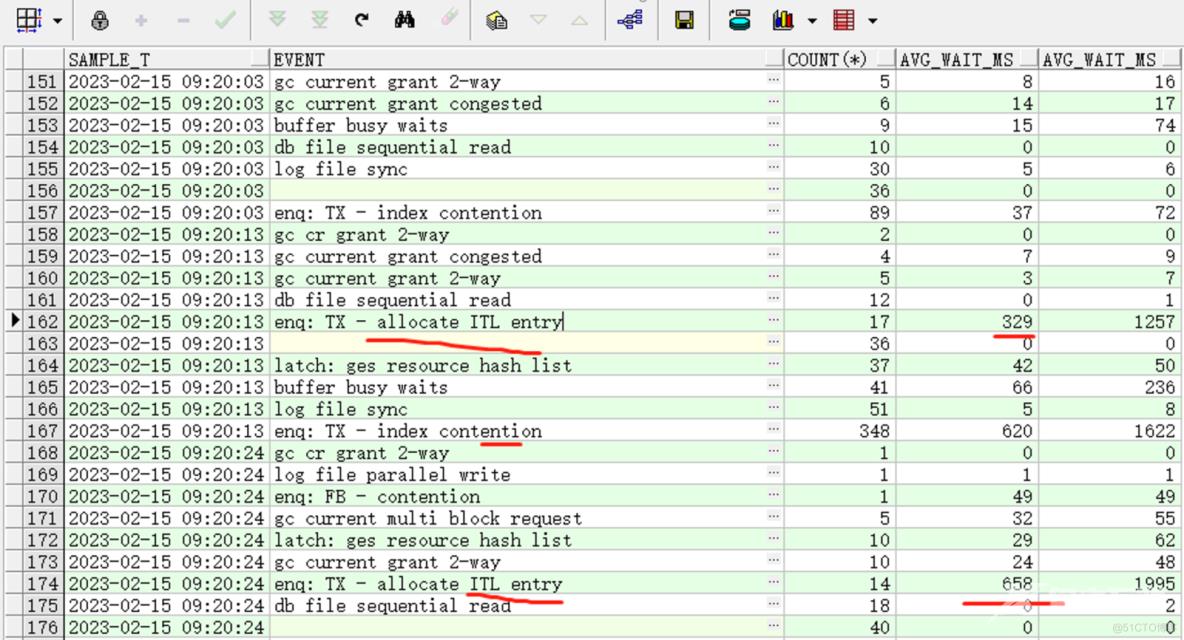
如何去解决高并发导致索引分裂的争用:
1.增加ITL槽来增加并发处理能力-->修改索引initrans 参数
其实修改initrans 参数并没有真正解决问题,随着并发度的不断提升,ITL 槽的争用也越发激烈,降低写入频次,批提,降低并发。
2.反向建索引。利:入库高效 弊:数据读取低效,本来访问一个索引块即可,现在需要访问多个索引块了。增加了额外I/O开销。
因为任何关于底层的改动,都会有真实的场景,真实的数据,切不可急挠挠的就去做改动,在压测环境进行压测后得出如下结论
考虑到是日分区表
1,修改空的日分区索引,加大initrans为32,按目前交易笔数5.4W笔每分钟体量压测,修改后降低了80%索引分裂等待;
2,修改空的日分区索引,加大initrans为32,按业务量增长至9W笔每分钟体量压测,修改后降低了50%索引分裂等待;
表300G,单个索引60G(所有分区加一起)rebuild索引的话,需要30分钟,按日分区的空分区修改索引的话,一个分区rebuild约1秒。
而且我们的开发比较牛C,在业务入口做了异步控制,通过MQ可以控制,可以通过关闭MQ写入,配合数据库侧做此改动。
目前该问题暴露的不是很严重,还在多场景压测中,看下在批提的同时,多大的itl槽位可以满足我们业务量翻倍的要求。
阶段四:万法归宗,各类组合拳下的优化成效
1,由每个小时的在Oracle数据库中sum记账,换至Redis实时累计记账
2,缩短阶段一中的幂等表保留周期,由此前的365天分区数据,缩短至3个月,使其扫描的行,块变少


总结:
面对问题的时候,我们先不要去否定什么或者排除自己的问题,因积极去了解业务,帮助开发一起解决生产问题,深挖逻辑的同时,也要对自己的技术水平自信。无需唯唯诺诺,在自己专业的领域,你就是最棒的!
账务的总体记账情况,由100多ms,优化至10ms。该案例大概横跨1年有余,希望可以切实的帮助到大家~感谢您的观阅。