接上篇https://www.daodaodao123.com/?p=776 本篇解析缺页异常分支之一,写时复制缺页异常; 1.写时复制缺页异常触发条件 (1)pte页表项的PRESENT置位(2)pte表项为不为空(3)vma可写,pte只读,进行写
接上篇 https://www.daodaodao123.com/?p=776
本篇解析缺页异常分支之一,写时复制缺页异常;
1.写时复制缺页异常触发条件
(1)pte页表项的PRESENT置位 (2)pte表项为不为空 (3)vma可写,pte只读,进行写操作
2.应用场景
(1)进程fork子进程的时候,为了避免复制物理页,父子进程以只读的方式共享所有的私有的匿名页和文件页,当父子进程有一方试图去写只读页时,触发写时复制缺页异常,内核会分配新的物理页,拷贝旧的物理页到新页,然后把新页映射虚拟页;
(2)进程创建私有匿名映射,读之后写(读映射到0页,写发生COW);
(3)进程创建私有文件映射,读之后写(读映射到page cache, 写发生COW);
3.fork时做的准备
dup_mm
->dum_mmap
->copy_page_range
...
->copy_pte_range
->copy_present_pte
->if(is_cow_mapping(vm_flags)&&pte_write(pte))
{
ptep_set_wrprotect(src_mm, addr, src_pet);
pte = pte_wrpotect(pte);
}
可见,对于私有的可写的页,fork时,将父子进程的页表改为只读.
注:子进程会创建一套独立新页表,只是PTE页表的内容,跟父进程页表完全一样。当先访问进程触发缺页异常时,修改的知识PTE页表,L0~2级页表是不变的。
4.两个重要函数
4.1 wp_page_copy()写时复制函数
static vm_fault_t wp_page_copy(struct vm_fault *vmf)
{
struct vm_area_struct *vma = vmf->vma;
struct mm_struct *mm = vma->vm_mm;
struct page *old_page = vmf->page;
struct page *new_page = NULL;
pte_t entry;
int page_copied = 0;
struct mmu_notifier_range range;
if (unlikely(anon_vma_prepare(vma))) ///检查VMA是否初始化了RMAP
goto oom;
if (is_zero_pfn(pte_pfn(vmf->orig_pte))) { ///PTE如果是系统零页,分配一个内容全零的页面
new_page = alloc_zeroed_user_highpage_movable(vma,
vmf->address);
if (!new_page)
goto oom;
} else { ///分配一个新物理页面,并且把old_page内容复制到new_page中
new_page = alloc_page_vma(GFP_HIGHUSER_MOVABLE, vma,
vmf->address);
if (!new_page)
goto oom;
if (!cow_user_page(new_page, old_page, vmf)) {
/*
* COW failed, if the fault was solved by other,
* it's fine. If not, userspace would re-fault on
* the same address and we will handle the fault
* from the second attempt.
*/
put_page(new_page);
if (old_page)
put_page(old_page);
return 0;
}
}
if (mem_cgroup_charge(new_page, mm, GFP_KERNEL))
goto oom_free_new;
cgroup_throttle_swaprate(new_page, GFP_KERNEL);
__SetPageUptodate(new_page); ///设置PG_uptodate, 表示内容有效
///注册一个mmu_notifier,并告知系统使dd_page无效
mmu_notifier_range_init(&range, MMU_NOTIFY_CLEAR, 0, vma, mm,
vmf->address & PAGE_MASK,
(vmf->address & PAGE_MASK) + PAGE_SIZE);
mmu_notifier_invalidate_range_start(&range);
/*
* Re-check the pte - we dropped the lock
*/ ///重新读取PTE,并判定是否修改
vmf->pte = pte_offset_map_lock(mm, vmf->pmd, vmf->address, &vmf->ptl);
if (likely(pte_same(*vmf->pte, vmf->orig_pte))) {
if (old_page) {
if (!PageAnon(old_page)) { ///如果oldpage是文件映射
dec_mm_counter_fast(mm,
mm_counter_file(old_page)); ///减少一个文件映射页面技术
inc_mm_counter_fast(mm, MM_ANONPAGES); ///增加匿名页面计数
}
} else {
inc_mm_counter_fast(mm, MM_ANONPAGES);
}
flush_cache_page(vma, vmf->address, pte_pfn(vmf->orig_pte));
entry = mk_pte(new_page, vma->vm_page_prot);
entry = maybe_mkwrite(pte_mkdirty(entry), vma); ///利用new_page生成一个新PTE
/*
* Clear the pte entry and flush it first, before updating the
* pte with the new entry, to keep TLBs on different CPUs in
* sync. This code used to set the new PTE then flush TLBs, but
* that left a window where the new PTE could be loaded into
* some TLBs while the old PTE remains in others.
*/
ptep_clear_flush_notify(vma, vmf->address, vmf->pte); ///刷新这个页面的TLB
page_add_new_anon_rmap(new_page, vma, vmf->address, false); ///new_page添加到RMAP系统中
lru_cache_add_inactive_or_unevictable(new_page, vma); ///new_page添加到LRU链表中
/*
* We call the notify macro here because, when using secondary
* mmu page tables (such as kvm shadow page tables), we want the
* new page to be mapped directly into the secondary page table.
*/
set_pte_at_notify(mm, vmf->address, vmf->pte, entry); ///新pte设置到硬件PTE中
update_mmu_cache(vma, vmf->address, vmf->pte);
if (old_page) { ///准备释放old_page,真正释放操作在page_cache_release()函数
/*
* Only after switching the pte to the new page may
* we remove the mapcount here. Otherwise another
* process may come and find the rmap count decremented
* before the pte is switched to the new page, and
* "reuse" the old page writing into it while our pte
* here still points into it and can be read by other
* threads.
*
* The critical issue is to order this
* page_remove_rmap with the ptp_clear_flush above.
* Those stores are ordered by (if nothing else,)
* the barrier present in the atomic_add_negative
* in page_remove_rmap.
*
* Then the TLB flush in ptep_clear_flush ensures that
* no process can access the old page before the
* decremented mapcount is visible. And the old page
* cannot be reused until after the decremented
* mapcount is visible. So transitively, TLBs to
* old page will be flushed before it can be reused.
*/
page_remove_rmap(old_page, false);
}
/* Free the old page.. */
new_page = old_page;
page_copied = 1;
} else {
update_mmu_tlb(vma, vmf->address, vmf->pte);
}
if (new_page)
put_page(new_page);
pte_unmap_unlock(vmf->pte, vmf->ptl);
/*
* No need to double call mmu_notifier->invalidate_range() callback as
* the above ptep_clear_flush_notify() did already call it.
*/
mmu_notifier_invalidate_range_only_end(&range);
if (old_page) {
/*
* Don't let another task, with possibly unlocked vma,
* keep the mlocked page.
*/
if (page_copied && (vma->vm_flags & VM_LOCKED)) {
lock_page(old_page); /* LRU manipulation */
if (PageMlocked(old_page))
munlock_vma_page(old_page);
unlock_page(old_page);
}
put_page(old_page);
}
return page_copied ? VM_FAULT_WRITE : 0;
oom_free_new:
put_page(new_page);
oom:
if (old_page)
put_page(old_page);
return VM_FAULT_OOM;
}
4.2 wp_page_reuse()页面复用函数
当发生COW缺页异常时,发现这个匿名页只被映射到一个vma中,则不再发生写时复制,如果vma属性为可写,直接修改页表为可写。
static inline void wp_page_reuse(struct vm_fault *vmf)
__releases(vmf->ptl)
{
struct vm_area_struct *vma = vmf->vma;
struct page *page = vmf->page; ///获取缺页异常页面
pte_t entry;
/*
* Clear the pages cpupid information as the existing
* information potentially belongs to a now completely
* unrelated process.
*/
if (page)
page_cpupid_xchg_last(page, (1 << LAST_CPUPID_SHIFT) - 1);
flush_cache_page(vma, vmf->address, pte_pfn(vmf->orig_pte)); ///刷新缺页异常页面的高速缓存
entry = pte_mkyoung(vmf->orig_pte); ///设置PTE的AF位
entry = maybe_mkwrite(pte_mkdirty(entry), vma); ///设置可写,置脏位
if (ptep_set_access_flags(vma, vmf->address, vmf->pte, entry, 1)) ///设置新PTE到实际页表中
update_mmu_cache(vma, vmf->address, vmf->pte);
pte_unmap_unlock(vmf->pte, vmf->ptl);
count_vm_event(PGREUSE);
}
5.写时复制过程解析:
写时复制过程流程图
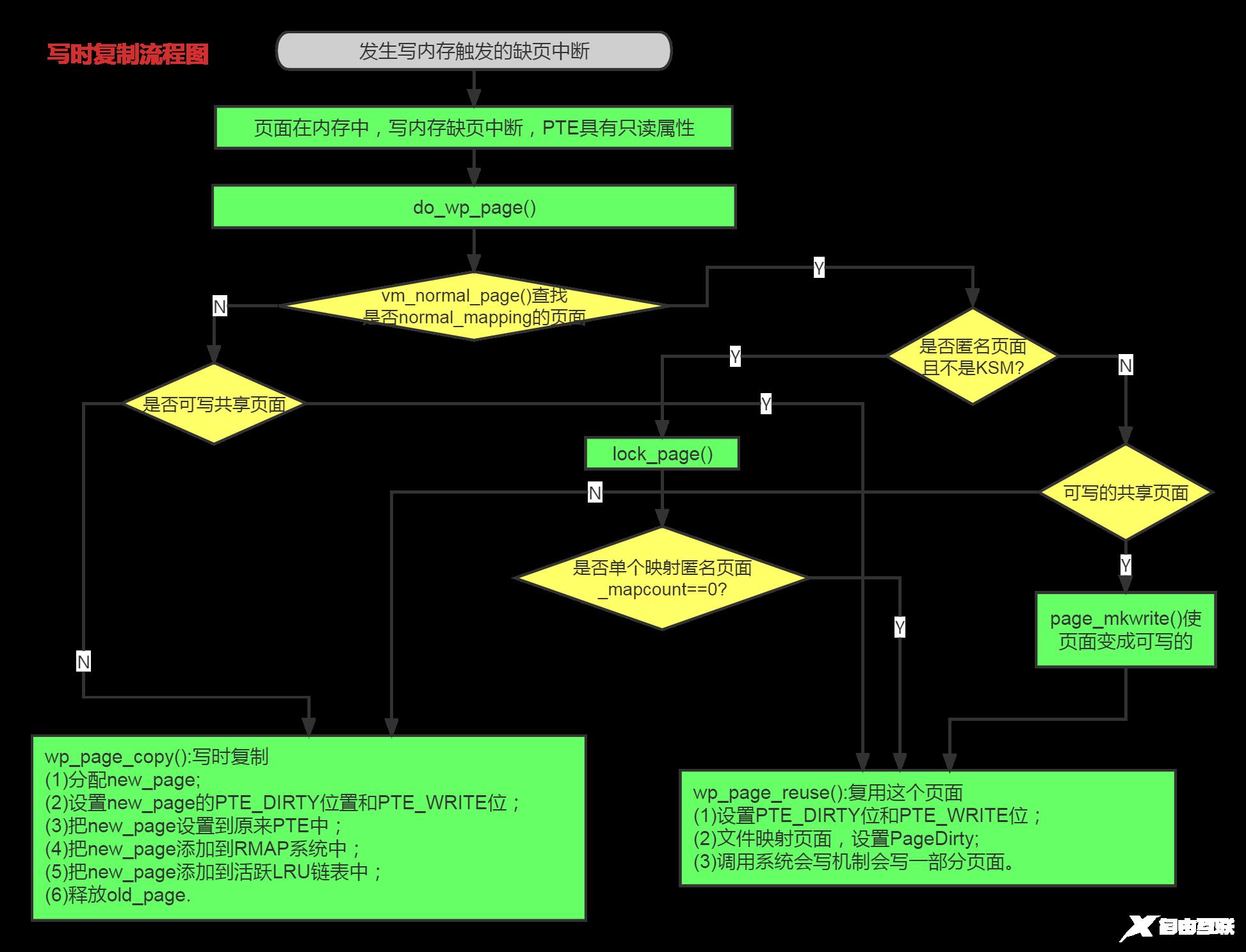
源码解析
static vm_fault_t do_wp_page(struct vm_fault *vmf)
__releases(vmf->ptl)
{
struct vm_area_struct *vma = vmf->vma;
if (userfaultfd_pte_wp(vma, *vmf->pte)) {
pte_unmap_unlock(vmf->pte, vmf->ptl);
return handle_userfault(vmf, VM_UFFD_WP);
}
/*
* Userfaultfd write-protect can defer flushes. Ensure the TLB
* is flushed in this case before copying.
*/
if (unlikely(userfaultfd_wp(vmf->vma) &&
mm_tlb_flush_pending(vmf->vma->vm_mm)))
flush_tlb_page(vmf->vma, vmf->address);
vmf->page = vm_normal_page(vma, vmf->address, vmf->orig_pte); ///查找缺页异常地址对应页面的page数据结构,返回为NULL,说明是一个特殊页面
if (!vmf->page) { ///处理特殊页面
/*
* VM_MIXEDMAP !pfn_valid() case, or VM_SOFTDIRTY clear on a
* VM_PFNMAP VMA.
*
* We should not cow pages in a shared writeable mapping.
* Just mark the pages writable and/or call ops->pfn_mkwrite.
*/
if ((vma->vm_flags & (VM_WRITE|VM_SHARED)) ==
(VM_WRITE|VM_SHARED)) ///特殊页面,且vma是可写且共享
return wp_pfn_shared(vmf); ///复用
pte_unmap_unlock(vmf->pte, vmf->ptl);
return wp_page_copy(vmf); ///vma不是可写共享页面,写时拷贝
}
/*
* Take out anonymous pages first, anonymous shared vmas are
* not dirty accountable.
*/
if (PageAnon(vmf->page)) {///PageAnon判断是否为匿名页面
struct page *page = vmf->page;
/* PageKsm() doesn't necessarily raise the page refcount */
if (PageKsm(page) || page_count(page) != 1)
goto copy;
if (!trylock_page(page))
goto copy;
if (PageKsm(page) || page_mapcount(page) != 1 || page_count(page) != 1) {
unlock_page(page);
goto copy;
}
/*
* Ok, we've got the only map reference, and the only
* page count reference, and the page is locked,
* it's dark out, and we're wearing sunglasses. Hit it.
*/
unlock_page(page);
wp_page_reuse(vmf); ///PageAnon判断是否为匿名页面,且不为KSM匿名页面, 复用
return VM_FAULT_WRITE;
} else if (unlikely((vma->vm_flags & (VM_WRITE|VM_SHARED)) ==
(VM_WRITE|VM_SHARED))) {
return wp_page_shared(vmf); ///处理可写的共享页面,复用
}
copy:
/*
* Ok, we need to copy. Oh, well..
*/
get_page(vmf->page);
pte_unmap_unlock(vmf->pte, vmf->ptl);
return wp_page_copy(vmf); ///处理写时复制的情况
}