前言
本文将会介绍Ansible Runner的基础概念以及笔者的一些实战经验。本文适合的人群为对Ansible提供的功能进行二次封装,并与相关自研平台或服务结合的工程师群体。
大家通常会选择使用Ansible来实现对海量服务器/VM批量操作的需求。在运用Ansible时,大多数人往往都比较注重于Playbook/Role的编写,而对于Ansible的调用方式一般都会选择命令行调用(包括利用代码调用命令行)。在运维工作中,部署服务、批量执行脚本等类似的工作会经常出现,这些工作通常会选择使用Ansible来实现。随着需要支持的工程(微服务)增多、研发迭代速度加快以及需要频繁执行特定脚本实现需求的等现象的出现;如果还是使用人工执行命令行的方式调用Ansible,则会给运维工作增加很大的压力(即使Ansible的Playbook/Role编写的再好也如此)。此时,大家可能会想到:可以通过代码来实现调用Ansible的操作,这样就可以对接到相应的自动化平台或服务中,从而实现Ansible的自动化调用。
笔者认为,上述思路的大方向是没有问题的,但很多人却忽略了一个重要的问题: 代码与Ansible的交互。做过运维工具开发的人一定很清楚这个痛点: 所调用的命令行命令只会通过屏幕打印的方式进行结果输出,而后续如果需要对结果进行分析的话,还需要读取这些屏幕打印内容并通过例如字符串匹配等方法来解析结果输出。上述这个操作实际上是一个很繁琐的逻辑,而且分析结果的准确性也不是很高(屏幕打印的格式可能会改变)。
这个问题本质上就是一个与Ansible命令行交互的问题,而Ansible Runner就可以帮助我们很好的解决这个问题。Ansible Runner会对Ansible的输出结果进行采集和分析,并将其中的数据保存在编程语言中的基础类型变量中。Ansible Runner能够帮助我们更好通过编码的方式来与Ansible进行交互。同时,Ansible Runner还将Ansible的相关调用封装成了标准的API供使用者调用;支持使用者自定义状态处理器或事件处理器来对Ansible执行过程中的各类事件或状态进行分析和处理。
因此,笔者在最开始就提到过,如果你需要将Ansible与相关自研平台或服务结合的需求时,则推荐使用Ansible Runner来封装Ansible相关功能。这样能够减轻很多代码开发的工作量,并且能够提高的平台/服务与Ansible交互的稳定性。当然,如果你只是有着“使用脚本来调用Ansible”的需求的话,那么就无需继续阅读本文的后续内容了。
笔者也会将自己的理解在文中进行阐述,这也算是在和大家交流心得的一个过程。若文中有错误的理解和概念,请大家及时纠正;吸纳大家的建议,对于我来说也是很重要的学习过程之一。
1.相关概念
1.1 Ansible Core API VS Ansible Runner API
目前有以下几种方法来通过代码形式调用Ansible:
1. 调用Ansible Core Python API
2. 调用Ansible Runner Python API
3. 使用Ansible Tower
4. 使用Ansible AWX
5. 使用命令行方式调用Ansible
如果使用非Python的编程语言,则只能通过3、4、5这三类方法来辅助实现。反之,则首选1和2两种方式。
Ansible Core API的优势是在于能够更细化的调用和控制Ansible的相关功能。而其缺点在于,一旦Core API随着Ansible版本升级而发生了改变,则与其相关的上层自研部分也需要同步进行修改;并且Ansible Core API也有着一定的学习成本,其调用方式相对复杂,需要先了解一部分Ansible的内部概念。
Ansible Runner的优势在于为使用者提供了一套通用的API来调用Ansible,使用者无需关心Ansible Core API的细节。并且Ansible Runner屏蔽了很多Ansible Core API的调用细节,使其API在调用时更加接近我们日常在命令行调用Ansible的方式。同时,Ansible Runner还提供了一些实用的Ansible高级用法,使得Ansible能够解决更多类型的需求。
因此,如果只是需求将Ansible的基本功能融合到相关平台或服务中,则推荐首选Ansible Runner(这也是Ansible官方所推荐的做法)。因为这样能够节省很多研发成本,使得开发者可以把更多的开发重心放到自研项目上。如果有对Ansible有深度改造或二次开发的需求,则推荐使用Ansible Core API。
Tips: 笔者认为,
Ansible Runner实际上做的事情就是将Ansible Core API与我们的自研工程进行二次解耦。之所为称其为二次解耦,是因为Ansible Core API本身就是Ansible为开发者提供的以接口形式调用的Ansible功能,但由于Ansible内部有着过多复杂的概念,因此Ansible Core API使用起来相对繁杂。而Ansible Runner提供的API对这些复杂部分进行了封装屏蔽,使得开发者能够更快速高效的调用Ansible。笔者认为Ansible Runner是从Ansible使用者角度来进行抽象封装API,所以Ansible Runner提供的API更加亲民;而Ansible是从研发者角度进行的抽象封装,它的本意是想将Ansible的内部概念以及功能以API的形式提供给外界使用。
2. Ansible Runner项目结构
Ansible Runner在调用Ansible时,有两种方式来提供Ansible所需的数据:
1. 指定数据位置
在调用Ansible Runner时,通过相关参数指定Ansible所需数据存放的文件或目录位置。
2. 遵循Ansible Runner项目结构建立数据目录
按照Ansible Runner的目录格式要求创建相应项目。
如同使用Ansible,在使用Ansible之前也需要按照Ansible的配置建立相应目录和创建相应文件;例如Inventory文件、Playbook文件和Role目录等等。
笔者推荐使用第二种方式来提供Ansible数据。原因有两点,一是Ansible Runner提供的项目结构并不复杂,而且大多数均为Ansible的概念,使用者能够很快理解和上手;二是使用了Ansible Runner提供的项目结构后,可以有效的规范和规整Ansible的相关数据。
Ansible Runner的项目结构如下图所示:
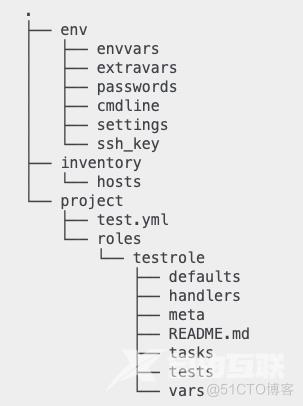 这里对其中的一些重要目录进行解释:
这里对其中的一些重要目录进行解释:
1. env/extravars
一般用来存放自定义变量。
2. env/passwords
用来存放ssh使用的密码,但需要使用特殊的格式书写。
3. env/cmdline
用来描述ansible的命令行参数
4. env/ssh_key
用来存放ssh key。注意,目前只能存放一个key。
5. env/settings
用于存放Ansible Runner自身所使用的命令行参数。
详情请参考:[Ansible Runner参数说明](https://ansible-runner.readthedocs.io/en/latest/intro/)
6. inventory
同Ansible的inventory目录。Ansible Runner在调用Ansible时候会指定Ansible加载该目录下的主机信息。
7. project/roles
同Ansible的Roles目录。
8. artifacts
Ansible Runner执行的结果、状态数据以及job事件数据都会存在该目录下。
9. profiling_data
如果为Ansible Runner启用了资源分析,那么profiling_data目录将被一组包含分析数据的文件。
3. Ansible Runner API
Ansible Runner项目的两个核心概念为:helper interfaces和ansible runner对象。
3.1 ansible runner对象
该对象中主要保存了Ansible的执行过程数据、执行状态数据、结果数据以及Ansible的执行输出。因此往往会通过该对象来获取Ansible的执行状态或执行结果等等。 还可以通过为ansible runner对象绑定不同类型的handler或callback来实现特殊需求。注意,实现handler时最好事先了解一下Ansible Runner中相应的status event与ansible event的数据结构。因为handler是基于这些event来触发的。这里笔者挑选了认为比较常用的几个绑定方法来进行详细的介绍。
3.1.1 finished_callback
该回调方法用于在执行结束后触发,可将一些清理或收尾的相关逻辑加入到该回调方法中。
Python示例代码如下:
def finished_callback(data):
"""
data实际上为ansible runner对象
注意,data的对象类型和ansible runner运行的模式相关
例如,如果是以普通模式运行,则data为ansible runner对象实例
若是以Processo模式运行,则data为ansible_runner.streaming.Processor对象实例
"""
print('\n结束')
print(data)
3.1.2 status_handler
Ansible Runner将Ansible执行过程分为了几个阶段,每个阶段都有相对应的状态值:
1. starting
2. running
3. canceled
4. timeout
5. failed
6. successful
Ansible Runner使用status event来保存这些阶段的状态数据。每当状态发生改变时,Ansible Runner就会发送出status events。此时如果配置了status_handler,则status event就会被发送到status_handler。因此,通过status_handler可以实现在特定的状态时执行相应的操作逻辑。
Python示例代码如下:
def status_handler(data, runner_config):
# data是一个dict,里边记录了runner的执行状态数据
print('\n状态改变')
print(runner_config)
for k, v in data.items():
print("{}: {}".format(k, v))
if data['status'] == 'successful':
print('执行成功')
elif data['status'] == 'failed' or data['status'] == 'timeout':
print('执行失败')
3.1.3 event_handler
Ansible Runner会收集Ansible在执行Playbook时所发出的每一个Ansible event。如果此时配置了event_handler,则每一个Ansible event都会被发送到event_handler中。因此,可通过event_handler可以实现在到特定步骤时执行相应的操作逻辑。
同时,Ansible Runner还可以将特定的event保存下来。实现这个功能只需要使event_handler在函数最后return True即可,return Fasle表示不保存在该event。被保存event的数据会存放于Ansible Runner目录结构中的artifact/job_events目录下,文件格式为json。后续还可以读取这些json文件来对Ansible event进一步进行分析。
Python示例代码如下:
def event_handler(data):
"""
从调用ansible开始,ansible进程每有一行屏幕打印,就会产生一个event
不同阶段的event都有不同的内部名称,例如playbook_on_stats
"""
if data['event'] == 'playbook_on_stats': # 获取特定事件中的数据
print('抓取事件数据')
print("{}: {}".format('event_data', data['event_data']))
# 获取执行失败的机器
unreachable_hosts = set(data['event_data']['dark'].keys())
failed_hosts = set(data['event_data']['failures'].keys())
problem_hosts = list(unreachable_hosts | failed_hosts)
print(f"执行失败的host:{problem_hosts}")
return True # 只保存特定事件数据
elif data['event'] == 'runner_on_ok' and data['event_data']['task'] == 'test task':
print("{}: {}".format('命令输出', data['event_data']['res']['stdout']))
return True # 只保存特定事件数据
else:
print('\n产生事件')
for k, v in data.items():
print("{}: {}".format(k, v))
return False # 不保存其他事件数据
4. 远程执行Ansible任务
通常,Playbook/Role与Ansible往往需要部署和安装在同一个节点上才可进行使用,这种使用方式可能会造成同一个Playbook/Role存在多份.因此就会导致每次在更新这些Playbook/Role时需要进行大量重复操作。而Ansible Runner允许Playbook/Role与Ansible部署在不同节点上,此时通过其特有的远程任务执行功能,依旧可以实现Playbook/Role的正常调用。
Ansible Runner的远程任务执行功能主要分为3个部分,本章节内将会对每一部分进行详细的介绍。
4.1 Transmit
该部分主要是将Playbook/Role进行序列化,转为二进制流,并输出序列化结果。
Python示例代码如下:
private_data_dir = os.path.abspath(os.path.join(os.path.dirname(__file__), "..", 'ansible-runner/test')) # 指定Ansible Runner的数据目录
transmit_output_file = f'/tmp/transmitterOutput-{str(uuid.uuid4())}' # 将序列化结果保存在指定文件中
with open(transmit_output_file, "wb+") as f: # 注意序列化结果为二进制流
transmitter = ansible_runner.run(
inventory=inventory,
private_data_dir=private_data_dir,
envvars=envvars,
role=role_name,
streamer='transmit', # 需要指定执行模式
_output=f, # 传入保存结果文件的file对象实例
quiet=True
)
transmitter._output.seek(0) # 将文件指针调整到文件开头处
result = transmitter._output.readlines()
print(result)
Tips: Ansible Runner之所以能够做到在没有存放Playbook/Role相关文件的节点上依旧可以正常执行脚本,原因就在于它把对应脚本序列化后并借助其他手段(例如网络传输等)将脚本内容传输到其他相应的执行节点上。因为本质上还是调用Ansible来执行这些脚本,所以脚本和Ansible务必需要在同一台节点上。
笔者认为,Ansible Runner是借鉴了分布式任务框架的一些相关理念,实现了类似于将Playbook/Role封装成任务并派发到相应的Ansible节点上执行的理念。但要注意的是,Ansible Runner并没有实现传输序列化数据这一部分功能,这一部分需要使用者自行来实现。
4.2 Worker
该部分主要接收被二进制序列化后的脚本,并真正调用Ansible执行这些脚本。同时,将整个执行过程进行二进制序列化并输出。
Python示例代码如下:
private_data_dir = os.path.abspath(os.path.join(os.path.dirname(__file__), "..", 'ansible-runner/worker')) # 指定Ansible Runner的数据目录
worker_output_file = f'/tmp/workerOutput-{str(uuid.uuid4())}' # 将执行结果保存在指定文件中
# 清空worker目录
if os.path.exists(private_data_dir):
shutil.rmtree(private_data_dir)
with open(transmit_output_file, "rb+") as transmit_output: # 注意序列化结果为二进制流
with open(worker_output_file, "wb+") as worker_output: # 注意整个执行过程的序列化为二进制流
worker = ansible_runner.run(
private_data_dir=private_data_dir,
streamer='worker', # 需要指定执行模式
_input=transmit_output, # 传入保存了transmit模式输出的序列化数据的file对象实例
_output=worker_output, # 传入保存结果文件的file对象实例
timeout=600,
quiet=True
)
worker._output.seek(0) # 将文件指针调整到文件开头处
result = worker._output.readlines()
print(result)
Worker模式在执行完后会将Ansible完整的执行过程进行二进制序列化并输出。在章节2介绍过,Ansible Runner会将Ansible的执行的结果、状态数据以及job事件数据都会存在artifacts目录中。Worker序列化的数据实际上就是artifacts目录中的数据,即后续Process模式分析的数据即为artifacts目录中的数据。
Tips: 对于这一部分,笔者想提醒的是:如果你的需求只是关心Playbook/Role是否有被执行,而非Playbook/Role是否有被成功执行;那么此时你只需要执行到Worker这个模式即可。因为
Worker是真正执行Playbook/Role的阶段,但这一点也需要大家额外关注。因为这个模式执行过后,Ansible就已经真正对生产环境服务进行了操作。如果脚本执行出现了问题,那么此时此刻就已经开始对生产环境产生了影响。笔者强调这点的原因是想提醒大家,对于Ansible Runner远程任务执行功能的风险控制从这一步就要开始警惕,例如相应的代码异常捕获以及马上执行后续的Process模式以来检查脚本的执行情况等等。毕竟作为运维人员,生产环境的稳定永远是重中之重。
4.3 Process
该部分主要用于接收二进制序列化的脚本执行结果,并对执行结果进行分析,最后输出分析结果。 Python示例代码如下:
private_data_dir = os.path.abspath(os.path.join(os.path.dirname(__file__), "..", 'ansible-runner/process')) # 指定Ansible Runner的数据目录
# 清空process目录
if os.path.exists(private_data_dir):
shutil.rmtree(private_data_dir)
with open(worker_output_file, "rb+") as worker_output: # 注意序列化结果为二进制流
processor = ansible_runner.run(
private_data_dir=private_data_dir,
streamer='process', # 需要指定执行模式
_input=worker_output, # 传入保存了执行结果文件的file对象实例
finished_callback=finished_callback, # 配置回调方法
status_handler=status_handler, # 配置handler方法
event_handler=event_handler, # 配置handler方法
)
print("{}: {}".format(processor.status, processor.rc)) # 输出执行状态和执行状态码(shell执行结果码)
需要注意的是,Process模式实际上只是对Worker模式的产出的数据进行了反序列化。在章节4.2曾提到过,Worker序列化的数据实际上就是artifacts目录中的数据。所以,Process模式执行完之后,会将反序列化后的数据放在其节点上的Ansible Runner数据目录内的artifacts目录中。此时,如果仅是需要了解Ansible执行成功与否,则只需通过获取Process模式返回的对象实例的status和rc属性即可;若需要进一步分析执行过程中的细节部分,则需要自行提取artifacts目录中的数据文件读取并解析。这里笔者给出一个简单的分析案例供大家参考:
def analyses_result_stats_from_artifact(
self,
artifacts_dir: str
) -> dict[str, Union(dict, list[bytes])]:
"""从结果文件中分析ansible执行结果的状态
该方法用于分析类型为playbook_on_stats的ansible runner event,
并且event数据是被保存在相关文件中的.
@param artifacts_dir: ansible runner的artifacts数据目录全路径
@type artifacts_dir: str
@return: 返回分析结果
其中,
key: playbook_stats为执行结果数据,类型为dict
key: problem_hosts为执行失败的主机信息,类型为list
@type: dict[str, Union(dict, list)]
"""
playbook_stats = None
problem_hosts = None
job_events_dir = os.path.join(artifacts_dir, 'job_events')
for root, dirs, files in os.walk(job_events_dir):
for file in files:
with open(os.path.join(root, file), "r") as job_event_file:
job_event = json.load(job_event_file)
if job_event['event'] == 'playbook_on_stats':
playbook_stats = job_event['event_data']
# 获取执行失败的机器
unreachable_hosts = set(job_event['event_data']['dark'].keys())
failed_hosts = set(job_event['event_data']['failures'].keys())
problem_hosts = list(unreachable_hosts | failed_hosts)
return {'playbook_stats': playbook_stats, 'problem_hosts': problem_hosts}
def analyses_successful_task_from_artifact(
self,
artifacts_dir: str
) -> Generator:
"""从结果文件中分析已成功完成的ansible task状态
该方法用于分析类型为runner_on_ok的ansible runner event,
并且event数据是被保存在相关文件中的.
@param artifacts_dir: ansible runner的artifacts数据目录全路径
@type artifacts_dir: str
@return: 该方法为一个迭代器;
将会逐个返回执行成功task的状态;
直到返回所有执行成功的task为止
@type: Generator
"""
job_events_dir = os.path.join(artifacts_dir, 'job_events')
for root, dirs, files in os.walk(job_events_dir):
for file in files:
with open(os.path.join(root, file), "r") as job_event_file:
job_event = json.load(job_event_file)
if job_event['event'] == 'runner_on_ok':
yield job_event['event_data']
Tips: 可以看出,Process模式分析的是Worker模式所产出的Ansible完整执行过程的序列化数据,即
Process模式依赖于Worker模式的输出。因此,若对于Ansible执行结果只有输出展示的需求时,是可以考虑使用同一节点来执行Worker模式与Process模式的;这样的好处在于能够减少一次传输序列化数据的步骤,从而提高效率。若有类似于需要保存Ansible执行结果的需求时,此时就需要考虑是否需要指定节点来运行Ansible Runner的Process模式了,因为未必所有的节点都能够与数据库或存储服务相通。
4.4 使用方式
上述这3种功能实际上为Ansible Runner的三种特殊执行模式,只需要在调用Ansible Runner时指定相应的参数即可开启特殊模式。这3个子功能需要配合使用,才能实现Ansible Runner提供的远程任务执行功能。因此,在正常情况下,Playbook/Role只需要部署在负责执行Transmit功能的Ansible Runner节点上即可。之后,通过其他方式将二进制序列化数据传递给负责执行Worker功能的Ansible Runner节点,并真正执行这些脚本。最后,将Worker输出的脚本执行结果序列化数据通过其他方式传递给Process功能节点,以来分析输出Playbook/Role的执行结果。
通过Ansible Runner的远程任务执行功能,可将Ansible的准备执行、执行以及结果分析这些功能进行解耦。这样的好处在于,可以进行脚本的统一管理、可以只为执行节点进行重点的安全加固、并且可以统一处理(例如保存)脚本执行结果等等。这项功能使我们对于Ansible的配置以及其衍产物有了更灵活的管理和运用思路。
Tips: Ansible Runner所提供的远程任务执行功能,可以使我们可以使用分布式系统的思路来处理有关Ansible操作的需求。笔者在这里提供一个自身亲身实现的案例,以来给大家提供一些思路:
可以
利用Celery和Ansible Runner可实现一种支持分布式操作的Ansible调用平台。其中,在Celery Client中实现Ansible Runner的Transmit模式的相关逻辑,并将产出的序列化数据作为Celery Task的参数传入Celery Broker中;随后,在Celery Worker中实现Ansible Runner的Worker模式与Process模式的相关逻辑,所需的序列化数据从Celery Broker中获取,并在Celery Worker中完成对Playbook/Role的执行和结果分析。通过引入Celery,可以使此架构能够支持让多个服务器集群并行处理Ansible的操作需求。往往在生产环境中,同一类服务可能会部署在多个区域中;对于这些服务的Ansible操作相同的,对于这种需求,就可以使用上述这种框架来实现快速并行的对多个集群的同一类服务进行并行操作变更。其次,在了解了每一种模式的工作原理后可以得知,每一种模式对于所在的Ansible执行节点的需求是不同的,这个时候我们就可以
根据这些特点为每一类Ansible Runner执行节点进行不同的权限以及安全加固控制。大多数情况下,Transmit模式往往会运行在一些内部平台/服务的节点上,因为这些平台/服务主要是下发Ansible任务,而非具体去执行Ansible操作;其次,运行Worker模式的节点往往需要和集群内的大多数服务器进行连通,此时就可以针对每一个运行了Worker模式的节点进行特定的权限控制,使其只能访问特定集群的服务器;对于运行Process模式的节点,一般情况下可能需要将Ansible的执行结果保存到数据库中,此时就可以只为这类节点配置数据库的点对点访问权限等安全措施。如果不使用Ansible Runner去实现上述的类似需求时,可能就会集中对一台(或某几台)服务器进行上述的安全加固配置,这可能会到导致某些Ansible节点的权限过大,从而造成安全隐患。
总结
在Ansible的官方文档中写到过: “如果仅是需要通过脚本方式或自动化方式去调用Ansible,则推荐使用Ansible Runner来实现这一需求”。这也就代表着Ansible Runner这个项目是获得了Ansible的官方认可。笔者也经过亲自实战体会了Ansible Runner的优势。使用Ansible Runner调用Ansible,能够让我们更加容易的使用代码和Ansible进行交互,而且还无需担心Ansible版本升级后带来的代码反向依赖问题。Ansible Runner帮助我们将自研项目与Ansible之间实现了很好的解耦。Ansible Runner提供的远程任务执行功能让我们可以以更加灵活的方式去调度Ansible。Ansible Runner本身的学习成本也不是很高,项目中的大部分概念都与Ansible相同,其提供的API也简单易懂,非常容易上手。希望Ansible Runner能够帮助大家更好的将Ansible功能融入到自研服务/平台中。