今天我们了解下MySQL数据库中的索引和最基础的事务是什么吧。注意:本次的索引会作为主要讲解部分,事务会分两部分讲解;希望大家在看本文章前先看完我之前的MySQL数据基础知识整理。
索引
索引:是一种用于快速查找数据库中特定数据的数据结构。它类似于书籍的目录,可以帮助我们在大量数据中快速定位到所需的信息。在数据库中,索引通常是在一个或多个列上创建的数据结构,它们存储了这些列中的值及其对应的行位置。当我们查询这个列时,数据库可以使用索引来快速定位到特定的行,而不必扫描整个表。这可以大大提高查询效率和性能。
简而言之,索引就相当于数据库中的目录,目录中包含了查询依据的简要信息,可以一次看到更多的目录信息。因此可以提高过滤效率得到最终地址,进而找到详细的信息。
下面,我来给大家介绍我们常用的索引操作:创建索引,查看索引信息,删除索引信息,修改索引。
创建索引
一般的,我们创建索引有三种方法:
- 当我们创建一个主键,外键或者唯一键时,数据库会自动针对该字段创建索引
- 在创建表格时,使用关键字index对字段进行普通索引声明
- 当我们需要添加索引时,可以给指定字段使用关键字index添加索引
下面我们来用简单的示例体会一下:
//使用关键字index进行普通索引声明
create table test(id int,index(id));
当我们需要为表格的指定字段添加索引,加快查询效率时,可以用以下指令:
alter table test add index idx_n(id);这里我想大家会有种疑惑,这里的idx_n是什么意思?作用是什么?下面我给大家讲解一下:在添加索引时,通常会为每个文档分配一个唯一标识符,称为“文档ID”。而idx_n是指第n个文档的文档ID,它在添加索引时用于确定每个文档的唯一标识符。具体来说,当我们为文档添加索引时,我们需要将文档的内容转换为一组特征向量,并将这些特征向量存储在倒排索引中。而为了能够在查询时快速地查找相关的文档,我们需要将每个文档的文档ID与其对应的特征向量关联起来。因此,idx_n在添加索引时的作用是为第n个文档分配一个唯一的文档ID,以便在查询时能够快速地找到对应的文档。这下大家就很好理解了吧,就是为我们需要添加到索引给出唯一标识符,其中的n就是索引的序号。
索引的查看
我们可以通过两种关键字查看一张表中的索引信息,一个是index,另一个是keys,我们来看指令:
show index from test;
show keys from test;得到如下查询结果:

其实keys和index关键字还是存在一些区别的:
- index是一种特殊的数据结构,它可以帮助数据库管理系统快速地定位和访问表中的数据。index可以提高查询效率,加快数据检索速度。
- keys是指在表中某一列上建立的索引。如果在某一列上建立了index,则这个列就被称为keys。
所以我们可以笼统地认为,index就是索引的广义概念,keys就是索引的具体概念。
删除索引
删除不需要的索引操作也是很简单的,我们可以使用关键字drop index删除不需要的索引,指令如下:
alter table test drop index idx_n;//这样我们就删除了当时添加的索引了那么,我们为什么需要删除索引呢?
其实,我们不难看出,索引的强大,就在于它可以将很多数据的关系在内部串连起来,这样就可以根据一种特点快速找到我们所需要的数据。但同时,假如我们需要删除某个文档,或需要手动更新一些数据关系来加快索引的查询效率,这时,旧的索引很可能就成为了负担。当一个文档被删除或更新时,它的索引也需要相应地更新,以确保搜索结果的准确性和一致性。此外,索引是一种非常典型的以空间换取时间的操作,底层维护索引也会消耗大量的空间;若我们不需要该字段的索引时,最好还是及时删除,这样也可以提高我们的搜索效率。
InnoDB存储引擎
接下来让我们简单了解下,MySQL数据库默认的存储引擎:InnoDB。
InnoDB采用的数据结构是B+树。B+树是一种平衡树,可以在O(log n)时间内进行插入、删除、查找等操作。InnoDB使用B+树来组织数据,数据按照主键值顺序存储,并且在叶子节点上存储完整的数据信息,包括主键和其他列的值。具体如下图:
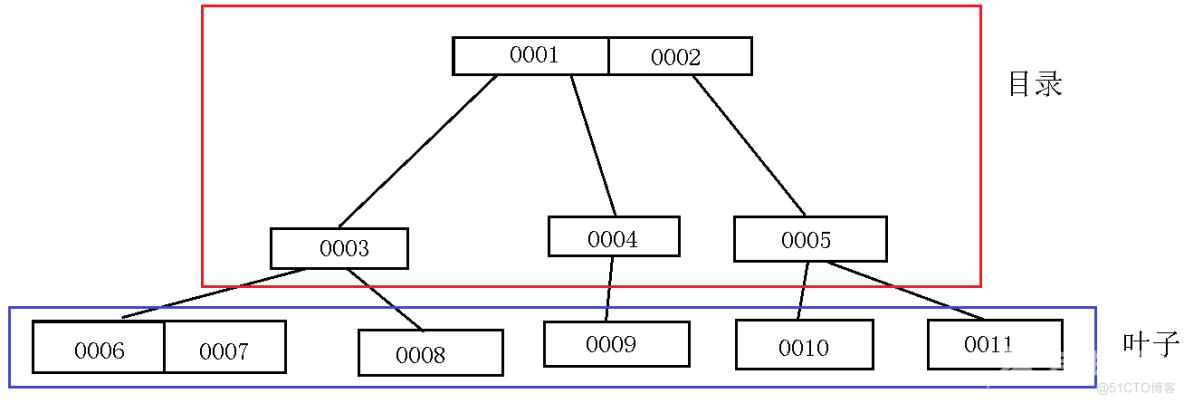
其中,目录中节点存储着索引的值和指向子节点的指针;叶子节点中存储着数据行的主键值和指向数据页的指针。当执行查询操作时,InnoDB会根据查询条件从主键索引B+树的根节点开始进行查找,先找到根节点上符合条件的索引记录,然后进入相应的子节点继续查找,直到找到叶子节点。在叶子节点上,就可以直接获取相应的数据行。如果需要查找的数据行不在主键B+树上,那么InnoDB还会根据辅助索引B+树的结构,找到相应的主键值,再到主键B+树上查找相应的数据行。
由于InnoDB存储引擎具有更好的性能和可靠性,因此被广泛的高并发,重要的业务场景。
索引的使用方式
索引有两种使用方式:聚簇索引和非聚簇索引
聚簇索引
聚簇索引是将数据行按照索引列的值进行排列,物理结构上相邻的行存储在一起,形成一个簇。因此,每张表上只能有一个聚簇索引。
聚簇索引具有很明显的优点:大大提高查询效率。因为数据按照索引列的值排序,同一范围内的数据存储在相邻的物理块中,如果查询条件符合这个范围,则只需要扫描少量的物理块即可找到需要的数据。
由于聚簇索引是使物理地址相邻的数据聚集成一个簇,因此在数据的更新上,会对整个数据进行移动,更新代价比较大。
此外,在聚簇索引中还有一个基于其的索引:辅助索引。
非聚簇索引
辅助索引,又称非聚簇索引。辅助索引并不会按照数据表中的某一列的值进行排序,而是按照辅助索引关联的列的值进行排序和存储的。因此,辅助索引的索引和数据是分离存储的。简单来说,辅助索引的叶子节点中存储的是数据的地址。
辅助索引的优势也是可以提高数据表的查询速度。当查询条件与辅助索引锁关联的列有关时,数据库可以使用辅助索引进行快速定位记录,从而加快查询速度。同时,辅助索引也能加快数据的更新,在插入和删除数据时,更新辅助索引的花销会更低,这样更新的速度也会更快。
但是我们需要主要,在为某列创建辅助索引时,数据库会根据该列的值建立一个索引表,该表中保存了该列值与对应行的指针或者副本,该表存储在磁盘空间中。因此,创建辅助所以会占用一定的磁盘空间。
综上所述,聚簇索引和非聚簇索引各有千秋,那么我们该在什么条件下使用这些索引呢??
简单来说,当我们需要对数据尽心频繁的更新时,使用非聚簇索引;当我们需要快速查询数据时,使用聚簇索引。理由其实在上述的优缺点已经讲得很明了了。
最后,我们在来看下创建索引的原则:
- 频繁用于作为查询依赖条件的字段适合创建索引
- 唯一性较差的字段不适合创建索引
- 频繁修改的字段不适合创建索引
- 索引的创建并不是越多越好,因此,不作为查询条件的字段就不要创建索引了
事务
事务:我们可以将其看成是一组操作,事务保证这组操作要么全部执行,要么全部不执行。事务通常用于确保数据库中数据的完整性和一致性。
事务拥有四大特征,即:ACID
- 原子性(Atomicity):一个事务是一个不可分割的操作单位,即事务中的所有操作要么全部完成,要么全部不完成。
- 一致性(Consistency):事务执行前后,数据库中的数据应该保持一致。即数据库完整性不会被破坏,符合所有预设规则。
- 隔离性(Isolation):多个事务并发执行时,每个事务都应该与其他事务隔离开来,以防止数据互相干扰。
- 持久性(Durability):事务执行成功后,其结果应该被永久保存在数据库中,即使系统崩溃也不会丢失。
这里我们给出一些事务的简单操作,由于比较好理解,就没有示例了,大家下去可以手动尝试:
//1.开始事务
begin;
start transaction;
//2.提交事务
commit;
//3.保存事务节点,就是回滚事务时返回到该节点
savepoint point_name;
//4.回滚事务,相当于回到开始或者point_name处的状态
rollback;/rollback point_name事务的保护机制:
- 一旦事务在操作中,客户端出现异常,为了维护原子性,这时数据库就会自动进行回滚。
- 一旦事务被提交,这时数据的修改就是永久性的。
以上就是本次的全被内容了,事务方面的讲解并没有结束,下次我们回继续从事务方面开始讲解有关MySQL数据库的相关知识。
【本文来自:美国大带宽服务器 http://www.558idc.com/mg.html提供,感恩】