今天我们来介绍下表中的键值约束和表的设计,这里面,表的设计比较绕,需要大家下来多多思考才可能完全掌握。
键值约束
我们先来看定义:
键值约束是指在数据库中对某个表格的一列或多列设置了唯一性约束,这些列被视为该表格的“键”,不能出现重复值。这意味着在插入、修改或删除数据时,系统会自动检查这些“键”列的值是否已经存在,如果已经存在,则会拒绝该操作。键值约束可以保证数据库中某些数据的唯一性和一致性,避免了数据冗余和重复的问题。常见的键值约束包括主键约束和唯一性约束。
简单地说,键值约束就是将表中的一列或者一组列用关键字primary key修饰,保证该列或该组列的唯一性。主要作用也很简单,就是保证我们的数据具有一致性,完整性和唯一性。
在表的设计中,常用的键值约束有:主键约束,唯一键约束和外键约束。下来,我就一一给大家介绍三个约束。
主键约束
主键约束:在创建表时,给定表中指定字段设置一列或多列的内容约束,约束表中的数据值唯一且不能为空,被约束的数据列称为主键,每张表中只能有一个主键。
关键字:primary key
作用:主键约束可以帮助我们维护表中数据的完整性和一致性,使得每条数据都可以被唯一的识别和访问。
下面给出代码示例:
//创建一个test表
create table if not exists test(sn int primary key,name varchar(32));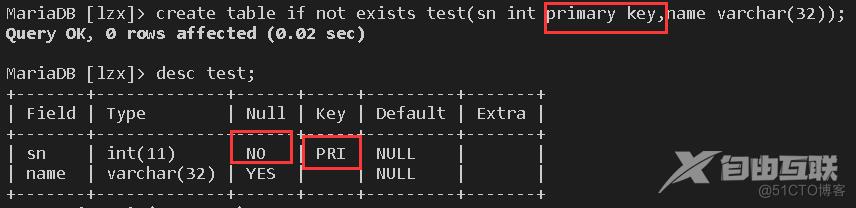
我们在设单独字段为主键时就可以直接在后面跟关键字可以创建,在我们查看表结构时,就会发现,能否为空字段显示不能为空,且关键字上位PRI表示以设为主键。
当我们将多个字段设置为主键时,也可以用以下指令:
create table if not exists test(sn int,name varchar(32),primary key pk(sn,name));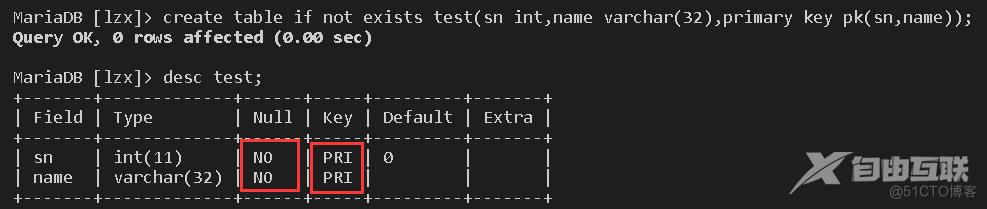
这时就表示该组合为一个主键字段,具有唯一性,要判断唯一性时,需要以一个组合为单位判断。
唯一键约束
唯一键约束:是为了确保表中某列或某组列的数据值是唯一的,这意味着表中的唯一键约束列数据必须是不重复的,在某些场景下,数据的唯一非常关键,这时,我们就可以将数据设置为唯一键约束。
关键字:unique key
作用:保证约束字段内容的唯一性。
下面给出示例:
//还是创建一个表格,两行代码,第一行是单列的唯一键约束,第二列是组合列的唯一键约束
create table if not exists test(sn int unique key,name varchar(32));
create table if not exists test(sn int,name varchar(32),unique key pk(sn,name));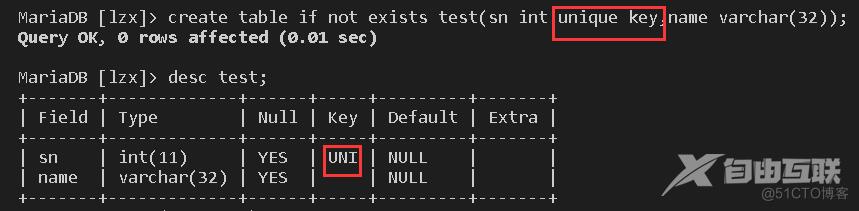
如果我们这时输入数据与约束字段冲突,就会报错,如下所示:
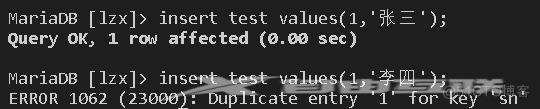
这里需要注意:如果我们将组列看成是一个约束,那么在输入数据时,必须是整个组数据相同才能触发输入异常,若其中一个数据不同,但其它数据相同,则也会正常输入,例如:
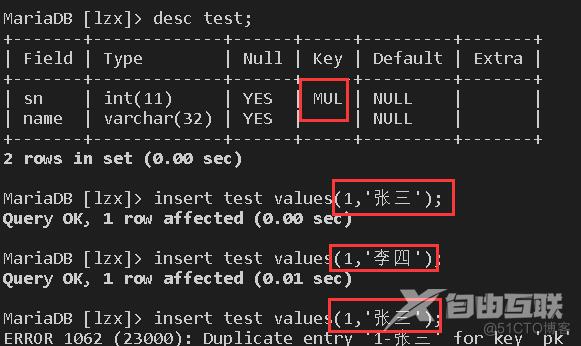
最后,我们还能从表中结构看出,唯一键约束只能约束数据唯一,并不能限制数据是否为空,因为在MySQL数据库中,空值并不具备唯一性判断,因此唯一性字段中可以有多个空值。
非空约束
非空约束:这个就比较好理解了,就是声明该字段不能为空
关键字:not null
指令如下:
create table if not exists test(sn int not null,name varchar(32));外键约束
外键约束:该约束主要是为了绑定不同表中两个指定字段一定存在某种关系,具体点来说,就是确保一个表中的字段一定匹配另一个表中的主键或者唯一键匹配。
作用:保证了数据的一致性和完整性。
- 一致性:外键约束可以限制表之间的关系,例如班级和学生表之间的关系,如果班级表中移除了某个班级,那个学生表中该班级的学生也会被移除。
- 完整性:外键约束可以防止在子表中插入无效的数据,我们在将数据学生表时,只能将该学生的班级id设为已存在的班级,否则插入失败。
指令:
foreign key fk(当前表字段) references 另一张表(字段)//表示另一张表的字段为当前表字段的外键约束使用示例如下:
//我们先创建一个班级表,这里我们需要规定id是主键,到时候方便设置为外键约束
create table class(id int primary key auto_increment,name varchar(32));
//然后我们在创建一个学生表,该学生的班级id就和班级表中的id关联
create table stu(sn int primary key auto_increment,name varchar(32),class_id int,foreign key fk(class_id) references class(id));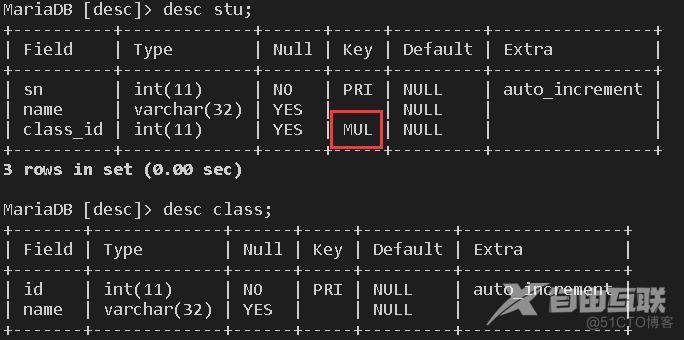
此时,就说明我们学生表的class_id和班级表的id关联了
附加属性
这里我们将两个常用的附加属性,其一是设置默认值,其二是设置扩展属性
默认值
这个很好理解嘛,就是给数据段设置一个默认属性,我们在输入数据时,如果某个数据有默认值,我们就可以输入空值,非常的好用。
关键字:default
指令如下:
//这里就是在设计表格时,给性别一个默认值,默认为男性
create table stu(sn int ,sex varchar(1) default '男');自增属性
设置自增属性,该功能只能针对数字,当我们需要加入一个数据时,可以将它的序号设置为空值,这样该值的序号就是该表中最大序号的下一个数字。
设置条件:该数字段必须为主键或者唯一键;设置字段必须为整数
关键字:auto_increment
指令如下:
//将学生表中的序号设置为自增属性
create table student(sn int primary key auto_increment,name varchar(32));表的设计
这里表的设计并不是指设计单独表,而是指表与表之间的关系。
首先我们来通过ER关系图,想象的看下表与表之间能有什么关系??
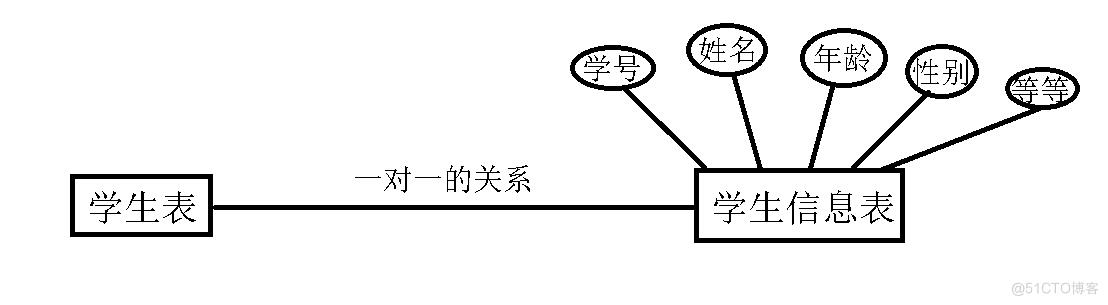
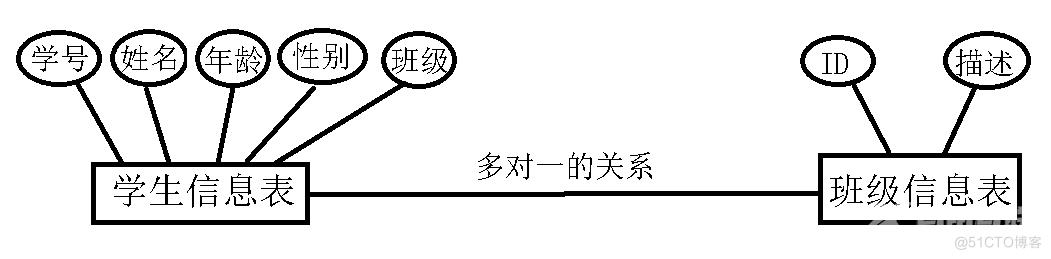

表中,总共有四种关系,我上图只画了三种,第四种就是第二幅图反着的关系,我们从学生的角度看就是多对一的关系,从班级来看就是一对多的关系。为了能更好的在表示表和表之间的关系,防止出现一些不必要的内存消耗和繁琐的操纵,我们规定了三大范式来规范创建表的关系。
三大范式
三大范式,作为关系型数据库设计的基本原则,帮助优化数据库,提高数据库的存储和查询效率,避免操作时出现的错误和不一致性。
第一范式(1NF):要求每个属性都是原子性的,不可分割的。即每个属性都只有一个值,不允许出现多值属性和重复的属性。例如:

第二范式(2NF):要求非主键属性必须完全依赖主键,也就是说一个表中不能存在部份依赖,如果存在部份依赖,需要将其拆分成多个表。例如:

第三范式(3NF):要求非主键属性之间不能存在传递依赖,也就是说一个表中不能存在传递依赖关系,如果存在,就需要拆分成多个表。例如:学生信息表和教师信息表之间,学生表中可以有老师,但不能有老师信息,老师的信息对于学生而言就是一种传递依赖关系。
对于上述提到的三大范式,都是对数据库的优化,因此我们给出明确的作用总结。
首先是第一范式:确保每个数据表中每个字段都是原子性的,即不可再分的,这样可以消除冗余数据,减少数据的存储空间,并且避免操作数据时产生错误。
接下来是第二范式:确保数据表中每个非主键自读那完全依赖于主键,而不是依赖主键的一部分,这样可以消除冗余数据,避免数据更新时出现不一致的情况,并且还能提高查询数据的效率。
最后是第三范式:确保每个数据表中的每个非主键字段都不依赖于其他非主键字段。这样可以进一步消除冗余数据,较少数据的存储空间,并且避免操作舒适产生错误。
总的来说,三大范式都是在帮助优化数据库的设计,提高数据的存储效率和查询效率,并且避免数据操作时可能产生的错误和不一致性问题。