一、为什么使用Redis Cluster集群
这里就要说到Redis集群的演变过程
1. 主从复制
工作模式为提供多台redis服务,选择其中的一台作为master节点向外提供读写服务,剩下的作为slave节点从master节点复制数据,只向外提供读服务。缺点在于,没能实现redis状态监控即故障自动切换。当主服务器宕机后,需要手动把一台服务器切换为主服务器,会造成一段时间内服务不可用;存储能力受单机限制;master不能动态扩容。
2. 哨兵
哨兵模式可以实现对redis节点的监控和master的自动故障转移。但仍然存在一些缺点。由于只有一台master提供写服务。当写操作并发量很大时,无法缓解写操作的压力;此外master不能动态扩容。针对这种场景,Redis在3.0版本中引入了Redis Cluster集群。
二、Redis Cluster简介
Redis Cluster集群是一个提供在多个Redis节点之间共享数据的程序集。由多个master节点提供写服务,每个master节点中存储的数据都不一样,这些数据通过数据分片的方式被自动分割到不同的master节点上。
为了保证集群的高可用,每个master节点下面还需要添加至少1个slave节点,这样当某个master节点发生故障后,可以从它的slave节点中选举一个作为新的master节点继续提供服务。不过当某个master节点和它下面所有的slave节点都发生故障时,整个集群就不可用了。基本架构图如下:
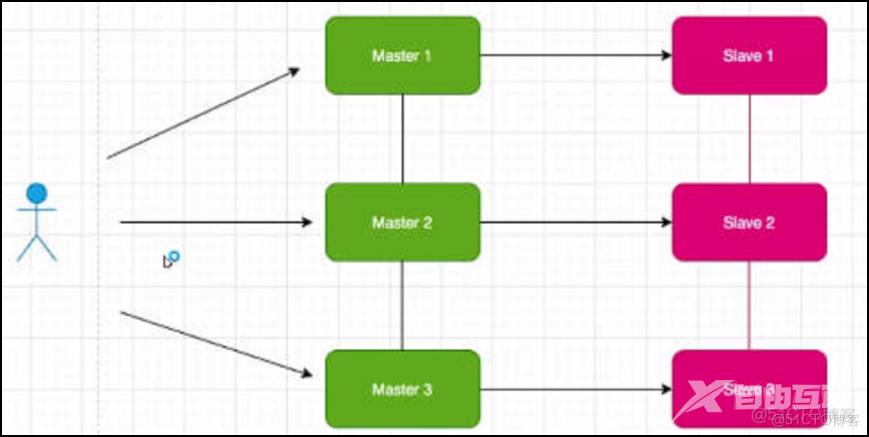
三、Redis Cluster集群的工作原理
3.1 哈希槽分区
这里就需要提到哈希槽这个概念。
Redis Cluster集群有16384个哈希槽,每个key通过CRC16校验后对16384取模来决定放在哪个槽。集群的每个master节点负责一部分hash槽。比如当前集群有3个master节点,则:
- master1节点包含0~5460号哈希槽
- master2节点包含5461~10922号哈希槽
- master3节点包含10923~16383号哈希槽
当需要redis集群存放一个数据(key-value)时,redis会先对这个key进行CRC16算法,将得到的结果对16384进行取余,这个余数会对应到(0~16383)其中一个槽,进而决定key-value存储在哪个节点中。
3.2 集群通信
寻找槽的过程并非一次就能精准命中的。比如某个key经取余计算要放到11000号槽位,但并不是一下就找到master3节点,可能先去访问master1、master2节点,再找到master3节点。
集群中的每个节点都保存了其它节点的信息,包括当前集群状态、集群中各节点负责的哈希槽、集群中各节点的master-slave状态、集群中各节点的存活状态等。这样即使第一次访问未能命中槽,也会告知客户端该槽位在哪个节点。
四、环境准备
准备八台机器,ip地址分别为192.168.8.105~112(主机名分别为node1~node8),其中192.168.8.111、192.168.8.112做Redis Cluster集群扩容&缩容使用,另外六台机器做Redis Cluster集群。用编译安装的方式部署6.2.x版本的redis。
五、搭建Redis Cluster集群
5.1 启用Redis Cluster配置
192.168.8.105~110六台机器需做redis.conf的如下配置(有注释的取消注释):
bind 0.0.0.0
dir "xxxxxxx" #快照文件保存路径
masterauth xxx #建议配置,否则后期的主从复制不能成功
requirepass xxx
cluster-enabled yes #开启集群模式,普通模式不能加入Redis Cluster集群。开启后进程会有cluster标识
cluster-config-file nodes-6379.conf #此为集群状态数据文件,记录主从关系和哈希槽范围信息,由Redis Cluster集群自动创建和维护
cluster-require-full-coverage no #默认为yes,设为no可以防止一个节点不可用导致整个Redis Cluster集群不可用
之后启动Redis
5.2 创建Redis Cluster集群
在任意一台机器执行如下命令:
redis-cli -a xxxxxx --cluster
create 192.168.8.105:6379 192.168.8.106:6379 192.168.8.107:6379
192.168.8.108:6379 192.168.8.109:6379 192.168.8.110:6379 --cluster-replicas 1
#命令redis-cli --cluster的选项--cluster-replicas是指定每个主节点的从节点个数
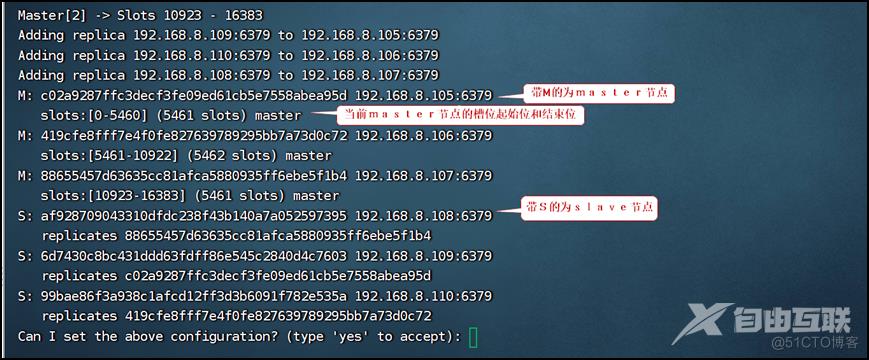
输入yes自动创建集群,确认已经分配的主从关系和各个master节点管理的槽位范围
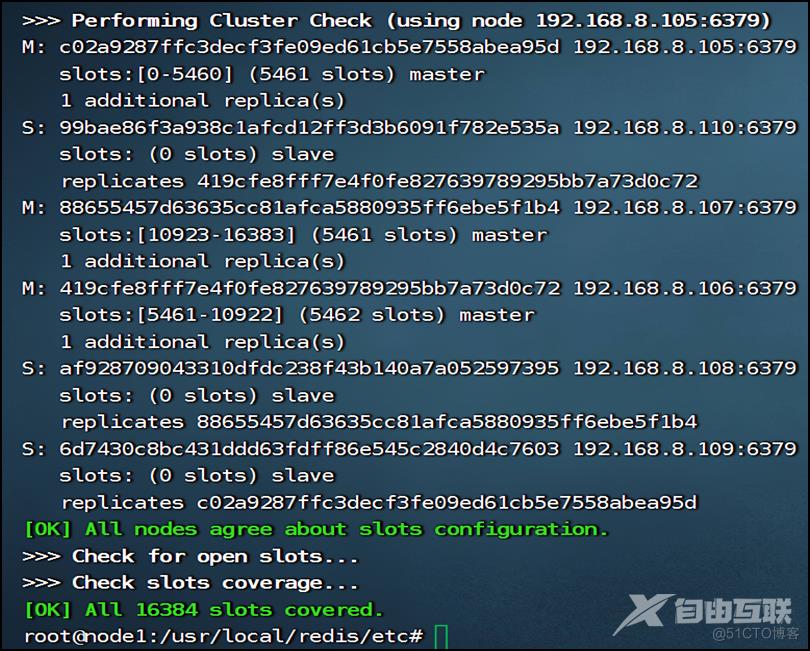
这样Redis Cluster集群就创建成功了。
可以用redis-cli -a xxxxxx --cluster check ip:port命令或redis-cli –a xxxxxx cluster info命令查看Redis Cluster集群状态,用redis-cli –a xxxxxx cluster nodes查看主从对应关系&槽位分配情况
5.3 测试Redis Cluster集群读写数据
先随便进入一个master节点写数据,发现不能写入:

再到对应的master节点去写数据就正常了。但是读数据也是在相关的master节点,对应的slave节点也无法执行get k1命令,只能用keys *命令查看。此时可以发现,slave节点仅用来存数据,读写操作都做不了。

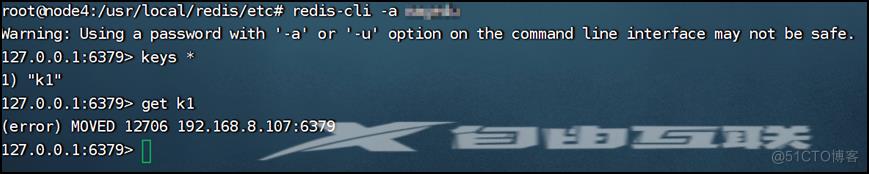
但是用redis-cli -a xxxxxx -c(-c参数用于集群模式)可以实现自动重定向,随便进入一个master节点写数据都可以,数据可以重定向到其它master节点

5.4 测试Redis Cluster集群的高可用
此时的主从关系如下:
Master
Slave
192.168.8.105(node1)
192.168.8.109(node5)
192.168.8.106(node2)
192.168.8.110(node6)
192.168.8.107(node3)
192.168.8.108(node4)
将192.168.8.105的redis服务停掉,之后由192.168.8.109提升为新的主节点(见下图):
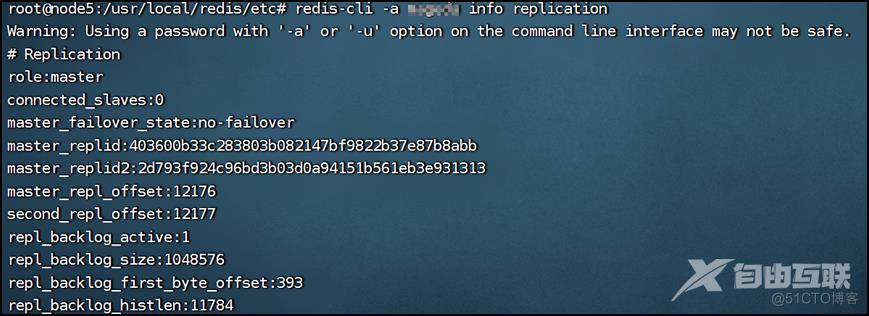
通过查看集群状态数据文件nodes-6379.conf也能看到192.168.8.105的redis服务异常,192.168.8.109提升为新的master节点。现由109机器代替105机器提供读写服务

即使重启105机器的redis,该机器也变成了109机器的从节点
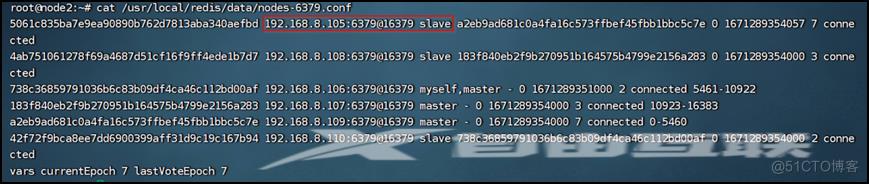
注意:如果是105和109机器或107和108机器或106和110机器(对应的主从关系的机器)的redis同时挂掉,则它们存的数据就不能访问。如果有设置了RDB持久化,则在重启redis后可以从rdb文件重新加载数据,但是在生产环境这样也会丢失一部分数据
六、Redis Cluster集群管理
6.1 扩容
6.1.1 应用场景
在客户访问量激增的情况下,已有的Redis Cluster集群很难满足越来越高的并发访问请求。为解决此问题,就新增两台机器,把它们动态添加到现有的Redis Cluster集群,且不影响业务的正常访问。简单的说就是新加n组主从到集群中。
注意:生产环境建议master节点为奇数个(eg:3,5),以防发生脑裂现象
6.1.2 准备工作
为192.168.8.111和192.168.8.112两台机器部署redis,配置文件与其它六台机器的相同,之后启动redis。
6.1.3 添加新的master节点到集群
这里把192.168.8.111作为新的master节点。在111机器执行如下命令:
redis-cli -a xxxxxx --cluster
add-node 192.168.8.111:6379 192.168.8.106:6379
#这里包括以下示例中的192.168.8.106为已有Redis Cluster集群的任意节点
执行效果如下:
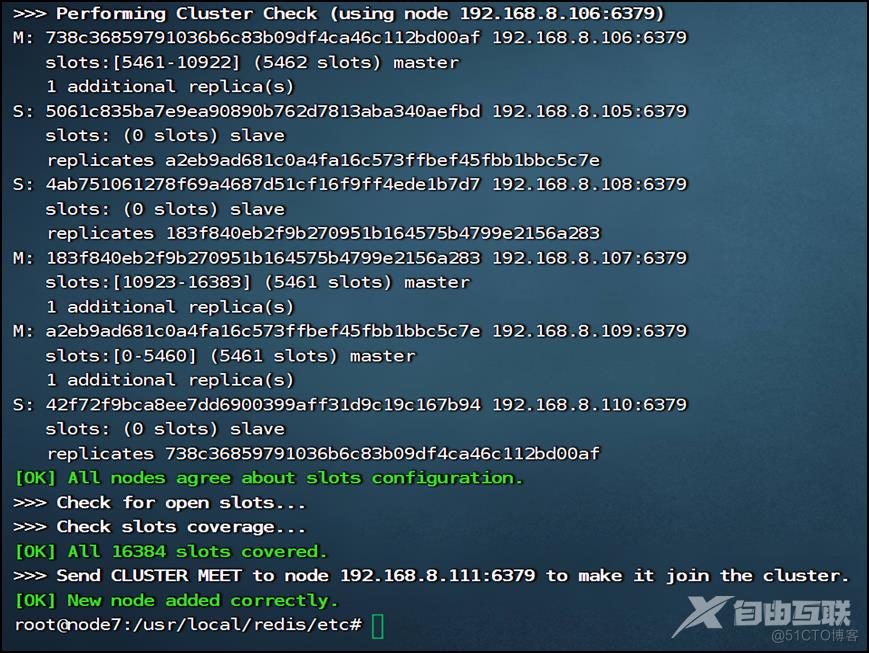
此时可以看到,虽然111机器作为新的master加入了Redis Cluster集群,但没有槽位,后续需要分配。

6.1.4 为新的master节点重新分配槽位
在任意一个master节点执行如下命令:
redis-cli -a xxxxxx --cluster reshard 192.168.8.106:6379
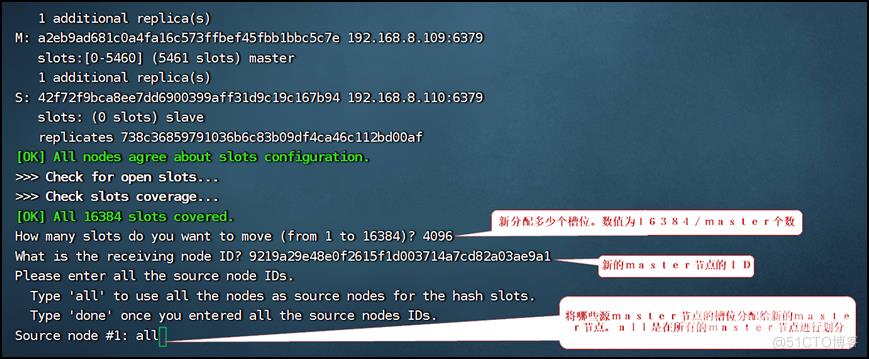
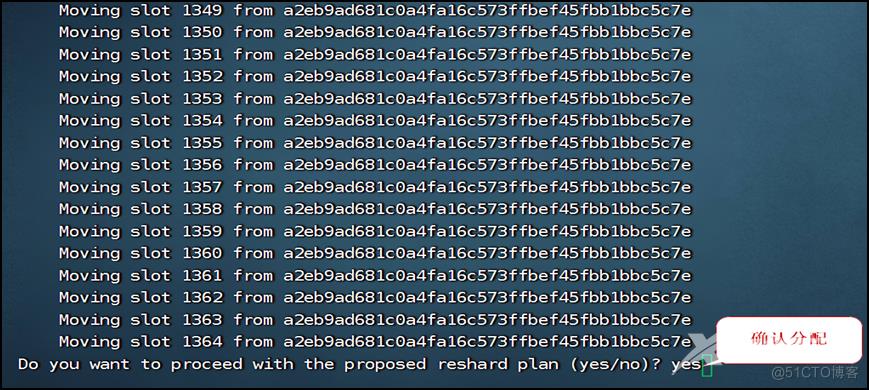
这样就完成分配槽位了。再确认一下槽位是否分配成功:
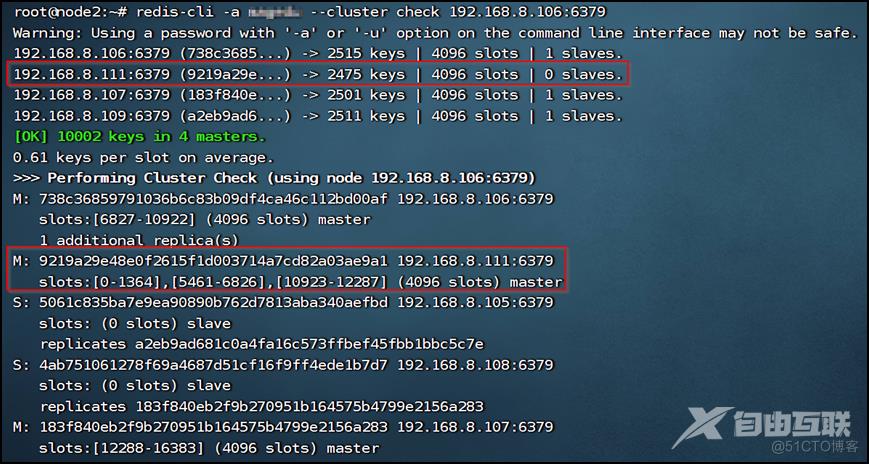
此时可以看到,新的master节点槽位已经分配成功,但没有配置从节点,存在高可用隐患。
6.1.5 为新的master节点指定slave节点实现高可用
将192.168.8.112作为192.168.8.111机器的从节点。在112机器执行如下命令:
redis-cli -a magedu --cluster
add-node 192.168.8.112:6379 192.168.8.106:6379 --cluster-slave
--cluster-master-id 9219a29e48e0f2615f1d003714a7cd82a03ae9a1
验证。如果是8个节点,4组主从说明扩容成功:
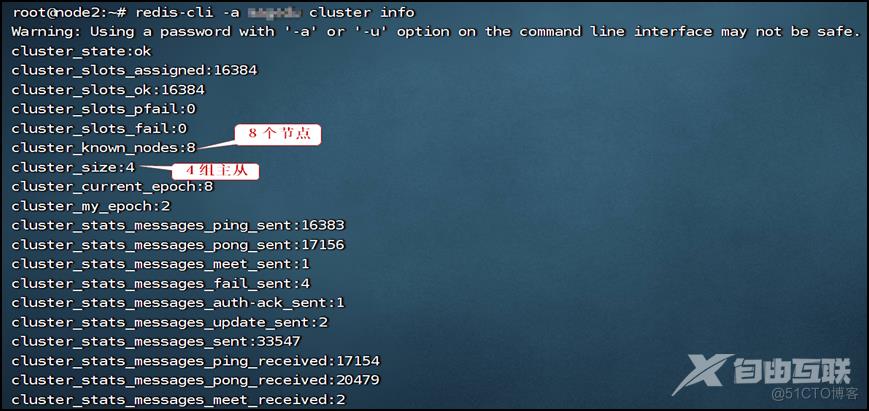
此时192.168.8.112就是192.168.8.111的从节点
6.2 缩容
6.2.1 应用场景
随着业务量缩水,用户访问量明显下降,业务组经与领导商量后决定将现有Redis Cluster集群的8台机器下线2台。缩容后仍能满足当前业务需求。
6.2.2 删除节点的过程
扩容是先添加机器到集群,再分配槽位。而缩容与之相反,是先将要下线的机器的槽位迁移到集群中的其它机器,然后才能下线机器。如果一个机器上的槽位未完全转移干净,删除该机器时会提示数据出错导致无法删除。
6.2.3 迁移要删除的master节点的槽位到其它master节点
这里仍然用192.168.8.111和192.168.8.112进行操作。
此时主从关系如下:
Master
Slave
192.168.8.109(node5)
192.168.8.105(node1)
192.168.8.106(node2)
192.168.8.110(node6)
192.168.8.107(node3)
192.168.8.108(node4)
192.168.8.111(node7)
192.168.8.112(node8)
根据之前的扩容操作(见相关截图),先把0~1364号槽位移到109机器。在集群任意一个节点执行如下命令:
redis-cli -a magedu --cluster reshard 192.168.8.106:6379
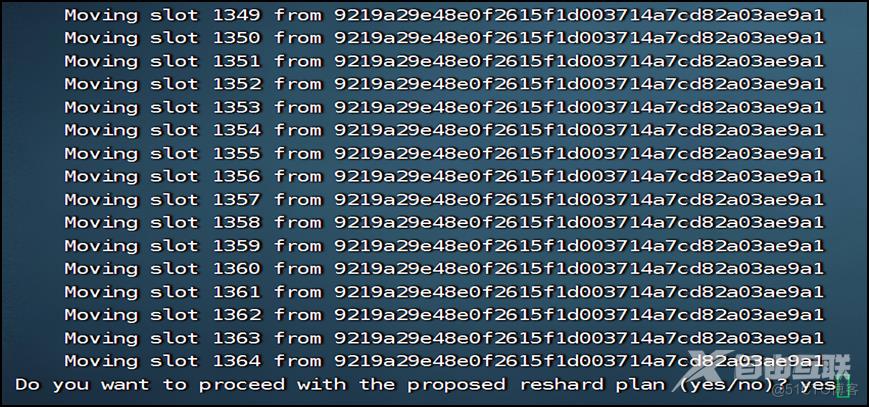
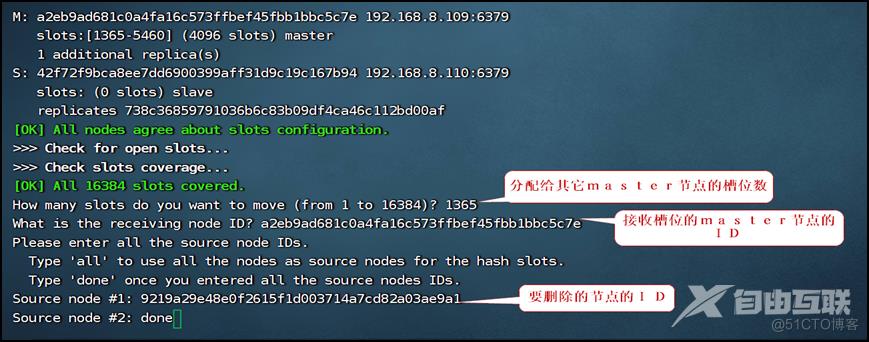
再把5461~6826号槽位移到106机器,把10923~12287号槽位移到107机器。这样111机器就没有槽位了。由于112机器一开始作为111机器的从节点,无槽位,因此后续可直接执行删除机器的操作。
6.2.4 从集群中删除机器
在集群中任意一个节点执行如下命令:
#删除111机器
redis-cli -a magedu --cluster
del-node 192.168.8.106:6379 9219a29e48e0f2615f1d003714a7cd82a03ae9a1
#删除112机器
redis-cli -a magedu --cluster
del-node 192.168.8.106:6379 4f6306221bb9afa5ff38ea9e9df85199575b22fd
此时再次查看就发现111和112机器被踢出集群了:
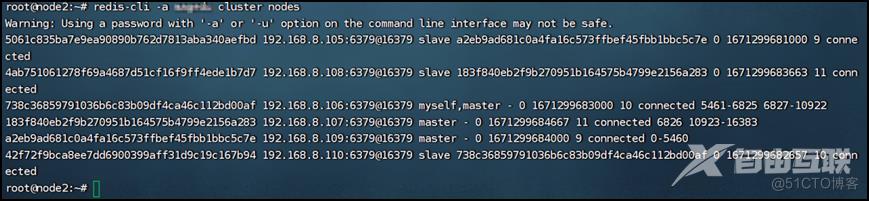
6.3 集群倾斜
Redis Cluster集群的多个节点运行了一段时间后可能会出现倾斜现象,某个节点数据偏多,内存消耗更大,或者访问更多。
发生倾斜的原因如下:
- 节点之间槽位分配不均
- 不同槽位对应的键值数量差异较大
- 内存相关配置不一致
- 包含bigkey
- 热点数据不均衡。有的数据访问量特别大,有的数据访问量特别小
相关操作包括:
#获取指定槽位对应的key个数。这里1000为槽位号
redis-cli -a xxxxxx cluster countkeysinslot 1000
#槽位重新平衡分布
redis-cli -a xxxxxx --cluster rebalance
192.168.8.106:6379
#获取bigkey
redis-cli -a xxxxxx --bigkeys
七、Redis Cluster集群的局限性
- 读写操作均由主节点完成,从节点仅做备用
- 主机数量多,造成维护成本较高
- 一些命令不能跨节点使用:mget、keys、scan等
- 不支持多个数据库,集群模式下只有1个数据库