
今天为大家带来的文章是Mobile3DRecon: Real-time Monocular 3D Reconstruction on a Mobile Phone。在手机上实现实时的单眼3D重建。
此文由浙江大学和商汤合作完成,在ISMAR2020 上获得BestPaper的研究。

本文展示了在手机上实现实时单眼3D重建的系统,称为Mobile3DRecon。该系统使用嵌入式单眼相机,在后端提供了在线网格生成功能,并在前端提供了实时6DoF姿势跟踪,以供用户在手机上实现具有真实感的AR效果。
与大多数现有的仅使用基于点云的3D模型在线生成技术或离线的表面网格生成技术不同,本文提供了一种全新的在线增量网格生成方法来实现快速的在线密集表面网格重建,以满足实时的AR应用需求。
对于6DoF跟踪的每个关键帧,本文使用多视图半全局匹配(SGM)的方法进行的单眼深度估计,然后进行深度细化处理。生成模块将每个估计的关键帧深度图融合到在线密集表面网格上,这对于实现逼真的AR效果(例如碰撞和遮挡等)。
本文在两个中距离移动平台上验证了实时重建的结果,通过定量和定性评估的实验证明了所提出的单眼3D重建系统的有效性。该系统可以处理虚拟物体与真实物体之间的遮挡和碰撞场景以实现逼真的AR效果。
一、背景与贡献
- 本文提出了以中多视图关键帧深度估计方法,该方法即使在具有一定姿态误差的无纹理区域中也可以鲁棒地估计密集深度,消除由姿势误差或无纹理区域引起的不可靠深度,并通过深度神经网络进一步优化了噪声深度。
- 本文提出了以中有效的增量网格生成方法,该方法可以融合估计的关键帧深度图以在线重建场景的表面网格,并逐步更新局部网格三角。这种增量网格方法不仅可以为前端的AR效果提供在线密集的3D表面重建,还可以确保将网格生成在后端CPU模块上的实时性能。这对于以前的在线3D重建系统来说是有难度的。
- 本文提出了带有单眼相机的实时密集表面网格重建管线,在手机上实现了单眼关键帧深度估计和增量网格更新的执行速度不超过后端的125ms/关键帧,在跟踪前端6DoF上快速到足以超过每秒25帧(FPS)。
二、算法流程
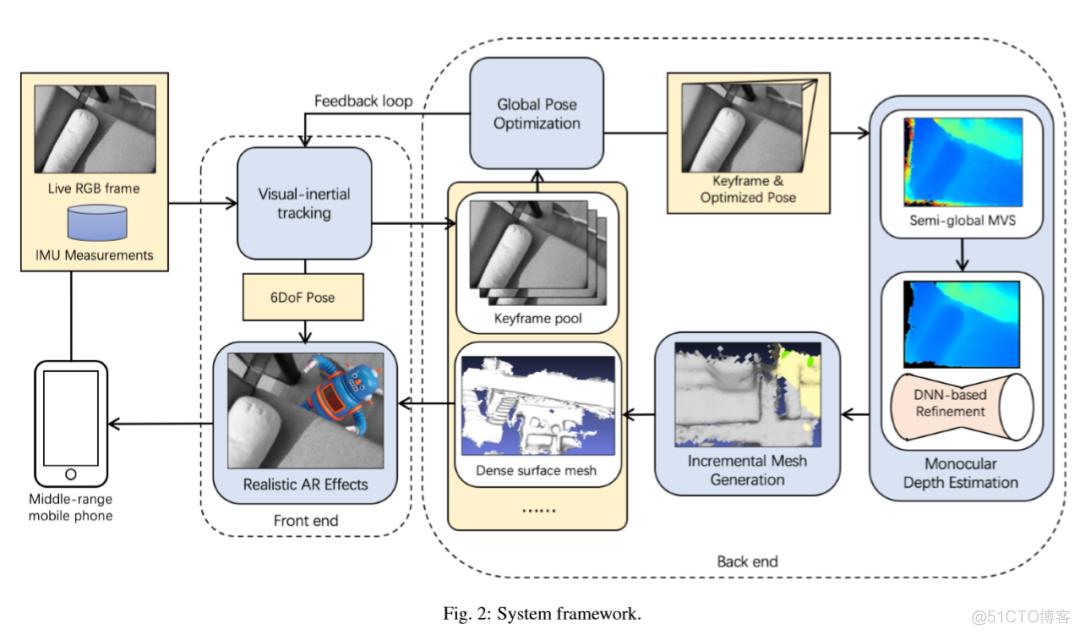
图1—系统简图
整个系统的处理图如图1所示,当用户使用手机上的单眼相机导航到他的环境时,本文提供的管道会使用基于关键帧的视觉惯性SLAM系统跟踪手机的6DoF姿势,该系统跟踪前端的6DoF的同时,也可以保证关键帧后端具有全局优化模块,以优化所有关键帧的姿势,并将其反馈给前端跟踪。本文在管道中使用了SenseAR SLAM进行姿势跟踪,并且任何基于关键帧的VIO或SLAM系统(例如谷歌的ARCore)目前都是适用的。
在前端正常初始化6DoF姿势跟踪之后,对于具有全局优化姿势的关键帧池中的最新传入关键帧,其密集深度图是通过多视图SGM在线估计的,其中先前的关键帧的一部分会被作为参考帧。卷积神经网络和多视图SGM被用来细化深度噪声,然后通过融合细化的关键帧深度图以生成周围环境的密集表面网格。这里的管道是用来执行增量在线网格生成,这更适合于手机平台上AR应用程序对实时3D重建的要求,深度估计和增量网格划分都作为后端模块进行。随着密集网格逐渐在后端被重建出来,高级别的AR应用程序可以使用这种实时的密集网格和6DoF SLAM的姿势为前端用户提供逼真的AR效果,比如遮挡和碰撞等。
1.单眼深度估计
单眼深度估计首先利用本文提出的多视图SGM方法进行立体匹配,然后基于置信图对深度信息进行滤波,最后利用深度学习细化深度信息。
立体匹配部分, 本文对深度空间的逆进行均匀采样,然后利用人口普查变换(CT)作为特征值描述子来计算补丁相似度(patch similarity)。这里通过查找表来计算两个人口普查位串之间的汉明距离,遍历每个带有标签I的切片的像素,来计算立体匹配的成本。之后,会得到的大小为W * H * L尺寸的成本量,其中W和H是框架的宽度和高度。然后汇总成本量,采用Winner-Take-All的策略获得初始深度图。
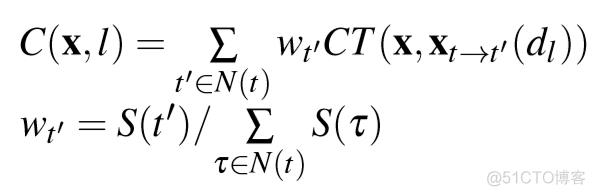
本文通过惩罚像素邻域的深度标记变化添加了额外的正则化来支持平滑度。对于带有标签l的图像像素x,成本的汇总是通过递归计算相邻方向的成本来完成的。
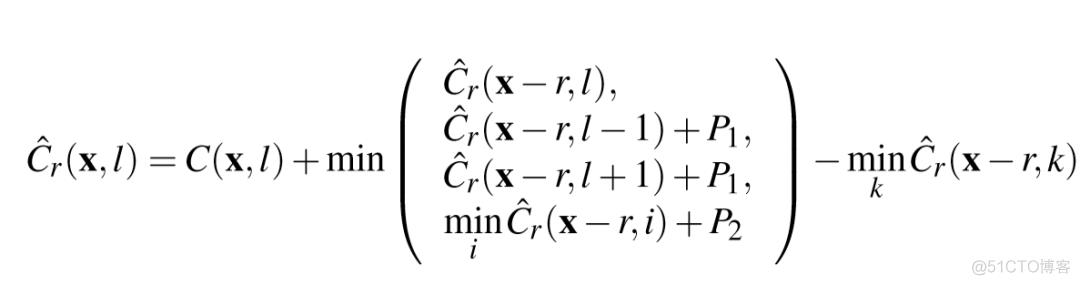
基于置信度的深度滤波利用SGM中的不确定度测量来计算置信度,同时也考虑了局部深度一致性。
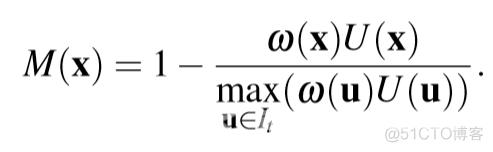
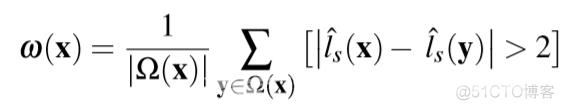
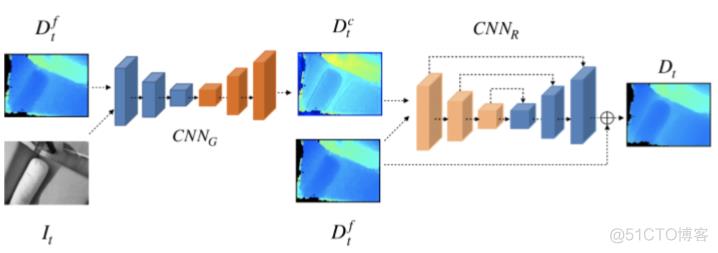
深度信息的细化是基于深度神经网络的,这是由一个两阶段的细化神经网络来组成。第一阶段是图像引导子网络CNNG,它将滤波后的深度与相应的关键帧上的灰度图像相结合得到粗细化的结果Dct,其中,灰度图像充当深度优化的引导,用以提供CNNG的物体边缘和语义信息的先验。第二阶段是残差U-Net CNNR,它可以进一步细化之前粗细化后的噪声结果得到最终的精细化深度信息。U-Net结构主要有助于使学习过程更加稳定并克服特征退化的问题。这里的训练集是采用Demon数据集进行训练。

2.渐进式网格生成
去除动态物体后,利用TSDF对体素进行融合。每一个估算出来的深度图都被集成到TSDF体素上,然后通过链接生成和更新的体素来重建3D物体,生成渐进式网格。
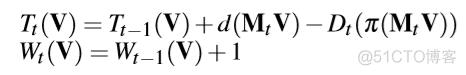
实时的网格更新是将渐进式移动的立方体块在单个CPU线程上集成,每一个关键帧只更新一部分立方体块。除此之外,本文为每一个体素定义了一个状态变量,用来判断更新,添加,通用和删除。更新和提取的三角网格只来自于添加和更新的立方体块。最后,再利用深度细化神经网络来提高平面网格的质量。
三、主要结果

我们的单眼深度估计是根据序列“室内楼梯”和“沙发”的两个代表性关键帧得出的:
- 原关键帧图像及其两个选定的参考关键帧图像;“室内楼梯”参考帧中的两个代表性像素及其极线绘制出从前端的6DoF跟踪来证明某些相机姿态误差的数据。
- 通过反投影进行的多视图SGM和相应点云的深度估计结果。
- 基于置信度的深度滤波后的结果及其对应的结果
- 在基于DNN的参考及其相应的点云之后的最终深度估计结果。

OPPO R17 Pro捕获的四个实验序列“室内楼梯”,“沙发”,“桌面”和“内阁”的表面网格生成结果:
a.显示了每个序列的一些代表性关键帧。没有基于DNN的深度细化的每个序列的生成 的全局表面网.
c.我们的基于DNN的深度细化的生成的全局表面网格。
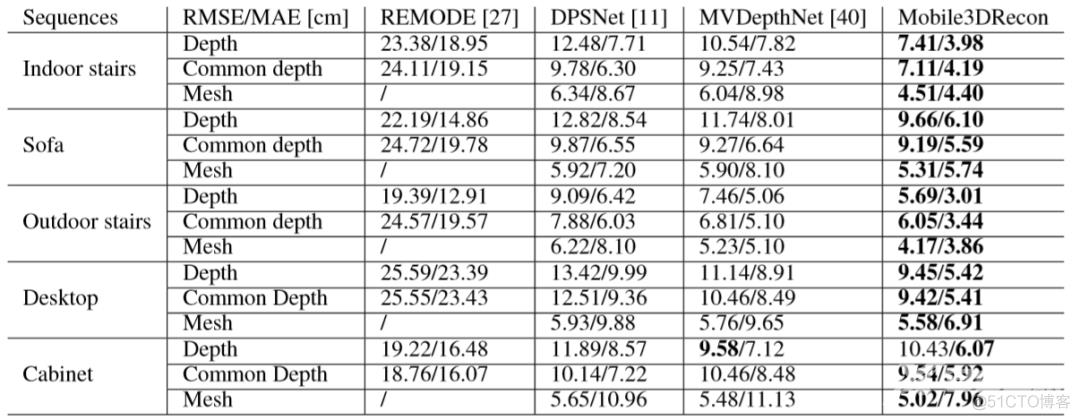
我们报告了我们的Mobile3DRecon和[11,27,40]的深度和表面网格结果的RMSE和MAE,这些结果是由我们的五个实验序列(由OPPO R17 Pro捕获的,ToF深度测量为GT)进行深度评估的,仅像素在GT和估计深度图中都有有效深度的情况下,将参与误差计算;对于通用深度评估,所有方法和GT中只有具有有效深度相同的像素才参与评估;
请注意,对于REMODE,我们仅考虑计算对于REMODE,由于深度小于35 cm,我们无法获得深度融合结果;对于网格评估,我们使用CloudCompare 2通过将每种方法的深度融合到GT网格(通过融合ToF深度)来比较网格结果。对于REMODE,由于深度误差严重,我们无法获得深度融合结果。

我们在所有子步骤中报告Mobile3DRecon的详细每关键帧时间消耗(以毫秒为单位),时间统计信息在两个移动平台上给出:带SDM710的OPPO R17 Pro和带SDM845的MI8。
标题:Mobile3DRecon: Real-time Monocular 3D Reconstruction on a Mobile Phone
作者:Xingbin Yang, Liyang Zhou, Hanqing Jiang, Zhongliang Tang, Yuanbo Wang, Hujun Bao, Member, IEEE, and Guofeng Zhang, Member, IEEE
机构:浙江大学;商汤科技
编译 : 张海晗
审核:管培育
