简述
介绍CUDA里面Stream的概念,用到CUDA的程序一般需要处理海量的数据,内存带宽经常会成为主要的瓶颈。在Stream的帮助下,CUDA程序可以有效地将内存读取和数值运算并行,从而提升数据的吞吐量。
内容
一般cuda流程
由于GPU和CPU不能直接读取对方的内存,CUDA程序一般会有一下三个步骤:1)将数据从CPU内存转移到GPU内存,2)GPU进行运算并将结果保存在GPU内存,3)将结果从GPU内存拷贝到CPU内存。如果不做特别处理,那么CUDA会默认只使用一个Stream(Default Stream)
默认stream流并发

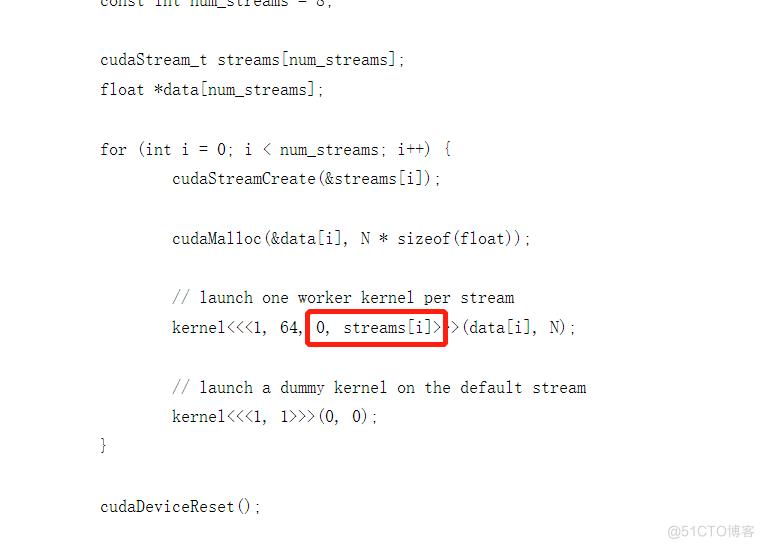
1.将数据拆分称许多块,每一块交给一个Stream来处理。
2.每一个Stream包含了三个步骤:1)将属于该Stream的数据从CPU内存转移到GPU内存,2)GPU进行运算并将结果保存在GPU内存,3)将该Stream的结果从GPU内存拷贝到CPU内存。
3.所有的Stream被同时启动,由GPU的scheduler决定如何并行。
简单的多流示例在将任何交错内核发送到默认流时不会实现并发

真正stream流并发
要在 nvcc7 及更高版本中启用每线程默认流,可以在包含 CUDA 头( cuda.h 或 cuda_runtime.h )之前,使用 nvcc 命令行选项 CUDA 或 #define 编译 CUDA_API_PER_THREAD_DEFAULT_STREAM 预处理器宏。
vs中的具体方法是,右键项目属性中的CUDA C/C++(前提是你创建的是CUDA程序,不然没有这个选项)选项中的Command Line中添加--default-stream per-thread就可以;
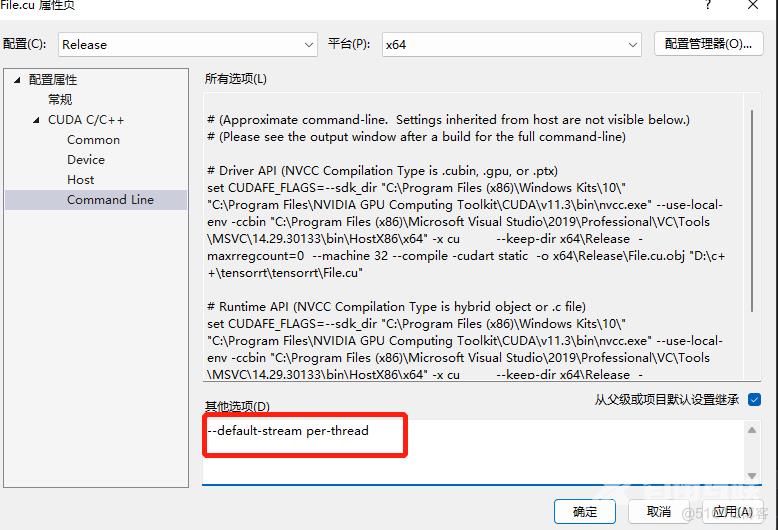
在这里可以看到九个流之间的完全并发:默认流(在本例中映射到流 14 )和创建的其他八个流

在GPU端默认一个时刻下只能运行一个kernel,但是有三种情况除外:
1.是开启了mps服务后同用户的多个进程调用可以同时刻在GPU上运行,实现kernel的并发执行;
2.是一个进程的多个线程调用写明不同stream队列的kernel操作,并且代码使用 --default-stream per-thread 参数进行nvcc的编译。
3.是一个进程(单线程)异步调用写明不同stream队列的kernel操作,并且代码使用 --default-stream per-thread 参数进行nvcc的编译。
cuda stream流特性
NVIDIA家的GPU有着不错的技能:
1.数据拷贝和数值计算可以同时进行。
2.两个方向的拷贝可以同时进行(GPU到CPU,和CPU到GPU)
不论GPU端是否可以多kernel并发,HOST和Device间的数据传输在一个时刻下都只能是单个操作,也就是说一个时刻下host端向device的数据传输只能是一个cuda调用,但是在host向device传输数据的同时device可以向host同时传输数据,同理同一时刻下device向host传输数据也只能是以cuda操作,不论GPU端的cuda操作是否有多个stream队列,单向的数据传输都是不能并发的。
【文章转自台湾大带宽服务器 http://www.558idc.com/tw.html提供,感恩】