如何优化商城高并发服务?对于线上服务会有哪些挑战?
①无法做离线缓存,所有数据都是实时读取。
②会有大量的请求发送给在线服务,对服务的响应时间要求较高,一般限制在300ms以内。如果超过这个时间,用户体验会急剧下降。
③数据量大。如果单次qps超过50W,单条1kb,50万就是5GB了,1分钟30G,对底层数据存储和访问压力很大。本文将讨论如何处理这些棘手的问题。
一、向关系型数据库sayno
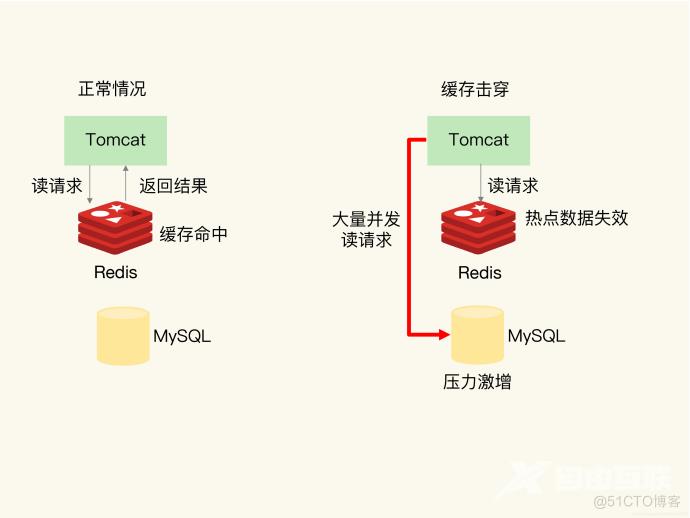
真正大规模的面向互联网C端的服务,是不会直接把数据库作为自己的存储系统的。无论是使用底层的子数据库和子表,还是各种优秀的连接池,mysql/oracle面对大规模的在线服务都有着天然的劣势。再怎么优化,也难以抵挡qps超过50万流量的冲击。所以换个思路,我们必须使用类似nosql的缓存系统,比如redis/mermCache,作为自己的“数据库”,而mysql等关系型数据库只是异步编写数据查询的备份系统。
就比如在双11主会场JD.COM,一些商品被摆上货架。这些商品在会场上架时直接写入redis,上架后再通过异步消息写入mysql。c端查询总是直接读取redis,而不是数据库,而B端查询可以去数据库。这部分流量不是很高,数据库肯定能承受。
二、使用多级缓存的优势
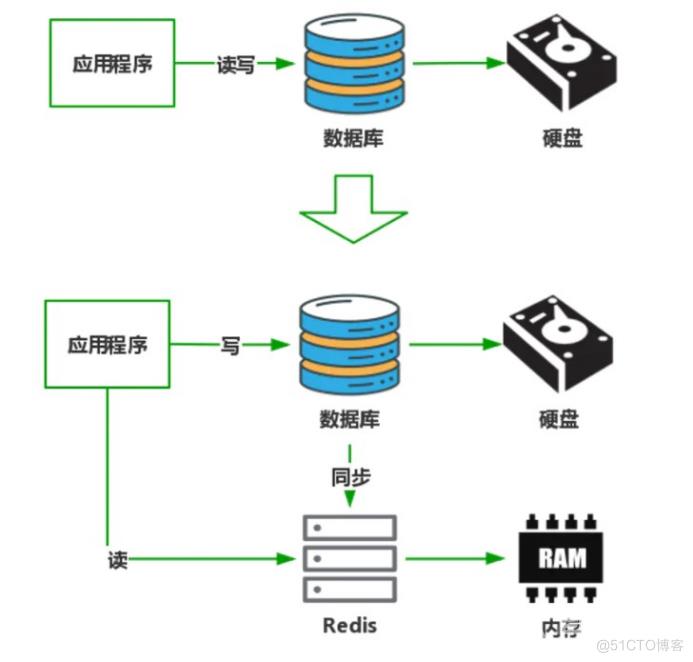
最近大家都知道CRMEB PRO商城是专门为高并发打造的,那么大家也都知道缓存是提高高并发性能的利器之一。那么如何在CRMEB PRO商城系统上利用好缓存,怎么在CRMEB PRO商城系统上面利用多级缓存,是我们需要思考的问题。Redis是目前缓存的首选。单机可以达到6-8万qps。面对高并发,我们可以手动横向扩展容量,满足qps可能无线增长的场景。但是这种方式也有缺点,因为redis是单线程的,会有热点问题。虽然redis内部使用crc16算法哈希,但是同样的密钥还是会落在单独的机器上,增加机器的负载。redis典型的有两个问题:缓存击穿和缓存穿透,尤其是在秒杀场景下,如果想要解决热点问题,会变得更加困难。这时候就必须考虑多级缓存了。在典型的峰值场景中,单个sku商品的qps将在销售开始的那一刻急剧上升。而我们这个时候需要用memeryCache来阻挡一层。memeryCache是多线程的,并发性比redis好,自然能解决热点问题。有了memeryCache,我们还需要localCache,这是一种用内存换取速度的方式。本地缓存将访问用户的一级请求。如果它找不到,就去memeryCache,然后redis。这个过程可以阻止数百万个qps。
三、多线程很牛,但也要适当使用
多线程有这么厉害吗?干嘛都说多线程,为什么CRMEB PRO商城系统要使用多线程,不用行不行?要讲明这个道理,我先来说一个实例.很典型的一个场景。原始的方式是循环一个30-40万的list,list执行的操作很简单,就是读redis中的数据,读一次数据一般需要3ms左右,这是同步的方式,在预览环境测试,是30秒+超时。我们优化的方式就是把同步调用改为线程池调用,线程池里的线程数或阻塞队列大小需要自己调优,最后实测接口rt只需要3秒。足以见多线程的强大。在多核服务的今天,如果还不使用多线程那就是对服务器资源浪费。这里需要说一句,使用多线层一定要做好监控,你需要随时知道线程的状态,如果线程数和queueSize设置的不恰当,将会严重影响业务,当然多线程也要分场景的,如果为了多线程而多线程反而更是一种资源浪费,因为多线程调度的时候会造成线程在内核态和用户态之间来回切换,如果使用不当反而会有反作用
四、降级和熔断可以带来不一样的效果
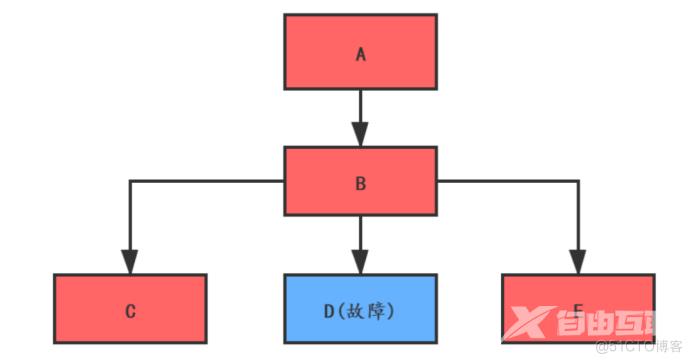
降级熔断是一种自我保护措施,这和电路上熔断的基本原理是一样的。可以防止电流过大引起火灾等。面对不可控的巨大流量请求,很可能会破坏服务器的数据库或redis,导致服务器宕机或瘫痪,造成无法挽回的损失。因为我们的服务本身需要有一个防御机制来抵御外部服务对自身的入侵,造成服务的破坏和联合反应。降级不同于熔断。两者的区别在于降级是在不影响主链接的情况下,关闭一些网上主链接的功能。如果熔断,意味着A请求B,B检测到业务流量有多大,开始熔断,那么请求会直接进入熔断池,直接返回失败。如何选择使用哪一种,需要在实践中结合业务场景来考虑。
五、优化IO让商城更加丝滑
很多人都会忽视IO这个问题,频繁的建联和断联都是对系统的重负。在并发请求中,如果存在单个请求的放大效那么将会使io呈指数倍增加。比如主会场的商品信息,如果需要商品的某个具体的详情,而这个详情需要调用下游来单个获取.随着主会场商品的热卖,商品越来越多,一次就要经过商品数X下游请求的数量,在海量的qps请求下,IO数被占据,大量的请求被阻塞,接口的响应速度就会呈指数级下降。所以需要批量的请求接口,所有的优化为一次IO
六、慎用重试,也特别注意以下几点!
重试是处理临时异常的常用方法。常见的处理方法是请求服务失败或写入数据库并重试。使用重试时,必须注意以下几点:①控制重试次数;②测量重试间隔;③是否重试做到配置化。之前我们线路上有个bug。kafka的消费有严重的滞后性,一个词的消耗时间在10秒以上。看了代码后发现是重试次数太多导致的,次数多不支持配置修改,所以当时的做法只能是临时改代码再上线。重试作为一个业务的第二次尝试,大大提高了程序的请求成功,但也要注意以上几点。
七、边界case的判断和兜底也很重要
作为互联网老手,很多人写出了不错的代码,但是经过几轮故障审查,发现很多造成重大事故的代码背后都是对一些边界问题的处理不足。他们犯的错误非常简单,但往往是这些小问题导致了重大事故。一次重大事故回顾,后来发现最终原因是没有判断空数组,导致传入的下游rpc为空,下游直接返回了全量业务数据,影响了上百万用户。这段代码修改起来很简单,但是需要自省,小的不足导致大的灾难。
八、学会优雅的打印日志,让商城问题无处遁形
作为跟踪在线问题的最佳工具,日志是保留bug场景的唯一来源。虽然有arthas这样的工具帮助我们排查问题,但是对于一些复杂的场景,还是需要日志来记录程序的数据。但在高流量场景下,如果打印全部日志对于online来说是一场灾难,有以下几个缺点:①磁盘占用严重。据估计,如果接口的qps在200000左右,则日志将为每秒几千兆字节,一天就有几千GB。②需要输出大量日志。占用了程序IO,增加了接口的RT(响应时间)。如果需要解决这个问题,①可以利用限流元件实现一个基于限流的对数元件。令牌桶算法可以限制打印日志的流量,比如一秒钟只能打印一个日志。②基于白名单的日志打印只有在线白名单用户才能打印,节省了大量无效日志输出。
总结:
本文讨论了CRMEB PRO商城系统高并发服务在面对大流量时的一些技术手段和应对要点。当然,实际的在线服务要比现在的复杂。这里只是一些建议。希望能保持敬畏之心,在高并发的道路上继续探索。更好的培养C端服务,做出更好的互联网商城应用。