单目深度估计模型Monodepth2对应的论文为Digging Into Self-Supervised Monocular Depth Estimation,由伦敦大学学院提出,这篇论文的研究目标是从单目RGB图像中恢复出对应的深度,由图1所示:该网络可以从单目图像中恢复对应的深度,图中不同颜色代表不同的深度。
论文地址:在公众号「3D视觉工坊」,后台回复「Monodepth2」,即可直接下载。

图1 Monodepth深度估计图
目前单目深度估计的难点,同时也是本论文着重解决的方向:
1、图像序列中存在遮挡。
2、当场景中发生物体运动的情况,如场景中运动的车辆,此时图像序列不仅存在因相机位姿而产生的图像改变,还存在因运动物体而产生的图像亮度的改变
从理论上说:在未给定第二帧图像的情况下估计图像对应的绝对或相对深度值是一个病态问题,因为无法通过构建三角化求解对应深度。然而,从直觉上说:人类通过在现实场景中生活、学习,获得了单眼估计深度的能力。因此,类比人类的学习能力,利用深度学习技术,从单目图像中获取对应的深度是可行的。该篇论文联合相机位姿估计与单目深度估计两项任务,使单目深度估计成为了可能。具体来说便是:首先利用单目深度估计网络进行逆深度估计,需要注意的是:该逆深度被限定在0与1之间,也就是说,该网络估计的为相对逆深度。然后进行相机位姿估计。最后利用相机位姿与视差计算亮度投影误差,作为网络模型的损失函数,利用梯度下降进行参数更新。接下来,本文将分三部分对Monodepth2模型进行介绍,分别是Monodepth2中的逆深度估计模块,相机位姿Pose估计模块,以及训练中使用的损失函数。
一、逆深度估计模块
该模块的作用是从单目图像中估计图像每个像素点的逆深度,在求解出逆深度之后,只需要对其取倒数便可获取对应的深度。这里需要说明,估计出来的逆深度被限定在0到1之间,与以真实深度存在一个比例因子,因此只可表示相机与场景的相对距离。该深度估计模块又可分为两个子模块,分别为特征编码子模块与特征解码子模块。特征编码子模块采用Res18模型结构,对输入图像进行32倍下采样,共生成5级特征,级数越高,特征空间分辨率越低(表示能力越强),但特征个数越多(对应通道部分)。特征解码子模块与U-Net解码模块部分一致,从第5级开始,联合特征编码子模块中相同分辨率的特征进行深度估计,该模块输出4级逆深度map(第五级因空间分辨率过低而不求解对应的逆深度),级数越低,空间分辨率越大,最大的空间分辨率与输入图像保持一致。
二、相机位姿Pose估计模块
该模块的作用为:由连续帧之间图像的变化情况,估计出相机之间的位姿(相机的运动情况)。该模块有两种处理情况,以下将对这两种情况分别介绍。
2.1 连续帧情况
首先进行符号的说明,用-1代表进行逆深度估计图像的前一帧图像,1代表进行逆深度估计图像的后一帧图像,0代表进行逆深度估计的当前图像。在该情况下利用相机位姿估计模块分别估计:从前一帧图像-1到当前图像0之间的位姿,与从当前图像0到后一帧图像1之间的位姿。
2.2 双目情况
同样进行符号说明,用0代表进行逆深度估计的当前图像(左目图像),"s"代表当前0图像对应的右目图像。在该情况下,因双目相机的位姿已固定,因此位姿也已固定(不需要利用pose估计模块进行估计)。
2.3 相机位姿模块结构
该模块同样分为特征编码子模块与特征解码子模块,其中该模块中的特征编码子模块与深度估计模块中的特征编码子模块结构一致,但参数独立,同样为Res18模型结构。因相机位姿求取的是图像连续帧之间的刚性运动,因此在该论文中,利用空间分辨率最低的第5级特征(抽象能力最强)输入进对应该模块的特征解码子模块来进行位姿估计。位姿解码子模块为3层卷积结构,对输入的第5级特征进行解码,并回归出对应每个像素点的运动信息。例如,位姿估计网络的输入为(256,6,20),那么经过解码回归之后输出的特征为(12,6,20)。对维度1(对应长),维度2(对应宽)求取均值可得连续帧之间的轴角与平移向量。在求得轴角后可通过罗德里格旋转公式求取旋转矩阵,如下图2所示。
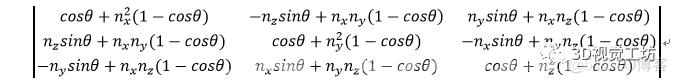 图2 罗德里格旋转公式
图2 罗德里格旋转公式
三、训练中使用的损失函数
本论文的创新点集中在对损失函数的改进。分别提出了:1.一种适用于单目遮挡情况下的匹配损失函数。2.一种在单目情况下检测相机间有无运动的标记方法。3.一种多尺度的匹配损失函数。以下将对这三种情况分别进行探讨。
3.1 一种适用于单目遮挡情况下的匹配损失函数
绝大多数单目深度(也包括光流与立体匹配)无监督方法都采用亮度投影误差(photometric reprojection error)作为训练的损失函数,亮度投影误差被定义为:利用深度与相机位姿对源图像进行采样,并与目标图像进行比对之后得到的误差,如下图3所示
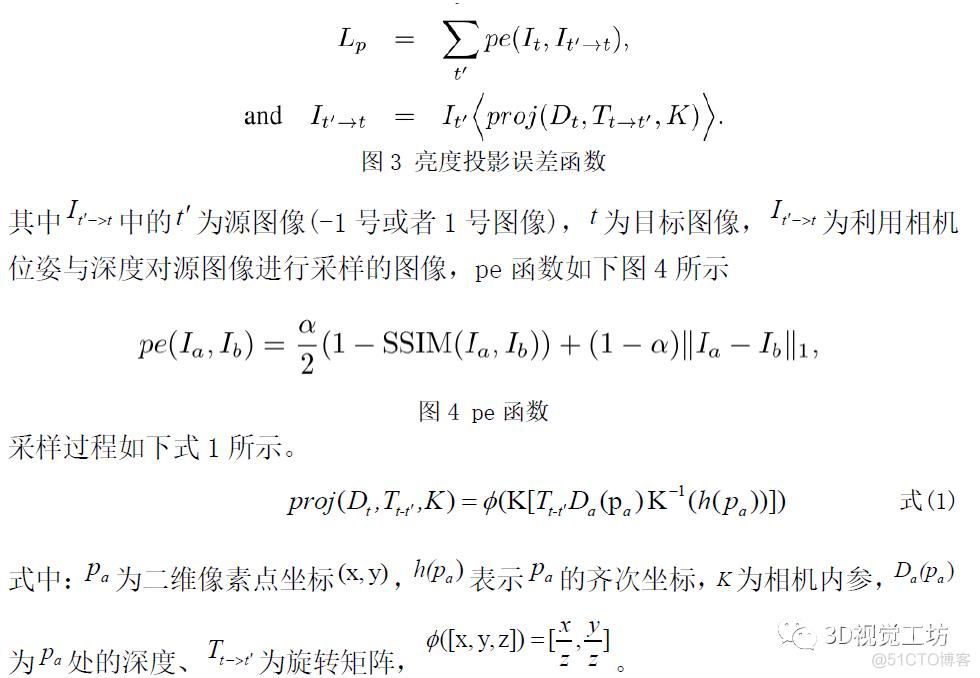
具体来说便是:利用相机位姿与深度获得采样坐标,利用采样坐标对源图像(-1或1号图像)进行采样,在未发生遮挡的情况下,采样后的图像应与目标图像(0号图像)在同位置的像素点亮度保持一致,这样在训练过程中,学习到使得采样图像与目标图像亮度值趋于一致的深度与相机位姿,计算该深度与相机位姿的模型参数即为最优参数。然而现实场景复杂多变,存在大量遮挡情况,在遮挡情况下,亮度投影误差会失效,因为采样之后的图像像素点发生了遮挡,对亮度投影误差进行简单的求取平均操作无法有效衡量该区域的匹配情况,如图5所示。
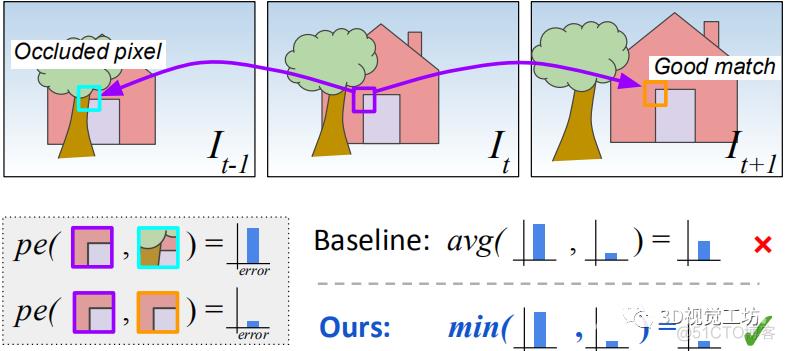
图5 遮挡情况示意图
因此,本论文对此种情况做出了改进,用取最小值操作取代取平均操作,如此做法可使亮度投影误差函数忽略遮挡处不正确的亮度值,进而使模型专注非遮挡区域的计算,整个计算过程如下图5所示:
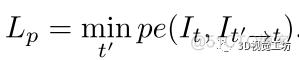
图5 论文中提出的最小化亮度守恒损失函数
3.2 一种在单目情况下检测相机间有无运动的标记方法
单目深度估计需要进行如下假设:场景静止、相机运动。如训练集中存在使此假设不成立的图像序列,会严重影响网络的精度。因此,本文利用一种检测相机间有无运动的标记方法,剔除图像序列中未发生运动的像素点。过程如下图6所示:
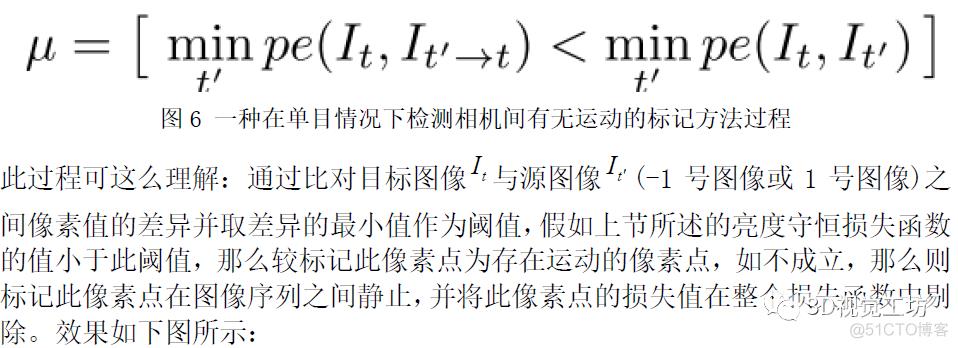

图7 图像序列中静止点可视化图
图中黑色像素点为静止点,需要从整个损失函数中剔除。
3.3 一种多尺度的匹配损失函数
此方法过程比较简单,即对逆深度估计模块估计出的4级逆深度map进行上采样到与输入同尺寸,并对上采样之后的4级逆深度map求取损失函数。
四、 总结
本文对单目深度估计模型Monodepth2的主要计算过程进行了介绍,通过以上三个步骤的改进,该模型达到state-of-the-art,因此可作为一般深度估计模型的baseline方法。
