Map的遍历问题,选择哪种方式性能最优?
java8之后提供了lambda表达式的遍历方式。因此如果可以用lambda表达式遍历,那就毫无疑问的直接选择即可。
遍历方式代码如下:
//entrySet方式:key和value一次性都拿出来
for (Entry<String, String> entry: map.entrySet()) {
key = entry.getKey();
value = entry.getValue();
}
//keySet方式:先拿出key,再去拿value
for (String key : map.keySet()) {
value = map.get(key);
}
//values方式:当只需要value的时候,这种方式才合适
for (String value : map.values()) {
}如果你是遍历HashMap:
遍历既需要key也需要value的时候:keySet与entrySet方法的性能差异取决于key的具体情况,如复杂度(复杂对象)、离散度、冲突率等。换言之,取决于HashMap查找value的开销。entrySet一次性取出所有key和value的操作是有性能开销的,当这个损失小于HashMap查找value的开销时,entrySet的性能优势就会体现出来。例如上述对比测试中,当key是最简单的数值字符串时,keySet可能反而会更高效,耗时比entrySet少10%。总体来说还是推荐使用entrySet。因为当key很简单时,其性能或许会略低于keySet,但却是可控的;而随着key的复杂化,entrySet的优势将会明显体现出来。
遍历只需要key的时候:keySet方法更为合适,因为entrySet将无用的value也给取出来了,浪费了性能和空间
只遍历value时,使用vlaues方法是最佳选择
如果你是遍历TreeMap:
同时遍历key和value时,与HashMap不同,entrySet的性能远远高于keySet。这是由TreeMap的查询效率决定的,也就是说,TreeMap查找value的开销较大,明显高于entrySet一次性取出所有key和value的开销。因此,遍历TreeMap时强烈推荐使用entrySet方法。
只遍历key时,keySet方法更为合适,因为entrySet将无用的value也给取出来了,浪费了性能和空间
只遍历value时,使用vlaues方法是最佳选择
综上:lambda遍历是首选。当lambda不适用(比如一边遍历一边需要移除等等),entrySet的遍历方式是最优的方式选择。
HashMap的原理(区分JDK8之前和之后)
哈希表(hash table)也叫散列表,是一种非常重要的数据结构,应用场景及其丰富,许多缓存技术(比如memcached)的核心其实就是在内存中维护一张大的哈希表,而HashMap的实现原理也常常出现在各类的面试题中,重要性可见一斑。
HashMap它包括几个重要的成员变量:table, size, threshold, loadFactor, modCount。
table是一个Entry[]数组类型,而Entry实际上就是一个单向链表。哈希表的"key-value键值对"都是存储在Entry数组中的。
size是HashMap的大小,它是HashMap保存的键值对的数量。
threshold是HashMap的阈值,用于判断是否需要调整HashMap的容量。threshold的值=“容量*加载因子”,当HashMap中存储数据的数量达到threshold时,就需要将HashMap的容量加倍。
loadFactor就是加载因子。
modCount是用来实现fail-fast机制的数组:查找快,新增、删除慢
采用一段连续的存储单元来存储数据。对于指定下标的查找,时间复杂度为O(1);通过给定值进行查找,需要遍历数组,逐一比对给定关键字和数组元素,时间复杂度为O(n),当然,对于有序数组,则可采用二分查找,插值查找,斐波那契查找等方式,可将查找复杂度提高为O(logn);对于一般的插入删除操作,涉及到数组元素的移动,其平均复杂度也为O(n)
线性链表:新增、删除快,查找慢
对于链表的新增,删除等操作(在找到指定操作位置后),仅需处理结点间的引用即可,时间复杂度为O(1),而查找操作需要遍历链表逐一进行比对,复杂度为O(n)
二叉树:自平衡的话,新增、删除、查找都不快不慢
对一棵相对平衡的有序二叉树,对其进行插入,查找,删除等操作,平均复杂度均为O(logn)。
哈希表(重点讲解):添加,删除,查找等操作都很快 (数组+链表)
相比上述几种数据结构,在哈希表中进行添加,删除,查找等操作,性能十分之高,不考虑哈希冲突的情况下,仅需一次定位即可完成,时间复杂度为O(1),接下来我们就来看看哈希表是如何实现达到惊艳的常数阶O(1)的。
我们知道,数据结构的物理存储结构只有两种:顺序存储结构和链式存储结构(像栈,队列,树,图等是从逻辑结构去抽象的,映射到内存中,也这两种物理组织形式),而在上面我们提到过,在数组中根据下标查找某个元素,一次定位就可以达到,哈希表利用了这种特性,哈希表的主干就是数组。
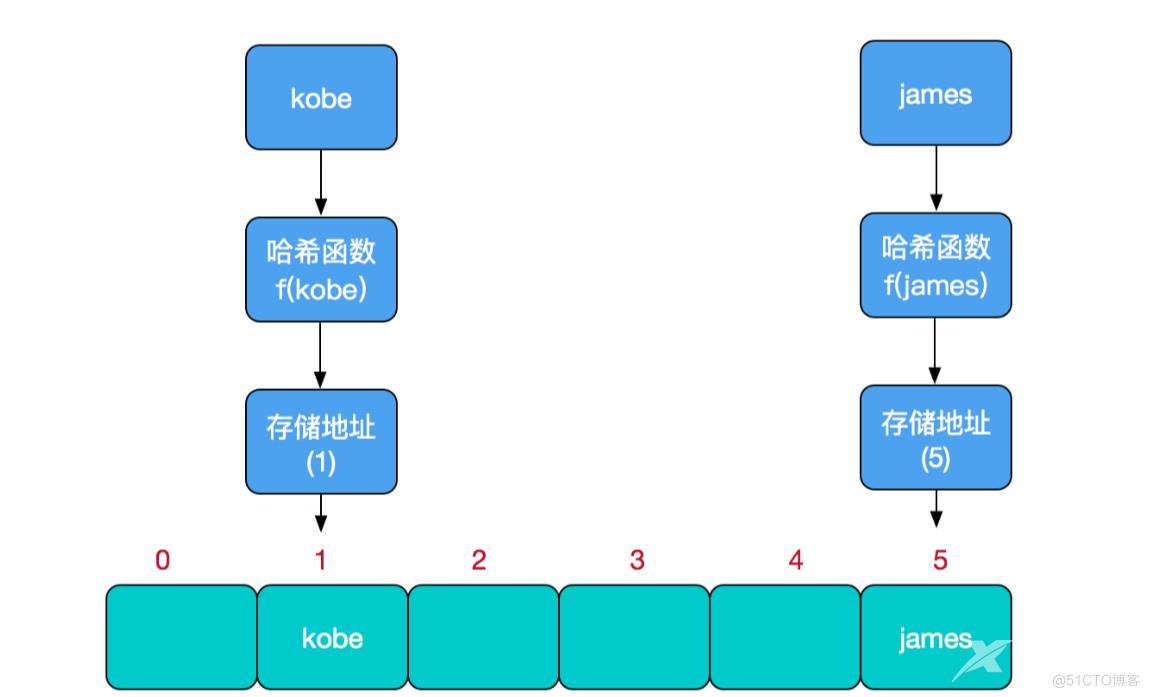
这样子:我们找位置就这么找:
1、我们通过把当前元素的关键字 通过某个函数(hash算法取模 存储位置 = f(关键字))映射到数组中的某个位置,通过数组下标一次定位就可完成操作。
2、哈希冲突(哈希碰撞):如果两个不同的元素,通过哈希函数得出的实际存储地址相同怎么办?也就是说,当我们对某个元素进行哈希运算,得到一个存储地址,然后要进行插入的时候,发现已经被其他元素占用了,其实这就是所谓的哈希冲突,也叫哈希碰撞。前面我们提到过,哈希函数的设计至关重要,好的哈希函数会尽可能地保证 计算简单和散列地址分布均匀,但是,我们需要清楚的是,数组是一块连续的固定长度的内存空间,再好的哈希函数也不能保证得到的存储地址绝对不发生冲突。那么哈希冲突如何解决呢?哈希冲突的解决方案有多种:开放定址法(发生冲突,继续寻找下一块未被占用的存储地址),再散列函数法,链地址法,而HashMap即是采用了链地址法,也就是数组+链表的方式,