Android底层基于Linux内核开发.随着Android版本不断更新,内存回收机制也在不断变化.本文简要介绍下不同版本下的内存回收原理.
Linux OOM机制
OOM(out of memory)是linux中内存管理机制的一种,在系统可用内存较少的情况下,内核为了保证系统还能够继续运行下去,会选择杀掉一些进程释放掉一些内存.通常oom_killer的触发流程是: 进程A想要分配物理内存->粗发缺页异常-> 内核去分配物理内存-> 物理内存不足-> OOM. 当OOM发生时,可以有两种选择:
- kernelpanic(死机)
- 启动oom_killer,遍历当前所有进程,根据进程的内存使用情况进行打分,然后从中选择一个分数最高进程杀掉,从而回收内存
主要处理流程
调用oom_killer前,系统会对oom_control做一个填充:
pagefault_out_of_memory(void)
{
struct oom_control oc = {
.zonelist = NULL,
.nodemask = NULL,
.memcg = NULL,
.gfp_mask = 0,
.order = 0,
};
...
out_of_memory(&oc);
}
oom_killer的处理主要集中在mm/oom_kill.c
核心函数为out_of_memory
bool out_of_memory(struct oom_control *oc)
{
unsigned long freed = 0;
enum oom_constraint constraint = CONSTRAINT_NONE;
if (oom_killer_disabled)
return false;
if (!is_memcg_oom(oc)) {
blocking_notifier_call_chain(&oom_notify_list, 0, &freed);
if (freed > 0)
/* Got some memory back in the last second. */
return true;
}
/*
* If current has a pending SIGKILL or is exiting, then automatically
* select it. The goal is to allow it to allocate so that it may
* quickly exit and free its memory.
*/
if (task_will_free_mem(current)) {
mark_oom_victim(current);
wake_oom_reaper(current);
return true;
}
/*
* The OOM killer does not compensate for IO-less reclaim.
* pagefault_out_of_memory lost its gfp context so we have to
* make sure exclude 0 mask - all other users should have at least
* ___GFP_DIRECT_RECLAIM to get here.
*/
if (oc->gfp_mask && !(oc->gfp_mask & __GFP_FS))
return true;
/*
* Check if there were limitations on the allocation (only relevant for
* NUMA and memcg) that may require different handling.
*/
constraint = constrained_alloc(oc);
if (constraint != CONSTRAINT_MEMORY_POLICY)
oc->nodemask = NULL;
check_panic_on_oom(oc, constraint);
if (!is_memcg_oom(oc) && sysctl_oom_kill_allocating_task &&
current->mm && !oom_unkillable_task(current, NULL, oc->nodemask) &&
current->signal->oom_score_adj != OOM_SCORE_ADJ_MIN) {
get_task_struct(current);
oc->chosen = current;
oom_kill_process(oc, "Out of memory (oom_kill_allocating_task)");
return true;
}
select_bad_process(oc);
/* Found nothing?!?! Either we hang forever, or we panic. */
if (!oc->chosen && !is_sysrq_oom(oc) && !is_memcg_oom(oc)) {
dump_header(oc, NULL);
panic("Out of memory and no killable processes...\n");
}
if (oc->chosen && oc->chosen != (void *)-1UL) {
oom_kill_process(oc, !is_memcg_oom(oc) ? "Out of memory" :
"Memory cgroup out of memory");
/*
* Give the killed process a good chance to exit before trying
* to allocate memory again.
*/
schedule_timeout_killable(1);
}
return !!oc->chosen;
}
处理流程:
- 通知系统中注册了oom_nofiy_list的模块释放了内存,如果这些内存从模块中释放了一些内存,那么直接结束omm killer进程,回收失败,则进入下一步omm_killer;
- 触发OOM_killer通常是由当前进程进行内存分配引起,而如果当前进程已经挂起了一个SIG_KILL信号,直接选中当前进程,否则进入下一步
- check_panic_on_oom检查系统管理员设置,看oom时是直接panic还是进行OOM_killer.
- 如果管理原规定,谁引起oom,kill谁,那么就直接杀掉正在尝试分配内存的进程
sysctl_oom_kill_allocating_task - 调用select_bad_process选择合适的进程,然后调用OOM_kill_process杀死选中进程.如果没有找到,则触发panic
sysctl_panic_on_oom
该参数在check_panic_on_oom函数中引用,当参数等于0时,启动OOM killer.当参数等于2时,如果不是sysrq进程的话,强制进入kernel panic.等于其他值时,要分具体情况,对于某些情况可以panic,有些情况启动oom killer.
kernel代码中,enum oom_constraint就是一个进一步描述oom状态的参数.定义如下:
enum oom_constraint {
CONSTRAINT_NONE,
CONSTRAINT_CPUSET,
CONSTRAINT_MEMORY_POLICY,
CONSTRAINT_MEMCG,
};
对于UMA而言,oom_constrain永远都是CONSTRAINT_NONE,表示系统并没有什么约束就出现了oom.
在NUMA下,有可能附加了其他的约束导致了系统遇到OOM状态,实际上,系统中还有充足的内存.这些约束包括:
OCNSTRAINT_CPUSET
cpusets是kernel中的一种机制,通过该机制可以把一组cpu和memory node资源分配给特定的一组进程.这时候如果出现OOM,仅仅说明该进程能分配memory的那个node出现状况了,整个系统有很多的memory node,其他的node可能有充足的memory资源.
CONSTRAINT_MEMORY_POLICY
memory policy是NUMA系统中如何控制分配各个memory node资源的策略模块。用户空间程序(NUMA-aware的程序)可以通过memory policy的API,针对整个系统、针对一个特定的进程,针对一个特定进程的特定的VMA来制定策略。产生了OOM也有可能是因为附加了memory policy的约束导致的,在这种情况下,如果导致整个系统panic似乎有点不太合适。
CONSTRAINT_MEMCG
MEMCG就是memory control group,Cgroup中的memory子系统就是控制系统memory资源分配的控制器,通俗的将就是把一组进程的内存使用限定在一个范围内。当这一组的内存使用超过上限就会OOM,在这种情况下的OOM就是CONSTRAINT_MEMCG类型的OOM。
select_bad_process
该函数从系统中选择一个合适被杀死的进程,对系统关键进程不能杀死,其他则通过 oom_badness 进行打分,分数最高者被选中:
graph TD; select_bad_process-->oom_evaluate_task oom_evaluate_task-->oom_badnessoom_badness
/**
* oom_badness - heuristic function to determine which candidate task to kill
* @p: task struct of which task we should calculate
* @totalpages: total present RAM allowed for page allocation
*
* The heuristic for determining which task to kill is made to be as simple and
* predictable as possible. The goal is to return the highest value for the
* task consuming the most memory to avoid subsequent oom failures.
*/
unsigned long oom_badness(struct task_struct *p, struct mem_cgroup *memcg,
const nodemask_t *nodemask, unsigned long totalpages)
{
long points;
long adj;
...
adj = (long)p->signal->oom_score_adj;
if (adj == OOM_SCORE_ADJ_MIN ||
test_bit(MMF_OOM_SKIP, &p->mm->flags) ||
in_vfork(p)) {
task_unlock(p);
return 0;
}
/*
* The baseline for the badness score is the proportion of RAM that each
* task‘s rss, pagetable and swap space use.
*/
points = get_mm_rss(p->mm) + get_mm_counter(p->mm, MM_SWAPENTS) +
atomic_long_read(&p->mm->nr_ptes) + mm_nr_pmds(p->mm);
task_unlock(p);
/*
* Root processes get 3% bonus, just like the __vm_enough_memory()
* implementation used by LSMs.
*/
if (has_capability_noaudit(p, CAP_SYS_ADMIN))
points -= (points * 3) / 100;
/* Normalize to oom_score_adj units */
adj *= totalpages / 1000;
points += adj;
/*
* Never return 0 for an eligible task regardless of the root bonus and
* oom_score_adj (oom_score_adj can‘t be OOM_SCORE_ADJ_MIN here).
*/
return points > 0 ? points : 1;
}
详细介绍下oom_badness主要工作:
代码17行
对某一个task进行打分(oom_score)主要由两部分组成:
系统打分,主要是根据该task的内存使用情况
用户打分,即oom_score_adj
该task的实际得分需要综合两方面的打分.如果用户将task的oom_socre_adj设置成OOM_SCORE_ADJ_MIN(-1000)的话,实际上就是禁止了oom killer杀死该进程.
返回0,即通知oom killer,该进程是"good process". 后面可以看到实际计算分数时最低分是1分.
代码27行
系统打分就是看物理内存消耗量,主要是三部分:RSS,swap fille或者swap device上占用的内存情况,页表占用的内存情况.
代码35行
root进程有3%的内存室友特权,因此这里要减去那些内存使用量
代码39行
用户可以调整oom_score,具体操作方法如下:
Android system
oom_score_adj的取值范围是-1000~1000,0表示用户不调整oom_score,负值表示要在实际打分值上减去一个折扣,正值表示要惩罚该task,也就是增加该进程的oom_score。在实际操作中,需要根据本次内存分配时候可分配内存来计算(如果没有内存分配约束,那么就是系统中的所有可用内存,如果系统支持cpuset,那么这里的可分配内存就是该cpuset的实际额度值)。oom_badness函数有一个传入参数totalpages,该参数就是当时的可分配的内存上限值。实际的分数值(points)要根据oom_score_adj进行调整,例如如果oom_score_adj设定-500,那么表示实际分数要打五折(基数是totalpages),也就是说该任务实际使用的内存要减去可分配的内存上限值的一半。
Android kernel LMK机制
在Android中,及时用户退出当前应用程序后,应用程序还是会存在于系统当中,这是为了方便程序的再次启动。但是这样的话,随着打开的程序的数量的增加,系统的内存就会不足,从而需要杀掉一些进程来释放内存空间。至于是否需要杀进程以及杀什么进程,这个就是由Android的内部机制LowMemoryKiller机制来进行的。
Andorid的Low Memory Killer是在标准的linux lernel的OOM基础上修改而来的一种内存管理机制。当系统内存不足时,杀死不必要的进程释放其内存。不必要的进程的选择根据有2个:oom_adj和占用的内存的大小。oom_adj代表进程的优先级,数值越高,优先级月低,越容易被杀死;对应每个oom_adj都可以有一个空闲进程的阀值。Android Kernel每隔一段时间会检测当前空闲内存是否低于某个阀值。假如是,则杀死oom_adj最大的不必要的进程,直到内存恢复低于阀值的状态。
对比下oom
LMK初始化
初始化主要为kobject注册和各通知链的注册
static int __init lowmem_init(void)
{
rc = kobject_init_and_add(lowmem_notify_kobj, &lowmem_notify_kobj_type,
mm_kobj, "lowmemkiller");
register_shrinker(&lowmem_shrinker);
#ifdef CONFIG_OOM_NOTIFIER
register_oom_notifier(&android_oom_notifier);
#endif
#ifdef CONFIG_E_SHOW_MEM
register_e_show_mem_notifier(&tasks_e_show_mem_notifier);
#endif
vmpressure_notifier_register(&lmk_vmpr_nb);
nl_sk = netlink_kernel_create(&init_net, LMK_NETLINK_PROTO, &cfg);
}
其中lowmen_shrinker定义如下:
static struct shrinker lowmem_shrinker = {
.scan_objects = lowmem_scan,
.count_objects = lowmem_count,
.seeks = DEFAULT_SEEKS * 16,
.flags = SHRINKER_LMK
};
static short lowmem_adj[6] = {
0,
1,
6,
12,
};
static int lowmem_minfree[6] = {
3 * 512, /* 6MB */
2 * 1024, /* 8MB */
4 * 1024, /* 16MB */
16 * 1024, /* 64MB */
};
lowmem_adj这个数据在系统运行中会有填充.具体数值可在如下节点获取:
/sys/module/lowmemorykiller/parameters/minfree:里面是以”,”分割的一组数,每个数字代表一个内存级别 /sys/module/lowmemorykiller/parameters/adj:对应上面的一组数,每个数组代表一个进程优先级级别
sp9832e_1h10:/sys/module/lowmemorykiller/parameters # cat minfree ; cat adj 18432,23040,27648,32256,55296,80640 0,100,200,300,900,906
代表的意思:两组数一一对应,当手机内存低于80640时,就去杀掉优先级906以及以上级别的进程,当内存低于55296时,就去杀掉优先级900以及以上的进程。
内存回收功能实现主要在lowmem_scan函数中:
static unsigned long lowmem_scan(struct shrinker *s, struct shrink_control *sc)
{
/* work around for antutu */
struct task_struct *selected_antutu = NULL;
int selected_antutu_tasksize = 0;
short selected_antutu_adj = -1000;
bool has_antutu_3D = false;
#ifdef CONFIG_LOWMEM_NOTIFY_KOBJ
lowmem_notif_sc.gfp_mask = sc->gfp_mask;
if (get_free_ram(&other_free, &other_file_orig, &other_file, sc)) {
if (mutex_is_locked(&kernfs_mutex))
msleep(1);
if (!mutex_is_locked(&kernfs_mutex))
lowmem_notify_killzone_approach();
else
lowmem_print(1, "skip as kernfs_mutex is locked.");
}
#else
get_current_ram(&other_free, &other_file_orig, &other_file, sc);
#endif
for (i = 0; i < array_size; i++) {
minfree = lowmem_minfree[i];
if (other_free < minfree && other_file < minfree) {
min_score_adj = lowmem_adj[i];
break;
}
}
ret = adjust_minadj(&min_score_adj, &pressure);
selected_oom_score_adj = min_score_adj;
for_each_process(tsk) {
struct task_struct *p;
short oom_score_adj;
if (tsk->flags & PF_KTHREAD)
continue;
if (time_before_eq(jiffies, lowmem_deathpending_timeout)) {
if (test_task_flag(tsk, TIF_MEMDIE)) {
rcu_read_unlock();
mutex_unlock(&scan_mutex);
return 0;
}
}
/* workaround for antutu */
if (strstr("com.antutu.benchmark.full", p->comm))
has_antutu_3D = true;
oom_score_adj = p->signal->oom_score_adj;
if (oom_score_adj < min_score_adj) {
task_unlock(p);
continue;
}
tasksize = get_mm_rss(p->mm);
task_unlock(p);
if (tasksize <= 0)
continue;
if (selected) {
if (oom_score_adj < selected_oom_score_adj)
continue;
if (oom_score_adj == selected_oom_score_adj &&
tasksize <= selected_tasksize)
continue;
}
/* workaround for antutu */
if (!selected_antutu &&
strstr("com.antutu.ABenchMark", p->comm)) {
selected_antutu = p;
selected_antutu_tasksize = tasksize;
selected_antutu_adj = oom_score_adj;
continue;
}
selected = p;
selected_tasksize = tasksize;
selected_oom_score_adj = oom_score_adj;
lowmem_print(2, "select ‘%s‘ (%d), adj %hd, size %d, to kill\n",
p->comm, p->pid, oom_score_adj, tasksize);
}
/* workaround for antutu:
* if 3D task is not exist, check if the antutu task is more suited
* to be killed
*/
if (selected && selected_antutu && !has_antutu_3D) {
if (selected_antutu_adj > selected_oom_score_adj ||
(selected_antutu_adj == selected_oom_score_adj &&
selected_antutu_tasksize > selected_tasksize)) {
selected = selected_antutu;
selected_tasksize = selected_antutu_tasksize;
selected_oom_score_adj = selected_antutu_adj;
}
}
if (selected) {
long cache_size = other_file * (long)(PAGE_SIZE / 1024);
long cache_size_orig = other_file_orig * (long)(PAGE_SIZE / 1024);
long cache_limit = minfree * (long)(PAGE_SIZE / 1024);
long free = other_free * (long)(PAGE_SIZE / 1024);
if (test_task_flag(selected, TIF_MEMDIE) &&
(test_task_state(selected, TASK_UNINTERRUPTIBLE))) {
lowmem_print(2, "‘%s‘ (%d) is already killed\n",
selected->comm,
selected->pid);
rcu_read_unlock();
mutex_unlock(&scan_mutex);
return 0;
}
task_lock(selected);
/* add for lmfs */
selected_process_uid = from_kuid(&init_user_ns,
selected->cred->uid);
selected_process_pid = selected->pid;
selected_process_adj = selected_oom_score_adj;
send_sig(SIGKILL, selected, 0);
/*
* FIXME: lowmemorykiller shouldn‘t abuse global OOM killer
* infrastructure. There is no real reason why the selected
* task should have access to the memory reserves.
*/
if (selected->mm)
mark_oom_victim(selected);
task_unlock(selected);
trace_lowmemory_kill(selected, cache_size, cache_limit, free);
si_swapinfo(&si);
lowmem_deathpending_timeout = jiffies + HZ;
rem += selected_tasksize;
trace_almk_shrink(selected_tasksize, ret,
other_free, other_file, selected_oom_score_adj);
} else {
trace_almk_shrink(1, ret, other_free, other_file, 0);
}
if (selected) {
send_killing_app_info_to_user(selected_process_uid,
selected_process_pid,
selected_process_adj);
return rem;
}
Android LMKD 机制
下面介绍Android 9 中新增的用户空间 lowmemorykiller 守护进程 (lmkd) 功能及其配置方法
代码位置 platform/system/core/lmkd/
过去,Android 使用内核中的 lowmemorykiller 驱动程序来缓解内存压力(通过终止非必需进程)。此机制非常严格,具体取决于硬编码值。此外,从内核版本 4.12 开始,lowmemorykiller 驱动程序会从上游内核中排除。
用户空间?lmkd?进程可实现相同的功能,但它是通过现有的内核机制来检测和估测内存压力。该进程使用内核生成的 vmpressure 事件来获取关于内存压力级别的通知。此外,它还可以使用内存 cgroup 功能来限制分配给相应进程的内存资源(根据每个进程的重要性)
ProcessList中定义有进程的优先级,越重要的进程的优先级越低,前台APP的优先级为0,系统APP的优先级一般都是负值,所以一般进程管理以及杀进程都是针对与上层的APP来说的,而这些进程的优先级调整都在AMS里面,AMS根据进程中的组件的状态去不断的计算每个进程的优先级,计算之后,会及时更新到对应进程的文件节点中,而这个对文件节点的更新并不是它完成的,而是lmkd,他们之间通过socket通信。
lmkd在手机中是一个常驻进程,用来处理上层ActivityManager在进行updateOomAdj之后,通过socket与lmkd进行通信,更新进程的优先级,如果必要则杀掉进程释放内存。lmkd是在init进程启动的时候启动的,在lmkd中有定义lmkd.rc:
service lmkd /system/bin/lmkd
class core
group root readproc
critical
socket lmkd seqpacket 0660 system system
socket lmfs stream 0660 root system
socket vmpressure stream 0666 root system
writepid /dev/cpuset/system-background/tasks
配置内核以支持LMKD
从 Android 9 开始,用户空间?lmkd?会在未检测到内核 lowmemorykiller 驱动程序时激活。请注意,用户空间?lmkd?要求内核支持内存 cgroup。因此,要改用用户空间?lmkd,您应使用以下配置设置编译内核:
CONFIG_ANDROID_LOW_MEMORY_KILLER=n CONFIG_MEMCG=y CONFIG_MEMCG_SWAP=y
LMKD 终止策略
lmkd 支持基于以下各项的新终止策略:
- vmpressure event
- severity
- 其他提示(如交换利用率
swap utilization) - 旧模式(在该模式下,
lmkd会像内核 lowmemorykiller 驱动程序一样做出终止决策)。
内存不足的设备和高性能设备的新终止策略有所不同。对于内存不足的设备,一般情况下,系统会选择承受较大的内存压力;对于高性能设备,如果存在内存压力,则属于异常情况,应及时修复,以免影响整体性能。ro.config.low_ram 属性允许选择其中一种模式。有关如何设置此属性的说明,请参阅低内存配置。
在旧模式下,lmkd 终止决策是基于可用内存和文件缓存阈值做出的。您可以将 ro.lmk.use_minfree_levels 属性设置为 true,从而启用此模式。
为特定设备配置LMKD
lmkd 调试日志。
false
*注意:*mem_pressure = 内存使用量/RAM_and_swap 使用量(以百分比的形式表示)
low level 正常回收;medium level就开始swaping;critical就是快没内存了
具体实现
AMS与LMKD通信command
主要分为五种,每种command代表一种数据控制方式,在ProcessList及lmkd中都有定义:
LMK_TARGET:更新/sys/module/lowmemorykiller/parameters/中的minfree及adj LMK_PROCPRIO:更新指定进程的优先级,也就是oom_socre_adj LMK_PROCREMOVE:移除进程 Purge:清理所有注册的进程 LMK_GETKILLCNT:获取kill的进程数
数据结构
用来描述handle events的数据结构
struct event_handler_info {
int data;
void (*handler)(int data, uint32_t events);
};
定义描述vmpressure event的结构体变量: vmpressure_hinfo
用来描述socket events的数据结构
struct sock_event_handler_info {
int sock;
struct event_handler_info handler_info;
};
用来定义了两个数据: ctrl_sock data_sock
table,类似hashtable,不过计算index的方式不是hash,而是oom_score_adj经过转换后直接作为index.数组的每个元素都是双向循环链表进程的优先级作为数组的index.即以进程的优先级为index,从-1000到+1000 + 1大小的数组,根据优先级,同优先级的进程index相同.每个元素是一个双向链表,这个链表上的所有proc的优先级都相同.这样根据优先级杀进程的时候就会非常方便,要杀指定优先级的进程可以根据优先级获取到一个进程链表,逐个去杀。
static struct adjslot_list procadjslot_list[ADJTOSLOT(OOM_SCORE_ADJ_MAX) + 1];
时序图
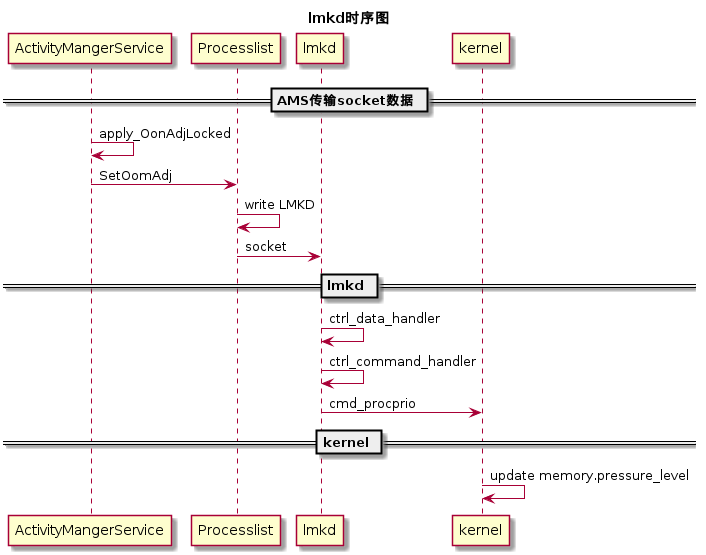
lmkd工作流程
入口main
int main(int argc __unused, char **argv __unused) {
struct sched_param param = {
.sched_priority = 1,
};
/* 2019/04/22 11:15:44 by jinliang
* 将此进程现在和未来所使用到的内存锁在物理内存中,防止被交换
*/
if (mlockall(MCL_CURRENT | MCL_FUTURE | MCL_ONFAULT) && (errno != EINVAL)) {
ALOGW("mlockall failed %s", strerror(errno));
}
/* CAP_NICE required */
/* 2019/04/22 11:18:12 by jinliang */
//设置调度策略为FIFO
if (sched_setscheduler(0, SCHED_FIFO, ¶m)) {
ALOGW("set SCHED_FIFO failed %s", strerror(errno));
}
if (lmfs_enabled)
start_lmfs();
/*
* 进入死循环等待fd事件
*/
mainloop();
}
init
/*1. 初始化socket监听接口ctrl_sock
*2. 创建epollfd套接字epollfd
*3. 填充epoll_event epev
* 1) epoll监听的事件为EPOLLIN
* 2) 监听的fd为ctrl_sock.sock
* 2) 回调函数为 ctrl_sock.handler_info
*4. 监听事件注册*/
static int init(void) {
struct epoll_event epev;
/* 2019/04/15 16:39:00 by jinliang */
/*---get _SC_PAGESIZE value---
* PAGE_SIZE is 4096,so total about 16M?
*/
page_k = sysconf(_SC_PAGESIZE);
if (page_k == -1)
page_k = PAGE_SIZE;
page_k /= 1024;
/*创建一个epoll句柄*/
epollfd = epoll_create(MAX_EPOLL_EVENTS);
/*get the lmkd control socket fd to listen the AMS command*/
ctrl_sock.sock = android_get_control_socket("lmkd");
/*list the socket command pass by AMS*/
/* listen():监听来自客户端的tcp socket的连接请求
* #include<sys/socket.h>
* int listen(int sockfd, int backlog)
* 参数sockfd是被listen函数作用的套接字
* 参数backlog是侦听队列的长度。*/
ret = listen(ctrl_sock.sock, MAX_DATA_CONN);
epev.events = EPOLLIN;
ctrl_sock.handler_info.handler = ctrl_connect_handler;
epev.data.ptr = (void *)&(ctrl_sock.handler_info);
/* 注册监听*/
if (epoll_ctl(epollfd, EPOLL_CTL_ADD, ctrl_sock.sock, &epev) == -1) {
ALOGE("epoll_ctl for lmkd control socket failed (errno=%d)", errno);
return -1;
}
maxevents++;
if (use_inkernel_interface) {
ALOGI("Using in-kernel low memory killer interface");
} else {
/*设置监听/dev/memcg/memory.pressure_level 和 /dev/memcg/cgroup.event_control*/
if (!init_mp_common(VMPRESS_LEVEL_LOW) ||
!init_mp_common(VMPRESS_LEVEL_MEDIUM) ||
!init_mp_common(VMPRESS_LEVEL_CRITICAL)) {
ALOGE("Kernel does not support memory pressure events or in-kernel low memory killer");
return -1;
}
}
return 0;
}
处理socket传递过来的数据
该步主要功能为维护minfree和adj以及process数据链表
在ctrl_connect_handler方法中处理了accept,并开始ctrl_data_handler中读取数据并进行处理:
static void ctrl_command_handler(int dsock_idx) {
len = ctrl_data_read(dsock_idx, (char *)packet, CTRL_PACKET_MAX_SIZE);
cmd = lmkd_pack_get_cmd(packet);
switch(cmd) {
case LMK_TARGET:
targets = nargs / 2;
if (nargs & 0x1 || targets > (int)ARRAY_SIZE(lowmem_adj))
goto wronglen;
cmd_target(targets, packet);
break;
case LMK_PROCPRIO:
if (nargs != 3)
goto wronglen;
cmd_procprio(packet);
break;
case LMK_PROCREMOVE:
if (nargs != 1)
goto wronglen;
cmd_procremove(packet);
break;
case LMK_PROCPURGE:
if (nargs != 0)
goto wronglen;
cmd_procpurge();
break;
case LMK_GETKILLCNT:
if (nargs != 2)
goto wronglen;
kill_cnt = cmd_getkillcnt(packet);
len = lmkd_pack_set_getkillcnt_repl(packet, kill_cnt);
if (ctrl_data_write(dsock_idx, (char *)packet, len) != len)
return;
break;
}
在use_inkernel_interface的情况下,做的事情都是很简单的,只是更新一下文件节点。如果不使用kernel interface,就需要lmkd自己维护两个table,在每次更新adj的时候去更新table。 且在初始化的时候也能看到,如果不使用kernel的lowmemorykiller,则需要lmkd自己获取手机内存状态,如果匹配到了minfree中的等级,则需要通过杀掉一些进程释放内存。
杀进程
杀进程主要是通过之前在init_mp_common 中设置的memory.pressure_level监听回调函数实现mp_event_common:
static void mp_event_common(int data, uint32_t events __unused) {
/*
* when only LMK enabled, we can pass vmpressure & swap-pressure to
* PerformanceManagerService because-of enable_adaptive_lmk,
* PerformanceManagerService then force-stop apps from the LRU list
* according to current vmpressure & swap-pressure;
*
* when only MEMCG enabled, the vmpressure & swap-pressure should also
* be passed to PerformanceManagerService
*/
if (!use_inkernel_interface) {
enum vmpressure_level level = (enum vmpressure_level)data;
int vmpressure_value = 0;
switch (level) {
case VMPRESS_LEVEL_LOW:
vmpressure_value = 70;
break;
case VMPRESS_LEVEL_MEDIUM:
vmpressure_value = 80;
break;
case VMPRESS_LEVEL_CRITICAL:
vmpressure_value = 90;
break;
default:
break;
}
handle_vmpressure(vmpressure_value);
}
}
经过层层调用 mp_event_common->handle_vmpressure->find_and_kill_process_adj->find_and_kill_process_adj_locked->kill_one_process
参考文档:
- https://source.android.com/devices/tech/perf/lmkd
- https://www.sohu.com/a/238012686_467784
- http://gityuan.com/2016/09/17/android-lowmemorykiller/
- https://blog.csdn.net/u011733869/article/details/78820240
??