目录
- 1、正则表达式的装饰符
- 2、查找单个匹配项
- 2.2 group
- 2.3 search
- 2.4 fullmatch
- 2.5 匹配对象
- 3、查找多个匹配项
- 3.1 compile
- 3.2 findall
- 3.3 finditer
- 4、分割split
- 4.1 替换
- 4.1.1 sub
- 4.1.2 subn
- 4.2 escape
- 4.3 purge
在Python中提供了操作正则表达式的模块,即re模块。
1、正则表达式的装饰符
2、查找单个匹配项
2.1 match
re.match 如果 string 开始的0或者多个字符匹配到了正则表达式样式,就返回一个相应的匹配对象 。 如果没有匹配,就返回 None ;注意它跟零长度匹配是不同的。
语法格式:
re.match(pattern, string, flags=0)
pattern:匹配的正则表达式string:要匹配的字符串。flags:标志位,用于控制正则表达式的匹配方式,
如:是否区分大小写,多行匹配等等。
匹配成功re.match方法返回一个匹配的对象,否则返回None。
示例代码:
""" -*- coding:uft-8 -*- author: 小甜 time:2020/5/30 """ import re string1 = "hello python" string2 = "hell5o python" pattern = r"[a-z]+\s\w+" # a-z出现1次到任意次加一个\s加任意字符出现1次到任意次 print(re.match(pattern, string1)) # <re.Match object; span=(0, 12), match='hello python'> print(re.match(pattern, string2)) # None
开局导入
re模块,r""表示为一个正则表达式
因为string2中间出现了一个数字5 所以不匹配
2.2 group
re.group是从Match对象中获取结果的,不过不分组默认为0,分组索引则从0开始(0是完整的一个匹配),如果多个分组,则第一个分组是1;也可以为其命名使用
示例代码:
"""
-*- coding:uft-8 -*-
author: 小甜
time:2020/5/30
"""
import re
string1 = "hello python"
string2 = "hell5o python"
pattern = r"[a-z]+\s\w+"
pattern1 = r"(\w+)(\s)(\w+)"
pattern2 = r"(?P<first>\w+\s)(?P<last>\w+)" # 命名分组
print(re.match(pattern, string1)) # <re.Match object; span=(0, 12), match='hello python'>
print(re.match(pattern, string1).group()) # hello python
print(re.match(pattern, string2)) # None
print(re.match(pattern1, string2).group(0)) # hell5o python
print(re.match(pattern1, string2).group(1)) # hell5o
print(re.match(pattern1, string2).group(2)) # 这里匹配的是那个空格
print(re.match(pattern1, string2).group(3)) # python
print(re.match(pattern2, string2).group("last")) # python
2.3 search
re.search 扫描整个字符串找到匹配样式的第一个位置,并返回一个相应的匹配对象 。如果没有匹配,就返回一个 None ; 注意这和找到一个零长度匹配是不同的。语法结构和match是一样的
示例代码:
""" -*- coding:uft-8 -*- author: 小甜 time:2020/5/30 """ import re string = "Hi World Hello python" pattern = r"Hello python" print(re.search(pattern, string).group()) # Hello python print(re.match(pattern, string)) # None
两者的区别:
re.match只匹配字符串的开始,如果字符串开始不符合正则表达式,则匹配失败,函数返回 None,而 re.search匹配整个字符串,直到找到一个匹配。
2.4 fullmatch
re.fullmatch如果整个 string 匹配这个正则表达式,就返回一个相应的匹配对象 。 否则就返回 None ; 注意跟零长度匹配是不同的。
语法格式跟上面的也是一样的
示例代码:
""" -*- coding:uft-8 -*- author: 小甜 time:2020/5/30 """ import re string = "Hi World Hello python" pattern = r"Hi World Hello python" pattern1 = r"hi World hello python" print(re.fullmatch(pattern, string)) # <re.Match object; span=(0, 21), match='Hi World Hello python'> print(re.fullmatch(pattern1, string)) # None
三者的区别:
match:字符串开头匹配search:查找任意位置的匹配项fullmatch:整个字符串要与正则表达式完全匹配
2.5 匹配对象
匹配对象总是有一个布尔值 True。如果没有匹配的话match() 和 search() 返回 None 所以可以简单的用 if 语句来判断是否匹配
示例代码:
import re
string = "Hi World Hello python"
pattern = r"Hello python"
match1 = re.search(pattern, string)
match2 = re.match(pattern, string)
if match1:
print(match1.group()) # Hello python
if match2: # 因为match2的值为none所以不执行
print(match2.group())
3、查找多个匹配项
3.1 compile
re.compile将正则表达式的样式编译为一个正则对象,可以用于匹配
语法结构:
re.compile(pattern, flags=0)
pattern: 匹配的正则表达式flags: 标志位,用于控制正则表达式的匹配方式,如:是否区分大小写,多行匹配等等。
3.2 findall
re.findall在字符串中找到正则表达式所匹配的所有子串,并返回一个列表,如果没有找到匹配的,则返回空列表。与match 和 search 不同的是 match 和 search 是匹配一次 findall 匹配所有。
语法结构:
re.findall(string[, pos[, endpos]])
string:待匹配的字符串。pos:可选参数,指定字符串的起始位置,默认为 0。endpos:可选参数,指定字符串的结束位置,默认为字符串的长度
3.3 finditer
pattern 在 string 里所有的非重复匹配,返回为一个迭代器保存了匹配对象 。 *string*从左到右扫描,匹配按顺序排列。空匹配也包含在结果里。
语法结构同match
示例代码:
import re
from collections.abc import Iterator # 导入判断是否为迭代器的对象
string = "hello python hi javascript"
pattern = r"\b\w+\b"
pattern_object = re.compile(r"\b\w+\b")
print(type(pattern_object)) # <class 're.Pattern'>
findall = pattern_object.findall(string)
for i in findall:
print(i)
finditer = re.finditer(pattern, string)
# 判断是否为迭代器
print(isinstance(finditer, Iterator)) # True
for _ in range(4):
finditer1 = finditer.__next__() # 取出下一个值
print(finditer1.group())
'''
--循环结果--
hello
python
hi
javascript
'''
如果有超大量的匹配项的话,返回finditer的性能要优于findall,这就是列表和迭代器的区别。
4、分割split
re.split方法按照能够匹配的子串将字符串分割后返回列表
语法结构:
re.split(pattern, string[, maxsplit=0, flags=0])
pattern:匹配的正则表达式string:分隔符。maxsplit:分隔次数,maxsplit=1分隔一次,默认为 0,不限制次数。flags:标志位,用于控制正则表达式的匹配方式,如:是否区分大小写,多行匹配等等。
示例代码:
import re string = '''hello hi good morning goodnight python javascript Linux ''' pattern = r'\s+' # 以空格回车制表符为回车符 print(re.split(pattern, string)) # 不限制次数分隔 # ['hello', 'hi', 'good', 'morning', 'goodnight', 'python', 'javascript', 'Linux', ''] print(re.split(pattern, string, 5)) # 分隔5次 # ['hello', 'hi', 'good', 'morning', 'goodnight', 'python\njavascript\nLinux\n']
与str模块的split不同的是,re模块的split支持正则
4.1 替换
4.1.1 sub
re.sub用于替换字符串中的匹配项
语法结构:
re.sub(pattern, repl, string, count=0, flags=0)
pattern: 正则中的模式字符串。repl: 替换的字符串,也可为一个函数。string: 要被查找替换的原始字符串。count: 模式匹配后替换的最大次数,默认 0 表示替换所有的匹配。flags: 编译时用的匹配模式,数字形式。
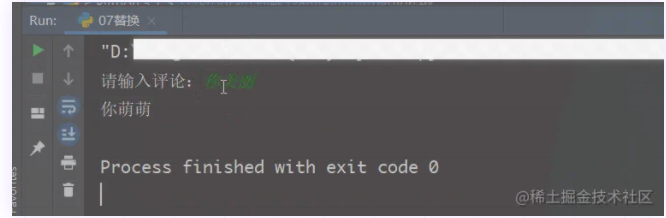
到这里就可以完成一个某手的评论区,修改不良评论的小案例
import re
string = input("请输入评论:")
pattern = r"[美丽可爱大方]{1}" # 检测的字符
print(re.sub(pattern, "萌", string))
效果图:

4.1.2 subn
行为与 sub() 相同,但是返回一个元组 (字符串, 替换次数).
4.2 escape
re.escape(pattern)转义 pattern 中的特殊字符。例如正则里面的元字符.
示例代码:
import re pattern = r'\w\s*\d\d.' # 打印pattern的特殊字符 print(re.escape(pattern)) # \w\s*\d\d.
任意可能包含正则表达式元字符的文本字符串进行匹配,它就是有用的,不过容易出现错误,手动转义比较好
4.3 purge
re.purge()清除正则表达式的缓存。
到此这篇关于Python 正则模块详情的文章就介绍到这了,更多相关Python 正则模块内容请搜索易盾网络以前的文章或继续浏览下面的相关文章希望大家以后多多支持易盾网络!