目录
- 原生批量插入的“坑”
- 解决方案
- 分片 Demo 实战
- 原生批量插入分片实现
- 总结
前面的文章咱们讲了 MyBatis 批量插入的 3 种方法:循环单次插入、MyBatis Plus 批量插入、MyBatis 原生批量插入,详情请点击《MyBatis 批量插入数据的 3 种方法!》
但之前的文章也有不完美之处,原因在于:使用 「循环单次插入」的性能太低,使用「MyBatis Plus 批量插入」性能还行,但要额外的引入 MyBatis Plus 框架,使用「MyBatis 原生批量插入」性能最好,但在插入大量数据时会导致程序报错,那么,今天咱们就会提供一个更优的解决方案。
原生批量插入的“坑”
首先,我们来看一下 MyBatis 原生批量插入中的坑,当我们批量插入 10 万条数据时,实现代码如下:
import com.example.demo.model.User;
import com.example.demo.service.impl.UserServiceImpl;
import org.junit.jupiter.api.Test;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.boot.test.context.SpringBootTest;
import java.util.ArrayList;
import java.util.List;
@SpringBootTest
class UserControllerTest {
// 最大循环次数
private static final int MAXCOUNT = 100000;
@Autowired
private UserServiceImpl userService;
/**
* 原生自己拼接 SQL,批量插入
*/
@Test
void saveBatchByNative() {
long stime = System.currentTimeMillis(); // 统计开始时间
List<User> list = new ArrayList<>();
for (int i = 0; i < MAXCOUNT; i++) {
User user = new User();
user.setName("test:" + i);
user.setPassword("123456");
list.add(user);
}
// 批量插入
userService.saveBatchByNative(list);
long etime = System.currentTimeMillis(); // 统计结束时间
System.out.println("执行时间:" + (etime - stime));
}
}
核心文件 UserMapper.xml 中的实现代码如下:
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE mapper PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN" "http://mybatis.org/dtd/mybatis-3-mapper.dtd">
<mapper namespace="com.example.demo.mapper.UserMapper">
<insert id="saveBatchByNative">
INSERT INTO `USER`(`NAME`,`PASSWORD`) VALUES
<foreach collection="list" separator="," item="item">
(#{item.name},#{item.password})
</foreach>
</insert>
</mapper>
当我们开心地运行以上程序时,就出现了以下的一幕:
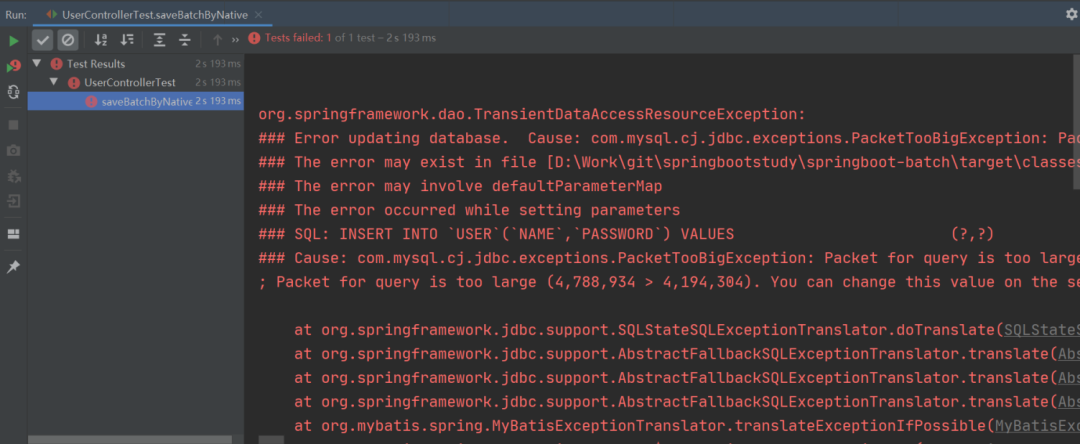
沃,程序竟然报错了!
这是因为使用 MyBatis 原生批量插入拼接的插入 SQL 大小是 4.56M,而默认情况下 MySQL 可以执行的最大 SQL 为 4M,那么在程序执行时就会报错了。
解决方案
以上的问题就是因为批量插入时拼接的 SQL 文件太大了,所以导致 MySQL 的执行报错了。那么我们第一时间想到的解决方案就是将大文件分成 N 个小文件,这样就不会因为 SQL 太大而导致执行报错了。也就是说,我们可以将待插入的 List 集合分隔为多个小 List 来执行批量插入的操作,而这个操作过程就叫做 List 分片。
有了处理思路之后,接下来就是实操了,那如何对集合进行分片操作呢?
分片操作的实现方式有很多种,这个我们后文再讲,接下来我们使用最简单的方式,也就是 Google 提供的 Guava 框架来实现分片的功能。
分片 Demo 实战
要实现分片功能,第一步我们先要添加 Guava 框架的支持,在 pom.xml 中添加以下引用:
<!-- google guava 工具类 --> <!-- https://mvnrepository.com/artifact/com.google.guava/guava --> <dependency> <groupId>com.google.guava</groupId> <artifactId>guava</artifactId> <version>31.0.1-jre</version> </dependency>
接下来我们写一个小小的 demo,将以下 7 个人名分为 3 组(每组最多 3 个),实现代码如下:
import com.google.common.collect.Lists;
import java.util.Arrays;
import java.util.List;
/**
* Guava 分片
*/
public class PartitionByGuavaExample {
// 原集合
private static final List<String> OLD_LIST = Arrays.asList(
"唐僧,悟空,八戒,沙僧,曹操,刘备,孙权".split(","));
public static void main(String[] args) {
// 集合分片
List<List<String>> newList = Lists.partition(OLD_LIST, 3);
// 打印分片集合
newList.forEach(i -> {
System.out.println("集合长度:" + i.size());
});
}
}
以上程序的执行结果如下:
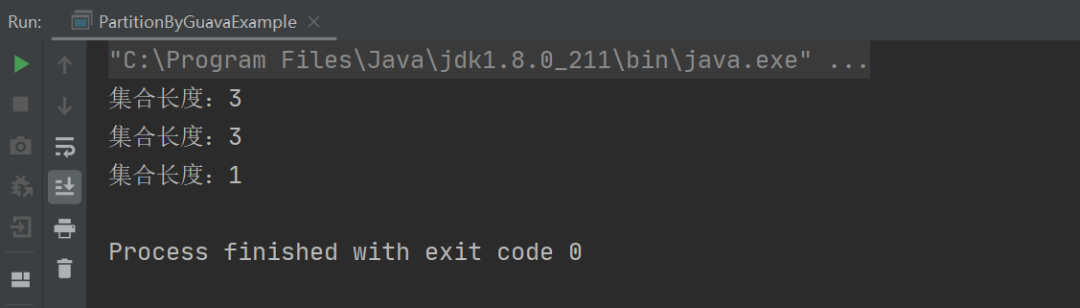
从上述结果可以看出,我们只需要使用 Guava 提供的 Lists.partition 方法就可以很轻松的将一个集合进行分片了。
原生批量插入分片实现
那接下来,就是改造我们的 MyBatis 批量插入代码了,具体实现如下:
@Test
void saveBatchByNativePartition() {
long stime = System.currentTimeMillis(); // 统计开始时间
List<User> list = new ArrayList<>();
// 构建插入数据
for (int i = 0; i < MAXCOUNT; i++) {
User user = new User();
user.setName("test:" + i);
user.setPassword("123456");
list.add(user);
}
// 分片批量插入
int count = (int) Math.ceil(MAXCOUNT / 1000.0); // 分为 n 份,每份 1000 条
List<List<User>> listPartition = Lists.partition(list, count);
// 分片批量插入
for (List<User> item : listPartition) {
userService.saveBatchByNative(item);
}
long etime = System.currentTimeMillis(); // 统计结束时间
System.out.println("执行时间:" + (etime - stime));
}
执行以上程序,最终的执行结果如下:
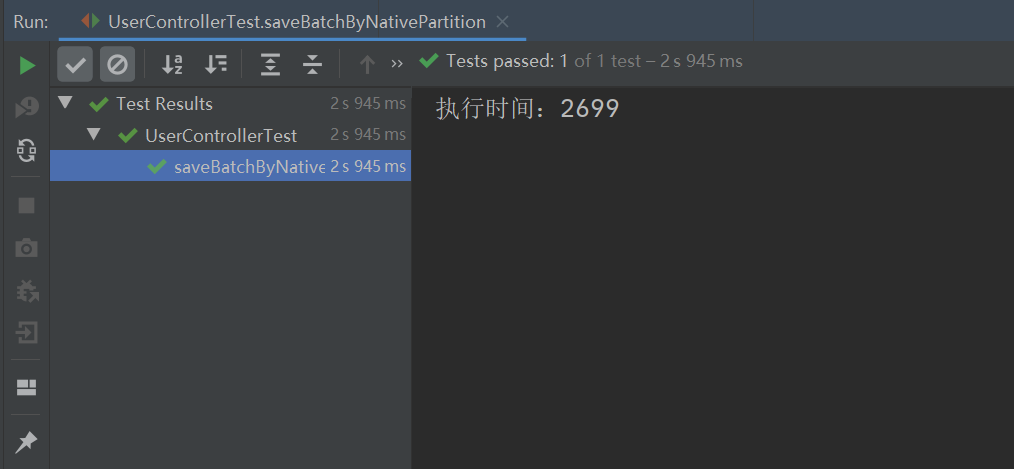
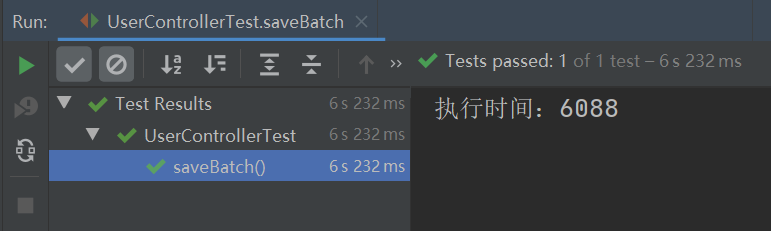
从上图可以看出,之前批量插入时的异常报错不见了,并且此实现方式的执行效率竟比 MyBatis Plus 的批量插入的执行效率要高,MyBatis Plus 批量插入 10W 条数据的执行时间如下:
总结
本文我们演示了 MyBatis 原生批量插入时的问题:可能会因为插入的数据太多从而导致运行失败,我们可以通过分片的方式来解决此问题,分片批量插入的实现步骤如下:
- 计算出分片的数量(分为 N 批);
- 使用 Lists.partition 方法将集合进行分片(分为 N 个集合);
- 循环将分片的集合进行批量插入的操作。
到此这篇关于浅谈MyBatis原生批量插入的坑与解决方案的文章就介绍到这了,更多相关MyBatis原生批量插入内容请搜索自由互联以前的文章或继续浏览下面的相关文章希望大家以后多多支持自由互联!