目录
- 1、Python 多线程处理的基本指南
- 2、多处理入门
- 3、它为什么如此重要?
- 4、实现
- 5、基准测试
Python 是一种流行的编程语言,也是数据科学社区中最受欢迎的语言。与其他流行编程语言相比,Python 的主要缺点是它的动态特性和多功能属性拖慢了速度表现。Python 代码是在运行时被解释的,而不是在编译时被编译为原生代码。
1、Python 多线程处理的基本指南
C 语言的执行速度比 Python 代码快 10 到 100 倍。但如果对比开发速度的话,Python 比 C 语言要快。对于数据科学研究来说,开发速度远比运行时性能更重要。由于存在大量 API、框架和包,Python 更受数据科学家和数据分析师的青睐,只是它在性能优化方面落后太多了。
2、多处理入门
考虑一个单核心 CPU,如果它被同时分配多个任务,就必须不断地中断当前执行的任务并切换到下一个任务才能保持所有进程正常运行。对于多核处理器来说,CPU 可以在不同内核中同时执行多个任务,这一概念被称为并行处理。
3、它为什么如此重要?
数据整理、特征工程和数据探索都是数据科学模型开发管道中的重要元素。在输入机器学习模型之前,原始数据需要做工程处理。对于较小的数据集来说,执行过程只需几秒钟就能完成;但对于较大的数据集而言,这项任务就比较繁重了。
并行处理是提高 Python 程序性能的一种有效方法。Python 有一个多处理模块,让我们能够跨 CPU 的不同内核并行执行程序。
4、实现
我们将使用来自 multiprocessing 模块的 Pool 类,针对多个输入值并行执行一个函数。这个概念称为数据并行性,它是 Pool 类的主要目标。
我将使用从
Kaggle下载的Quora问题对相似性数据 集来演示这个模块。
上述数据集包含了很多在 Quora 平台上提出的文本问题。我将在一个 Python 函数上执行多处理模块,这个函数通过删除停用词、删除 HTML 标签、删除标点符号、词干提取等过程来处理文本数据。
preprocess()就是执行上述文本处理步骤的函数。
可以在 这里 找到托管在我的 GitHub 上的函数 preprocess() 的代码片段。
现在,我们使用 multiprocessing 模块中的 Pool 类为数据集的不同块并行执行该函数。数据集的每个块都将并行处理。
import multiprocessing
from functools import partial
from QuoraTextPreprocessing import preprocess
BUCKET_SIZE = 50000
def run_process(df, start):
df = df[start:start+BUCKET_SIZE]
print(start, "to ",start+BUCKET_SIZE)
temp = df["question"].apply(preprocess)
chunks = [x for x in range(0,df.shape[0], BUCKET_SIZE)]
pool = multiprocessing.Pool()
func = partial(run_process, df)
temp = pool.map(func,chunks)
pool.close()
pool.join()
该数据集有 537,361 条记录(文本问题)需要处理。对于 50,000 的桶大小,数据集被分成 11 个较小的数据块,这些块可以并行处理以加快程序的执行时间。
5、基准测试
人们常问的问题是使用多处理模块后执行速度能快多少。我在实现了数据并行性,对整个数据集执行一次 preprocess() 函数后对比了基准执行时间。
运行测试的机器有 64GB 内存和 10 个 CPU 内核。
多处理和单处理执行的基准时间:
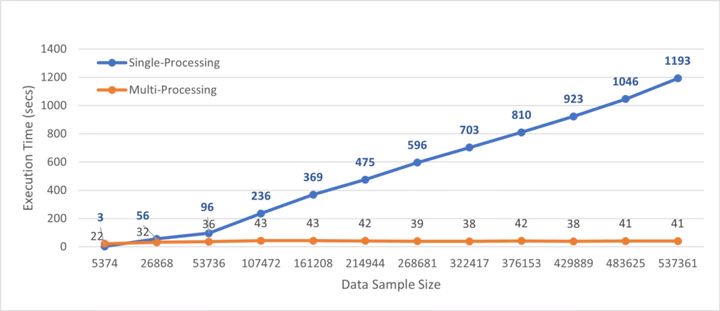
从上图中,我们可以观察到 Python 函数的并行处理将执行速度提高了近 30 倍。
我们可以在我的
GitHub中找到用于记录基准测试数据的Python文件。
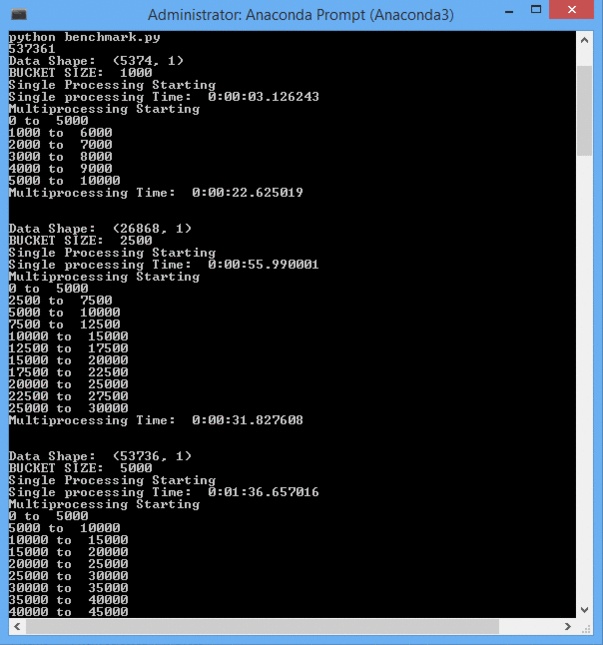
基准测试过程:
结 论:
在本文中,我们讨论了 Python 中多处理模块的实现,该模块可用于加速 Python 函数的执行。添加几行多处理代码后,具有 537k 实例的数据集的执行时间几乎快了 30 倍。
处理大型数据集的时候,我建议大家使用并行处理,因为它可以节省大量时间并加快工作流程。
到此这篇关于几行代码让 Python 函数执行快 30 倍的文章就介绍到这了,更多相关Python 函数执行内容请搜索易盾网络以前的文章或继续浏览下面的相关文章希望大家以后多多支持易盾网络!