目录 一、列操作 二、行操作 总结 准备导入的excel为: 可以采用pandas的read_excel功能, 具体代码如下 : import pandas as pdgetdata=pd.read_excel(r'C:/文件夹索引/文件名.xlsx', sheet_name='工作表she
目录
- 一、列操作
- 二、行操作
- 总结
准备导入的excel为:
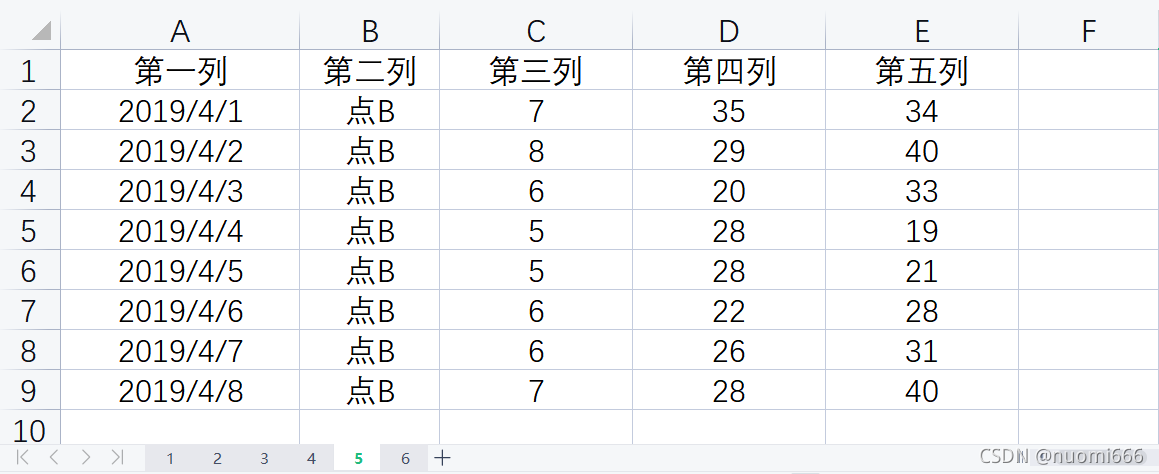
可以采用pandas的read_excel功能,具体代码如下:
import pandas as pd
getdata=pd.read_excel(r'C:/文件夹索引/文件名.xlsx',
sheet_name='工作表sheet的名字')
sheet_name不设置参数,就默认第一个工作表,同时也可设置工作表的位置,读取第5个工作表可以设置为=4。
一、列操作
如果对获取工作表其中的某列或者多列,可以使用usecols参数,比如读取第5个工作表的第2列到第5列,可以用下面的代码:
import pandas as pd
getdata=pd.read_excel(r'C:/文件夹索引/文件名.xlsx',
sheet_name='工作表sheet的名字',
sheet_name=4,
usecols=[i for i in range (1,6)])
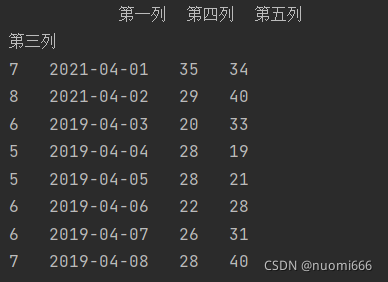
usecols参数也可以设置成列的索引字母,比如usecols="B,D:E",可以获取第1和3到5列,同时设置参数index_col=1,把第二列当作索引,代码及输出结果为:
getdata=pd.read_excel(r'C:/文件夹索引/文件名.xlsx',
sheet_name='工作表sheet的名字',
sheet_name=4,
usecols="A,C:E",
index_col=1)
print(Getdata)
二、行操作
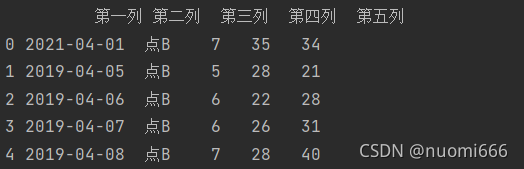
如果不想获取全部行数,如获取前5行可以设置参数nrows=5,同时跳过第2行到第4行,可以设置参数skiprows=[i for i in range(2,5)],或者skiprows=[2,3,4],代码及输出结果:
getdata=pd.read_excel(r'C:/文件夹索引/文件名.xlsx',
sheet_name='工作表sheet的名字',
skiprows=[2,3,4],
nrows=5)
print(Getdata)
这里应当注意,设置的nrows是总共要获取多少行,如果设置skiprows跳过一定数量行后,将在之后行里继续获取,直到补足nrows所要获取的行数。
总结
本篇文章就到这里了,希望能够给你带来帮助,也希望您能够多多关注易盾网络的更多内容!