我们知道现实中的数据通常是杂乱无章的,需要大量的预处理才能使用。Pandas 是应用最广泛的数据分析和处理库之一,它提供了多种对原始数据进行预处理的方法。
import numpy as np
import pandas as pd
df = pd.DataFrame({
"id": [100, 100, 101, 102, 103, 104, 105, 106],
"A": [1, 2, 3, 4, 5, 2, np.nan, 5],
"B": [45, 56, 48, 47, 62, 112, 54, 49],
"C": [1.2, 1.4, 1.1, 1.8, np.nan, 1.4, 1.6, 1.5]
})
df
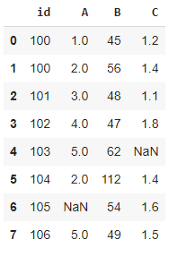
上述数据中 NaN 表示的缺失值,id 列包含重复的值,B 列中的 112 似乎是一个异常值。
这些就是现实数据中的一些典型问题。我们将创建一个管道来处理刚才描述的问题。对于每个任务,我们都需要一个函数。因此,首先是创建放置在管道中的函数。需要注意的是,管道中使用的函数需要将数据帧作为参数并返回数据帧。
第一个函数是处理缺少的值
def fill_missing_values(df):
for col in df.select_dtypes(include= ["int","float"]).columns:
val = df[col].mean()
df[col].fillna(val, inplace=True)
return df
我喜欢用列的平均值替换数字列中缺少的值,当然你也可以根据具体场景来定义。只要它将数据帧作为参数并返回数据帧,它就可以在管道中工作。
第二个函数是帮助我们删除重复的值
def drop_duplicates(df, column_name): df = df.drop_duplicates(subset=column_name) return df
调用 Pandas 内置的 drop duplicates 函数,它可以消除给定列中的重复值。
最后一个函数是用于消除异常值
def remove_outliers(df, column_list):
for col in column_list:
avg = df[col].mean()
std = df[col].std()
low = avg - 2 * std
high = avg + 2 * std
df = df[df[col].between(low, high, inclusive=True)]
return df
此函数的作用如下:
- 需要一个数据帧和一列列表
- 对于列表中的每一列,它计算平均值和标准偏差
- 计算标准差,并使用下限平均值
- 删除下限和上限定义的范围之外的值
与前面的函数一样,你可以选择自己的检测异常值的方法。
创建管道
我们现在有3个函数来进行数据预处理的任务。接下来就是使用这些函数创建管道。
df_processed = (df.pipe(fill_missing_values).pipe(drop_duplicates, "id").pipe(remove_outliers, ["A","B"]))
此管道按给定顺序执行函数。我们可以将参数和函数名一起传递给管道。
这里需要提到的一点是,管道中的一些函数修改了原始数据帧。因此,使用上述管道也将更新df。
解决此问题的一个方法是在管道中使用原始数据帧的副本。如果你不关心保持原始数据帧的原样,那么可以在管道中使用它。
我将更新管道,如下所示:
my_df = df.copy() df_processed = (my_df.pipe(fill_missing_values).pipe(drop_duplicates, "id").pipe(remove_outliers, ["A","B"]))
让我们看一下原始数据帧和处理后的数据帧:

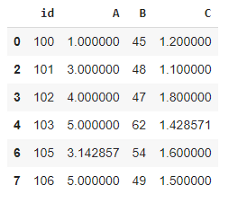
结论
当然,你可以通过单独使用这些函数来完成相同的任务。但是,管道函数提供了一种结构化和有组织的方式,可以将多个功能组合到单个操作中。
根据原始数据和任务,预处理可能包括更多步骤。可以根据需要在管道函数中添加任意数量的步骤。随着步骤数量的增加,与单独执行函数相比,管道函数的语法变得更清晰。
以上就是python优化数据预处理方法Pandas pipe详解的详细内容,更多关于pandas pipe数据预处理优化的资料请关注易盾网络其它相关文章!