本文实例为大家分享了微信小程序实现瀑布流分页滚动加载的具体代码,供大家参考,具体内容如下
两种分页方式
普通的分页效果会在页面底部提供点击下一页和上一页的按钮,在点击了按钮之后才会触发调取数据的接口,这种方式的用户体验一般
另一种分页效果不需要用户点击按钮,只要浏览到当前页面的后几条数据时,系统会自动发送请求获取后一页的数据,并展示到页面上,这样就可以实现类似无限滚动的效果
以csdn为例,当滚动条到达这个地方时,会自动调用请求下一页数据的接口,然后累加到加载完成的数据列表中
实现思路
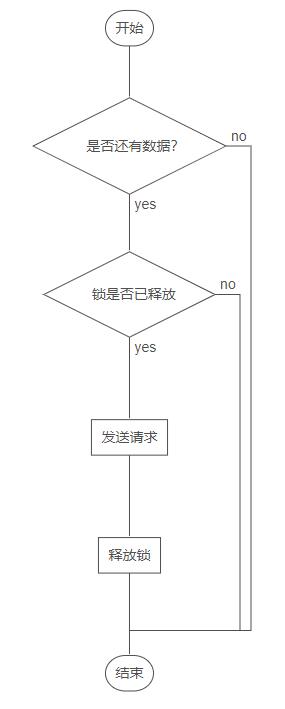
滚动分页的方式存在一个问题,当用户滚动的非常快时,可能会导致第一次请求还未完成,第二次请求就开始了,为了避免这个问题,我们可以加入一个锁标识,发送一次请求后加锁,请求完成后释放锁,这样就可以完美避免这种问题
得出实现思路
1、判断是否还有可加载的数据
2、获取锁
3、发送请求,调用接口
4、释放锁
5、返回数据
代码实现
首先我们需要一个paging对象
class Paging{
page //记录当前页码
count //记录一页显示的数量
req //接口请求对象(此处我已封装,可按照自己需求定义属性)
url //请求路径
moreData = true //是否存在下一页数据(首次请求时默认存在下一页数据)
accumulator = [] //已加载的数据列表
locker = false //锁标识
}
为paging对象定义一个构造器,默认从第一页开始请求,每页五条数据
constructor(req, page=0, count=5){
this.page = page
this.count = count
this.req = req
this.url = req.url
}
接下来编写getMoreData方法
getMoreData(){
//1、判断是否存在下一页数据
//2、获取锁,判断锁是否为释放状态
//3、请求数据
//4、释放锁
}
1、判断是否存在下一页数据
这里直接获取moreData属性进行判断
if(!this.moreData){
return
}
2、获取锁
此处新增一个方法,如果当前没有锁,代表可以继续请求数据,在请求数据前先把锁标识设置为true,防止下次请求继续发送
_getLocker(){
if(this.locker){
return false
}
this.locker = true
return true
}
3、请求数据
我们需要返回给页面的数据结构如下:
{
empty, //是否为空
items, //当前页数据
moreData, //是否存在下一页数据
accumulator //已经请求过的所有数据
}
首先定义一个获取请求结构的方法
_getCurrentReq(){
let url = this.url
//设置请求参数
const params = `page=${this.page}&count=${this.count}`
//判断拼接方式
if(url.includes('?')){
url += '&' + params
}else{
url += '?' + params
}
this.req.url = url
return this.req
}
获取数据的方法如下:
_actualGetData(){
const req = this._getCurrentReq() //获取到具体的请求内容
let paging = Http.request(req) //调用自定义工具中的请求方法,进行数据的获取
//如果没有获取到结果直接返回null
if(!paging){
return null
}
if(paging.total === 0){
return {
empty: true,
items: [],
moreData: false,
accumulator: []
}
}
//如果当前页码数小于总页码数表示还存在下一页数据,设置moreData为true,否则设置为false
this.moreData = pageNum < totalPage-1 ? true : false
//如果存在下页数据,将page+1,便于下次的获取
if(this.moreData){
this.page += 1
}
//因瀑布流显示数据需要累加展示,所以数据列表也需要累加
this.accumulator = this.accumulator.concat(paging.items)
return{
empty: false,
items: paging.items,
moreData: this.moreData,
accumulator: this.accumulator
}
}
4、释放锁
释放锁直接将锁标识的状态改变即可
this.locker = false
getMoreData方法编写完毕,然后就可以在对应界面的js文件中进行调用了
在第一次进入界面时,需要自动调用一次,然后在用户每次触底时再次调用
initBottomSpuList(){
//获取到paging对象
const paging = new Paging({
url: url
})
//将paging对象存入js的data中
this.data.spuPaging = paging
//调用方法
const data = paging.getMoreData()
if(!data){
return
}
//重新加载瀑布流
wx.lin.renderWaterFlow(data.items)
},
微信小程序有自带的触底时自动触发的函数,将方法调用的代码写入这个函数即可
onReachBottom: function () {
const data = this.data.spuPaging.getMoreData()
if(!data){
return
}
//重新加载瀑布流
wx.lin.renderWaterFlow(data.items)
}
至此,就可以实现瀑布流分页滚动加载的效果了
以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持自由互联。