在C/C++中有个叫指针的玩意存在感极其强烈,而说到指针又不得不提到内存管理。现在时不时能听到一些朋友说指针很难,实际上说的是内存操作和管理方面的难。(这篇笔记咱也会结合自己的理解简述一些相关的内存知识)
最近在写C程序使用指针的时候遇到了几个让我印象深刻的地方,这里记录一下,以便今后回顾。

指针和二级指针“经一蹶者长一智,今日之失,未必不为后日之得。” - 王阳明《与薛尚谦书》
简述下指针的概念。
指针一个指针可以理解为一条内存地址。
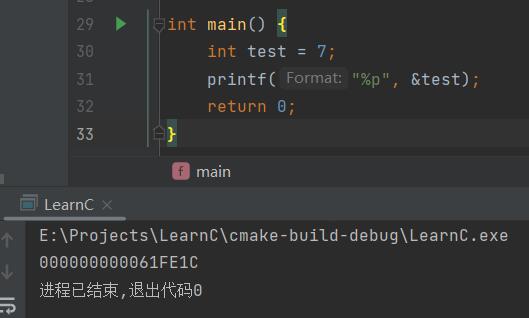
指针变量这里先定义了一个整型变量
test,接着用取址运算符&取得这个变量的内存地址并打印出来。
可以看到该变量的内存地址是000000000061FE1C
指针变量就是存放指针(也就是存放内存地址)的变量,使用数据类型* 变量名进行定义。
值得注意的是指针变量内储存的指针(内存地址)所代表的变量的数据类型,比如int*定义的指针变量就只能指向int类型的变量。
int test = 233;
int* ptr = &test;
二级指针
test变量的类型是整型int,所以test存放的就是一个整形数据。
而ptr变量的类型是整型指针类型int*,存放则的是整性变量test的指针(内存地址)。
二级指针指的是一级指针变量的地址。
int main() {
int test = 233;
printf("%p\n", &test);
int *ptr = &test;
printf("%p", &ptr);
return 0;
}
/* stdout
000000000061FE1C
000000000061FE10
*/
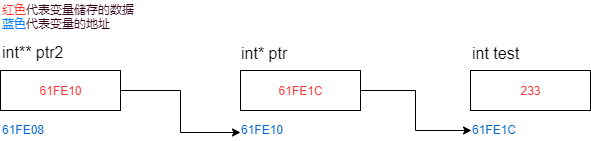
二级指针变量这个例子中二级指针就是
ptr变量的地址000000000061FE10。
二级指针变量就是存放二级指针(二级指针的地址)的变量,使用数据类型** 变量名进行定义。
int main() {
int test = 233;
int *ptr = &test;
int **ptr2 = &ptr;
return 0;
}
ptr变量的类型是整型指针类型int*,存放的是整性(int)变量test的指针(内存地址),
ptr2变量的类型是二级整型指针类型int**,存放的是整性指针(int*)变量ptr的内存地址。
虽然二级以上的指针变量相对来说不太常用,但我觉得基本的辨别方法还是得会的:
通过观察发现,指针变量的数据类型定义其实就是在其所指向的数据类型名后加一个星号,
比如说:
-
指针
ptr指向整型变量int test,那么它的定义写法就是int* ptr。(数据类型在int后加了一个星号) -
指针
ptr2指向一级指针变量int* ptr,那么它的定义写法就是int** ptr2。(数据类型在int*后加了一个星号)
再三级指针变量int*** ptr3,乍一看星号这么多,实际上“剥”一层下来就真相大白了:
(int**)*
实际上三级指针变量指向的就是二级指针变量的地址。

其他更多级的指针变量可以依此类推。
栈内存和堆内存指针和内存操作关系紧密,提到指针总是令人情不自禁地想起内存。
程序运行时占用的内存空间会被划分为几个区域,其中和这篇笔记息息相关的便是栈区(Stack)和堆区(Heap)。
栈区 (Stack)栈区的操作方式正如数据结构中的栈,是LIFO后进先出的。这种操作模式的一个很经典的应用就是递归函数了。
每个函数被调用时需要从栈区划分出一块栈内存用来存放调用相关的信息,这块栈内存被称为函数的栈帧。
栈帧存放的内容主要是(按入栈次序由先至后):
-
返回地址,也就是函数被调用处的下一条指令的内存地址(内存中专门有代码区用于存放),用于函数调用结束返回时能接着原来的位置执行下去。
-
函数调用时的参数值。
-
函数调用过程中定义的局部变量的值。
-
and so on...
由LIFO后进先出可知一次函数调用完毕后相较而言局部变量先出栈,接着是参数值,最后栈顶指针指向返回地址,函数返回,接着下一条指令执行下去。
栈区的特性:
-
交由系统(C语言这儿就是编译器参与实现)自动分配和释放,这点在函数调用中体现的很明显。
-
分配速度较快,但并不受程序员控制。
-
相对来说空间较小,如果申请的空间大于栈剩余的内存空间,会引发栈溢出问题。(栈内存大小限制因操作系统而异)
比如递归函数控制不当就会导致栈溢出问题,因为每层函数调用都会形成新的栈帧“压到”栈上,如果递归函数层数过高,栈帧迟迟得不到“弹出”,就很容易挤爆栈内存。
-
栈内存占用大小随着函数调用层级升高而增大,随着函数调用结束逐层返回而减小;也随着局部变量的定义而增大,随着局部变量的销毁而减小。
栈内存中储存的数据的生命周期很清晰明确。
-
栈区是一片连续的内存区域。
堆区 (Heap)
堆内存就真的是“一堆”内存,值得一提的是,这里的堆和数据结构中的堆没有关系。
相对栈区来说,堆区可以说是一个更加灵活的大内存区,支持按需进行动态分配。
堆区的特性:
-
交由程序员或者垃圾回收机制进行管理,如果不加以回收,在整个程序没有运行完前,分配的堆内存会一直存在。(这也是容易造成内存泄漏的地方)
在C/C++中,堆内存需要程序员手动申请分配和回收。
-
分配速度较慢,系统需要依照算法搜索(链表)足够的内存区域以分配。
-
堆区空间比较大,只要还有可用的物理内存就可以持续申请。
-
堆区是不连续(离散)的内存区域。(大概是依赖链表来进行分配操作的)
-
现代操作系统中,在程序运行完后会回收掉所有的堆内存。
要养成不用就释放的习惯,不然运行过程中进程占用内存可能越来越大。
简述C中堆内存的分配与释放 分配
这里咱就直接报菜名吧!

这一部分的函数的原型都定义在头文件stdlib.h中。
-
void* malloc(size_t size)用于请求系统从堆区中分配一段连续的内存块。
-
void* calloc(size_t n, size_t size);在和
malloc一样申请到连续的内存块后,将所有分配的内存全部初始化为0。 -
void* realloc(void* block, size_t size)修改已经分配的内存块的大小(具体实现是重新分配),可以放大也可以缩小。
malloc可以记成Memory Allocate 分配内存;
calloc可以记成Clear and Allocate 分配并设置内存为0;
realloc可以记成Re-Allocate 重分配内存。
简单来说原理大概是这样:
-
malloc内存分配依赖的数据结构是链表。简单说来就是所有空闲的内存块会被组织成一个空闲内存块链表。 -
当要使用
malloc分配内存时,它首先会依据算法扫描这个链表,直到找到一个大小满足需求的空闲内存块为止,然后将这个空闲内存块传递给用户(通过指针)。
(如果这块的大小大于用户所请求的内存大小,则将多余部分“切出来”接回链表中)。 -
在不断的分配与释放过程中,由于内存块的“切割”,大块的内存可能逐渐被切成许多小块内存存在链表中,这些便是内存碎片。当
malloc找不到合适大小的内存块时便会尝试合并这些内存碎片以获得大块空闲的内存。 -
实在找不到空闲内存块的情况下,
malloc会返回NULL指针。
释放
释放手动分配的堆内存需要用到free函数:
void free(void* block)
只需要传入指向分配内存始址的指针变量作为实参传入即可。
在
C/C++中,对于手动申请分配的堆内存在使用完后一定要及时释放,
不然在运行过程中进程占用内存可能会越来越大,也就是所谓的内存泄漏。
不过在现代操作系统中,程序运行完毕后OS会自动回收对应进程的内存,包括泄露的内存。内存泄露指的是在程序运行过程中无法操作的内存。
free为什么知道申请的内存块大小?
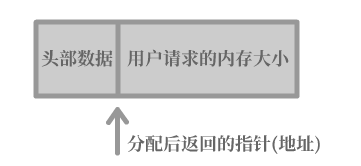
简单来说,就是在malloc进行内存分配时会把内存大小分配地略大一点,多余的内存部分用于储存一些头部数据(这块内存块的信息),这块头部数据内就包括分配的内存的长度。
但是在返回指针的时候,malloc会将其往后移动,使得指针代表的是用户请求的内存块的起始地址。
头部数据占用的大小通常是固定的(网上查了一下有一种说法是16字节,也有说是sizeof(size_t)的),在将指针传入free后,free会将指针向前移动指定长度以获得头部数据,读取到分配的内存长度,然后连同头部数据和所分配长度的内存一并释放掉。
内存释放可以理解为这块内存被重新接到了空闲链表上,以备后面的分配。
(实际上内存释放后的情况其实挺复杂的,得要看具体的算法实现和运行环境)
二维数组 定义和初始化
C语言中二维数组的定义:
数据类型 数组名[行数][列数];
初始化则可以使用大括号:
int a[3][4]={
{1,2,3,4},
{5,6,7,8},
{9,10,11,12}
};
int b[3][4]={ // 内层不要大括号也是可以的,具体为什么后面再说
1,2,3,4,
5,6,7,8,
9,10,11,12
};
char str[2][6]={
"Hello",
"World"
};
此外,在有初始化值的情况下,定义二维数组时的一维长度(行数)是可以省略的:
int a[][4]={ // 如果没有初始化,则一维长度不可省略
1,2,3,4,
5,6,7,8,
9,10,11,12
}
按上述语句定义的数组,在进程内存中一般储存于:
-
栈区 - 在函数内部定义的局部数组变量。
-
静态储存区 - 当用
static修饰数组变量或者在全局作用域中定义数组。
数组在内存中是连续且呈线性储存的,二维数组也是不例外的。
虽然在使用过程中二维数组发挥的是“二维”的功能,但其在内存中是被映射为一维线性结构进行储存的。
实践验证一下:
int i, j;
int a[][4] = { // 如果没有初始化,则一维长度不可省略
1, 2, 3, 4,
5, 6, 7, 8,
9, 10, 11, 12
};
size_t len1 = sizeof(a) / sizeof(a[0]);
size_t len2 = sizeof(a[0]) / sizeof(a[0][0]);
for (i = 0; i < len1; i++) {
for (j = 0; j < len2; j++)
printf(" [%d]%p ", a[i][j], &a[i][j]);
printf("\n");
}
输出:

第一维有3行,第二维有4列。
一个int类型数据占用4个字节,从上面的图可以看出来:
-
[1]000000000061FDD0->[2]000000000061FDD4相隔4字节,说明这两个数组元素相邻,同一行中数组元素储存连续。 -
[4]000000000061FDDC->[5]000000000061FDE0同样相隔4字节,这两个数组元素在内存中也是相邻的。 -
从
[1]000000000061FDD0到[12]000000000061FDFC正好相差44个字节,整个二维数组元素在内存中是连续储存的。
这样一看,为什么定义并初始化的时候二维数组的第一维可以省略已经不言而喻了:
在初始化的时候编译器通过数组第二维的大小对元素进行“分组”,每一组可以看作是一个一维数组,这些一维数组在内存中从低地址到高地址连续排列储存形成二维数组:
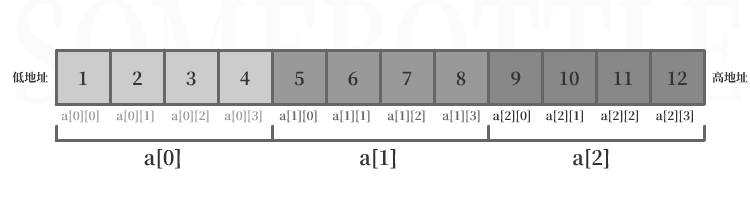
二维数组名代表的地址在上面例子中大括号中的元素
{1,2,3,4,5,6,7,8,9,10,11,12}被按第二维长度4划分成了{1,2,3,4},{5,6,7,8},{9,10,11,12}三组,这样程序也能知道第一维数组长度为3了。
一维数组名代表的是数组的起始地址(也是第一个元素的地址)。
二维数组在内存中也是映射为一维进行连续储存的,
既然如此,二维数组名代表的地址其实也是整个二维数组的起始地址,在上面的例子中相当于a[0][0]的地址。
在上面的示例最后加一行:
printf("Arr address: %p", a);
打印出来的地址和a[0][0]的地址完全一致,是000000000061FDD0。
首先要明确一点:二维数组 ≠ 二级指针
刚接触C语言时我总是想当然地把这两个搞混了,实际上根本不是一回事儿。
-
二级指针变量储存的是一级指针变量的地址。
-
二维数组是内存中连续储存的一组数据,二维数组名相当于一个一级指针(二维数组的起始地址)。
int arr[][4]={
{1,2},{1},{3},{4,5}
};
int** ptr=arr; // 这样写肯定是不行的!,ptr储存的是一级指针变量的地址
int* ptr=arr; // 这样写是可以的,但是不建议
int* ptr=&arr[0][0]; // 这样非常ok, ptr储存的是数组起始地址(也就是首个变量的地址)
可以把之前二维数组的例子改一下:
int i;
int a[][4] = { // 如果没有初始化,则一维长度不可省略
1, 2, 3, 4,
5, 6, 7, 8,
9, 10, 11, 12
};
size_t len1 = sizeof(a) / sizeof(a[0]);
size_t len2 = sizeof(a[0]) / sizeof(a[0][0]);
size_t totalLen = len1 * len2; // 整个二维数组的长度
int *ptr = &a[0][0]; // ptr指向二维数组首地址
for (i = 0; i < totalLen; i++) {
// 一维指针操作就是基于一维的,所以整个二维数组此时会被当作一条连续的内存
printf(" [%d]%p ", ptr[i], &ptr[i]);
// printf(" [%d]%p ", *(ptr + i), ptr + i);
if (i % len2 == 3) // 换行
printf("\n");
}
printf("Arr address: %p", ptr);
输出结果和之前遍历二维数组的是一模一样的。
指针数组 实现“二维数组”既然二级指针变量不能直接指向二维数组,那能不能依赖二级指针来实现一个类似的结构呢?当然是可以的啦!
整型变量存放着整型int数据,整型数组int a[]中存放了整型数据;
如果是用申请堆内存来实现的整型数组:
int* arr = (int*)malloc(sizeof(int) * 3);
指针int*变量arr此时指向的是连续存放整型(int)数据的内存的起始地址,相当于一个一维数组的起始地址。
代码实现
二级指针int**变量存放着一级指针变量的地址,那么就可以构建二级指针数组来存放二级指针数据(也就是每个元素都是一级指针变量的地址)。

具体代码实现:
int rows = 3; // 行数/一维长度
int cols = 4; // 列数/二维长度
int **ptr = (int **) malloc(rows * sizeof(int *));
// 分配一段连续的内存,储存int*类型的数据
int i, j, num = 1;
for (i = 0; i < rows; i++) {
ptr[i] = (int *) malloc(cols * sizeof(int));
// 再分配一段连续的内存,储存int类型的数据
for (j = 0; j < cols; j++)
ptr[i][j] = num++; // 储存一个整型数据1-12
}
其中
ptr[i] = (int *) malloc(cols * sizeof(int));
这一行,等同于
*(ptr+i) = ...
也就是利用间接访问符*让一级指针变量指向在堆内存中分配的一段连续整形数据,这里相当于初始化了第二维。
而在给整型元素赋值时和二维数组一样用了中括号进行访问:
ptr[i][j] = i * j;
其实就等同于:
*(*(ptr+i)+j) = i * j;
-
第一次访问第一维元素,用第一维起始地址
ptr加上第一维下标i,取出对应的一级指针变量中存放的地址:*(ptr+i)
这个地址是第二维中一段连续内存的起始地址。 -
第二次访问第二维元素,用1中取到的地址
*(ptr+i)加上第二维下标j,再用间接访问符*访问对应的元素,并赋值。
在内存中的存放
指针数组在内存中的存放不同于普通定义的二维数组,它的每一个维度是连续储存的,但是维度和维度之间在内存中的存放是离散的。
用一个循环打印一下每个元素的地址:
for (i = 0; i < rows; i++) {
for (j = 0; j < cols; j++)
printf(" [%d]%p ", ptr[i][j], *(ptr + i) + j);
printf("\n");
}
输出:

可以看到第二维度的地址是连续的,但是第二维度“数组”之间并不是连续的。比如元素4和元素5的地址相差了20个字节,并不是四个字节。
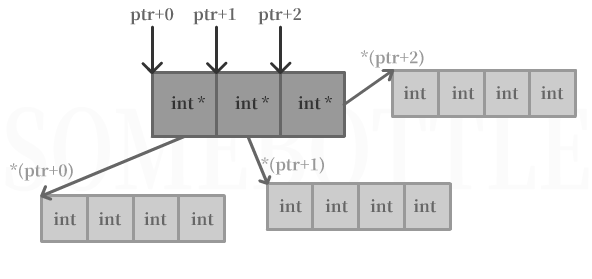
其在内存中的存放结构大致如上,并无法保证*(ptr+0)+3和*(ptr+1)的地址相邻,也无法保证*(ptr+1)+3和*(ptr+2)的地址相邻。
这种非连续的存放方式可以说是和二维数组相比很大的一个不同点了。
释放对应的堆内存
通常指针数组实现的“二维数组”是在堆内存中进行存放的,既然申请了堆内存,咱也应该养成好习惯,使用完毕后将其释放掉:
for (i = 0; i < rows; i++)
free(ptr[i]);
free(ptr);
先利用一个循环释放掉每一个一级指针变量指向的连续内存块(储存整型数据),最后再把二级指针变量指向的连续内存块(储存的是一级指针变量的地址)释放掉。
sizeof的事儿
sizeof()是C语言中非常常用的一个运算符,而二级指针和二维数组的区别在这里也可以很好地展现出来。
对于非变量长度定义的数组,sizeof在编译阶段就会完成求值运算,被替换为对应数据的大小的常量值。
int arr[n];这种定义时数组长度为变量的即为变量长度数组(C99标准开始支持),不过还是不太推荐这种写法。
直接固定长度定义二维数组时,编译器是知道这个变量是数组的,比如:
int arr[3][4];
size_t arrSize = sizeof(arr);
在编译阶段,编译器知道数组arr是一个整型int二维数组:
-
每个第二维数组包含四个
int数据,长度为sizeof(int)*4=16个字节。 -
第一维数组包含三个第二维数组,每个第二维数组长度为
16字节,整个二维数组总长度为16*3=48个字节。
即sizeof(arr) = 48。
对于指针数组
指针变量储存的是指针,也就是一个地址。内存地址在运算的时候会存放在CPU的整数寄存器中。
64位计算机中整数寄存器宽度有64bit(位),而指针数据要能存放在这里。
目前来说 1 字节(Byte) = 8 位(bit),那么64位就是8个字节,
所以64位系统中指针变量的长度是8字节。
int rows = 3; // 行数/一维长度
int **ptr = (int **) malloc(rows * sizeof(int *));
size_t ptrSize = sizeof(ptr); // 8 Bytes
size_t ptrSize2 = sizeof(int **); // 8 Bytes
size_t ptrSize3 = sizeof(int *); // 8 Bytes
size_t ptrSize4 = sizeof(char *); // 8 Bytes
虽然上面咱通过申请分配堆内存实现了二维数组(用二级指针变量ptr指向了指针数组起址),
但其实在编译器眼中,ptr就单纯是一个二级指针变量,占用字节数为8 Bytes(64位),储存着一个地址,因此在这里是无法通过sizeof获得这块连续内存的长度的。
通过上面的例子很容易能观察出来:
sizeof(指针变量) = 8 Bytes (64位计算机)
无论指针变量指向的是什么数据的地址,它储存的单纯只是一个内存地址,所以所有指针变量的占用字节数是一样的。
函数传参与返回
得先明确一点:C语言中不存在所谓的数组参数,通常让函数接受一个数组的数据需要通过指针变量参数传递。
传参时数组发生退化int test(int newArr[2]) {
printf(" %d ", sizeof(newArr)); // 8
return 0;
}
int main() {
int arr[5] = {1, 2, 3, 4, 5};
test(arr);
return 0;
}
在上面这个例子中test函数的定义中声明了“看上去像数组的”形参newArr,然而sizeof的运算结果是8。
实际上这里的形参声明是等同于int* newArr的,因为把数组作为参数进行传递的时候,实际上传递的是数组的首地址(因为数组名就代表数组的首地址)。
这种情况下就发生了数组到指针的退化。
在编译器的眼中,newArr此时就被当作了一个指针变量,指向arr数组的首地址,因此声明中数组的长度怎么写都行:int newArr[5],int newArr[]都可以。
为了让代码更加清晰,我觉得最好还是声明为int* newArr,这样一目了然能知道这是一个指针变量!
函数内运算涉及到数组长度时
当函数内运算涉及到数组长度时,就需要在函数定义的时候另声明一个形参来接受数组长度:
int test(int *arr, size_t rowLen, size_t colLen) {
int i;
size_t totalLen = rowLen * colLen;
for (i = 0; i < totalLen; i++) {
printf(" %d ", arr[i]);
if (i % colLen == colLen - 1) // 每个第二维数组元素打印完后换行
printf("\n");
}
return 0;
}
int main() {
int arr[3][3] = {
1, 2, 3,
4, 5, 6,
7, 8, 9
};
test(arr, sizeof(arr) / sizeof(arr[0]), sizeof(arr[0]) / sizeof(arr[0][0]));
return 0;
}
输出:

这个例子中test函数就多接受了二维数组的一维长度rowLen和二维长度colLen,以对二维数组元素进行遍历打印。
返回“数组”
经常有应用场景需要函数返回一个“数组”,说是数组,实际上函数并无法返回一个局部定义的数组,哪怕是其指针(在下面一节有写为什么)。
取而代之地,常常会返回一个指针指向分配好的一块连续的堆内存。
(在算法题中就经常能遇到要求返回指针的情况)
int *test(size_t len) {
int i;
int *arr = (int *) malloc(len * sizeof(int));
for (i = 0; i < len; i++)
arr[i] = i + 1;
return arr;
}
int main() {
int i = 0;
int *allocated = test(5);
for (; i < 5; i++)
printf(" %d ", allocated[i]);
free(allocated); // 一定要记得释放!
return 0;
}
这个示例中,test函数的返回类型是整型指针。当调用了test函数,传入要分配的连续内存长度后,其在函数内部定义了一个局部指针变量,指向分配好的内存,在内存中存放数据后将该指针返回。
在主函数中,test返回的整型指针被赋给了指针变量allocated,所以接下来可以通过一个循环打印出这块连续内存中的数据。
再次提醒,申请堆内存并使用完后,一定要记得使用free进行释放!
记得初学C语言的时候,我曾经犯过一个错误:将函数内定义的数组的数组名作为返回值:
int *test() {
int arr[4] = {1, 2, 3, 4};
return arr;
}
int main() {
int i = 0;
int *allocated = test();
for (; i < 4; i++)
printf(" %d ", *(allocated + i));
return 0;
}
这个例子中直到for循环前进程仍然正常运行,但是一旦尝试使用*运算符取出内存中的数据*(allocated + i),进程立马接收到了系统发来的异常信号SIGSEGV,进而终止执行。
SIGSEGV是比较常见的一种异常信号,代表Signal Segmentation Violation,也就是内存分段冲突
造成异常的原因通常是进程 试图访问一段没有分配给它的内存,“野指针”总是伴随着这个异常出现。
上面简述栈区的时候提到了栈帧,每次调用函数时会在栈上给函数分配一个栈帧用来储存函数调用相关信息。
函数调用完成后,先把运算出来的返回值存入寄存器中,接着会在栈帧上进行弹栈操作,在这个过程中分配的局部变量就会被回收。
最后,程序在栈顶中取到函数的返回地址,返回上层函数继续执行余下的指令。栈帧销毁,此时局部变量相关的栈内存已经被回收了。
然而此时寄存器中仍存着函数的返回值,是一个内存地址,但是内存地址代表的内存部分已经被回收了。
当将返回值赋给一个指针变量时,野指针就产生了——此时这个指针变量指向一片未知的内存。
所以当进程试图访问这一片不确定的内存时,就容易引用到无效的内存,此时系统就会发送SIGSEGV信号让进程终止执行。
教训
教训总结成一句话就是:
- 程序中请不要让函数返回代表栈内存的局部变量的地址。
延伸:返回静态局部变量是可以的,因为静态局部变量是储存在静态储存区的。
int *test() {
static int arr[4] = {1, 2, 3, 4};
return arr;
}