本章是系列文章的第二章,介绍了基于控制流图的一些优化方法。包括DAG、值标记、相同子表达式等方法。这章的后面介绍了llvm的一些基本概念,并引导大家写了个简单的pass。
本文中的所有内容来自学习DCC888的学习笔记或者自己理解的整理,如需转载请注明出处。周荣华@燧原科技
优化编译器和人类检视代码的角度是不一样的。
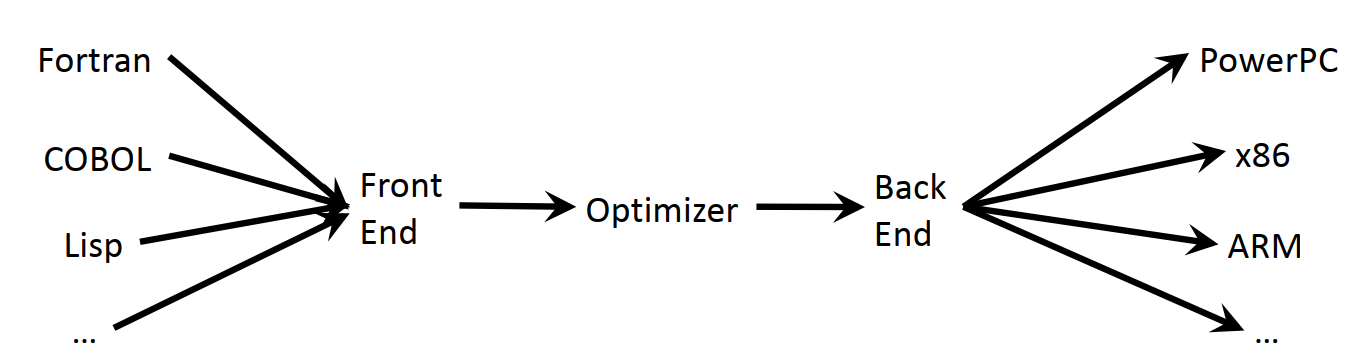
人类更关注源代码,但源代码和机器码相差太大,另外,从工程师的角度,最好能有一种通用的方法来表示不同编程语言,并且面向不同的target硬件架构,这种通用的表达我们通常称为程序的中间表达(Intermediate Representations),简称IR。针对不同层,我们经常会看到不同的IR,高级的有HLIR,低级的有LLIR,还有多级的IR,叫MLIR(Multi-Level Intermediate representation,有时MLIR也会当做中级IR,也就是Middle Level IR的简称)。
2.1.2 控制流图CFG
控制流图是编译器表示程序的一种方式。
控制流图是BB(Basic Block,基本块)为结点,根据程序在BB之间的流动方向作为有向边的有向图。
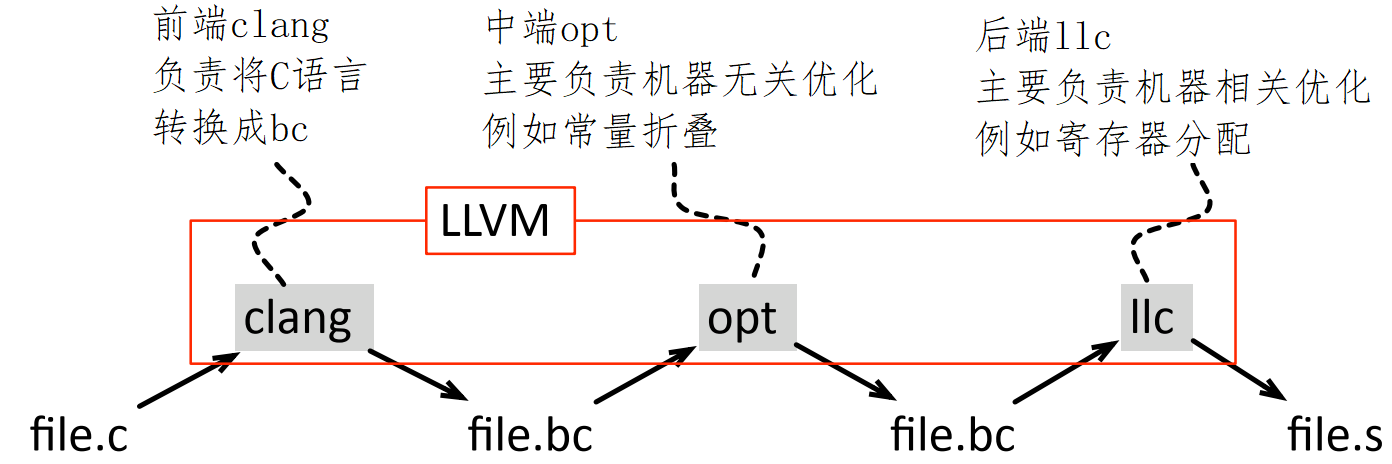
2.1.3 LLVMLLVM是The Low Level Virtual Machine(低级虚拟机)的简称,是当前各种研究领域最常用的编译器,也是很多大公司普遍使用的编译器。和其他编译器一样,LLVM分为前端(clang),中端(opt)和后端(llc)。
llvm可以帮我们生成dot格式的CFG,例如对identity.c,可以先用clang将c源文件转换成bc文件,然后用opt转换成dot文件,如果环境上有dot工具,并且环境也有窗口的话(纯命令行的远程不行,由于没有窗口可以打开,只能用dot工具将dot文件转换成windows认识的svg或者png文件,推荐svg,因为文本可以拷贝。)
clang -c -emit-llvm identity.c -o identity.bc opt –view-cfg identity.bc '' is not a recognized processor for this target (ignoring processor) WARNING: You're attempting to print out a bitcode file. This is inadvisable as it may cause display problems. If you REALLY want to taste LLVM bitcode first-hand, you can force output with the `-f' option. Writing '/tmp/cfgfoo-f4b44d.dot'... done. Trying 'xdg-open' program... Remember to erase graph file: /tmp/cfgfoo-f4b44d.dot root@cse-lab-003:/home/james/workspace/bc# Error: no "view" rule for type "application/msword" passed its test case (for more information, add "--debug=1" on the command line) /usr/bin/xdg-open: 851: /usr/bin/xdg-open: www-browser: not found /usr/bin/xdg-open: 851: /usr/bin/xdg-open: links2: not found /usr/bin/xdg-open: 851: /usr/bin/xdg-open: elinks: not found /usr/bin/xdg-open: 851: /usr/bin/xdg-open: links: not found /usr/bin/xdg-open: 851: /usr/bin/xdg-open: lynx: not found /usr/bin/xdg-open: 851: /usr/bin/xdg-open: w3m: not found xdg-open: no method available for opening '/tmp/cfgfoo-f4b44d.dot' dot -Tsvg '/tmp/cfgfoo-f4b44d.dot' > cfgfoo-f4b44d.svg
将刚刚生成的cfgfoo-f4b44d.svg拷贝到windows,用浏览器可以打开对应c/c++或者bc文件的CFG:
LLVM用一种指令的序列来表达程序,这些指令的序列称为bytecodes,或者简称bc。LLVM的指令又称为LLIR,LLIR和target机器没有绑定关系,是一种类汇编的代码,LLVM的汇编代码的详细说明参见New tab (llvm.org)。
2.1.4 基本块Basic Blocks基本块是满足下面属性的最大的连续指令序列:
- 控制流只能从基本块的第一行开始执行(不能有jump执行块中间的某行代码)
- 除非是基本块的最后一条指令,否则不允许包含离开基本块的分支或者挂机指令
- 代码的第一行是基本块首领
- 任何条件或者非条件跳转指令的目标行是基本块首领
- 任意条件或者非条件跳转指令的下一行是基本块首领
- 基本块的首领是基本块的一部分
- 基本块首领到下一个基本块的首领直接的代码,属于该基本块
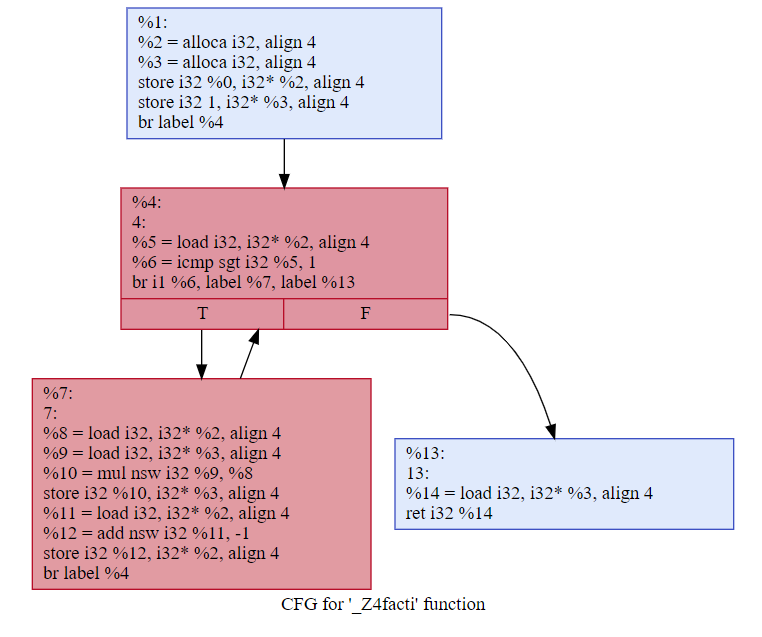
下面是一个简单的例子:
1 int fact(int n) { 2 int ans = 1; 3 while (n > 1) { 4 ans *= n; 5 n--; 6 } 7 return ans; 8 }
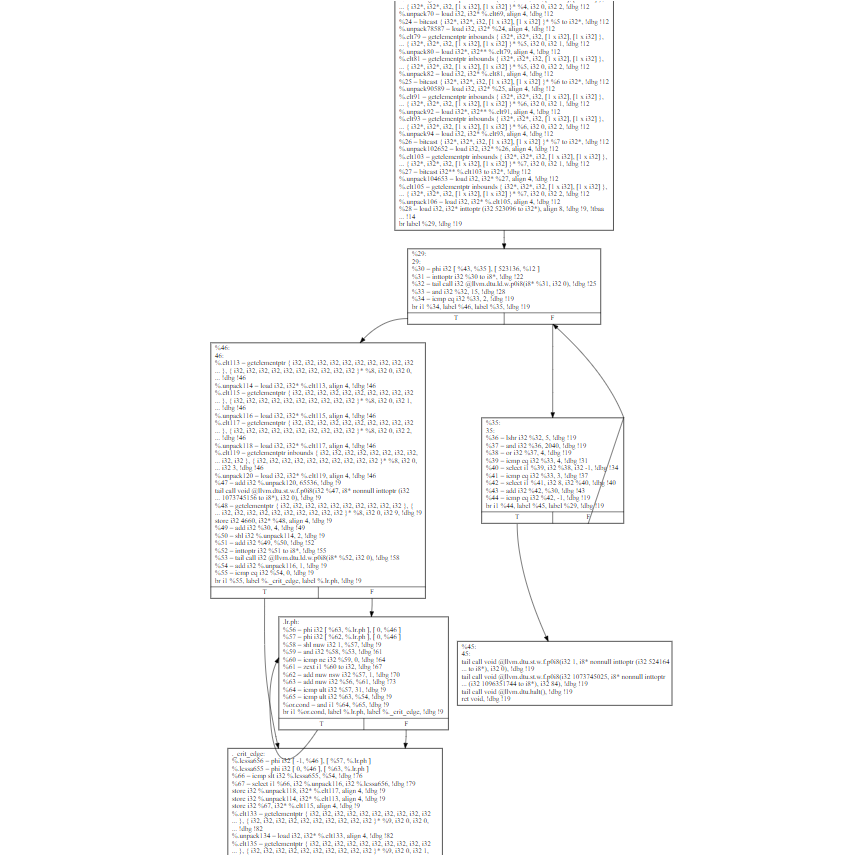
这个函数用opt生成的CFG是这样的,opt自动把while循环涉及的2个BB标了红色(自由互联不支持直接以html格式增加svg图,只能贴个截图):
2.1.7 本地优化和全局优化
作用于在一个BB内部的优化称为本地优化。常见的有:
- 基于DAG的优化
- 窥孔优化
- 本地寄存器分配
基于整个程序的优化称为全局优化。
本课程介绍的大多数优化都是全局优化。
2.2 基于程序DAG的优化 2.2.1 程序的有向无环图(Directed Acyclic Graph)- 每个输入值对应DAG中的一个结点
- BB中的每行指令生成一个结点
- 如果指令S用到了指令S1, ..., Sn中的变量,画一条从Si, i∈{1, ..., n}到S的边
- BB中定义但未在BB中使用的变量称为输出值
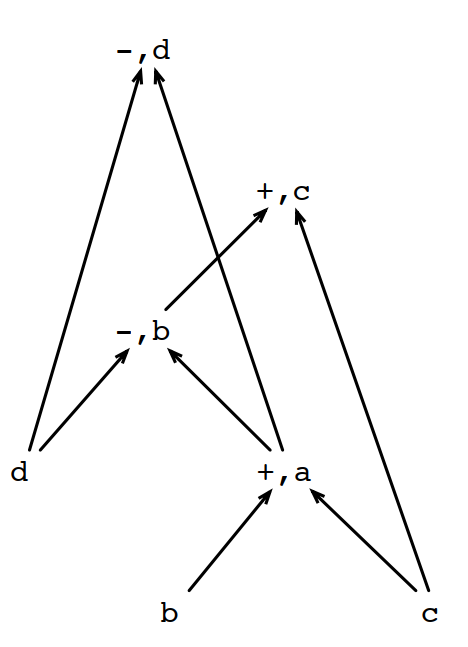
例如下面的BB:
1 a = b + c 2 b = a – d 3 c = b + c 4 d = a – d
生成的DAG是这样的:
llvm也支持自动生成DAG,不过LLVM生成的DAG是基于llvm ir,所以如果是用高级语言写的代码,转换成llvm ir的时候会有很多寄存器相关的操作,这样DAG显得非常大,例如上面的代码,如果要编译成llvmir的话,还需要封装一个函数,变成:
1 int dag_test(int b, int c, int d) { 2 int a = b + c; 3 b = a - d; 4 c = b + c; 5 d = a - d; 6 return c; 7 }
保存成bb2.cc,然后用clang生成对应的llvm ir:
clang -c -emit-llvm bb2.cc
生成的llvm ir自动取名bb2.ll,内容是这样的:
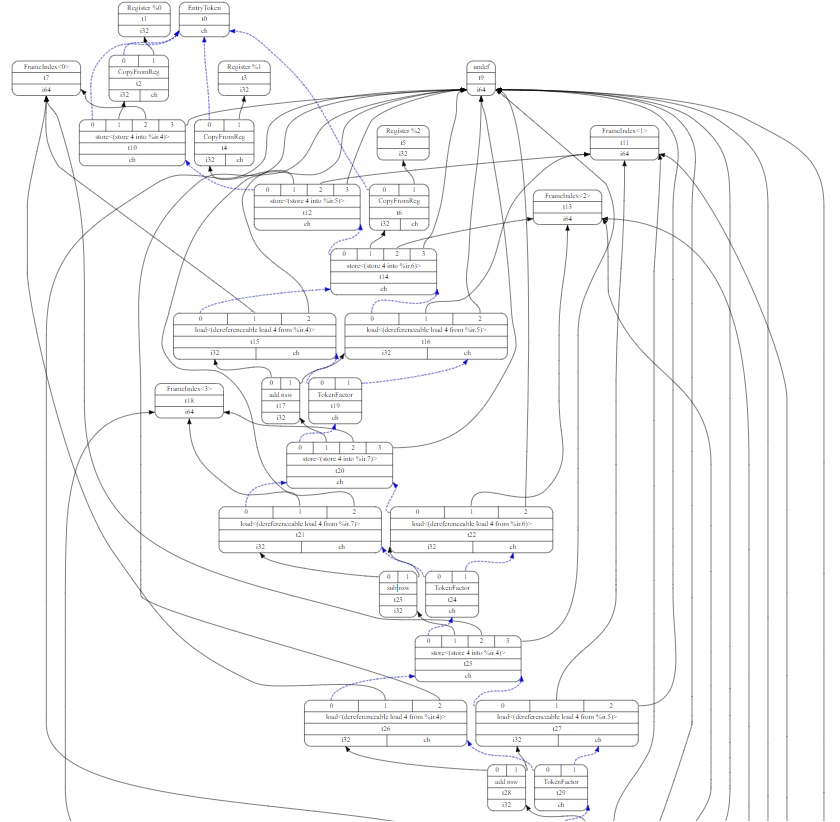
1 ; ModuleID = 'bb2.cc' 2 source_filename = "bb2.cc" 3 target datalayout = "e-m:e-p270:32:32-p271:32:32-p272:64:64-i64:64-f80:128-n8:16:32:64-S128" 4 target triple = "x86_64-unknown-linux-gnu" 5 6 ; Function Attrs: noinline nounwind optnone uwtable 7 define dso_local i32 @_Z8dag_testiii(i32 %0, i32 %1, i32 %2) #0 { 8 %4 = alloca i32, align 4 9 %5 = alloca i32, align 4 10 %6 = alloca i32, align 4 11 %7 = alloca i32, align 4 12 store i32 %0, i32* %4, align 4 13 store i32 %1, i32* %5, align 4 14 store i32 %2, i32* %6, align 4 15 %8 = load i32, i32* %4, align 4 16 %9 = load i32, i32* %5, align 4 17 %10 = add nsw i32 %8, %9 18 store i32 %10, i32* %7, align 4 19 %11 = load i32, i32* %7, align 4 20 %12 = load i32, i32* %6, align 4 21 %13 = sub nsw i32 %11, %12 22 store i32 %13, i32* %4, align 4 23 %14 = load i32, i32* %4, align 4 24 %15 = load i32, i32* %5, align 4 25 %16 = add nsw i32 %14, %15 26 store i32 %16, i32* %5, align 4 27 %17 = load i32, i32* %7, align 4 28 %18 = load i32, i32* %6, align 4 29 %19 = sub nsw i32 %17, %18 30 store i32 %19, i32* %6, align 4 31 %20 = load i32, i32* %5, align 4 32 ret i32 %20 33 } 34 35 ; attributes #0 = { noinline nounwind optnone uwtable "correctly-rounded-divide-sqrt-fp-math"="false" "disable-tail-calls"="false" "frame-pointer"="all" "less-precise-fpmad"="false" "min-legal-vector-width"="0" "no-infs-fp-math"="false" "no-jump-tables"="false" "no-nans-fp-math"="false" "no-signed-zeros-fp-math"="false" "no-trapping-math"="true" "stack-protector-buffer-size"="8" "target-cpu"="x86-64" "target-features"="+cx8,+fxsr,+mmx,+sse,+sse2,+x87" "unsafe-fp-math"="false" "use-soft-float"="false" } 36 attributes #0 = { nounwind uwtable "disable-tail-calls"="false" "less-precise-fpmad"="false" "no-frame-pointer-elim"="true" "no-frame-pointer-elim-non-leaf" "no-infs-fp-math"="false" "no-jump-tables"="false" "no-nans-fp-math"="false" "no-signed-zeros-fp-math"="false" "stack-protector-buffer-size"="8" "target-cpu"="x86-64" "target-features"="+fxsr,+mmx,+sse,+sse2,+x87" "unsafe-fp-math"="false" "use-soft-float"="false" } 37 38 39 40 !llvm.module.flags = !{!0} 41 !llvm.ident = !{!1} 42 43 !0 = !{i32 1, !"wchar_size", i32 4} 44 !1 = !{!"clang version 11.1.0"}
我这里用的是llvm11的clang,生成出来的llvm ir的module的原始attributes是35行,但这个attributes无法生成DAG,需要改成36行的attributes。
然后用llvm的llc(注意,llvm发布版本默认是release版本的,想要看到DAG,需要自己基于源代码编译debug版本的,内网有我编译好的debug版本的llvm11,在/home/.devtools/efb/clang11/bin目录,大家可以加到自己的默认PATH里面之后直接用)将llvm ir转换成dot文件:
llc -view-dag-combine1-dags bb2.ll
如果是命令行连接的linux系统,由于没有window可以展示,会提示生成了dot文件。然后大家可以选择将dot文件转换成svg或者png等图片格式,我更喜欢svg,因为里面的字符串还是字符串形式的存在,不像png完全是图片,不方便拷贝,生成svg的命令如下,假定提示生成的dot文件名为dag._Z8dag_testiii-3c598e.dot:
dot -Tsvg dag._Z8dag_testiii-3c598e.dot > dag._Z8dag_testiii-3c598e.dot.svg
生成出来的dag._Z8dag_testiii-3c598e.dot.svg是文本文件,可以拷贝到支持HTML的浏览器中打开,效果如下(转换成llvm ir之后的代码,增加了很多寄存器操作,所以虽然简单的7行代码,生成的DAG也非常夸张):
2.2.2 基于相同子表达式的优化
回到刚才画的简化版DAG,我们重复画图过程,增加利用相同子表达式优化的方法重新画一次:
- 对任意输入vi:
- 在DAG上画结点vi
- 并打上in标签
- 按BB中的顺序对每条指令v=f(v1, ..., vn):
- 如果DAG中存在一个标签为f的结点v',按顺序包含v的所有子结点,定义v'是v的一个别名
- 如果不存在,
- 画一个结点v,
- 对每个1≤i≤n,画一条边(vi, v),
- 并给v打标签f
按上面的画法,到第4行的d的时候,就能发现它和第2行的b,拥有相同的子结点{d, a}并且顺序一样,所以第4行的d和第2行的b是别名关系。
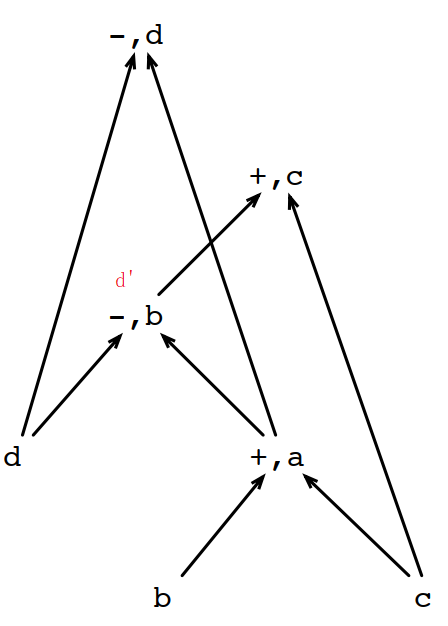
实际应用过程中,我们使用值标记的方法来计算相同子表达式:
- 对DAG的每个结点关联一个签名(lb, v1, ..., vn),其中lb是该结点的标签,vi (1≤i≤n)是该结点的所有子结点。
- 将签名中的子结点序列作为hash函数的key,
- hash函数的值就是该变量的值标记
- 当有新结点加入到DAG时,
- 先根据它的所有子结点计算出一个hash值,如果已经存在,我们直接返回该hash值对应对应的索引。
- 如果找不到,则创建该结点。
对上面的DAG,我们生成的值标记的hash表如下,最后一列很显然是不必要的:
为了找到更多的CSE(Common SubExpressions),需要制定更多的定理:
交换律:对+运算符,x+y和y+x等同。
特性转换:x<y一般转换成t=x-y; t<0
结合律: 对
a=b+c; t=c+d; e=t+b;
等同于:
a=b+c; e=a+d;
算术特性转换:
x+0=0+x=x;
x*1=1*x=x;
x-0=x;
x/1=x;
计算强度降维转换:
x2=x*x;
2*x=x+x;
x/2=x*0.5;
常量折叠:在编译阶段计算表达式的值,并将表达式替换成对应的值。
2.2.4 死代码删除死代码(Dead Code)是满足下面2个条件的DAG结点:
- 该结点没有子结点;
- 该结点不是输出结点。
- 上面的删除过程可以通过多轮迭代实现。
- 优化器分析一个指令的集合
- 每次只分析比较小的固定窗口内的指令
- 这个固定窗口不断往下滑动
- 当窗口内发现某种可以优化的模式,则执行该优化
窥孔优化的实例:
- 冗余的load和store指令删除
- 冗余分支指令的删除
- 冗余调整指令的删除
- 计算强度降维:除法 > 乘法 > 减法 > 移位/加法
- 机器特有属性:addl > incl
局部寄存器分配的伪代码类似这样:
1 allocate(Block b) { 2 for (Inst i : b.instructions()) { 3 for (Operand o : i.operands()) { 4 if (o is in memory m) { 5 r = find_reg(i) assign r to o add "r = load m" before i 6 } 7 } 8 for (Operand o : i.operands()) { 9 if (i is the last use of o) { 10 return the register bound to o to the list of free registers 11 } 12 } 13 v = i.definition r = find_reg(i) assign r to v 14 } 15 }
溢出(spilling):大多数情况下寄存器是有限的,需要在寄存器不够用的情况下将之前保存在寄存器里面的内容映射回内存,这个操作叫做溢出。
find_reg函数的伪代码是这样的:
1 find_reg(i) { 2 if there is free register r 3 return r 4 else 5 let v be the latest variable to be used after i, that is in a register 6 if v does not have a memory slot 7 let m be a fresh memory slot 8 else 9 let m be the memory slot assigned to v 10 add "store v m" right after the definition of v 11 return r 12 }
可以看出局部寄存器的分配,主要依赖在变量使用前插入"r = load m"指令,并在变量使用完之后插入"store v m"来实现。
但当寄存器不足的时候,要选择将哪个变量从寄存器溢出到内存里面?
伯克利算法策略:溢出时通常选择离溢出点最远的变量,也称为LRU(Least Recently Used,最近最少使用算法)。该算法在各种缓存溢出过程中广泛采用,包括页面置换,cache miss等过程。
对只有2个寄存器的机器,要实现下面的计算:
1 a = load m0 2 b = load m1 3 c = a + b 4 d = 4 * c 5 e = b + 1 6 f = e + a 7 g = d / e 8 h = f - g 9 ret h
实际完成局部寄存器分配之后的代码和各变量在寄存器,内存里面的生命周期是这样的:
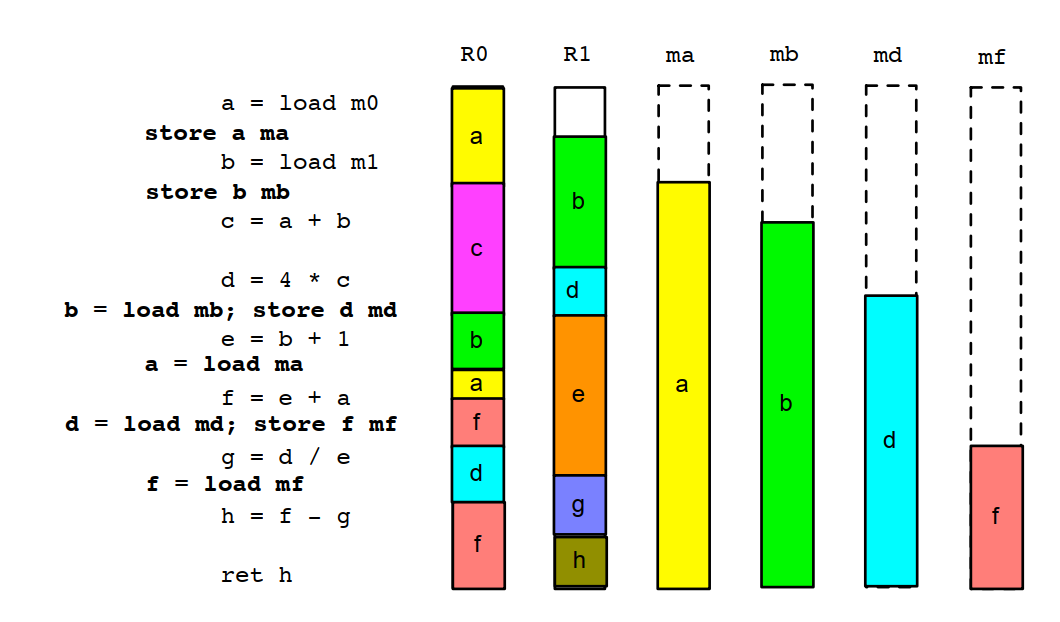
上面的算法在这次运算中其实不是最优解。如果在"c=a+b"计算之前不把b踢出寄存器,而是在"d=4*c"计算中让d复用c的寄存器,就可以少store一次b并且少load一次b。
但在1998年就有科学家证明了,找到每次分配寄存器的最优解是NP完全问题(NP-completeness,是"nondeterministic polynomial-time completeness"的简称,也就是不确定的多项式时间完全问题,其中不确定性指的是不确定图灵机,是数学上形式化描述的暴力搜索算法。对确定性的算法,只需要进行一次迭代就能得出结果,对不确定的算法,需要遍历整个空间。)。也就是说,如果遍历所有分配选项,当然是能找出一个最优解的,但时间消耗非常大,所以各个类似领域都是用LRU作为较优解。
2.5 LLVM简介 2.5.1 LLVM是一种编译框架结构llvm有很多编译工具:
1 root@e6db4f256fba:/home/.devtools/efb/clang11/bin# cd /home/.devtools/efb/clang11/bin/ 2 root@e6db4f256fba:/home/.devtools/efb/clang11/bin# ls 3 bugpoint ld64.lld llvm-gsymutil llvm-rtdyld 4 c-index-test llc llvm-ifs llvm-size 5 clang lld llvm-install-name-tool llvm-special-case-list-fuzzer 6 clang++ lld-link llvm-isel-fuzzer llvm-split 7 clang-11 lldb llvm-itanium-demangle-fuzzer llvm-stress 8 clang-apply-replacements lldb-argdumper llvm-jitlink llvm-strings 9 clang-change-namespace lldb-instr llvm-lib llvm-strip 10 clang-check lldb-server llvm-link llvm-symbolizer 11 clang-cl lldb-vscode llvm-lipo llvm-tblgen 12 clang-cpp lli llvm-lit llvm-undname 13 clang-doc llvm-addr2line llvm-locstats llvm-xray 14 clang-extdef-mapping llvm-ar llvm-lto llvm-yaml-numeric-parser-fuzzer 15 clang-format llvm-as llvm-lto2 mlir-cpu-runner 16 clang-include-fixer llvm-bcanalyzer llvm-mc mlir-edsc-builder-api-test 17 clang-move llvm-c-test llvm-mca mlir-linalg-ods-gen 18 clang-offload-bundler llvm-cat llvm-microsoft-demangle-fuzzer mlir-opt 19 clang-offload-wrapper llvm-cfi-verify llvm-ml mlir-reduce 20 clang-query llvm-config llvm-modextract mlir-sdbm-api-test 21 clang-refactor llvm-cov llvm-mt mlir-tblgen 22 clang-rename llvm-cvtres llvm-nm mlir-translate 23 clang-reorder-fields llvm-cxxdump llvm-objcopy modularize 24 clang-scan-deps llvm-cxxfilt llvm-objdump obj2yaml 25 clang-tblgen llvm-cxxmap llvm-opt-fuzzer opt 26 clang-tidy llvm-diff llvm-opt-report pp-trace 27 clangd llvm-dis llvm-pdbutil sancov 28 diagtool llvm-dlltool llvm-profdata sanstats 29 dsymutil llvm-dwarfdump llvm-ranlib scan-build 30 find-all-symbols llvm-dwp llvm-rc scan-view 31 git-clang-format llvm-elfabi llvm-readelf verify-uselistorder 32 hmaptool llvm-exegesis llvm-readobj wasm-ld 33 ld.lld llvm-extract llvm-reduce yaml2obj
2.5.2 使用opt进行机器无关优化,输入输出都是bc或者llvm ir
1 root@e6db4f256fba:/home/.devtools/efb/clang11/bin# opt --help 2 OVERVIEW: llvm .bc -> .bc modular optimizer and analysis printer 3 4 USAGE: opt [options] <input bitcode file> 5 6 OPTIONS: 7 8 Color Options: 9 10 --color - Use colors in output (default=autodetect) 11 12 General options: 13 14 --Emit-dtu-info - Enable DTU info section generation 15 --O0 - Optimization level 0. Similar to clang -O0 16 --O1 - Optimization level 1. Similar to clang -O1 17 --O2 - Optimization level 2. Similar to clang -O2 18 --O3 - Optimization level 3. Similar to clang -O3 19 --Os - Like -O2 with extra optimizations for size. Similar to clang -Os 20 --Oz - Like -Os but reduces code size further. Similar to clang -Oz 21 -S - Write output as LLVM assembly 22 --aarch64-neon-syntax=<value> - Choose style of NEON code to emit from AArch64 backend: 23 =generic - Emit generic NEON assembly 24 =apple - Emit Apple-style NEON assembly 25 --addrsig - Emit an address-significance table 26 --analyze - Only perform analysis, no optimization 27 --asm-show-inst - Emit internal instruction representation to assembly file 28 --atomic-counter-update-promoted - Do counter update using atomic fetch add for promoted counters only 29 Optimizations available: 30 --X86CondBrFolding - X86CondBrFolding 31 --aa - Function Alias Analysis Results 32 --aa-eval - Exhaustive Alias Analysis Precision Evaluator 33 --aarch64-a57-fp-load-balancing - AArch64 A57 FP Load-Balancing 34 --aarch64-branch-targets - AArch64 Branch Targets 35 --aarch64-ccmp - AArch64 CCMP Pass 36 --aarch64-collect-loh - AArch64 Collect Linker Optimization Hint (LOH) 37 --aarch64-condopt - AArch64 CondOpt Pass 38 --aarch64-copyelim - AArch64 redundant copy elimination pass 39 --aarch64-dead-defs - AArch64 Dead register definitions 40 --aarch64-expand-pseudo - AArch64 pseudo instruction expansion pass 41 --aarch64-fix-cortex-a53-835769-pass - AArch64 fix for A53 erratum 835769 42 --aarch64-jump-tables - AArch64 compress jump tables pass 43 --aarch64-ldst-opt - AArch64 load / store optimization pass 44 --aarch64-local-dynamic-tls-cleanup - AArch64 Local Dynamic TLS Access Clean-up 45 --aarch64-prelegalizer-combiner - Combine AArch64 machine instrs before legalization 46 --aarch64-promote-const - AArch64 Promote Constant Pass 47 --aarch64-simd-scalar - AdvSIMD Scalar Operation Optimization 48 --aarch64-simdinstr-opt - AArch64 SIMD instructions optimization pass 49 --aarch64-speculation-hardening - AArch64 speculation hardening pass 50 --aarch64-stack-tagging-pre-ra - AArch64 Stack Tagging PreRA Pass 51 --aarch64-stp-suppress - AArch64 Store Pair Suppression 52 --adce - Aggressive Dead Code Elimination 53 …………
不同优化级别的优化使能的优化选项:
1 root@e6db4f256fba:/home/.devtools/efb/clang11/bin# llvm-as < /dev/null | opt -O0 -disable-output -debug-pass=Arguments 2 Pass Arguments: -tti -verify -ee-instrument 3 Pass Arguments: -targetlibinfo -tti -assumption-cache-tracker -profile-summary-info -forceattrs -basiccg -always-inline -verify 4 root@e6db4f256fba:/home/.devtools/efb/clang11/bin# llvm-as < /dev/null | opt -O3 -disable-output -debug-pass=Arguments 5 Pass Arguments: -tti -tbaa -scoped-noalias -assumption-cache-tracker -targetlibinfo -verify -ee-instrument -simplifycfg -domtree -sroa -early-cse -lower-expect 6 Pass Arguments: -targetlibinfo -tti -tbaa -scoped-noalias -assumption-cache-tracker -profile-summary-info -forceattrs -inferattrs -domtree -callsite-splitting -ipsccp -called-value-propagation -attributor -globalopt -domtree -mem2reg -deadargelim -domtree -basicaa -aa -loops -lazy-branch-prob -lazy-block-freq -opt-remark-emitter -instcombine -simplifycfg -basiccg -globals-aa -prune-eh -inline -functionattrs -argpromotion -domtree -sroa -basicaa -aa -memoryssa -early-cse-memssa -speculative-execution -basicaa -aa -lazy-value-info -jump-threading -correlated-propagation -simplifycfg -domtree -aggressive-instcombine -basicaa -aa -loops -lazy-branch-prob -lazy-block-freq -opt-remark-emitter -instcombine -libcalls-shrinkwrap -loops -branch-prob -block-freq -lazy-branch-prob -lazy-block-freq -opt-remark-emitter -pgo-memop-opt -basicaa -aa -loops -lazy-branch-prob -lazy-block-freq -opt-remark-emitter -tailcallelim -simplifycfg -reassociate -domtree -basicaa -aa -memoryssa -loops -loop-simplify -lcssa-verification -lcssa -scalar-evolution -loop-rotate -licm -loop-unswitch -simplifycfg -domtree -basicaa -aa -loops -lazy-branch-prob -lazy-block-freq -opt-remark-emitter -instcombine -loop-simplify -lcssa-verification -lcssa -scalar-evolution -indvars -loop-idiom -loop-deletion -loop-unroll -mldst-motion -phi-values -basicaa -aa -memdep -lazy-branch-prob -lazy-block-freq -opt-remark-emitter -gvn -phi-values -basicaa -aa -memdep -memcpyopt -sccp -demanded-bits -bdce -basicaa -aa -lazy-branch-prob -lazy-block-freq -opt-remark-emitter -instcombine -lazy-value-info -jump-threading -correlated-propagation -basicaa -aa -phi-values -memdep -dse -basicaa -aa -memoryssa -loops -loop-simplify -lcssa-verification -lcssa -scalar-evolution -licm -postdomtree -adce -simplifycfg -domtree -basicaa -aa -loops -lazy-branch-prob -lazy-block-freq -opt-remark-emitter -instcombine -barrier -elim-avail-extern -basiccg -rpo-functionattrs -globalopt -globaldce -basiccg -globals-aa -domtree -float2int -lower-constant-intrinsics -domtree -basicaa -aa -memoryssa -loops -loop-simplify -lcssa-verification -lcssa -scalar-evolution -loop-rotate -loop-accesses -lazy-branch-prob -lazy-block-freq -opt-remark-emitter -loop-distribute -branch-prob -block-freq -scalar-evolution -basicaa -aa -loop-accesses -demanded-bits -lazy-branch-prob -lazy-block-freq -opt-remark-emitter -inject-tli-mappings -loop-vectorize -loop-simplify -scalar-evolution -basicaa -aa -loop-accesses -lazy-branch-prob -lazy-block-freq -loop-load-elim -basicaa -aa -lazy-branch-prob -lazy-block-freq -opt-remark-emitter -instcombine -simplifycfg -domtree -loops -scalar-evolution -basicaa -aa -demanded-bits -lazy-branch-prob -lazy-block-freq -opt-remark-emitter -slp-vectorizer -opt-remark-emitter -instcombine -loop-simplify -lcssa-verification -lcssa -scalar-evolution -loop-unroll -lazy-branch-prob -lazy-block-freq -opt-remark-emitter -instcombine -memoryssa -loop-simplify -lcssa-verification -lcssa -scalar-evolution -licm -lazy-branch-prob -lazy-block-freq -opt-remark-emitter -transform-warning -alignment-from-assumptions -strip-dead-prototypes -globaldce -constmerge -domtree -loops -branch-prob -block-freq -loop-simplify -lcssa-verification -lcssa -basicaa -aa -scalar-evolution -block-freq -loop-sink -lazy-branch-prob -lazy-block-freq -opt-remark-emitter -instsimplify -div-rem-pairs -simplifycfg -verify 7 Pass Arguments: -domtree 8 Pass Arguments: -targetlibinfo -domtree -loops -branch-prob -block-freq 9 Pass Arguments: -targetlibinfo -domtree -loops -branch-prob -block-freq
2.5.3 pass
pass是llvm特有的概念。Llvm的paas框架是llvm系统中的重要部分,也是编译器中最有趣的部分,llvm通过应用一连串的pass来达到优化效果。部分pass为编译器提供转换或者优化功能,而这些pass又依赖其他pass提供这些转换和优化需要的分析结果。Pass是llvm提供的编译代码的一种结构化的技术。
所有llvm的pass都是Pass类的子类,它们重载继承自Pass类的虚拟函数,根据pass的功能需要,可以选择继承自ModulePass, CallGraphSCCPass, FunctionPass, LoopPass, RegionPass, 或者 BasicBlockPass 类,这些类相对于最上层的Pass类,提供了更多上下文信息。
2.5.4 虚拟寄存器分配mem2reg例如下面这个函数:
1 int main() { 2 int c1 = 17; 3 int c2 = 25; 4 int c3 = c1 + c2; 5 printf("Value = %d\n", c3); 6 }
编译生成的llvm ir是这样的(省略了一些属性,只显示了函数体):
1 clang -S -emit-llvm mem2reg.cc 2 llvm-dis mem2reg.bc 3 cat mem2reg.ll 4 ; ModuleID = 'mem2reg.bc' 5 source_filename = "mem2reg.cc" 6 target datalayout = "e-m:e-p270:32:32-p271:32:32-p272:64:64-i64:64-f80:128-n8:16:32:64-S128" 7 target triple = "x86_64-unknown-linux-gnu" 8 9 @.str = private unnamed_addr constant [12 x i8] c"Value = %d\0A\00", align 1 10 11 ; Function Attrs: noinline norecurse optnone uwtable 12 define dso_local i32 @main() #0 { 13 %1 = alloca i32, align 4 14 %2 = alloca i32, align 4 15 %3 = alloca i32, align 4 16 store i32 17, i32* %1, align 4 17 store i32 25, i32* %2, align 4 18 %4 = load i32, i32* %1, align 4 19 %5 = load i32, i32* %2, align 4 20 %6 = add nsw i32 %4, %5 21 store i32 %6, i32* %3, align 4 22 %7 = load i32, i32* %3, align 4 23 %8 = call i32 (i8*, ...) @printf(i8* getelementptr inbounds ([12 x i8], [12 x i8]* @.str, i64 0, i64 0), i32 %7) 24 ret i32 0 25 } 26 27 declare dso_local i32 @printf(i8*, ...) #1 28 29 attributes #0 = { noinline norecurse optnone uwtable "correctly-rounded-divide-sqrt-fp-math"="false" "disable-tail-calls"="false" "frame-pointer"="all" "less-precise-fpmad"="false" "min-legal-vector-width"="0" "no-infs-fp-math"="false" "no-jump-tables"="false" "no-nans-fp-math"="false" "no-signed-zeros-fp-math"="false" "no-trapping-math"="true" "stack-protector-buffer-size"="8" "target-cpu"="x86-64" "target-features"="+cx8,+fxsr,+mmx,+sse,+sse2,+x87" "unsafe-fp-math"="false" "use-soft-float"="false" } 30 attributes #1 = { "correctly-rounded-divide-sqrt-fp-math"="false" "disable-tail-calls"="false" "frame-pointer"="all" "less-precise-fpmad"="false" "no-infs-fp-math"="false" "no-nans-fp-math"="false" "no-signed-zeros-fp-math"="false" "no-trapping-math"="true" "stack-protector-buffer-size"="8" "target-cpu"="x86-64" "target-features"="+cx8,+fxsr,+mmx,+sse,+sse2,+x87" "unsafe-fp-math"="false" "use-soft-float"="false" } 31 32 !llvm.module.flags = !{!0} 33 !llvm.ident = !{!1} 34 35 !0 = !{i32 1, !"wchar_size", i32 4} 36 !1 = !{!"clang version 11.1.0"}
直接对上面生成的bc文件跑opt,发现优化之后的llvm ir和优化前的llvm ir几乎完全一样,没有达到预期的优化效果。问了一圈,有同事怀疑是属性里面的optnone 再使坏,删掉之后确实能正常优化了。
下面是优化之后的llvm ir和优化过程中运行的命令,可以看出main函数从之前的8行指令优化成了2行。在寄存器足够的情况下,仅仅mem2reg这个优化pass的效果也是非常可观的。
1 root@e6db4f256fba:~/DCC888# opt --mem2reg mem2reg.ll > mem2reg_after.bc 2 root@e6db4f256fba:~/DCC888# llvm-dis mem2reg_after.bc 3 root@e6db4f256fba:~/DCC888# cat mem2reg_after.ll 4 ; Function Attrs: noinline norecurse uwtable 5 define dso_local i32 @main() #0 { 6 %1 = add nsw i32 17, 25 7 %2 = call i32 (i8*, ...) @printf(i8* getelementptr inbounds ([12 x i8], [12 x i8]* @.str, i64 0, i64 0), i32 %1) 8 ret i32 0 9 }
2.5.5 常量折叠constprop
经过一轮常量折叠后main函数代码可以精简到1行,下面是命令和优化后的llvm ir。
1 root@e6db4f256fba:~/DCC888# opt --constprop mem2reg_after.ll > mem2reg_constprop.bc 2 root@e6db4f256fba:~/DCC888# llvm-dis mem2reg_constprop.bc 3 root@e6db4f256fba:~/DCC888# cat mem2reg_constprop.ll 4 define dso_local i32 @main() #0 { 5 %1 = call i32 (i8*, ...) @printf(i8* getelementptr inbounds ([12 x i8], [12 x i8]* @.str, i64 0, i64 0), i32 42) 6 ret i32 0 7 }
2.5.6 通用子表达式early-cse
再来一个CSE的例子,源代码如下:
1 root@e6db4f256fba:~/DCC888# cat cse.cc 2 #include<stdio.h> 3 int main(int argc, char** argv) { 4 char c1 = argc + 1; 5 char c2 = argc - 1; 6 char c3 = c1 + c2; 7 char c4 = c1 + c2; 8 char c5 = c4 * 4; 9 if (argc % 2) 10 printf("Value = %d\n", c3); 11 else 12 printf("Value = %d\n", c5); 13 }
先秀一下没做CSE之前的llir(llvm ir可以简写成llir,省去不关心的各种attributes,但自己跑的时候注意把optnone的attribute删除掉再跑):
root@e6db4f256fba:~/DCC888# clang -S -emit-llvm cse.cc root@e6db4f256fba:~/DCC888# opt --mem2reg cse.ll > cse_mem2reg.bc root@e6db4f256fba:~/DCC888# llvm-dis cse_mem2reg.bc root@e6db4f256fba:~/DCC888# cat cse_mem2reg.ll define dso_local i32 @main(i32 %0, i8** %1) #0 { %3 = add nsw i32 %0, 1 %4 = trunc i32 %3 to i8 %5 = sub nsw i32 %0, 1 %6 = trunc i32 %5 to i8 %7 = sext i8 %4 to i32 %8 = sext i8 %6 to i32 %9 = add nsw i32 %7, %8 %10 = trunc i32 %9 to i8 %11 = sext i8 %4 to i32 %12 = sext i8 %6 to i32 %13 = add nsw i32 %11, %12 %14 = trunc i32 %13 to i8 %15 = sext i8 %14 to i32 %16 = mul nsw i32 %15, 4 %17 = trunc i32 %16 to i8 %18 = srem i32 %0, 2 %19 = icmp ne i32 %18, 0 br i1 %19, label %20, label %23 20: ; preds = %2 %21 = sext i8 %10 to i32 %22 = call i32 (i8*, ...) @printf(i8* getelementptr inbounds ([12 x i8], [12 x i8]* @.str, i64 0, i64 0), i32 %21) br label %26 23: ; preds = %2 %24 = sext i8 %17 to i32 %25 = call i32 (i8*, ...) @printf(i8* getelementptr inbounds ([12 x i8], [12 x i8]* @.str, i64 0, i64 0), i32 %24) br label %26 26: ; preds = %23, %20 ret i32 0 }
经过cse优化之后的结果,注意,优化前的7~10和11~14行的代码一样,被优化成一份了:
1 root@e6db4f256fba:~/DCC888# opt --early-cse cse_mem2reg.ll | llvm-dis 2 ; Function Attrs: noinline norecurse uwtable 3 define dso_local i32 @main(i32 %0, i8** %1) #0 { 4 %3 = add nsw i32 %0, 1 5 %4 = trunc i32 %3 to i8 6 %5 = sub nsw i32 %0, 1 7 %6 = trunc i32 %5 to i8 8 %7 = sext i8 %4 to i32 9 %8 = sext i8 %6 to i32 10 %9 = add nsw i32 %7, %8 11 %10 = trunc i32 %9 to i8 12 %11 = sext i8 %10 to i32 13 %12 = mul nsw i32 %11, 4 14 %13 = trunc i32 %12 to i8 15 %14 = srem i32 %0, 2 16 %15 = icmp ne i32 %14, 0 17 br i1 %15, label %16, label %18 18 19 16: ; preds = %2 20 %17 = call i32 (i8*, ...) @printf(i8* getelementptr inbounds ([12 x i8], [12 x i8]* @.str, i64 0, i64 0), i32 %11) 21 br label %21 22 23 18: ; preds = %2 24 %19 = sext i8 %13 to i32 25 %20 = call i32 (i8*, ...) @printf(i8* getelementptr inbounds ([12 x i8], [12 x i8]* @.str, i64 0, i64 0), i32 %19) 26 br label %21 27 28 21: ; preds = %18, %16 29 ret i32 0 30 }
上面代码里面的trunc指令负责把大的数据类型转换成小的数据类型,因为函数入参是int,但计算时需要转换成char,但计算时编译器又会自动把它扩展成int32,这时又需要调用sext指令,加法运算完又要调用trunc指令转回char。
这就是为何经常有人建议,除非涉及协议对接,要不然不要用char当做整数处理,如果编译器不做优化的话,性能比直接用int会差很多。
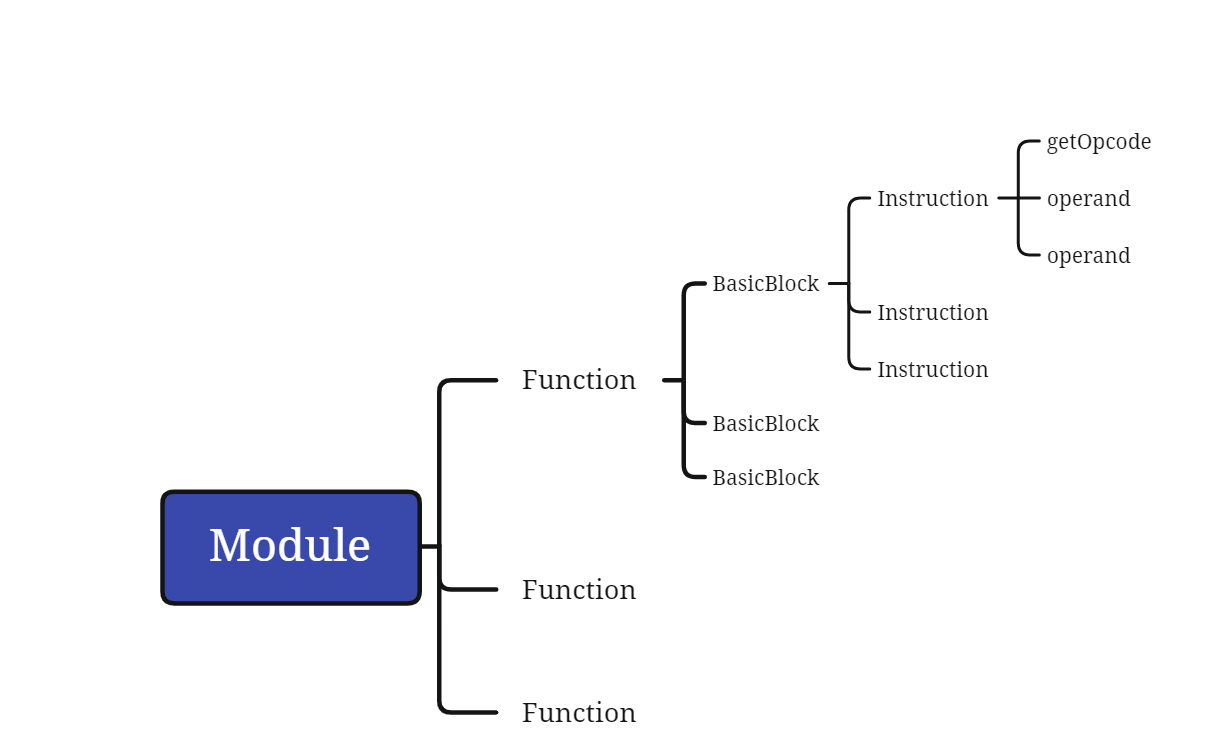
2.5.7 自己动手写一个llvm的pass写pass之前需要先了解一下llvm对代码的抽象。llvm代码抽象的最上层是Module,每个Module由一个或者多个Function组成,再往下依次是BasicBlock,Instruction,每条Instruction由一个OpCode和一个或者多个个operand组成。
我们的pass可以是针对下面任意一个层次的处理。
原ppt里面的写pass的流程是llvm2的,当前比较新的版本已经不可用,下面的例子是基于llvm11验证通过,参考了官网的例子https://www.llvm.org/docs/WritingAnLLVMPass.html#quick-start-writing-hello-world。
例如要写一个基于Function的Pass,需要继承自FunctionPass类,重载基于该类的runOnFunction虚函数。下面是一个计算函数内操作符个数的Pass:
1 #define DEBUG_TYPE "opCounter" 2 #include "llvm/IR/Function.h" 3 #include "llvm/Pass.h" 4 #include "llvm/Support/raw_ostream.h" 5 #include <map> 6 using namespace llvm; 7 namespace { 8 struct CountOp : public FunctionPass { 9 std::map<std::string, int> opCounter; 10 static char ID; 11 CountOp() : FunctionPass(ID) {} 12 virtual bool runOnFunction(Function &F) { 13 errs() << "Function " << F.getName() << '\n'; 14 for (Function::iterator bb = F.begin(), e = F.end(); bb != e; ++bb) { 15 for (BasicBlock::iterator i = bb->begin(), e = bb->end(); i != e; ++i) { 16 if (opCounter.find(i->getOpcodeName()) == opCounter.end()) { 17 opCounter[i->getOpcodeName()] = 1; 18 } else { 19 opCounter[i->getOpcodeName()] += 1; 20 } 21 } 22 } 23 std::map<std::string, int>::iterator i = opCounter.begin(); 24 std::map<std::string, int>::iterator e = opCounter.end(); 25 while (i != e) { 26 errs() << i->first << ": " << i->second << "\n"; 27 i++; 28 } 29 errs() << "\n"; 30 opCounter.clear(); 31 return false; 32 } 33 }; 34 } // namespace 35 char CountOp::ID = 0; 36 static RegisterPass<CountOp> X("opCounter", "Counts opcodes per functions");
通过runOnFunction的入参就是Function,通过遍历Function找到BasicBlock,通过遍历BasicBlock找到Instruction,获得Instruction的OpcodeName,并增加累加功能。函数遍历完之后,使用errors()错误输出流将计算的操作符的次数打印出来。
每个Pass都会定义一个ID,看大家代码都是统一赋值成0,看起来不可思议,实际上传给FunctionPass的是一个引用,这个引用再作为引用传递给FunctionPass的父类Pass,Pass将ID的地址作传给PassID,最终实现用每个类里面定义的ID的地址作为类的真实ID的效果。下面贴的代码为了表达这个传递关系,省略了其他无关代码:
282 class FunctionPass : public Pass { 283 public: 384 explicit FunctionPass(char &pid) : Pass(PT_Function, pid) {}
78 class Pass { 79 AnalysisResolver *Resolver = nullptr; // Used to resolve analysis 80 const void *PassID; 81 PassKind Kind; 82 83 84 public: 85 explicit Pass(PassKind K, char &pid) : PassID(&pid), Kind(K) {}
将上面写好的CountOp.cpp拷贝到llvm/lib/Transforms/CountOP目录下面,并将llvm/lib/Transforms/Hello/CMakeLists.txt拷贝到本目录下,将其中的Hello替换成我们新创建的CountOP:
1 # If we don't need RTTI or EH, there's no reason to export anything 2 # from the hello plugin. 3 if( NOT LLVM_REQUIRES_RTTI ) 4 if( NOT LLVM_REQUIRES_EH ) 5 set(LLVM_EXPORTED_SYMBOL_FILE ${CMAKE_CURRENT_SOURCE_DIR}/CountOP.exports) 6 endif() 7 endif() 8 9 if(WIN32 OR CYGWIN) 10 set(LLVM_LINK_COMPONENTS Core Support) 11 endif() 12 13 add_llvm_library( LLVMCountOP MODULE BUILDTREE_ONLY 14 CountOP.cpp 15 16 DEPENDS 17 intrinsics_gen 18 PLUGIN_TOOL 19 opt 20 )
修改llvm/lib/Transforms/CMakeLists.txt,增加一行“add_subdirectory(CountOP)”,然后启动llvm的编译。编译完会在当前build目录下面生成lib/LLVMCountOP.so库,将这个库拷贝到当前代码目录,执行下面命令就可以看到这个pass的执行结果:
1 root@e6db4f256fba:~/DCC888# opt -load LLVMCountOP.so --opCounter mem2reg.bc -disable-output 2 Function main 3 add: 1 4 alloca: 3 5 call: 1 6 load: 3 7 ret: 1 8 store: 3