你好呀,我是歪歪。
那天我正在用键盘疯狂的输出:

突然微信弹出一个消息,是一个读者发给我的。
我点开一看:
啊,这熟悉的味道,一看就是 HashMap,八股文梦开始的地方啊。
但是他问出的问题,似乎又不是一个属于 HashMap 的八股文:
为什么这里要把 table 变量赋值给 tab 呢?
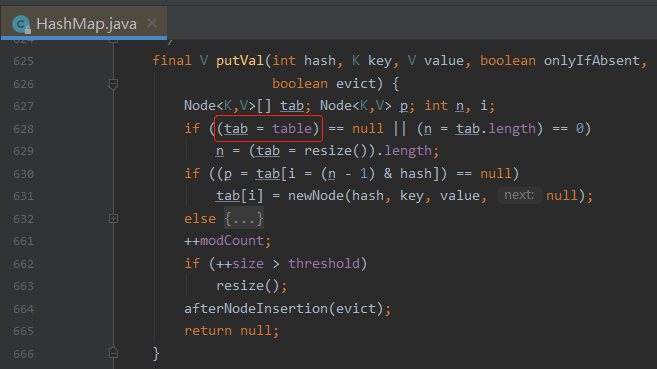
table 大家都知道,是 HashMap 的一个成员变量,往 map 里面放的数据就存储在这个 table 里面的:
在 putVal 方法里面,先把 table 赋值给了 tab 这个局部变量,后续在方法里面都是操作的这个局部变量了。
其实,不只是 putVal 方法,在 HashMap 的源码里面,“tab= table” 这样的写发多达 14 个,比如 getNode 里面也是这样的用法:
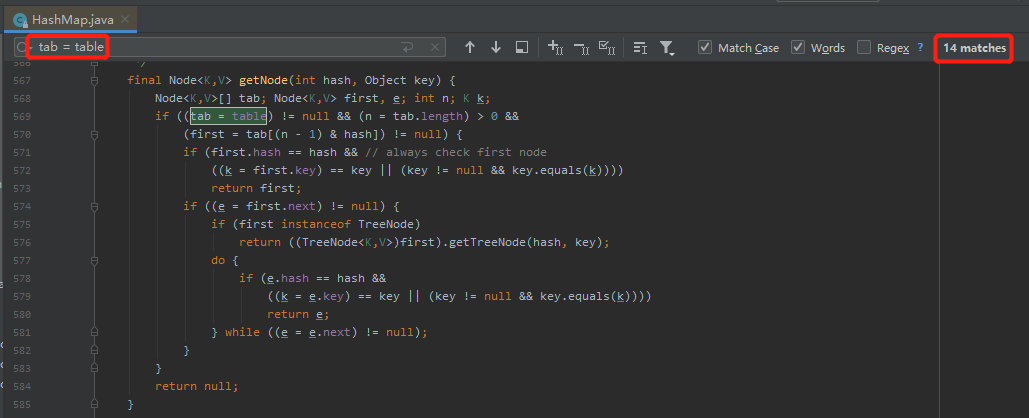
我们先思考一下,如果不用 tab 这个局部变量,直接操作 table,会不会有问题?
从代码逻辑和功能上来看,是不会有任何毛病的。
如果是其他人这样写,我会觉得可能是他的编程习惯,没啥深意,反正又不是不能用。
但是这玩意可是 Doug Lea 写的,隐约间觉得必然是有深意在里面的。

所以为什么要这样写呢?
巧了,我觉得我刚好知道答案是什么。
因为我在其他地方也看到过这种把成员变量赋值给局部变量的写法,而且在注释里面,备注了自己为什么这么写。
而这个地方,就是 Java 的 String 类:
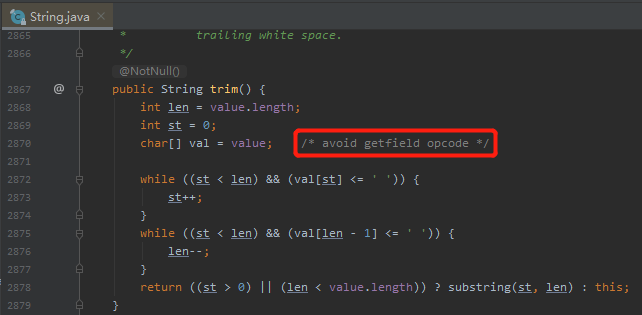
比如 String 类的 trim 方法,在这个方法里面就把 String 的 value 赋给了 val 这个局部变量。
然后旁边给了一个非常简短的注释:
avoid getfield opcode
本文的故事,就从一行注释开始,一路追溯到 2010 年,我终于抽丝剥茧找到了问题的答案。
一行注释,就是说要避免使用 getfield 字节码。
虽然我不懂是啥意思,但是至少我拿到了几个关键词,算是找到了一个“线头”,接下来的事情就很简单了,顺着这个线头往下缕就完事了。
而且直觉上告诉我这又是一个属于字节码层面的极端的优化,缕到最后一定是一个骚操作。
那么我就先给你说结论了:这个代码确实是 Doug Lea 写的,在当年确实是一种优化手段,但是时代变了,放到现在,确实没有卵用。

既然这里提到了字节码的操作,那么接下来的思路就是对比一下这两种不同写法分别的字节码是长啥样的不就清楚了吗?
比如我先来一段这样的测试代码:
public class MainTest {
private final char[] CHARS = new char[5];
public void test() {
System.out.println(CHARS[0]);
System.out.println(CHARS[1]);
System.out.println(CHARS[2]);
}
public static void main(String[] args) {
MainTest mainTest = new MainTest();
mainTest.test();
}
}
上面代码中的 test 方法,编译成字节码之后,是这样的:
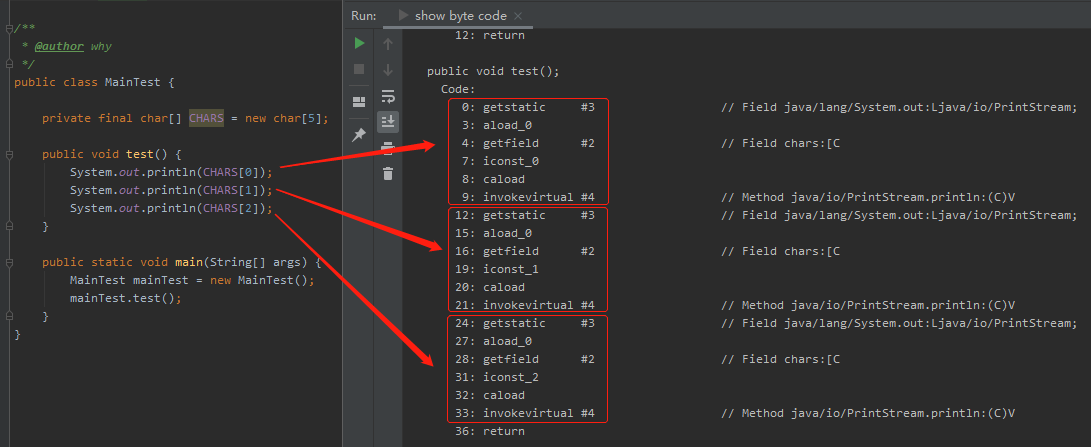
可以看到,三次输出,对应着三次这样的字节码:

在网上随便找个 JVM 字节码指令表,就可以知道这几个字节码分别在干啥事儿:
getstatic:获取指定类的静态域, 并将其压入栈顶 aload_0:将第一个引用类型本地变量推送至栈顶 getfield:获取指定类的实例域, 并将其值压入栈顶 iconst_0:将int型0推送至栈顶 caload:将char型数组指定索引的值推送至栈顶 invokevirtual:调用实例方法
如果,我把测试程序按照前面提到的写法修改一下,并重新生成字节码文件,就是这样的:
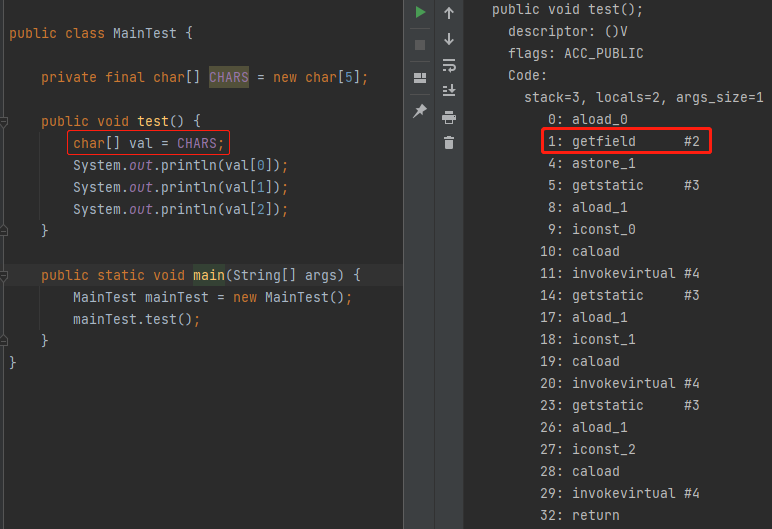
可以看到,getfield 这个字节码只出现了一次。
从三次到一次,这就是注释中写的“avoid getfield opcode”的具体意思。
确实是减少了生成的字节码,理论上这就是一种极端的字节码层面的优化。
具体到 getfield 这个命令来说,它干的事儿就是获取指定对象的成员变量,然后把这个成员变量的值、或者引用放入操作数栈顶。
更具体的说,getfield 这个命令就是在访问我们 MainTest 类中的 CHARS 变量。
往底层一点的说就是如果没有局部变量来承接一下,每次通过 getfield 方法都要访问堆里面的数据。
而让一个局部变量来承接一下,只需要第一次获取一次,之后都把这个堆上的数据,“缓存”到局部变量表里面,也就是搞到栈里面去。之后每次只需要调用 aload_
aload_
这一点,从 JVM 文档中对于这两个指令的描述的长度也能看出来:
https://docs.oracle.com/javase/specs/jvms/se7/html/jvms-6.html#jvms-6.5.getfield
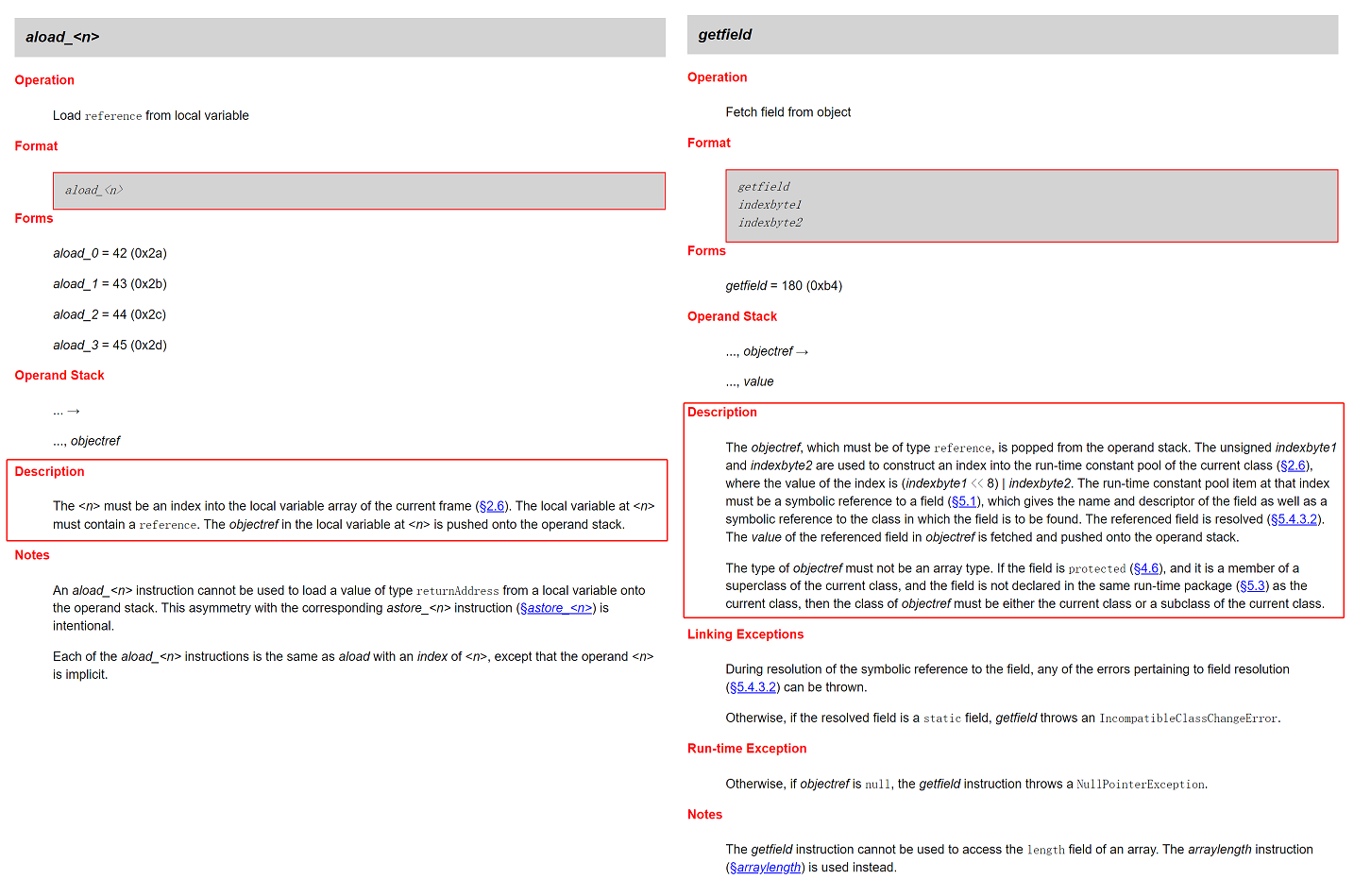
就不细说了,看到这里你应该明白:把成员变量赋值到局部变量之后再进行操作,确实是一种优化手段,可以达到“avoid getfield opcode”的目的。
看到这里你的心开始有点蠢蠢欲动了,感觉这个代码很棒啊,我是不是也可以搞一波呢?
不要着急,还有更棒的,我还没给你讲完呢。

在 Java 里面,我们其实可以看到很多地方都有这样的写法,比如我们前面提到的 HashMap 和 String,你仔细看 J.U.C 包里面的源码,很多都是这样写的。
但是,也有很多代码并没有这样写。
比如在 stackoverflow 就有这样的一个提问:
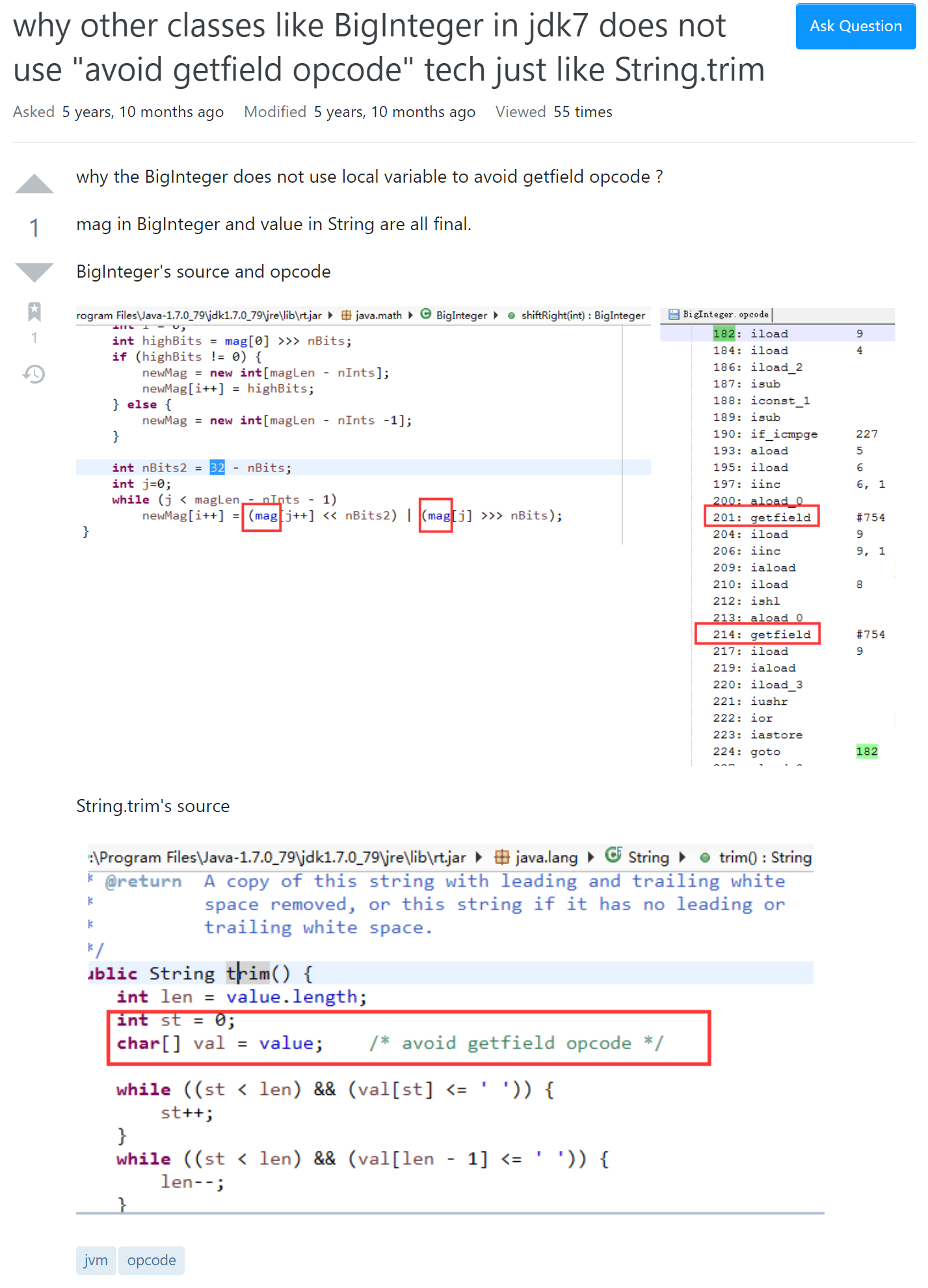
提问的哥们说为什么 BigInteger 没有采用 String 的 trim 方法 “avoid getfield opcode” 这样的写法呢?
下面的回答是这样说的:

在 JVM 中,String 是一个非常重要的类,这种微小的优化可能会提高一点启动速度。另一方面,BigInteger 对于 JVM 的启动并不重要。
所以,如果你看了这篇文章,自己也想在代码里面用这样的“棒”写法,三思。
醒醒吧,你才几个流量呀,值得你优化到这个程度?

而且,我就告诉你,前面字节码层面是有优化不假,我们都眼见为实了。
但是这个老哥提醒了我:

他提到了 JIT,是这样说的:这些微小的优化通常是不必要的,这只是减少了方法的字节码大小,一旦代码变得足够热而被 JIT 优化,它并不真正影响最终生成的汇编。
于是,我在 stackoverflow 上一顿乱翻,终于在万千线索中,找出了我觉得最有价值的一个。
这个问题,就和文章开头的读者问我的可以说一模一样了:
https://stackoverflow.com/questions/28975415/why-jdk-code-style-uses-a-variable-assignment-and-read-on-the-same-line-eg-i
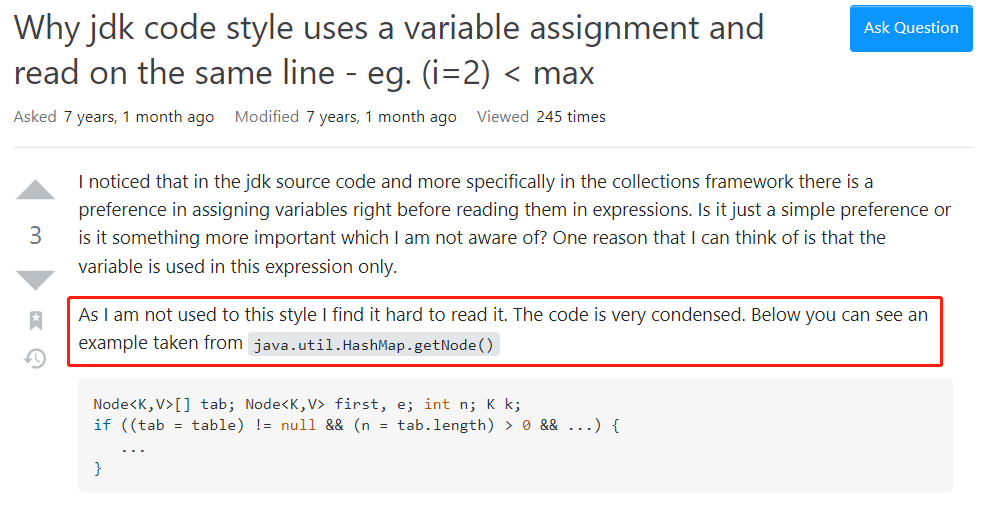
这个哥们说:在 jdk 源码中,更具体地说,是在集合框架中,有一个编码的小癖好,就是在表达式中读取变量之前,先将其赋值到一个局部变量中。这只是一个简单的小癖好吗,还是里面藏着一下我没有注意到的更重要的东西?
随后,还有人帮他补充了几句:

这代码是 Doug Lea 写的,小 Lea 子这人吧,经常搞一些出其不意的代码和优化。他也因为这些“莫名其妙”的代码闻名,习惯就好了。
然后这个问题下面有个回答是这样说的:

Doug Lea 是集合框架和并发包的主要作者之一,他编码的时候倾向于进行一些优化。但是这些优化这可能会违反直觉,让普通人感到困惑。
毕竟人家是在大气层。
接着他给出了一段代码,里面有三个方法,来验证了不同的写法生成的不同的字节码:

三个方法分别如下:
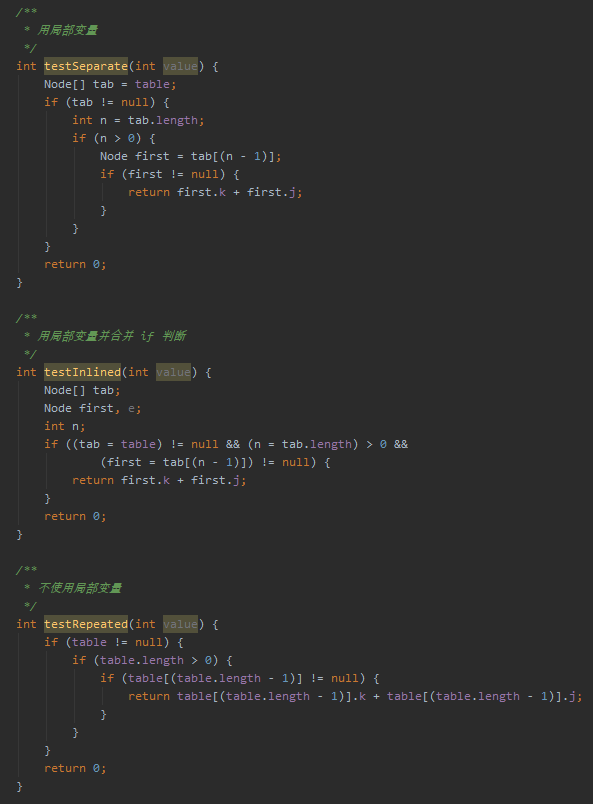
对应的字节码我就不贴了,直接说结论:
The testSeparate method uses 41 instructions
The testInlined method indeed is a tad smaller, with 39 instructions
Finally, the testRepeated method uses a whopping 63 instructions
同样的功能,但是最后一种直接使用成员变量的写法生成的字节码是最多的。
所以他给出了和我前面一样的结论:

这种写法确实可以节省几个字节的字节码,这可能就是使用这种方式的原因。
但是...
主要啊,他要开始 but 了:
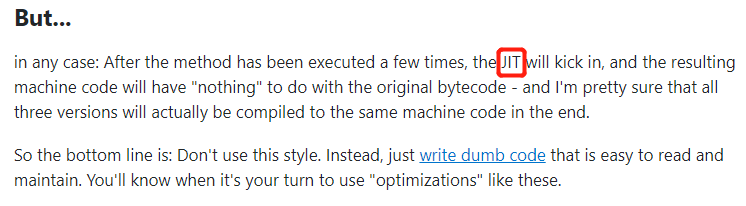
但是,在不论是哪个方法,在被 JIT 优化之后,产生的机器代码将与原始字节码“无关”。
可以非常确定的是:三个版本的代码最终都会编译成相同的机器码(汇编)。
因此,他的建议是:不要使用这种风格,只需编写易于阅读和维护的“愚蠢”代码。你会知道什么时候轮到你使用这些“优化”。
可以看到他在“write dumb code”上附了一个超链接,我挺建议你去读一读的:
https://www.oracle.com/technical-resources/articles/javase/devinsight-1.html
在这里面,你可以看到《Java Concurrency in Practice》的作者 Brian Goetz:

他对于“dumb code”这个东西的解读:

他说:通常,在 Java 应用程序中编写快速代码的方法是编写“dumb code”——简单、干净,并遵循最明显的面向对象原则的代码。
很明显,tab = table 这种写法,并不是 “dumb code”。

好了,说回这个问题。这个老哥接着做了进一步的测试,测试结果是这样的:

他对比了 testSeparate 和 TestInLine 方法经过 JIT 优化之后的汇编,这两个方法的汇编是相同的。
但是,你要搞清楚的是这个小哥在这里说的是 testSeparate 和 testInLine 方法,这两个方法都是采用了局部变量的方式:
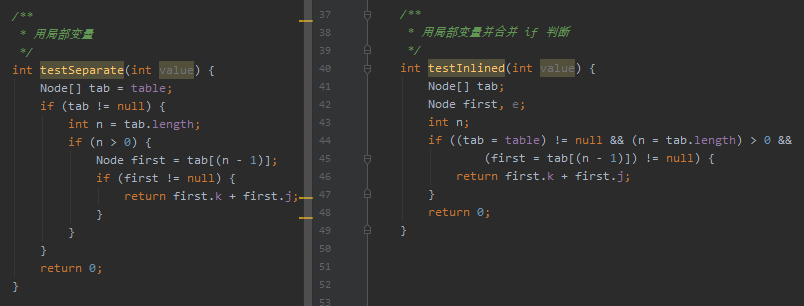
只是 testSeparate 的可读性比 testInLine 高了很多。
而 testInLine 的写法,就是 HashMap 的写法。
所以,他才说:我们程序员可以只专注于编写可读性更强的代码,而不是搞这些“骚”操作。JIT 会帮我们做好这些东西。
从 testInLine 的方法命名上来看,也可以猜到,这就是个内联优化。
它提供了一种(非常有限,但有时很方便)“线程安全”的形式:它确保数组的长度(如 HashMap 的 getNode 方法中的 tab 数组)在方法执行时不会改变。
他为什么没有提到我们更关心的 testRepeated 方法呢?
他也在回答里面提到这一点:
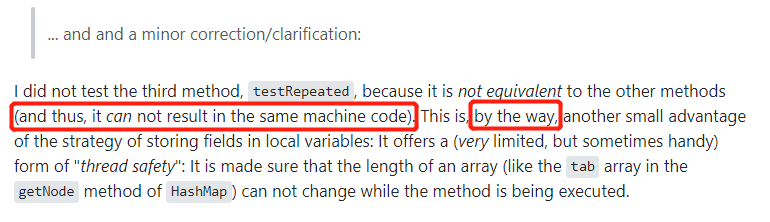
他对之前的一个说法进行了 a minor correction/clarification。
啥意思,直接翻译过来就是进行一个小的修正或者澄清。用我的话说就是,前面话说的有点满,现在打脸了,你听我狡辩一下。
前面他说的是什么?
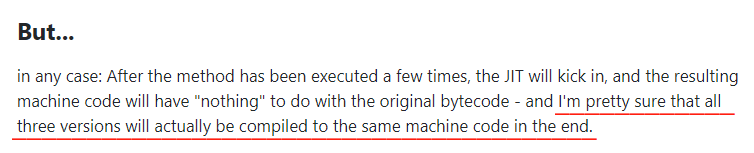
他说:这都不用看,这三个方法最终生成的汇编肯定是一模一样的。
但是现在他说的是:
it can not result in the same machine code
它不能产生相同的汇编

最后,这个老哥还补充了这个写法除了字节码层面优化之外的另一个好处:
一旦在这里对 n 进行了赋值,在 getNode 这个方法中 n 是不会变的。如果直接使用数组的长度,假设其他方法也同时操作了 HashMap,在 getNode 方法中是有可能感知到这个变化的。
这个小知识点我相信大家都知道,很直观,不多说了。
但是,看到这里,我们好像还是没找到问题的答案。
那就接着往下挖吧。
继续挖继续往下挖的线索,其实已经在前面出现过了:

通过这个链接,我们可以来到这个地方:
https://stackoverflow.com/questions/2785964/in-arrayblockingqueue-why-copy-final-member-field-into-local-final-variable
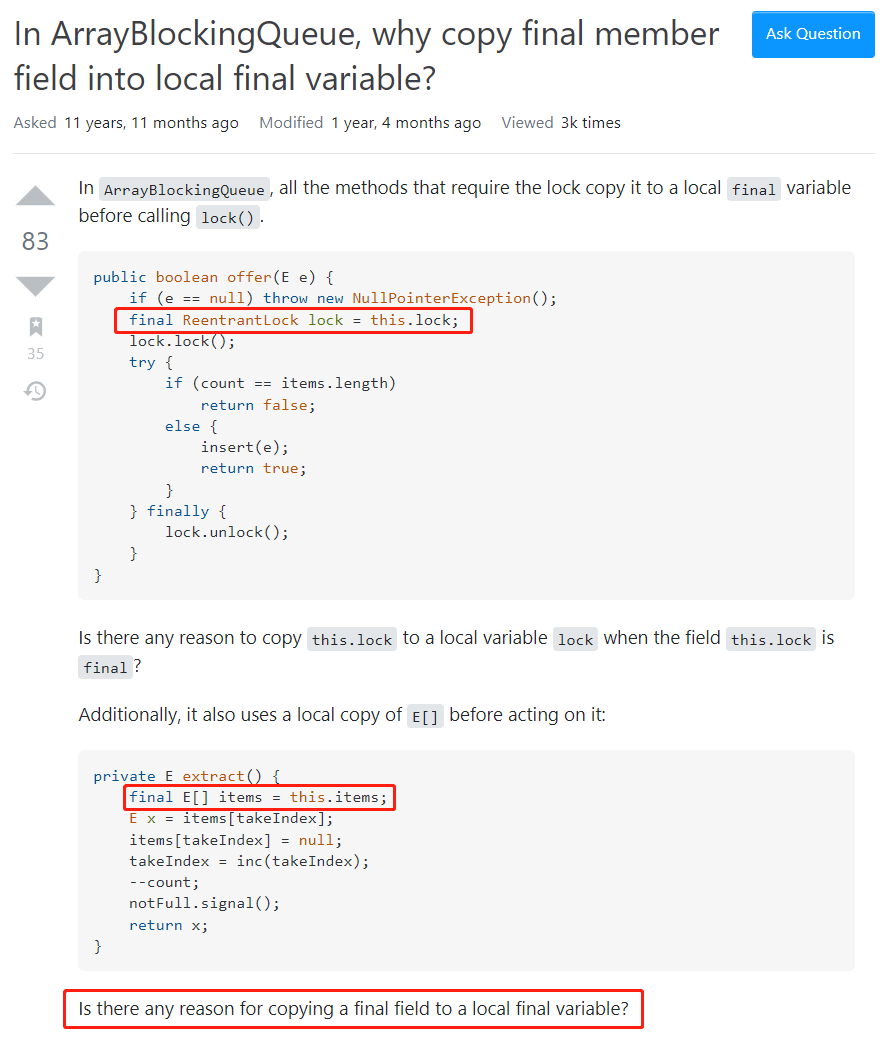
瞟一眼我框起来的代码,你会发现这里抛出的问题其实又是和前面是一样。
我为什么又要把它拿出来说一次呢?
因为它只是一个跳板而已,我想引出这下面的一个回答:
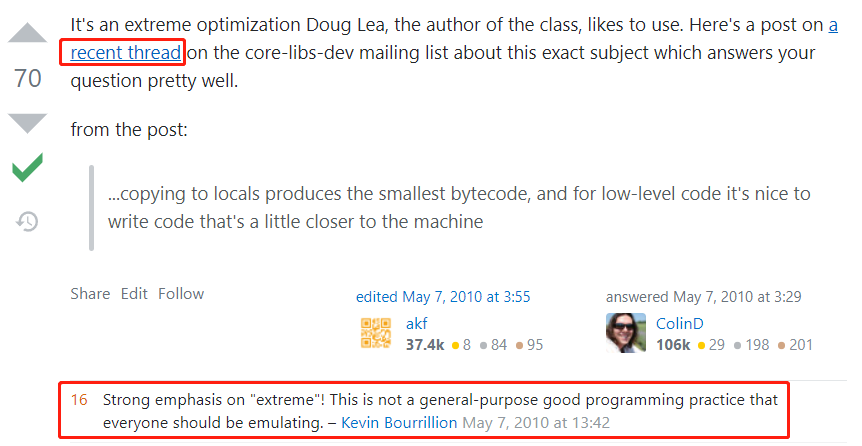
这个回答说里面有两个吸引到我注意的地方。
第一个就是这个回答本身,他说:这是该类的作者 Doug Lea 喜欢使用的一种极端优化。这里有个超链接,你可以去看看,能很好地回答你的问题。
这里面提到的这个超链接,很有故事:
http://mail.openjdk.java.net/pipermail/core-libs-dev/2010-May/004165.html
但是在说这个故事之前,我想先说说这个回答下面的评论,也就是我框起来的部分。
这个评论观点鲜明的说:需要着重强调“极端”!这不是每个人都应该效仿的、通用的、良好的写法。
凭借我在 stackoverflow 混了这么几年的自觉,这里藏龙卧虎,一般来说 说话底气这么足的,都是大佬。
于是我点了他的名字,去看了一眼,果然是大佬:
这哥们是谷歌的,参与了很多项目,其中就有我们非常熟悉的 Guava,而且不是普通开发者,而是 lead developer。同时也参与了 Google 的 Java 风格指南编写。
所以他说的话还是很有分量的,得听。
然后,我们去到那个很有故事的超链接。
这个超链接里面是一个叫做 Ulf Zibis 的哥们提出的问题:

Ulf 同学的提问里面提到说:在 String 类中,我经常看到成员变量被复制到局部变量。我在想,为什么要做这样的缓存呢,就这么不信任 JVM 吗,有没有人能帮我解答一下?
Ulf 同学的问题和我们文章中的问题也是一样的,而他这个问题提出的时间是 2010 年,应该是我能找到的关于这个问题最早出现的地方。
所以你要记住,下面的这些邮件中的对话,已经是距今 12 年前的对话了。
在对话中,针对这个问题,有比较官方的回答:
回答他问题这个人叫做 Martin Buchholz,也是 JDK 的开发者之一,Doug Lea 的同事,他在《Java并发编程实战》一书里面也出现过:
.png)
来自 SUN 公司的 JDK 并发大师,就问你怕不怕。
他说:这是一种由 Doug Lea 发起的编码风格。这是一种极端的优化,可能没有必要。你可以期待 JIT 做出同样的优化。但是,对于这类非常底层的代码来说,写出的代码更接近于机器码也是一件很 nice 的事情。
关于这个问题,这几个人有来有回的讨论了几个回合:

在邮件的下方,有这样的链接可以点击,可以看到他们讨论的内容:

主要再看看这个叫做 Osvaldo 对线 Martin 的邮件:
https://mail.openjdk.java.net/pipermail/core-libs-dev/2010-May/004168.html

Osvaldo 老哥写了这么多内容,主要是想喷 Martin 的这句话:这是一种极端的优化,可能没有必要。你可以期待 JIT 做出同样的优化。
他说他做了实验,得出的结论是这个优化对以 Server 模式运行的 Hotspot 来说没有什么区别,但对于 Client 模式运行的 Hotspot 来说却非常重要。在他的测试案例中,这种写法带来了 6% 的性能提升。
然后他说他现在包括未来几年写的代码应该都会运行在以 Client 模式运行的 Hotspot 中。所以请不要乱动 Doug 特意写的这种优化代码,我谢谢你全家。
同时他还提到了 JavaME、JavaFX Mobile&TV,让我不得不再次提醒你:这段对话发生在 12 年前,他提到的这些技术,在我的眼里已经是过眼云烟了,只听过,没见过。
哦,也不能算没见过,毕竟当年读初中的时候还玩过 JavaME 写的游戏。
就在 Osvaldo 老哥言辞比较激烈的情况下,Martin 还是做出了积极的回应:

Martin 说谢谢你的测试,我也已经把这种编码风格融合到我的代码里面了,但是我一直在纠结的事情是是否也要推动大家这样去做。因为我觉得我们可以在 JIT 层面优化这个事情。
接下来,最后一封邮件,来自一位叫做 David Holmes 的老哥。
巧了,这位老哥的名字在《Java并发编程实战》一书里面,也可以找到。
人家就是作者,我介绍他的意思就是想表达他的话也是很有分量的:

因为他的这一封邮件,算是给这个问题做了一个最终的回答。

我带着自己的理解,用我话来给你全文翻译一下,他是这样说的:
我已经把这个问题转给了 hotspot-compiler-dev,让他们来跟进一下。
我知道当时 Doug 这样写的原因是因为当时的编译器并没有相应的优化,所以他这样写了一下,帮助编译器进行优化了一波。但是,我认为这个问题至少在 C2 阶段早就已经解决了。如果是 C1 没有解决这个问题的话,我觉得是需要解决一下的。
最后针对这种写法,我的建议是:在 Java 层面上不应该按照这样的方式去敲代码。
There should not be a need to code this way at the Java-level.
至此,问题就梳理的很清楚了。
首先结论是不建议使用这样的写法。
其次,Doug 当年这样写确实是一种优化,但是随着编译器的发展,这种优化下沉到编译器层面了,它帮我们做了。
最后,如果你不明白前面提到的 C1,C2 的话,那我换个说法。
C1 其实就是 Client Compiler,即客户端编译器,特点是编译时间较短但输出代码优化程度较低。
C2 其实就是 Server Compiler,即服务端编译器,特点是编译耗时长但输出代码优化质量也更高。
前面那个 Osvaldo 说他主要是用客户端编译器,也就是 C1。所以后面的 David Holmes 才一直在说 C2 是优化了这个问题的,C1 如果没有的话可以跟进一下,巴拉巴拉巴拉的...
关于 C2 的话,简单提一下,记得住就记,记不住也没关系,这玩意一般面试也不考。
大家常常提到的 JVM 帮我们做的很多“激进”的为了提升性能的优化,比如内联、快慢速路径分析、窥孔优化,都是 C2 搞的事情。
另外在 JDK 10 的时候呢,又推出了 Graal 编译器,其目的是为了替代 C2。
至于为什么要替换 C2,额,原因之一你可以看这个链接...
http://icyfenix.cn/tricks/2020/graalvm/graal-compiler.html
C2 的历史已经非常长了,可以追溯到 Cliff Click 大神读博士期间的作品,这个由 C++ 写成的编译器尽管目前依然效果拔群,但已经复杂到连 Cliff Click 本人都不愿意继续维护的程度。
你看前面我说的 C1、C1 的特点,刚好是互补的。
所以为了在程序启动、响应速度和程序运行效率之间找到一个平衡点,在 JDK 6 之后,JVM 又支持了一种叫做分层编译的模式。
也是为什么大家会说:“Java 代码运行起来会越来越快、Java 代码需要预热”的根本原因和理论支撑。
在这里,我引用《深入理解Java虚拟机HotSpot》一书中 7.2.1 小节[分层编译]的内容,让大家简单了解一下这是个啥玩意。
首先,我们可以使用 -XX:+TieredCompilation 开启分层编译,它额外引入了四个编译层级。
第 0 级:解释执行。 第 1 级:C1 编译,开启所有优化(不带 Profiling)。Profiling 即剖析。 第 2 级:C1 编译,带调用计数和回边计数的 Profiling 信息(受限 Profiling). 第 3 级:C1 编译,带所有Profiling信息(完全Profiling). 第 4 级:C2 编译。
常见的分层编译层级转换路径如下图所示:

0→3→4:常见层级转换。用 C1 完全编译,如果后续方法执行足够频繁再转入 4 级。 0→2→3→4:C2 编译器繁忙。先以 2 级快速编译,等收集到足够的 Profiling 信息后再转为3级,最终当 C2 不再繁忙时再转到 4 级。 0→3→1/0→2→1:2/3级编译后因为方法不太重要转为 1 级。如果 C2 无法编译也会转到 1 级。 0→(3→2)→4:C1 编译器繁忙,编译任务既可以等待 C1 也可以快速转到 2 级,然后由 2 级转向 4 级。
如果你之前不知道分层编译这回事,没关系,现在有这样的一个概念就行了。
再说一次,面试不会考的,放心。
好了,恭喜你看到这里了。回想全文,你学到了什么东西呢?
是的,除了一个没啥卵用的知识点外,什么都没有学到。

本文首发于公众号why技术,转载请注明出处和链接。