Raft协议是比paxos协议更容易理解和实现的一种一致性协议。http://thesecretlivesofdata.com/raft/ 这个网址动态演示了Raft协议的整个过程。跟着记录一下:
1:Raft是一个可被理解接受的分布式一致性协议。

2:什么是分布式一致性协议呢?以一个例子为例

3:假设有一个单节点系统

4:假设这个节点是个数据库服务器,只存储了一个数据。

5:假设存储的数据是 X

6: 现在有个客户端可以向这个server发送数据

7:向server端发送了修改数据的请求
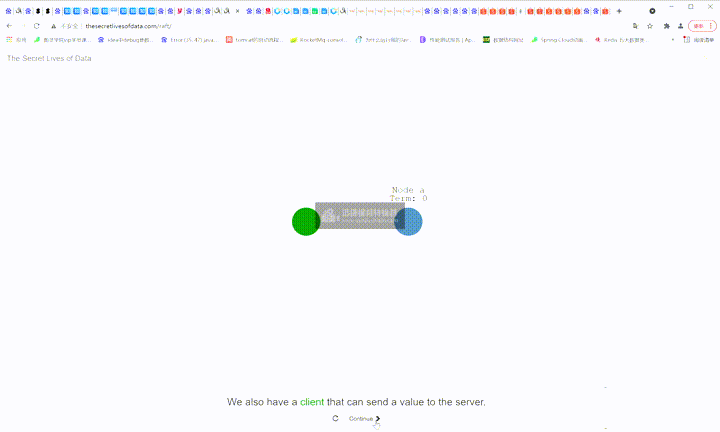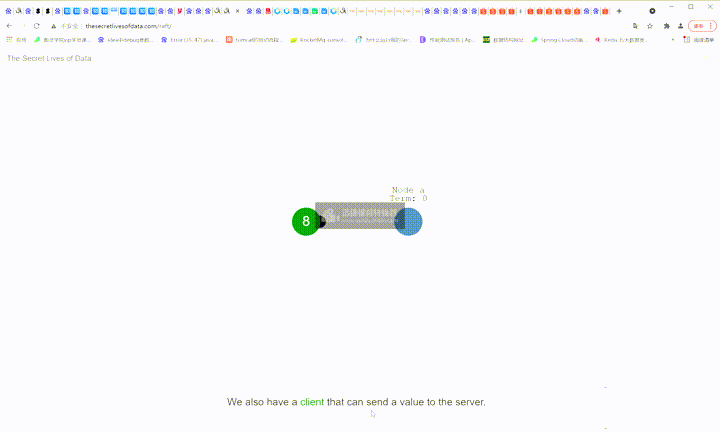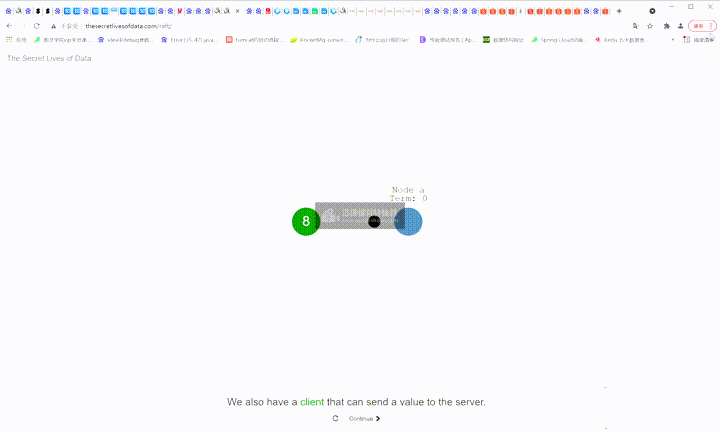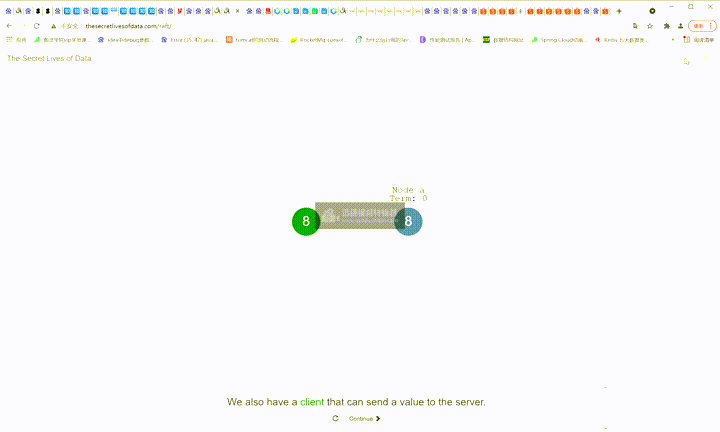
8:在一个节点上,很容易做到数据一致性。

9:如果有多个节点,又如何让数据保持一致性呢。这就是分布式一致性的问题。

10:Raft是一种用于实现分布式一致性的协议。

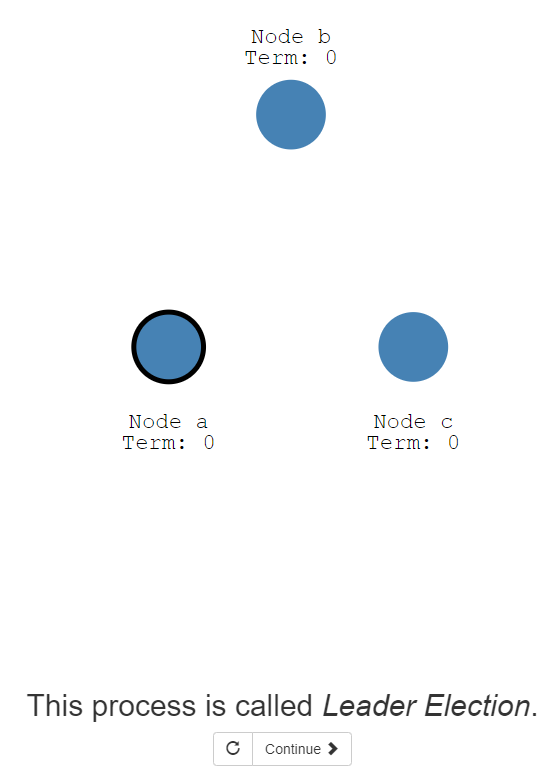
11:让我们从总体上看一下它是如何工作的。一个节点的状态分为三种:Follower,Candidate,Leader




12:所有的节点刚开始都是follower的状态。

13:如果follower状态的节点,没有接收到来自leader的信息,那么这个节点就可以变成candidate状态

14:候选者节点会向其他节点发送投票请求。

15:候选者如果得到了大多数节点的投票,这个候选者就变成了leader。

上述过程被称为Leader选举过程。

当leader选举出来之后,对于当前系统的所有写操作都通过leader来完成。如果有客户端请求到follower节点,也会转到leader来。

16:每次的变更,都会在节点上的日志中新增一条记录。

17:这条日志记录当前还是未提交的状态,所以还没有真正的更新节点上的值。

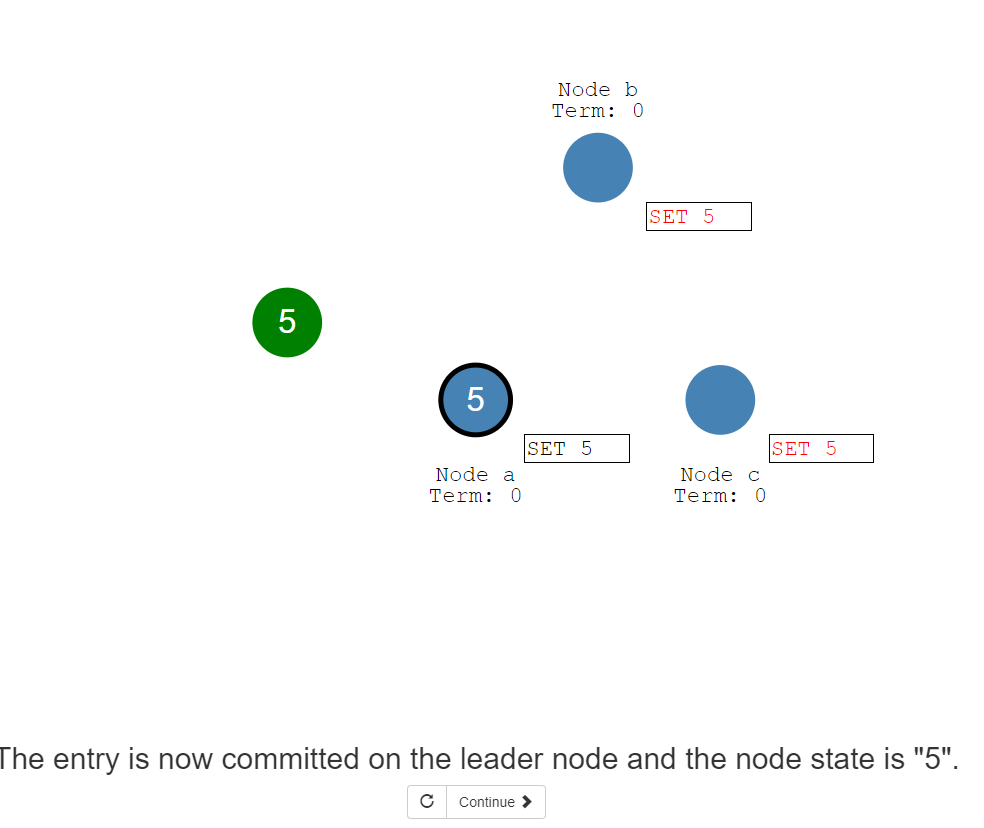
18:leader节点为了提交这条记录,首先把它复制到其它follower节点上去。

19:leader节点等待大多数follower节点将这条变更记录写入成功并返回。

20:到这里,这条变更记录在leader节点才处于提交状态,节点的状态记录为 “5”,写入内存成功。
21:leader节点通知其他follower节点变更记录进行提交。
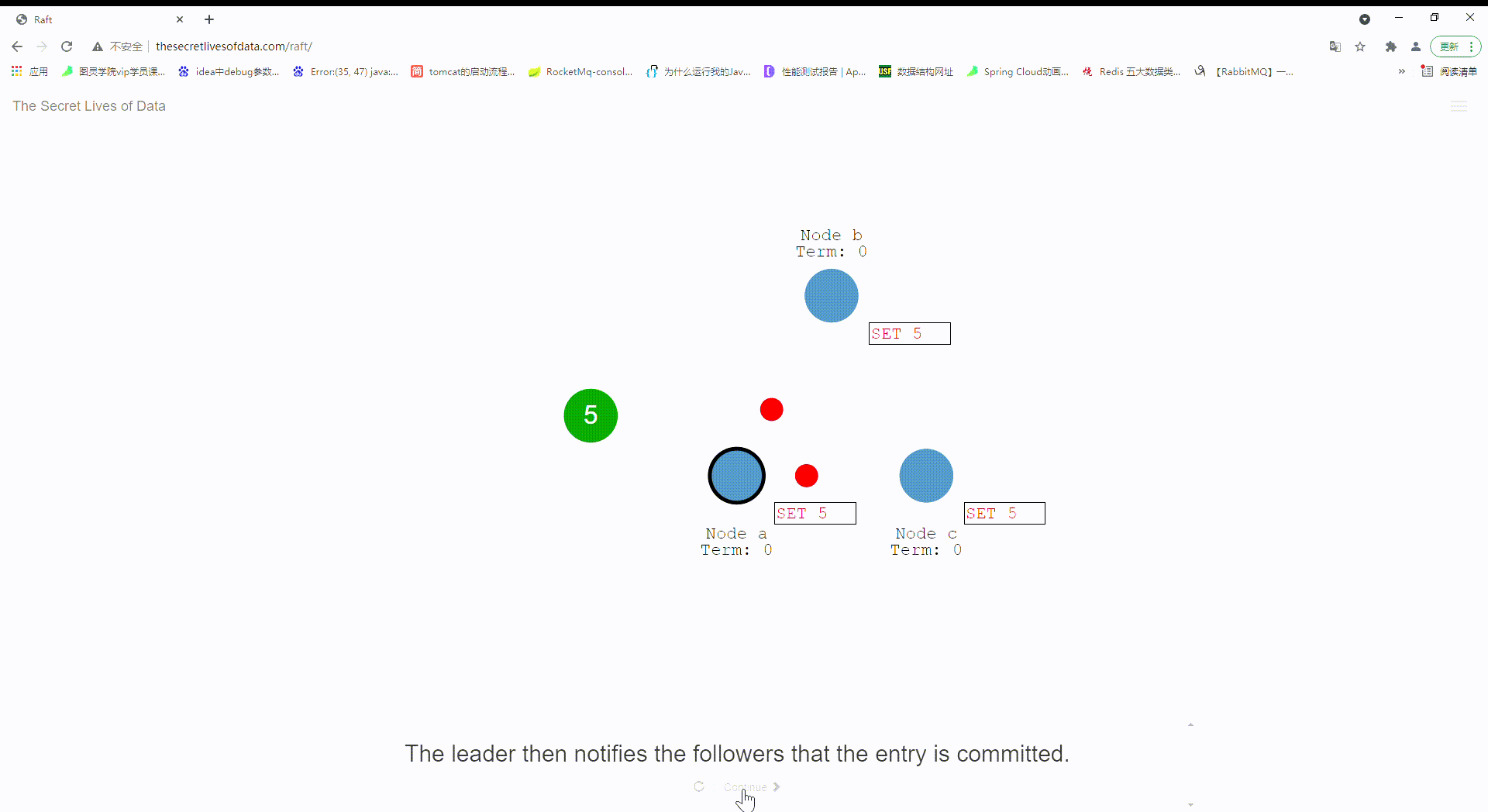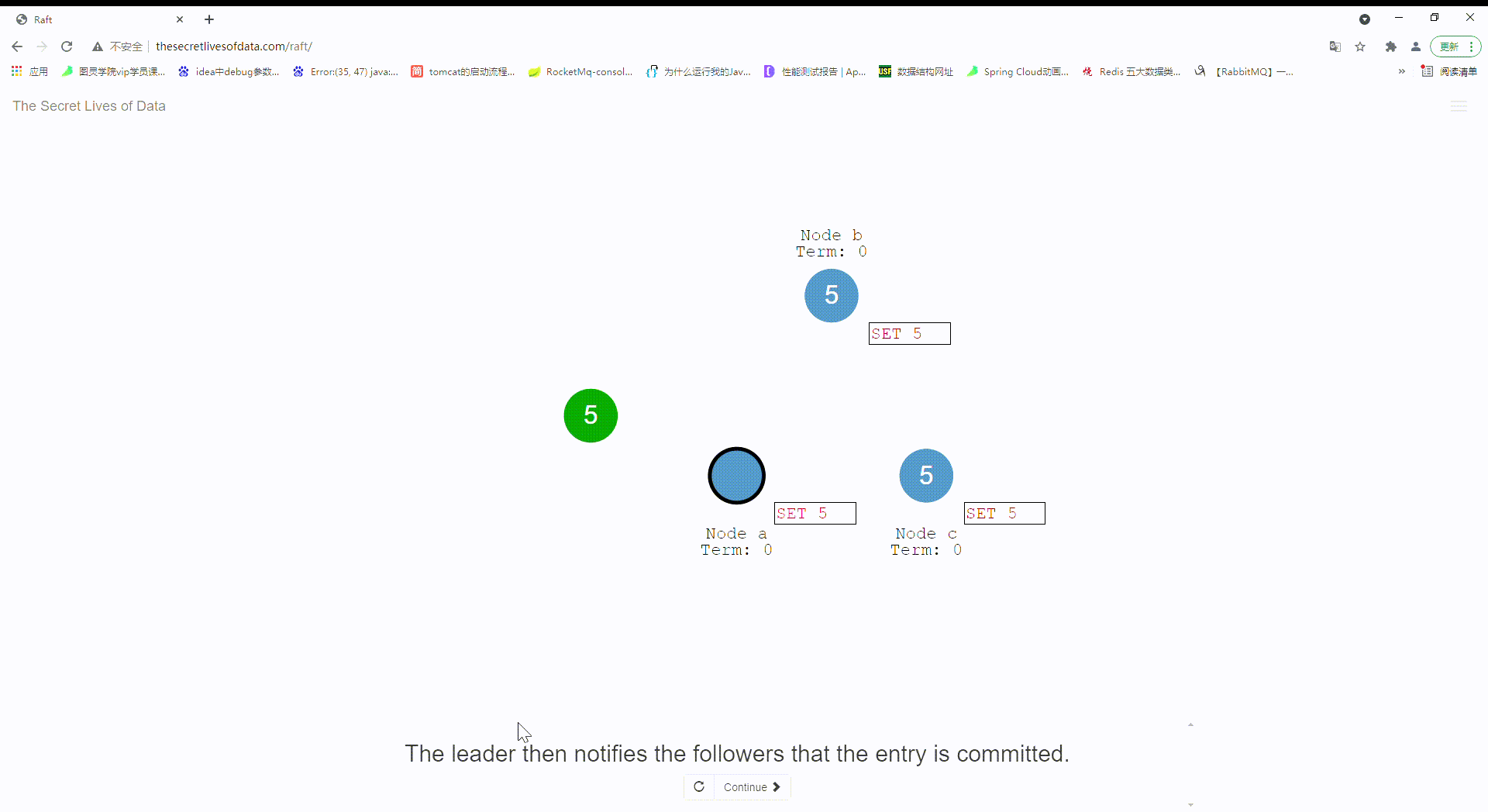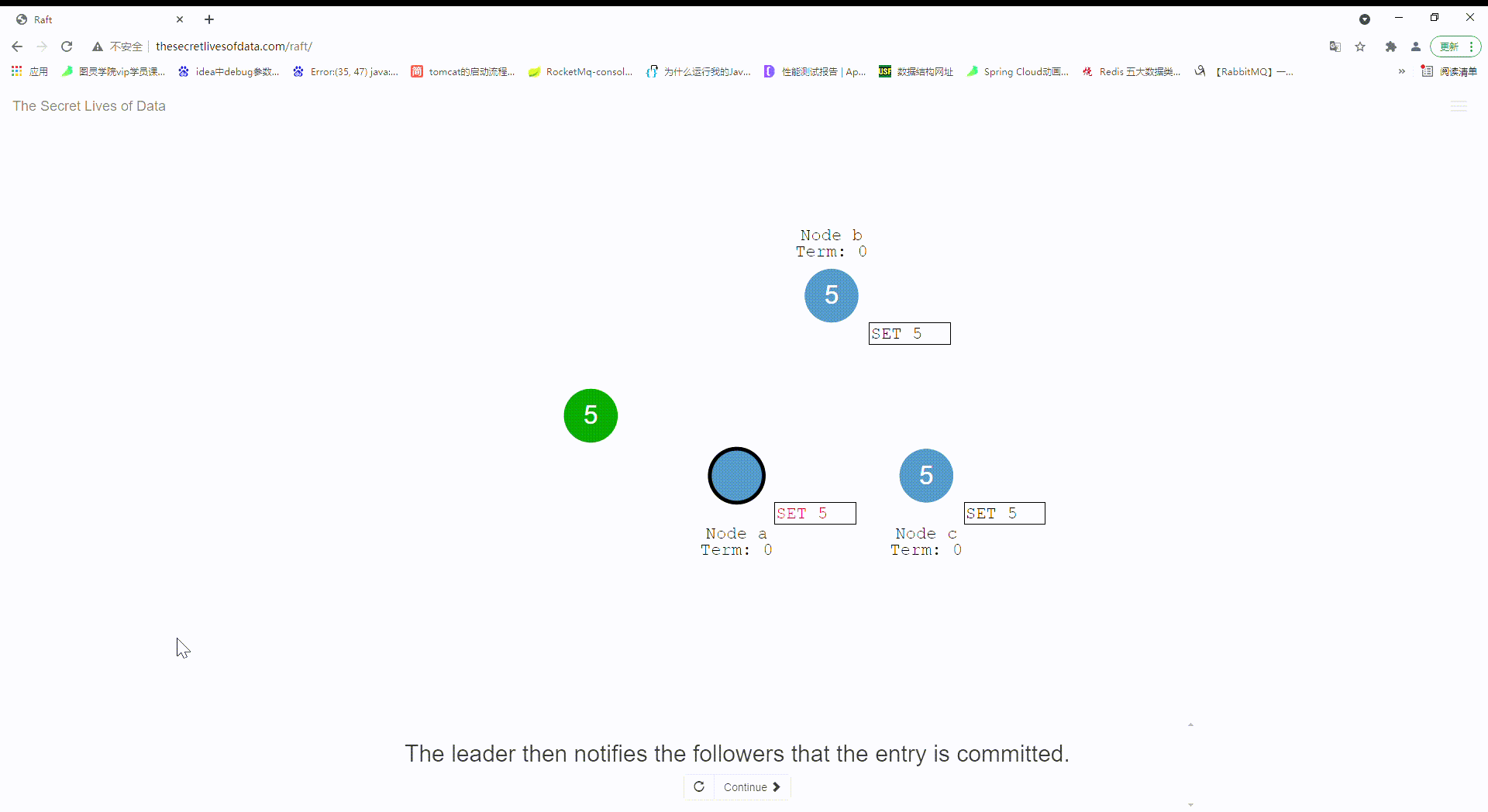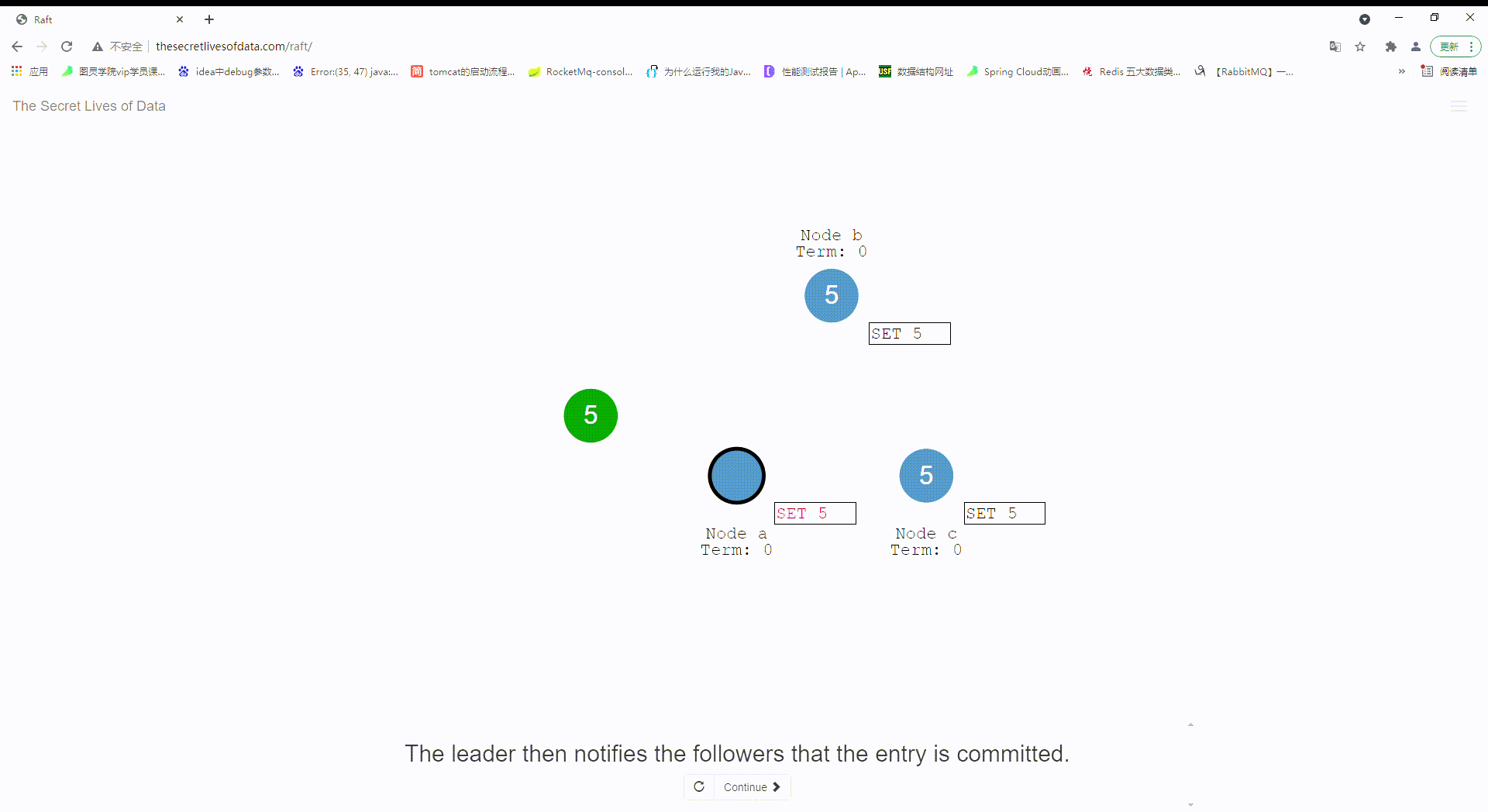
22:当前集群现在对于系统状态而言已经达到了一致性。实际上通过了两个阶段提交uncommit,commit.
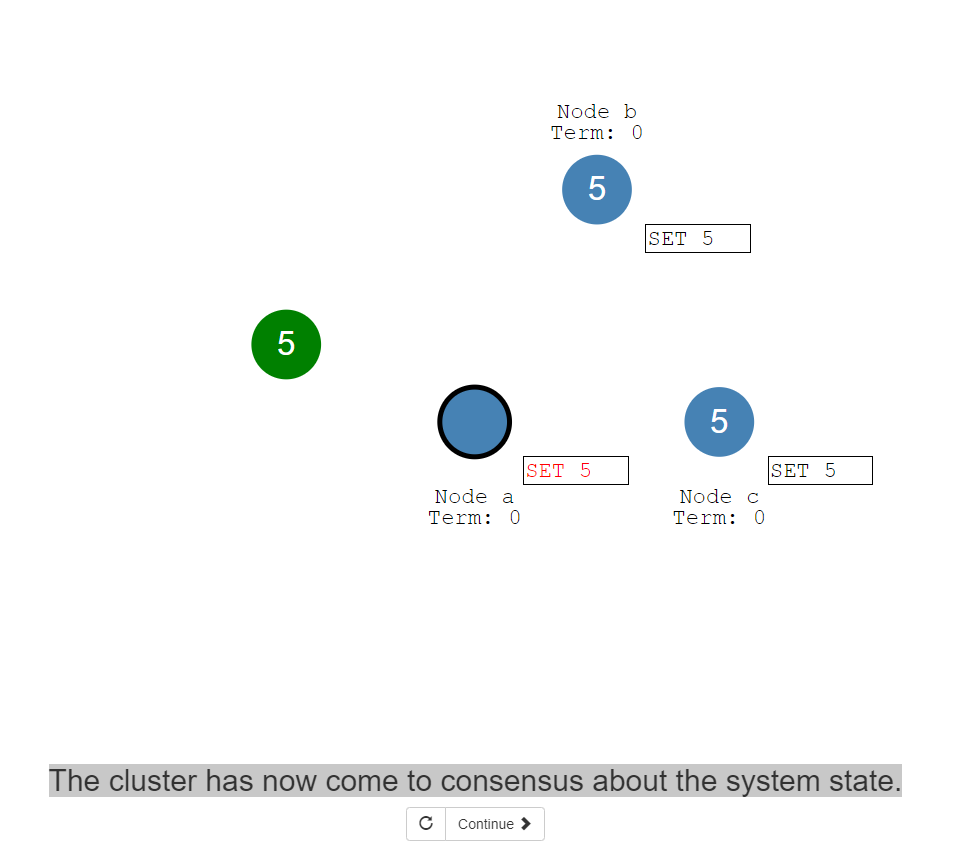
上述过程称为日志复制

23:在Raft协议中有两个超时时间的设置来控制选举。

24:第一个是选举超时时间。
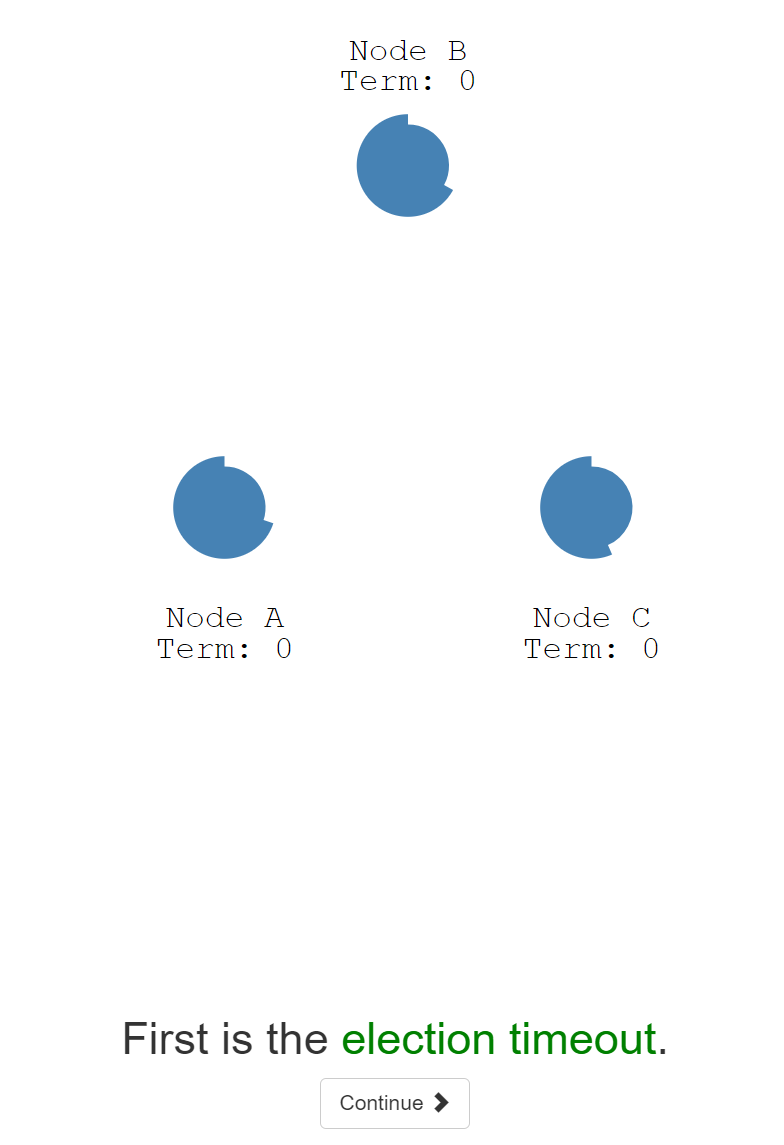
25:这个选举超时时间是指follower等待变成candidate的时间。
26:这个选举超时时间是150ms~300ms之间的随机值。

27:每个节点在election time 内自我选举成candidate,然后开始新一轮的选举投票。候选者会发送投票请求给其他节点,让其他节点投票给自己称为leader。
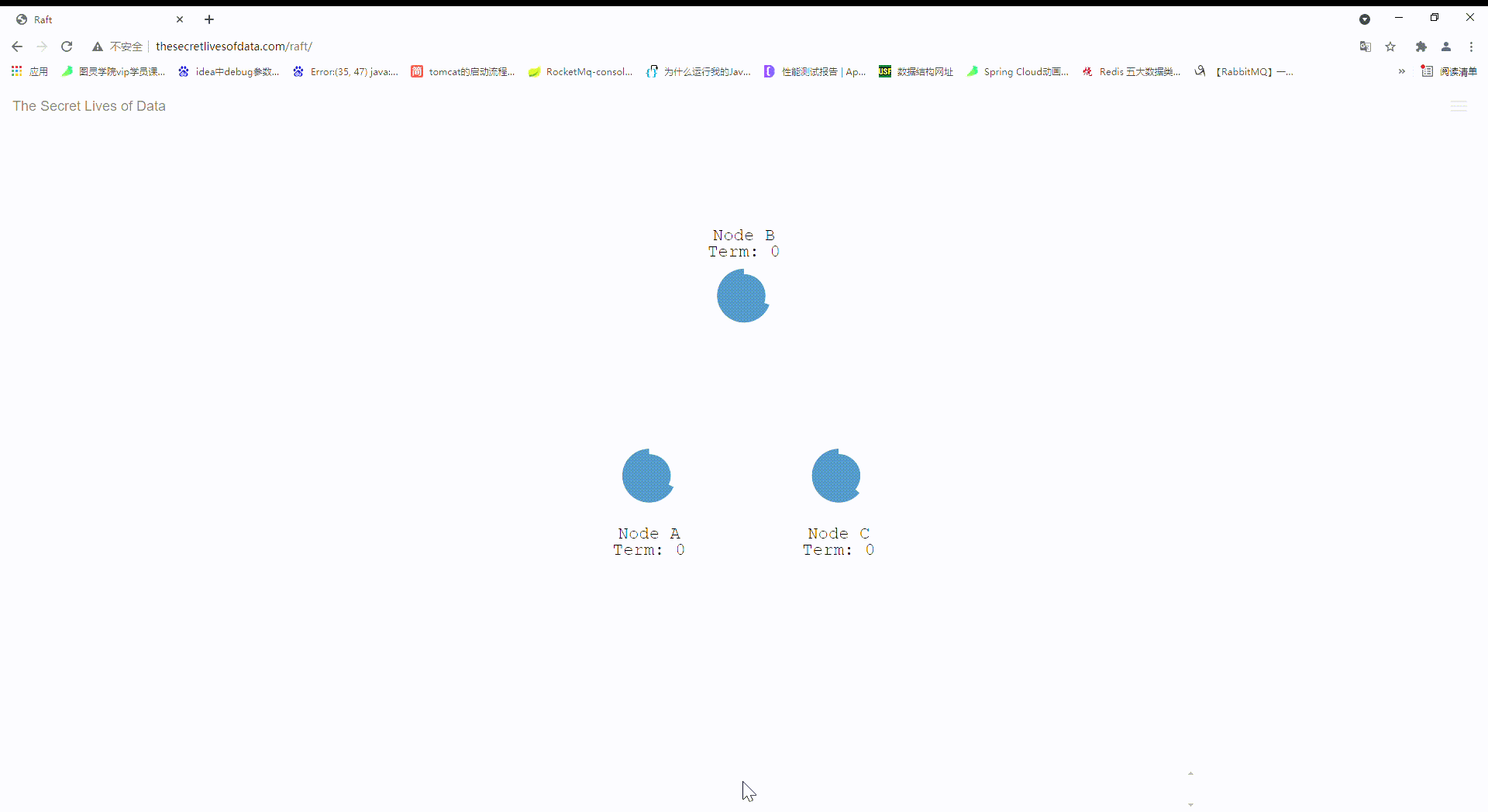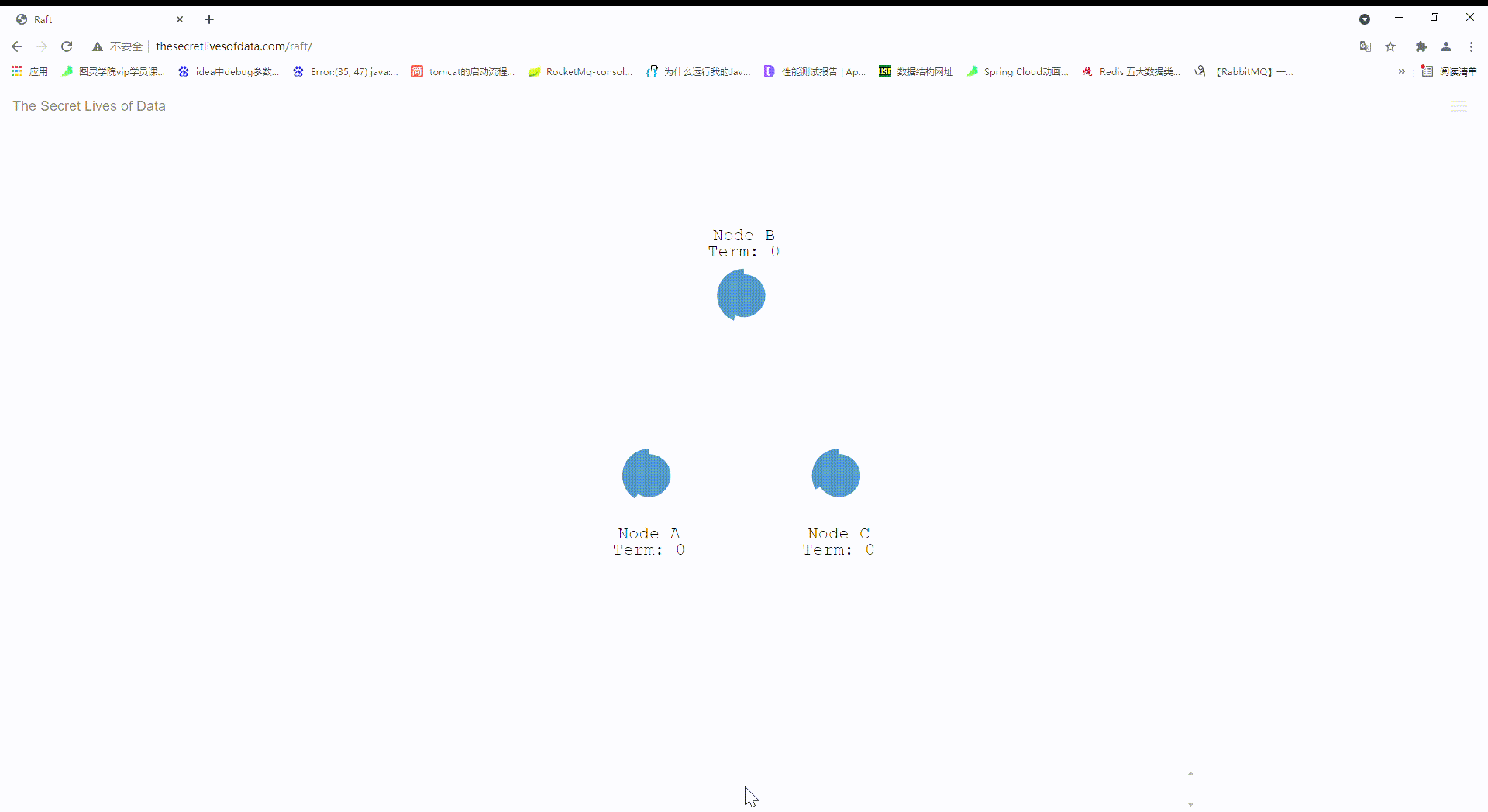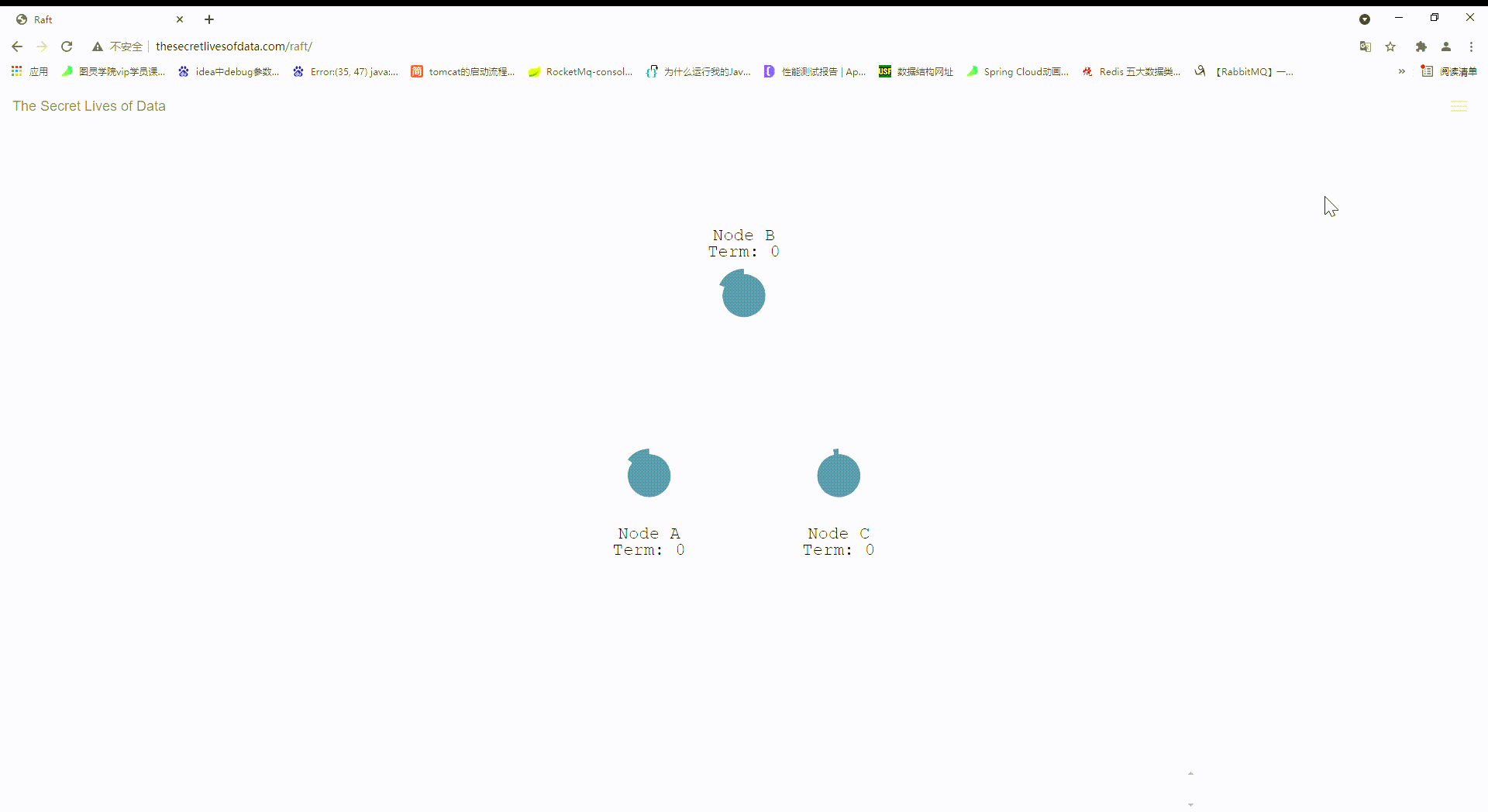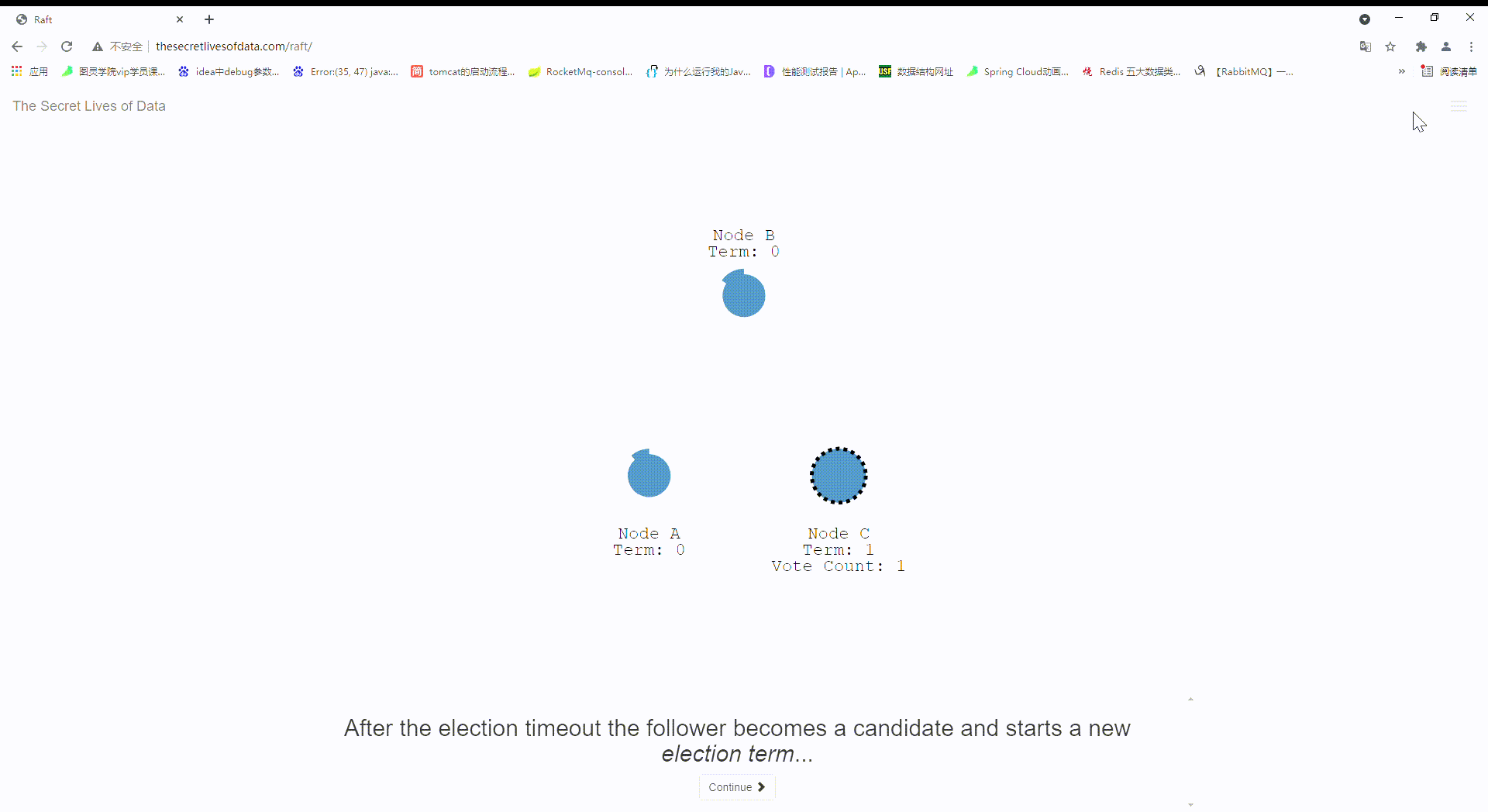


28:如果接收到请求的节点在当前周期内还没有进行过投票,那么它就会投票给当前这个candidate。然后receiving节点会重置选举超时时间。一旦candidate接收到大多数节点的投票,它就会变成leader。

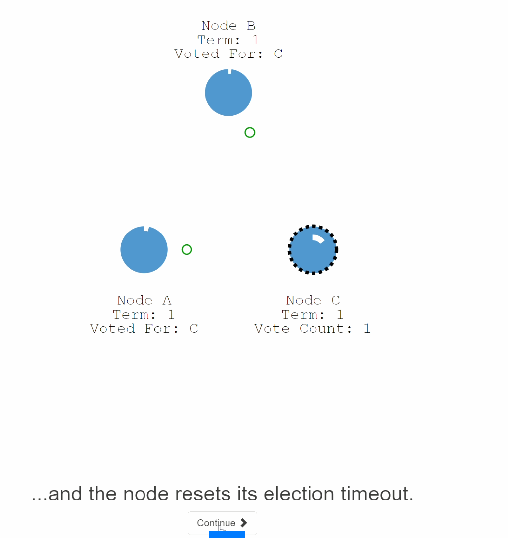

29:leader 开始向其他follower发送 追加变更记录的信息.
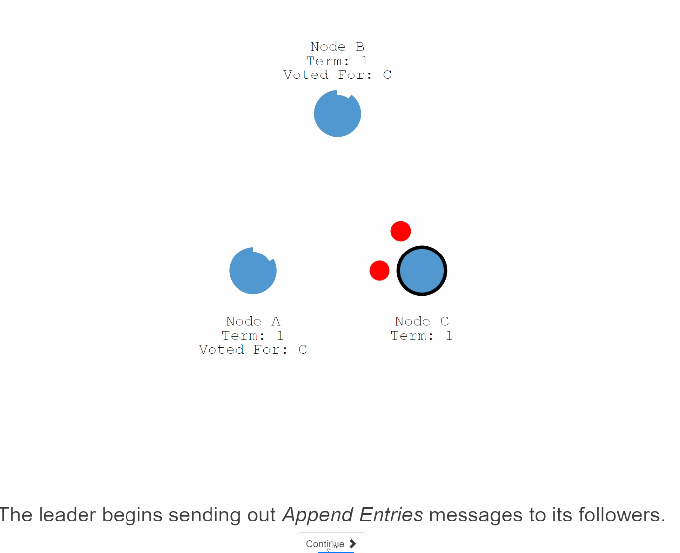
30: 这些消息按心跳超时时间作为时间间隔发送到其他节点。

31:follower们也会给每一个消息进行响应。

32:直到一个follower停止接收leader发送过来的心跳并变成candidate之后这个选举过程才算结束。注意!follower和leader通信过程中,自我选举也一直都在,只是每次收到leader的心跳之后就被重置了。
这也是后面leader挂了之后,马上开始election的原因。
33:接下来看下把lader停掉,集群是怎么重新选举的。

34:假设B 原来是leader,突然挂了,也就没法向其他follower节点发送心跳了,正如32步骤中说的那样,另外两个节点一直在进行election term,下图是A节点首先成为了candidate,然后发送投票请求给C,C响应成功,
A节点就变成了leader。
35:下面我们看下投票发生分裂的情况,当集群中投票有多个follower节点同时变成candidate。下面第二个图,A,C节点同时变成candidate,并向其他节点发送vote请求。
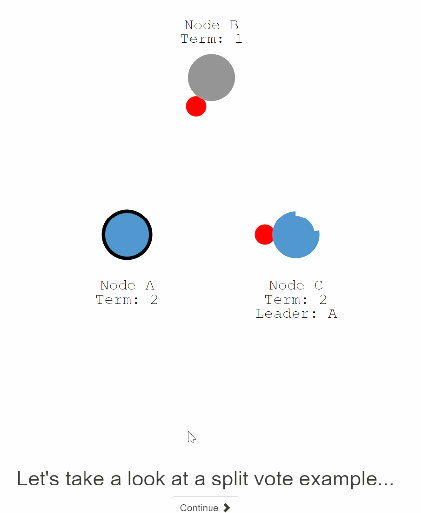

36:这两个进行election 的节点都收到了两个节点的投票。
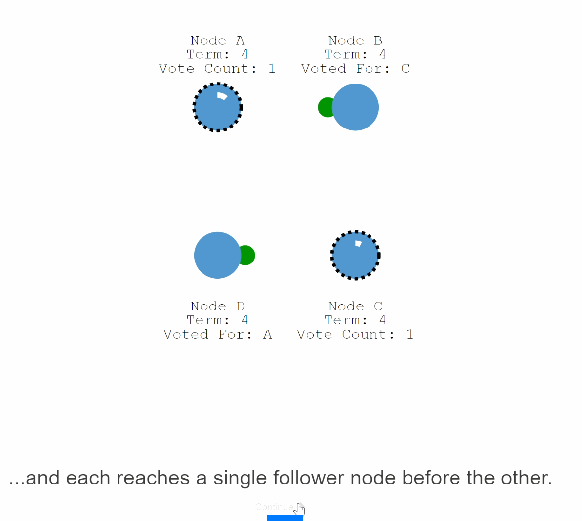

37:两个候选者得到的票数一样,开始下一个周期的投票。

等下个周期开始A,C看那个节点先发起投票。最后A得到了大多数票数。

下面详细说明下 Log Replication的过程
38:一旦选定了一个leader之后,我们需要复制所有的变更记录到系统的所有节点。
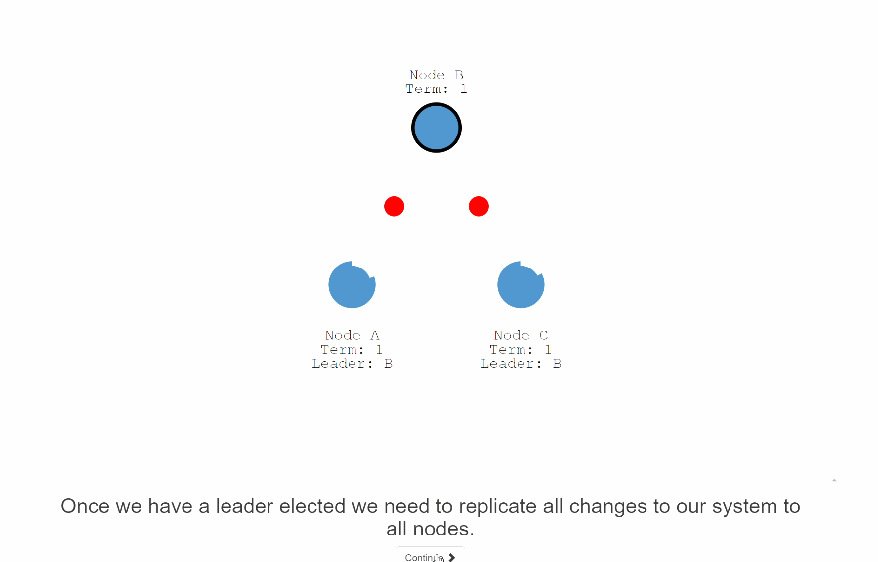
39:复制的这个过程靠leader和follower之间心跳来维持的。
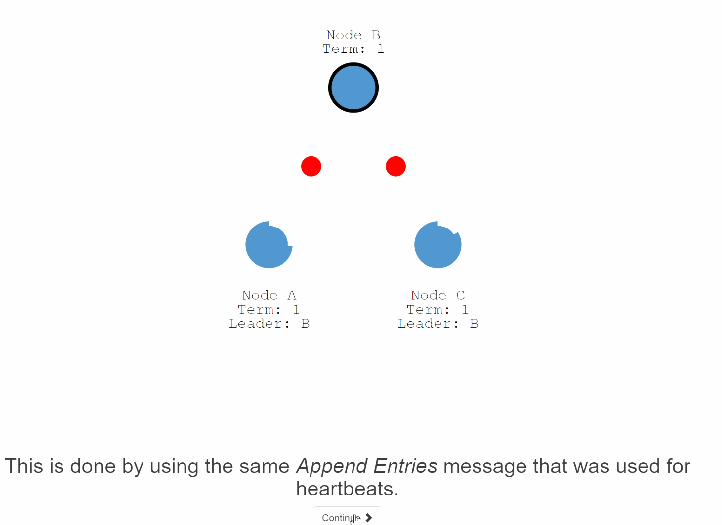
40:过程如下:
1:一个客户端过来向leadeer发送一条信息,新增了5这条数据,在leader这边先写入本地日志set 5。
2: 下次心跳的时候,leader带着这条set 5日志操作向其他follower发送请求。
3:当集群中大多数follower节点ack的时候,leader节点才将这条记录进行commit比如写入磁盘落地等。
4:响应客户端。
41:在上面的基础上增加2的过程如下。

Raft协议还可以保证在发生分区的情况下保持系统一致性。

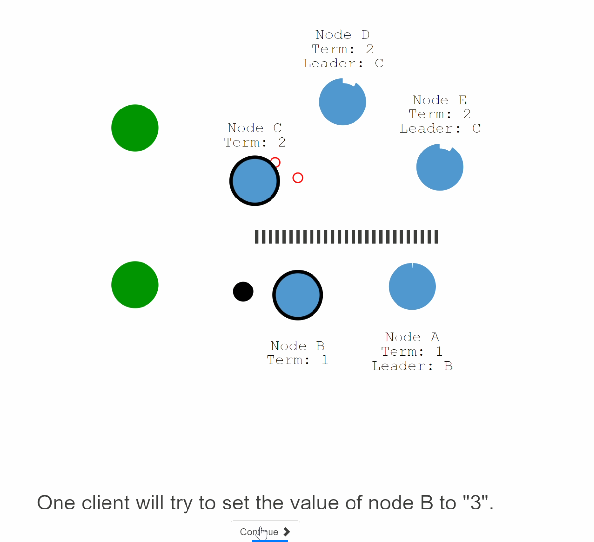
42:假设五个节点发生了分区,其中A,B是一个区的,C,D,E是一个区的

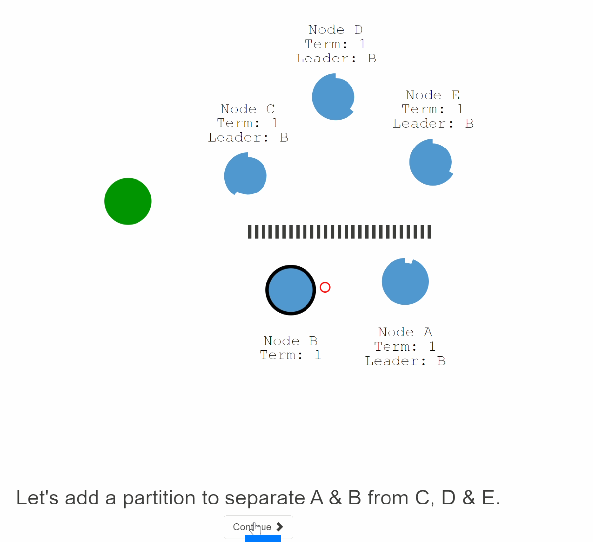
43:分区一单发生C,D,E集群就会开始election term ,假设C节点变成了第二个leader。
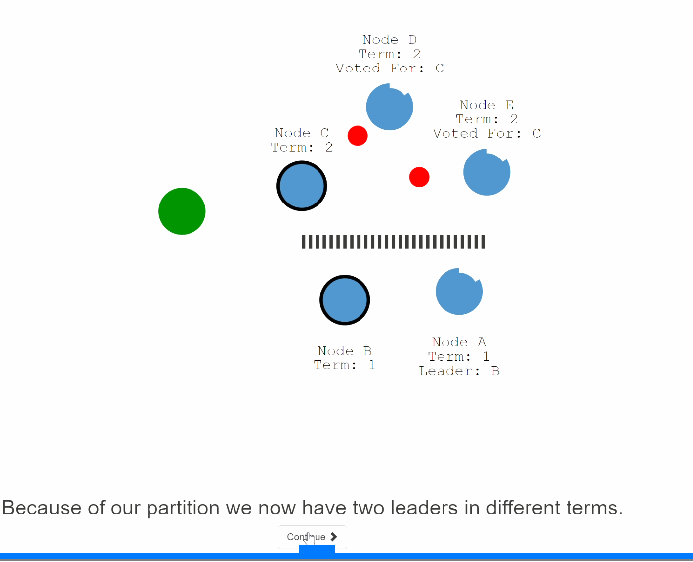
44: 假设有个客户端来请求B节点进行set 3,但是由于分区的原因B节点不能复制这条变更记录到大多数的节点,所以这条记录一直处于uncommit的状态,也不能给客户端进行响应。
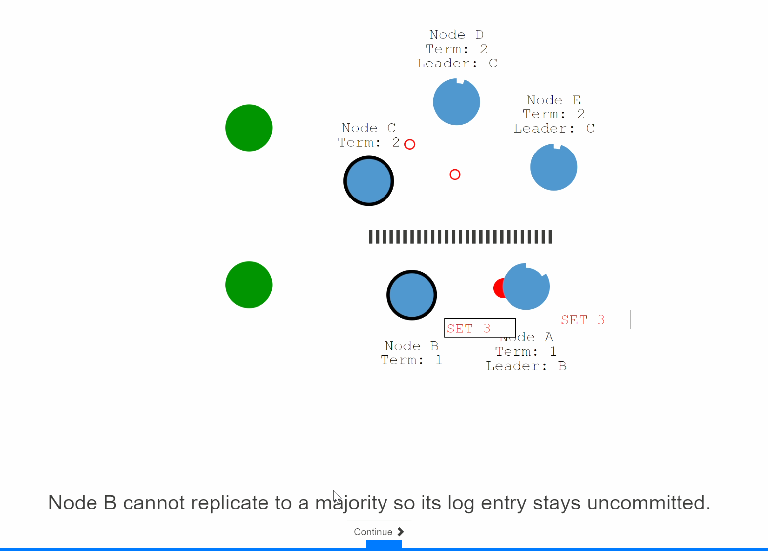
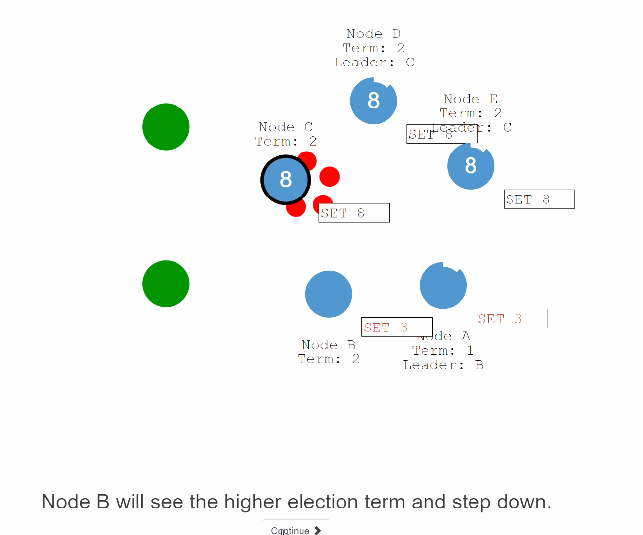
45:假设另外一个分区有一个客户端来进行连接在C节点操作set 8操作,由于C可以复制到大多数节点,所以这个set 8的操作是会成功的。

46:当分区的问题解决之后,B节点会发现比它更高级的election term 也就是C,B就会主动放弃leader成功follower。并且,A,B节点上处于uncommit的记录也会回滚掉,接收新leader发来的log。
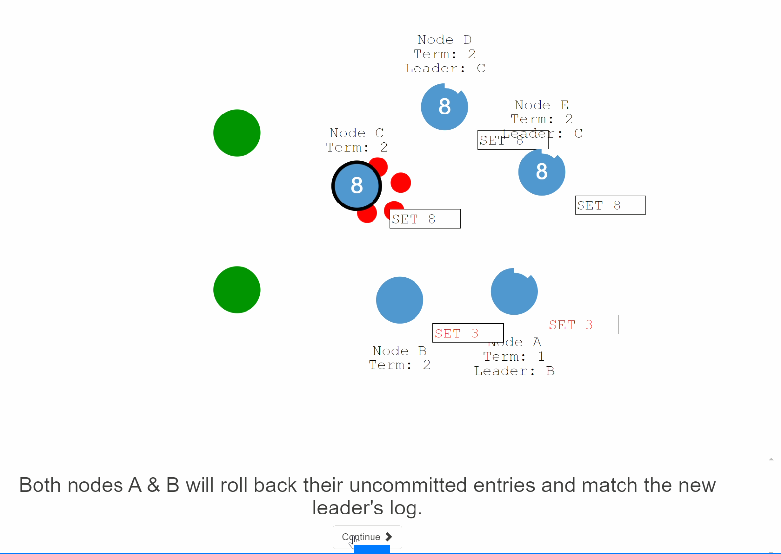

这样这个集群之间的节点也就处于一致了。
【文章原创作者:站群服务器 http://www.558idc.com/mggfzq.html 欢迎留下您的宝贵建议】