二叉查找树是二叉树这种数据结构应用的基础,了解二叉查找树的基本操作有助于进一步学习二叉树。 转载请注明出处:https://www.cnblogs.com/morningli/p/16033726.html 二叉树主要用于两种用途
转载请注明出处:https://www.cnblogs.com/morningli/p/16033726.html
二叉树主要用于两种用途,一是用来建立索引,通过索引的建立快速检索海量数据;二是用来保存信息,比如生物的遗传树等。我们程序员主要还是关注前一种用途,本文讲到的二叉查找树正是利用二叉树的特性快速查找数据的一种数据结构。
首先我们来了解一下二叉查找树的定义:
它或者是一棵空树,或者是具有下列性质的二叉树: 若它的左子树不空,则左子树上所有结点的值均小于它的根结点的值; 若它的右子树不空,则右子树上所有结点的值均大于它的根结点的值; 它的左、右子树也分别为二叉排序树。
二叉查找树又叫二叉搜索树、二叉排序树。二叉查找树作为一种经典的数据结构,它既有链表的快速插入与删除操作的特点,又有数组快速查找的优势;应用十分广泛,可用于实现动态集和查找表,例如在文件系统和数据库系统一般会采用这种数据结构进行高效率的排序与检索操作。
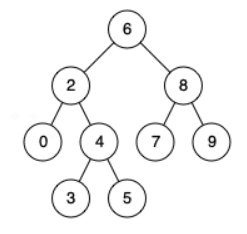
Tree-Search(x, key)
if x = NIL or key = x.key then
return x
if key < x.key then
return Tree-Search(x.left, key)
else
return Tree-Search(x.right, key)
end if
迭代搜索
Iterative-Tree-Search(x, key)
while x ≠ NIL and key ≠ x.key then
if key < x.key then
x := x.left
else
x := x.right
end if
repeat
return x
插入
1 Tree-Insert(T, z) 2 y := NIL 3 x := T.root 4 while x ≠ NIL do 5 y := x 6 if z.key < x.key then 7 x := x.left 8 else 9 x := x.right 10 end if 11 repeat 12 z.parent := y 13 if y = NIL then 14 T.root := z 15 else if z.key < y.key then 16 y.left := z 17 else 18 y.right := z 19 end if删除
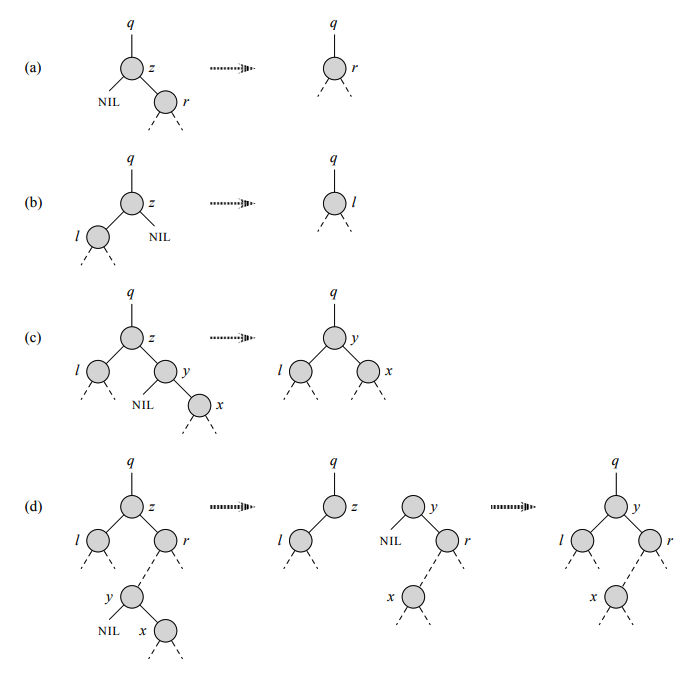
删除一个节点,比如说z, 从二叉搜索树T应遵守三种情况:
- z是叶子节点:直接删除,不影响原树。
- z仅仅有左或右子树的节点:节点删除后,将它的左子树或右子树整个移动到删除节点z的位置就可以,子承父业。见下图(a)和(b) z既有左又有右子树的节点:找到须要删除的节点z的后继y(右子树最小节点),用y的数据来替待z的数据,然后再删除节点y。
- y是z的直接右子节点,y提升到z的位置,左指针指向原来z的左子树,见下图(c)
- y不是z的直接右子节点,y的右子节点(y不可能有左子节点)取代y的位置,y取代z的位置,见下图(d)
本文主要讲二叉查找树的一些主要操作,二叉查找树的主要问题是树的形状完全跟插入删除数据的顺序有关,在一些场景下很容易就退化成了普通的链表,这也是二叉查找树的时间复杂度最差的时候会是O(n)的原因,下一篇会继续深入讲解二叉树查找树会如何退化以及如何应对,敬请期待。
引用:
https://baike.baidu.com/item/%E4%BA%8C%E5%8F%89%E6%90%9C%E7%B4%A2%E6%A0%91/7077855?fr=aladdin
https://en.wikipedia.org/wiki/Binary_search_tree