总结自《go语言设计与实现》
名词解释:-
中间代码
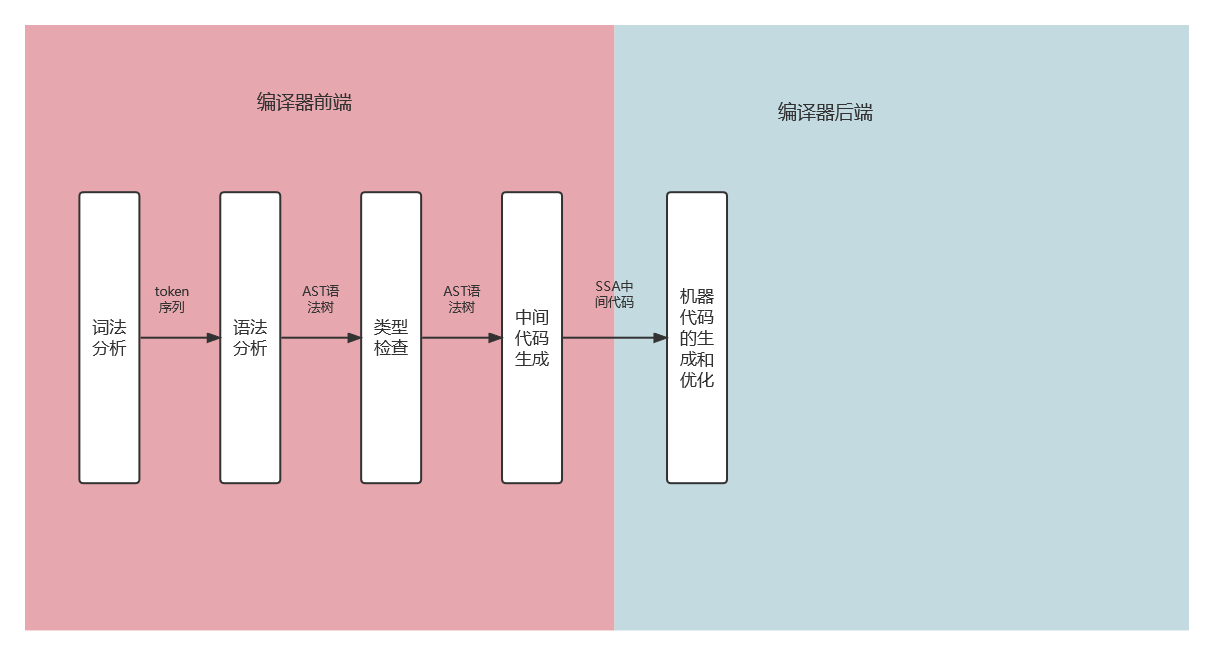
中间代码是编译器或者虚拟机使用的语言,它可以来帮助我们分析计算机程序。在编译过程中,编译器会在将源代码转换到机器码的过程中,先把源代码转换成一种中间的表示形式,即中间代码。将编程语言到机器码的过程拆成中间代码生成和机器码生成两个简单步骤可以简化该问题,中间代码是一种更接近机器语言的表示形式,对中间代码的优化和分析相比直接分析高级编程语言更容易。
-
SSA
静态单赋值是中间代码的特性,如果中间代码具有静态单赋值的特性,那么每个变量就只会被赋值一次。在实践中,我们通常会用下标实现静态单赋值,这里以下面的代码举个例子:
x := 1 x := 2 y := x经过简单的分析,我们就能够发现上述的代码第一行的赋值语句
x := 1不会起到任何作用。下面是具有 SSA 特性的中间代码,我们可以清晰地发现变量y_1和x_1是没有任何关系的,所以在机器码生成时就可以省去x := 1的赋值,通过减少需要执行的指令优化这段代码。x_1 := 1 x_2 := 2 y_1 := x_2
-
词法与语法分析
-
编译过程其实都是从解析代码的源文件开始的,词法分析的作用就是解析源代码文件,它将文件中的字符串序列转换成 Token 序列,方便后面的处理和解析,我们一般会把执行词法分析的程序称为词法解析器。
-
而语法分析的输入是词法分析器输出的 Token 序列,语法分析器会按照顺序解析 Token 序列,该过程会将词法分析生成的 Token 按照编程语言定义好的文法(Grammar)自下而上或者自上而下的规约,每一个 Go 的源代码文件最终会被归纳成一个 SourceFile 结构 。
词法分析会返回一个不包含空格、换行等字符的 Token 序列,例如:package, json, import, (, io, ), …,而语法分析会把 Token 序列转换成有意义的结构体,即语法树。
-
-
类型检查
当拿到一组文件的抽象语法树之后,Go 语言的编译器会对语法树中定义和使用的类型进行检查,类型检查会按照以下的顺序分别验证和处理不同类型的节点:
- 常量、类型和函数名及类型;
- 变量的赋值和初始化;
- 函数和闭包的主体;
- 哈希键值对的类型;
- 导入函数体;
- 外部的声明;
通过对整棵抽象语法树的遍历(也会修改语法树),我们在每个节点上都会对当前子树的类型进行验证,以保证节点不存在类型错误,所有的类型错误和不匹配都会在这一个阶段被暴露出来,其中包括:结构体对接口的实现。
类型检查阶段不止会对节点的类型进行验证,还会展开和改写一些内建的函数,例如 make 关键字在这个阶段会根据子树的结构被替换成 runtime.makeslice或者 runtime.makechan等函数。
-
中间代码生成
当我们将源文件转换成了抽象语法树、对整棵树的语法进行解析并进行类型检查之后,就可以认为当前文件中的代码不存在语法错误和类型错误的问题了,Go 语言的编译器就会将输入的抽象语法树转换成中间代码。
在类型检查之后,编译器会通过 cmd/compile/internal/gc.compileFunctions编译整个 Go 语言项目中的全部函数,这些函数会在一个编译队列中等待几个 Goroutine 的消费,并发执行的 Goroutine 会将所有函数对应的抽象语法树转换成中间代码。由于 Go 语言编译器的中间代码使用了 SSA 的特性,所以在这一阶段我们能够分析出代码中的无用变量和片段并对代码进行优化
-
机器码生成
Go 语言源代码的 src/cmd/compile/internal 目录中包含了很多机器码生成相关的包,不同类型的 CPU 分别使用了不同的包生成机器码,其中包括 amd64、arm、arm64、mips、mips64、ppc64、s390x、x86 和 wasm