之前说过七层/五层/四层的网络模型,我们从网络模型可以看出传输层(tcp/udp)开始 就是我们平常编写程序所运行的层次了。在系统层级,为了系统安全之类的考虑我们将 传输层向上 划分为用户态 将 传输层向下 划分到 内核态(暂时可以认为这么划分)

在网络交互中客户端和服务端的交互时发生了什么?
- 首先我们
应用启动运行,对外暴露一个端口(或者多个),此时调用系统``创建一个(或多个)这个端口的socket(或者说是创建一个(或多个)监听器) 客户端发起请求,此时客户端生成一个socket然后通过传输层->网络层->链路层->物理层 ->( 物理层-链路层-网络层-传输层)``服务器进行三次握手确认链接- 然后
客户端将数据按照第二部的链路顺序 在发送到 服务端 服务端从网卡->将数据(0/1)读出->内核态->用户态- 用户态处理数据,将处理后的数据再原路返回。

从上我们可以知道 客户端 和 服务端 的数据``流向。这仅仅是一台客户端的,作为服务器肯定是要有多台客户端进行通信的,如果有多个客户端同时访问此时的过程如何呢?这就引出我们今天要说的主题:IO多路复用。为了讲清楚,我们先将传统的网络io拉出来进行一步步推导。
我们在上面说过,服务端应用启动的时候会创建一个主动socket(也就是监听器),那么如果有客户端建立链接的时候被监听到,然后执行 创建一个被动socket执行服务端的代码:服务端一般就是读取数据 然后 处理数据 最后返回数据 关闭链接
但是 我们建立链接的时候 数据还没有``到达``用户态,也就是此时数据不一定传输完成了。那么我们服务端的读数据 也就被阻塞了(我们程序发起io调用,如果内核态 没有准备好,那么我们程序是在io 阶段被阻塞的,也就是我们平常说的系统卡了)。此时就引出我们第一个概念:阻塞IO



在上面我们可以看到 客户端写入流 和 服务端读入流 是有一个阻塞的阶段的(客户端可以分多次写入流,然后发送到服务端),而且这里我们要注意的是,这个流是从物理层传入的(服务端举例子,客户端是相反的),那么数据到达用户层 还是有一个 内核态 到用户态的切换(这个上下文切换是比较耗费性能的)。
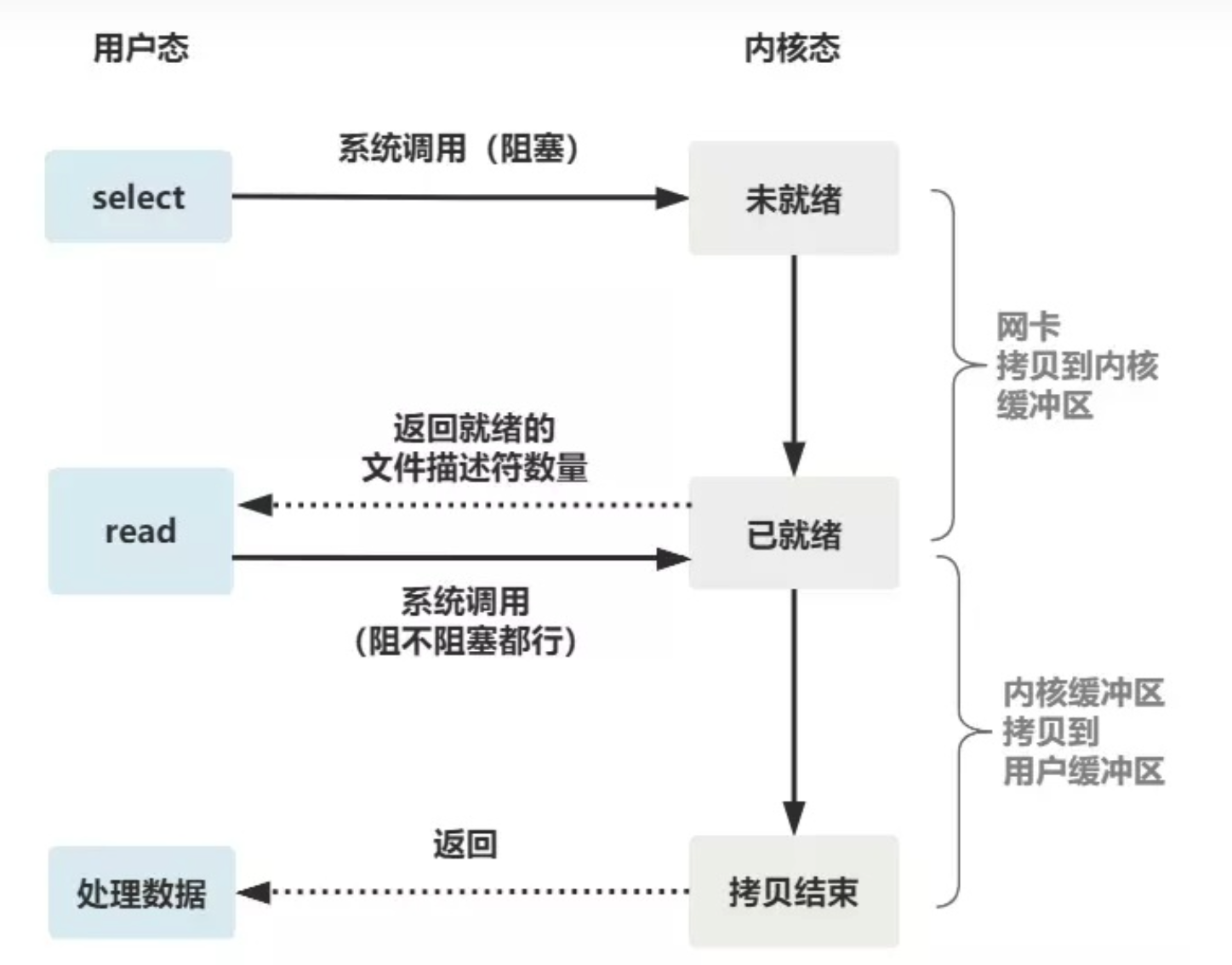
然后我们对从 底层 到 用户层的过程进行一下分析:将read (系统提供的read 函数)展开来,可以发现这个read 分成两个部分:
数据从外部流入网卡然后走到内核缓冲区,此时客户端socke文件描述符变成1,然后用户缓冲区再去读取(服务端进行读取使用)


在这个模型中,服务端处理请求是串联的。也就是说如果这个请求被阻塞了,那么剩下的请求都要被阻塞``等待``上一个请求处理完成才行。所以,我们上面说,在 服务器读数据的时候,数据还没到(数据还没读到用户态),那么服务器被阻塞,然后其他客户端的请求也不能被处理。
比如:
小明和小红两个人访问同一个服务,然后小明先点,但是数据没被处理完成,然后小红在进行发送请求,此时服务器就将小红的请求挂起,等待小明的处理完成在进行处理。
这样来说,服务器的cpu岂不是会浪费?当用户数量少的时候还可以,但是如果用户数量多来怎么行
所以我们就自己优化一下。
怎么优化,既然服务器此时还在等待数据,那么我们在开一个线程去处理另外的客户端不就ok了?
所以我们对监听和 read进行解耦合,监听到一个客户端就放进来一个客户端的请求,然后服务再启动一个线程去处理这个请求。
但是这个有两个比较突出的问题:
- 服务端需要开辟
大量的线程,这对服务端的压力是很大的 - 这个read 还是
单线程``阻塞的,我们没办法向下走啊
所以这个对于传统的io 来说还是没有解决实际的问题,想要解决只能在操作系统中(内核态)处理。而这就引出我们第二个概念:非阻塞io
二、非阻塞IO我们在看上面的read 函数,可以发现read 函数是分成两个部分进行的,那我们是不是可以将这个两个过程分开?
服务端的read 执行,然后read 直接返回-1 让 服务端 代码进行下一步操作,不用在阻塞到读取这里。

虽然系统不再阻塞服务端的读取程序了,但是服务端还是要使用这个数据啊,所以服务端还是需要有个线程不断的进行循环,以此知道数据读取完成了,所以还是有服务端创建线程的压力啊。(也就是我们还是需要自己循环这个状态;还有一点 read 读取 还是 阻塞的,我们非阻塞的只是数据预处理阶段-也就是网卡到内核缓冲区的部分,这个是同步和异步的一个重要区分点)

我们再一次发挥聪明的头脑,既然服务端为每个客户端创建一个线程是耗费创建线程的压力,那么就将每个客户端的文件描述符存储起来(数组),然后等到可以在用户态read 的时候在调用服务端的注册函数不就ok了,然后单独创建一个线程 专门用来做 遍历。这样不就减少了服务端的压力了


这是不是有点多路复用的意思?
但是我们在应用层写的read 还是要调用系统的read 方法,也就是还是需要消耗系统资源的(在 while 循环里做系统调用,就好比你做分布式项目时在 while 里做 rpc 请求一样,是不划算的)。所以我们能不能扔到系统中去?这就引出我们今天的角-io多路复用
多路复用的思想: 是 在 非阻塞 io 的基础上进行优化的,也就是对于 read 第一部分 预处理阶段 是非阻塞的。(可以理解为,我们告诉系统那些在等待,等系统处理好了 在通知 系统,我们再去调用io 读取)
此时操作系统提供了一个select 函数,我们可以通过它把一个文件描述符的数组发给操作系统, 让操作系统去遍历,确定哪个文件描述符可以读写, 然后告诉我们去处理:
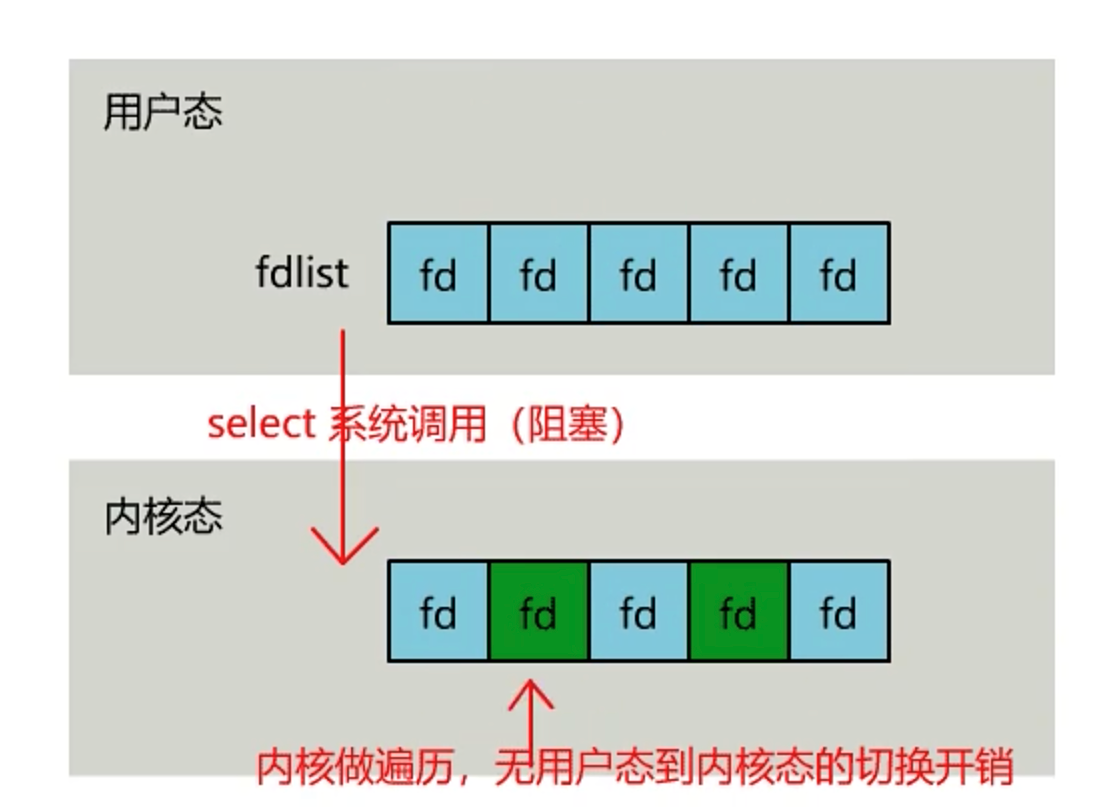
这里注意一下,虽然我们让系统遍历了,但是我们自己还是需要遍历的,只不过此时我们自己遍历的没有了系统的开销了。然后有了数据之后我们在进行调用注册函数。

但是我们知道
- 系统调用fd 数据,也就是拷贝一份到内核,高并发场景下这样的拷贝消耗的资源是惊人的。(可优化为不复制)且数组也是有限制的。
- 还有select 在内核层仍然是通过遍历的方式检查文件描述符的就绪状态,是个同步过程,只不过无系统调用切换上下文的开销。(内核层可优化为异步事件通知)
- select 仅仅返回可读文件描述符的个数,具体哪个可读还是要用户自己遍历。(可优化为只返回给用户就绪的文件描述符,无需用户做无效的遍历)
这一点我们还有一个注意的点:我们read第二步还是在阻塞的
为了解决数组的限制(这不阻碍高并发的数量么),所以它用了动态数组,也就是链表,去掉了 select 只能监听 1024 个文件描述符的限制。
epoll此时我们的终极解决方案过来了
epoll 主要就是针对这三点进行了改进。

- 内核中保存一份文件描述符集合,无需用户每次都重新传入,只需告诉内核修改的部分即可。
- 内核不再通过轮询的方式找到就绪的文件描述符,而是通过异步 IO 事件唤醒。
- 内核仅会将有 IO 事件的文件描述符返回给用户,用户也无需遍历整个文件描述符集合。
这里我们就将linux中的io 多路复用讲完了。
我们在io多路复用,到最后我们的epoll 中,可以看到,最后是内核态 将准备好的io 给到 应用层的 程序,所以我们可以进一步来进行一下优化,我们在程序层 将 数据准备 和io读取 进行分开:
也就是 在主线中调用 数据预处理 等方法,然后另写 一个方法对 预处理完成 之后的方法进行 处理。也就是在程序层我们做一个“异步” (注意 ,这里其实还是同步的,因为我们的read 第二部分还是阻塞的,也就是我们还是在等待这个read ,可以理解为:我们不在主线程等待了,对于内核态来说并不知道,认为 用户态的这段还是在一个线程中)
我们上面做了那么多, 我们在应用层做的都是想要 在内核态数据真正 读取到用户态 的时候才使用数据,所以 我们考虑一下系统 对于第二部分也进行一个非阻塞的 返回 不就ok 了。
也就是 服务端(用户态)进行一次系统调用(一次上下文切换),然后就往下进行,然后内核态 完成 用户态的 拷贝的时候在进行通知,处理。
注意一下,本章重点想要说的是 io 多路复用,其他都是用来和 多路复用进行辅助理解的。
- 阻塞io 就是 服务端 从建立链接 ->读取数据->处理数据 都是一个线程中完成,一次只处理一个;
- 我们通过 创建多线程 来解决 防止 主线程 卡主 或者其他线程等待的时间太长的问题
- 非阻塞io 出来之后,我们就可以将 监听 和 读取 在操作系统层面解 耦合,但是我们还是需要自己遍历状态
- select 函数出来之后,我们可以将数组放到用户态进行处理(还是需要自己遍历,只不过没有系统开销了)
- poll 使用动态数组来储存 描述符,解决数组长度问题(还是需要自己遍历,只不过没有系统开销了)
- epoll 不用每次都传入 描述符,然后使用红黑树 提高系统的性能,这下 我们应用层 终于不用在写遍历去处理了。
- 型号驱动io 是 程序层结偶,等待 内核台可以读取的时候,在进行io 调用
- 异步io(AIO) 是 内核态 进行解耦 ,也就是我们程序层 一次调用,然后内核态 到用户层的拷贝 完成的时候 我们的程序层的io 调用就被执行了,不用再去程序层 另外写东西执行了。

最后说一下,这些都是我自己的理解,如果内容有误,请联系告知,在此不胜感激!!!
本文的内容都是使用下面的博客进行理解自己修改的:
【https://baijiahao.baidu.com/s?id=1718409483059542510&wfr=spider&for=pc】
【https://zhuanlan.zhihu.com/p/470778284】
部分图片来源百度搜索
如有侵权请联系我删除,感谢!!!