距离DDD实践反思写完已经过去一年,期间发生了很多事情,比如换了工作,细节按下不表;新团队的技术负责人对DDD在团队里的落地很关心,问最近有没有什么进展?这就很尴尬了:之前我接手并主要负责的XXX服务在现阶段是不太适合用DDD的,自身和外部其他几个服务的边界并不清楚(其中包含了一些历史技术债),而且当前处于一个变化比较快的阶段,也没有什么业务输入,不太适合贸然重构,所以并没有在XXX服务中搞DDD。

做技术总要有点追求嘛,虽然现阶段工作最高优先级还是保证业务快速发展,还是想继续实践下DDD的。
这时正巧一个老应用要做重构,在这个基础上一个新的类目管理功能,虽然是一个新的领域,但是产品文档确定的业务规则已经非常清晰,并且后续变化不会很大。美中不足的是需求对应的功能此时已经用传统的CRUD的方式写完了大半了,纠结了半天,还是决定:搞!

本文对于DDD的基础术语就不再单独讲解了,下面直接进入正题。
原则问题关于DDD,我一年前观点基本没有变化,这里再总结归纳一下。要先确定是否满足以下条件,再考虑是不是要用DDD,不要为了DDD而DDD。永远记住:没有银弹!

实践时,你就会发现DDD在项目落地时做了很多折中,不能教条化地照搬。
- 业务规则要有一定的复杂性和稳定性。如果一个业务通过CRUD就能轻易的搞定且以后也不会变得很复杂,或者业务还一直在快速变化(这也意味着经常有很强的的项目时间节点要求和临时性的规则),不要用DDD。
- 域的划分是清晰的,建模是准确的,领域方法是可以梳理的且足够丰富的,是考虑使用DDD先决条件。域的划分不等于将一个应用强行拆成很多个应用,人为地提升系统复杂性。
- 不要带来过多的额外成本,不要舍本逐末。如果因为DDD导致一个应用的开发、测试、运维成本翻倍,甚至引入了更多的bug,那么就要反思下这次实践是否成功了。
这里概括一下需求要点,已刨除掉需求具体的背景以及和本文无关的其他项目需求内容。
本次需要实现一个管理如下图的类目树结构的功能:
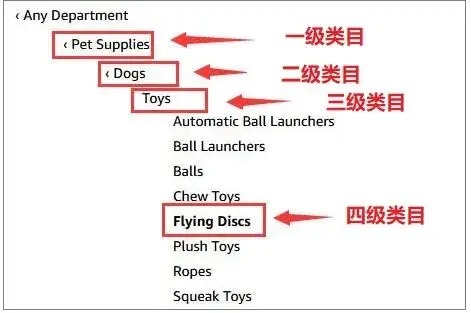
(图源:https://t.cj.sina.com.cn/articles/view/7321552158/1b466051e001010bfc)
具体的规则和支持的操作:
- 类目节点组织成一棵或多颗树,每个类目节点下可以有一个或多个子类目节点
1.1 子类目节点是有序的,可以进行重排序
1.2 最顶层的类目节点是根
1.3 类目节点上可以关联多个同种类型的内容实体 - 类目节点可以新增、删除、重命名、上架、下架
2.1 上架和下架是类目节点的状态。如果类目节点下没有关联内容,或者它其下没有上架的子类目节点,无法上架。
2.1 删除节点时,其下的子节点和子节点关联的内容需要一并删除
象征性地画一下限界上下文和ER图,因为隐藏了很多细节所以看上去很简单。ER图里并没有聚合根,要问为什么请继续往后看。
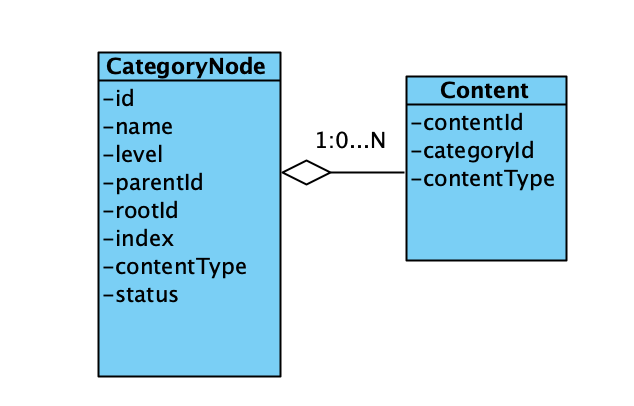
DDD只在脑中有概念是不够的,为了将概念转化为代码,第一步就是把这些概念变成代码,这样才能指导后续的编写。

实际上,这就可以看做是折中的开始了,因为DDD本身是不关心具体存储的,但是做模型设计,你必须考虑如何持久化。
本文中为了实现类目树本身并不会用到继承以下值对象的类,为了完整性考虑才写出来的。
点击查看代码
/**
* 值对象抽象类
*
*/
public abstract class ValueObject {
}
/**
* 字段型值对象
*
* 表示这个值对象会使用表字段来存储。
*
* 并不总是表示一个单一的字段, 可能是多个字段组合而成。
*
* 你可以把枚举也看做值对象,但enum是没法继承这个类的。
*/
public abstract class FieldValueObject extends ValueObject {
}
/**
* 对象关系映射型值对象
*
* 表示这个值对象会使用关系数据库映射的方式来存储。
* 这里没有使用id,需要视情况而定
*/
public abstract class OrmValueObject extends ValueObject {
/**
* 创建时间
*/
protected Date created;
/**
* 更新时间
*/
protected Date lastModified;
}
点击查看代码
/**
* 实体抽象类
* 封装了所有实体的通用属性
*/
public abstract class Entity {
/**
* id
*/
protected Long id;
/**
* 创建时间
*/
protected Date created;
/**
* 更新时间
*/
protected Date lastModified;
/**
* 是否逻辑删除
*/
protected Boolean deleted;
}
除了实体本身的属性,空的。
点击查看代码
/**
* 聚合根
*/
public abstract class Aggregate extends Entity{
}
话说大了,其实这节列出来的都快成失血模型了。充血模型在哪里?等到下面一节就有了,先看看这些贫血模型提升下血压吧:

点击查看代码
/**
* 内容类目节点
*
*/
public class Category extends Entity {
/**
* 名称
*/
private String name;
/**
* 层级, 0表示根
*/
private Integer level;
/**
* 父节点id, 如果不存在则为0
*/
private Long parentId;
/**
* 根节点id, 如果是根节点则是它本身
*/
private Long rootId;
/**
* 内容类型
*/
private ContentTypeEnum contentType;
/**
* 节点状态
* 0-下架,1上架
*/
private CategoryStatusEnum status;
/**
* 节点顺序, 有小到大递增
*/
private Integer index;
/**
* 节点路径, 不含它自己
* 用于冗余
*/
private List<Long> path;
public boolean isOff() {
return status!=null && StringUtils.equals(status.getCode(), CategoryStatusEnum.OFF.getCode());
}
public boolean isOn() {
return status!=null && StringUtils.equals(status.getCode(), CategoryStatusEnum.ON.getCode());
}
}
/**
* 类目节点上的内容
*
*/
public class Content extends Entity {
/**
* 所属的类目id
*/
private Long categoryId;
/**
* 所属类目节点的根id, 用于冗余查询
*/
private Long rootId;
/**
* 内容id
*/
private String contentId;
/**
* 内容类型
*/
private ContentTypeEnum contentType;
/**
* 内容在类目树上的路径(id),,用于冗余查询
*/
private List<Long> path;
}
CRUD也可以用Repository,你也可以把Repository用Tunnel代替,这里还是使用Repository来表示将持久化的对象加载到内存中、将内存对象持久化的服务。
Repository与直接调用mybatis提供的mapper/DAO不同点:
- 可以包含业务逻辑、事务,本身会成为领域服务的一部分;
- 需要将DO转化为Model,不能直接把DO给外部使用。
在本次需求里,Repository具体提供了哪些方法就不列举了,可以看下面一个方法,它通过事务绑定了两个动作,保证新建的根节点的rootId字段是它自己创建时生成的主键。
点击查看代码
@Repository
public class CategoryRepository {
@Resource
private CategoryDAO categoryDAO;
// 其他方法略
/**
* 创建根节点
*/
@Transactional(rollbackFor = Exception.class)
public long addRoot(Category category) {
CategoryDO categoryDO = CategoryConverter.toDO(category);
categoryDAO.insert(categoryDO);
categoryDAO.updateRootId(categoryDO.getId());
category.setId(categoryDO.getId());
return categoryDO.getId();
}
}
直到这里,除了看似玄虚的建模抽象类,几乎和CRUD没什么区别对不对?

重点来了:聚合根!
先抽象出聚合根,再将领域方法合理地抽象到聚合根,DDD才算是开始落地。再回顾一下【需求分析】这一节,所有的操作都是和节点有关的,但是单个节点不能支持所有的操作,比如子节点排序,是包含了一个节点下所有的子节点的操作。那么,将一棵类目树作为聚合根,所有对节点的操作都抽象为 对一棵树上某个节点及关联节点的操作,是不是就把操作本身和聚合根联系到了一起呢?
点击查看代码
/**
* 类目树 - 聚合根
* 领域对象(树)的领域方法, 本身包含了操作节点的持久化管理, 即所有操作需要满足:
* 对树及树的节点的操作, 内存中的对象必须和持久化的保持一致, 如果进行持久化, 内存中存在的也需要进行更新, 反之亦然
*
* 使用树进行操作, 需要注意不要在同一个流程中对同一个对象混用树和repository进行操作, 否则会发生数据不一致
*
*/
public class CategoryTree extends Aggregate {
/**
* 类目树的根节点id
*/
final private long rootId;
/**
* 类目节点缓存
* 可能不是全部的节点都会缓存
* key: 节点id
* value: 节点
*/
final private Map<Long, Category> nodeMap = Maps.newHashMap();
/**
* 节点仓储
*/
final private CategoryRepository categoryRepository;
/**
* 节点内容仓储
*/
final private ContentRepository contentRepository;
/**
* 节点并发锁
*/
final private RedisLock redisLock;
/**
* 初始化, 数据懒加载
*
* @param rootId
* @param categoryRepository
* @param classifiedContentRepository
* @param redisLock
*/
public categoryTree(Long rootId, categoryRepository categoryRepository,
ContentRepository contentRepository, RedisLock redisLock) {
this.rootId = rootId;
this.deleted = false;
this.categoryRepository = categoryRepository;
this.contentRepository = contentRepository;
this.redisLock = redisLock;
}
// 领域方法, 见下文
... ...
}
你会发现,如果想要在聚合根实现领域方法,因为会涉及持久化,聚合根一定是和Repository绑定在一起的。那么,聚合根很自然的变成了充血模型。
虽然聚合根是类目树的根节点,我不推荐将所有这课类目树的所有节点都加在到内存中,而是在每次操作时按需加载,操作完直接持久化,否则你会面对着无休止的数据一致性的纠结。
领域服务的前戏——工厂类聚合根里包含了Repository、Redis并发锁,总不能每次new的时候都手动注入一次吧?

如果不用new来创建对象,很自然的可以想到用工厂类来做这些脏活累活。
点击查看代码
@Service
public class CategoryTreeFactory {
@Resource
private CategoryRepository categoryRepository;
@Resource
private ContentRepository contentRepository;
@Resource
private RedisLock redisLock;
/**
* 通过根构造(加载)树
* @param rootId
* @return
*/
public ContentCategoryTree build(long rootId) {
ContentCategory root = categoryRepository.loadOne(rootId);
if(root == null) {
throw new RuntimeException("根节点不存在");
}
if(root.getRootId() != rootId) {
throw new RuntimeException("rootId对应的节点不是根节点");
}
return new CategoryTree(rootId, categoryRepository, contentRepository, redisLock);
}
/**
* 通过节点构造(加载)类目树
*
* @param categoryId
* @return
*/
public CategoryTree buildByNode(long categoryId) {
Category category = categoryRepository.loadOne(categoryId);
if(category == null) {
throw new RuntimeException("类目节点不存在");
}
return build(category.getRootId());
}
/**
* 创建一个只有根的新树
* @param name
* @param contentType
* @return
*/
public CategoryTree buildNewTree(String name, ContentTypeEnum contentType) {
int index = 1;
Set<String> rootNameSet = Sets.newHashSet();
List<ContentCategory> roots = contentCategoryRepository.loadRoots();
if(!CollectionUtils.isEmpty(roots)) {
// 获得新的根节点的顺序
index = roots.get(roots.size()-1).getIndex() + 1;
roots.forEach(p->rootNameSet.add(p.getName()));
}
// 以后改成按类型名称排序
if(rootNameSet.contains(name)) {
throw new RuntimeException("根节点名称重复");
}
Category root = new Category();
root.setName(name);
root.setStatus(CategoryStatusEnum.OFF);
root.setContentType(contentType);
root.setIndex(index);
// 临时设置一个id,规避持久化问题
root.setRootId(CategoryConstant.ROOT_PARENT_ID);
root.setParentId(CategoryConstant.ROOT_PARENT_ID);
root.setLevel(CategoryConstant.ROOT_LEVEL);
root.setDeleted(false);
long rootId = categoryRepository.addRoot(root);
return build(rootId);
}
}
接下来,就要在聚合根充实领域服务了,这一步是和抽象聚合根是紧密结合在一起的。
模板方法这里先铺垫一下,为了提高代码的复用性,需要因地制宜的抽一下模板方法。在本例中,有两种:
- 只操作单个节点
- 自下而上操作每个节点
后续也有可能自下而上操作的,实现起来和自下而上操作类似。
先看下适用于不同场景的两个方法接口。
点击查看代码
/**
* 类目操作方法接口
* 只适用于单个节点
*
*/
public interface CategorySingleOperation<R> {
/**
* 方法接口
* @return
*/
R process();
}
/**
- 类目操作方法接口
- 适用于遍历时的节点
/
public interface CategoryTraverseOperation {
/*
* 方法接口
* @return
*/
void process(Long categoryNodeId);
}
再看下两种场景对应的模板方法,它们把一些通用操作封装了一下。自下而上的操作时,使用了堆栈和对列。
点击查看代码
/**
* 对一个节点进行操作模板方法
* @param func 具体的操作
* @param nodeId 节点id
* @param withLock 是否加互斥锁
* @param <R>
* @return
*/
private <R> R executeForOneNode(Long nodeId, boolean withLock, CategorySingleOperation<R> func) {
Category node = nodeMap.get(nodeId);
if(node == null) {
node = categoryRepository.loadOne(nodeId);
nodeMap.put(nodeId, node);
}
if(node == null) {
throw new RuntimeException("待处理的节点不存在");
}
if(withLock) {
if(!redisLock.acquire(buildLockKey(nodeId), SystemConstants.CATEGORY_LOCK_TIME)) {
throw new RuntimeException("并发锁获取失败");
}
R r = func.process();
redisLock.release(buildLockKey(nodeId));
return r;
} else {
return func.process();
}
}
/**
* 从一个节点开始, 自上而下逐层进行操作模板方法
* @param func 具体的操作
* @param nodeId 节点id
* @param withLock 是否加互斥锁
* @return
*/
private void executeForDownUpByLevel(Long nodeId, boolean withLock, CategoryTraverseOperation func) {
Category node = loadOne(nodeId);
if(node == null) {
throw new MeiJianException(PbdErrorCodeEnum.NO_DATA.getCode(), "节点不存在!");
}
// 按层组装节点
LinkedList<Category> queueForTraverse = Lists.newLinkedList();
LinkedList<Long> stackForHandle = Lists.newLinkedList();
queueForTraverse.offer(node);
while(!queueForTraverse.isEmpty()) {
Category currentNode = queueForTraverse.poll();
stackForHandle.push(currentNode.getId());
List<Category> children = categoryRepository.loadByParentId(currentNode.getId());
if(!CollectionUtils.isEmpty(children)) {
children.forEach(queueForTraverse::offer);
}
}
// 自底向上处理
while(!stackForHandle.isEmpty()) {
Long currentCategoryId = stackForHandle.pop();
if(withLock) {
if(!redisLock.acquire(buildLockKey(nodeId), SystemConstants.CATEGORY_LOCK_TIME)) {
throw new RuntimeException("并发锁获取失败");
}
func.process(currentCategoryId);
redisLock.release(buildLockKey(nodeId));
} else {
func.process(currentCategoryId);
}
}
}
终于到这里了。前面经过噼里啪啦一顿抽象,领域方法写起来已经很简单了,下面举几个例子,分别展示单个节点操作和自底向上操作一个节点下的所有节点的写法。
实际上不止这几个方法,通过模板方法省掉了大量重复代码,看上去也干净整洁很多,这里就不一一列举了。
点击查看代码
/**
* 增加类目节点, 序号为父节点下最大值
* @param parentId
* @param name
* @param contentType
* @return
*/
public Long addContentCategory(Long parentId, String name, ContentTypeEnum contentType) {
return executeForOneNode(parentId, true, () -> {
int index = 0;
Category parent = loadOne(parentId);
List<Category> children = categoryRepository.loadByParentId(parent.getId());
if(!CollectionUtils.isEmpty(children)) {
for(Category child: children) {
if(child.getIndex() > index) {
index = child.getIndex();
}
}
}
index++;
return categoryRepository.add(buildCategory(name, contentType, parent, index));
});
}
/**
* 删除节点及节点上的内容
* 为了防止脏数据, 从底向上删
*
* @param categoryId
*/
public void deleteNodes(Long categoryId) {
executeForDownUpByLevel(categoryId, false, currentCategoryId-> {
contentRepository.deleteByCategoryId(currentCategoryId);
categoryRepository.delete(currentCategoryId);
});
}
面对一部分需求里的内容,你会发现CQRS有时并不是要故意搞什么高大上的概念,而是不得已而为之......只靠领域服务臣妾做不到啊