论文地址:https://arxiv.53yu.com/abs/2106.07577
基于 F-T-LSTM 复杂网络的联合声学回声消除和语音增强 摘要随着对音频通信和在线会议的需求日益增加,在包括噪声、混响和非线性失真在内的复杂声学场景下,确保声学回声消除(AEC)的鲁棒性已成为首要问题。尽管已经有一些传统的方法考虑了非线性失真,但它们对于回声抑制仍然效率低下,并且在存在噪声时性能会有所衰减。在本文中,我们提出了一种使用复杂神经网络的实时 AEC 方法,以更好地建模重要的相位信息和频率时间 LSTM (F-T-LSTM),它扫描频率和时间轴,以实现更好的时间建模。此外,我们利用修改后的 SI-SNR 作为损失函数,使模型具有更好的回声消除和噪声抑制 (NS) 性能。仅使用 140 万个参数,所提出的方法在平均意见得分 (MOS) 方面优于 AEC challenge 基线 0.27。
关键字:回声消除、复杂网络、非线性失真、噪声抑制;
1 引言回声是在全双工语音通信系统中产生的,由于近端扬声器和麦克风之间的声学耦合,远端用户接收到他/她自己的语音的修改版本。回声消除 (AEC) 旨在消除麦克风信号中的回声,同时最大限度地减少近端说话者语音的失真。传统的基于数字信号处理 (DSP) 的 AEC 通过使用自适应滤波器 [1, 2, 3] 估计声学回声路径来工作。但在实际应用中,由于回波路径变化、背景噪声和非线性失真等问题,它们的性能可能会严重下降。背景噪声在真正的全双工语音通信系统中是不可避免的。然而,传统的语音增强方法与 AEC [4] 相结合,对这种干扰尤其是非平稳噪声的鲁棒性不够。非线性失真通常由低质量的扬声器、功率过大的放大器和设计不佳的外壳引起;即使是适度的非线性失真也会显着降低线性 AEC 模型的性能 [5]。一般来说,后置滤波方法 [6, 7, 8] 被进一步用于传统的 AEC,但这些方法对于回声抑制仍然效率低下。
由于其强大的非线性建模能力,深度学习的最新进展在声学回声消除方面显示出巨大的潜力。有一些方法将传统的信号处理与神经网络相结合来处理 AEC 任务。Ma等人[9] 使用自适应滤波器处理线性回声以及用于残余非线性回声消除的轻量级 LSTM 结构。Fazel等人 [10] 设计了一个具有频域 NLMS 的深度上下文注意模块,以自适应地估计近端语音的特征。Wang等人[11] 和 Valin 等人[12] 在最近的 AEC 挑战中也取得了有竞争力的结果 [13]。 Zhang 和 Wang [14] 将 AEC 表述为一个有监督的语音分离问题,其中采用双向长短期记忆 (BLSTM) 网络来预测麦克风信号幅度的掩码。此后,许多基于语音增强/分离网络的AEC算法被提出。韦斯特豪森等人。 [15] 通过将远端信号连接为附加信息来扩展 DTLN [16]。Chen等人[17] 在 ConvTasNet [18] 的修改的基础上,提出了一种带有卷积网络的残余回波抑制 (RES) 方法,Kim 等人[19] 提出了一种基于 Wave-U-Net [20] 的辅助编码器和注意力网络,以有效抑制回声。
最近在语音增强方面的研究 [21, 22] 显示了使用复杂网络的显著优势,该网络同时处理幅度和相位,从而在语音增强方面取得卓越的性能。与实值网络相比,复杂网络甚至可以以更小的参数[22]获得更好的性能。优异的性能主要归功于相位信息的有效利用。此外,基于复杂领域的方法在深度噪声抑制(DNS)挑战中取得了整体更好的主观聆听性能[13]。
在本文中,受复杂网络最新进展的启发,我们通过采用复杂的编码器-解码器结构化网络来解决 AEC 任务。据我们所知,这是第一个在 AEC 任务中采用复杂网络的工作。具体来说,我们分别使用复杂的 Conv2d 层和复杂的 Transposed-Conv2d 层作为编码器和解码器来模拟来自远端和近端信号的复杂频谱,并使用复杂的 LSTM 层作为掩码估计模块。受 F-T-LSTM [23] 的启发,我们在编码器提取的高维特征的频率轴上执行递归。频率轴上的双向 F-LSTM 可以让网络更好地学习频段之间的关系,随后的 T-LSTM 扫描时间轴,旨在进一步去除回波信号。我们还采用分段的 Si-SNR 作为我们网络的损失函数。仅使用 1.4M 参数,所提出的方法在平均意见得分 (MOS) 方面优于 AEC 挑战基线 0.27。
2 提出方法 2.1 问题表述我们在图 1 中说明了声学回声消除的信号模型。麦克风信号 \(y(n)\) 由近端语音 \(s(n)\)、声学回声 \(d(n)\) 和背景噪声 \(v(n)\) 组成:
\[y(n)=s(n)+d(n)+v(n) (1) \]其中 \(n\) 是指时间样本索引。 $d(n) $ 是由远端信号 $x(n) $ 得到的,如图 1 所示,它也可能有扬声器引起的非线性失真。 $h(n) $ 表示声学回声路径。声学回声消除任务是在 $x(n) $ 已知的前提下,将$s(n) $ 与 $y(n) $ 分开。
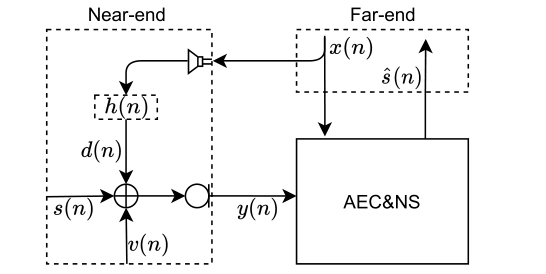
图 1:声学回声场景图。
如图 2 所示,我们的深度复杂 AEC 网络由三个模块组成:复杂编码器-解码器网络、F-TLSTM 和复杂 LSTM。

图 2:提出的网络系统流程图。
(A) 红色虚线区域显示 \(y(n)\) 和 \(x(n)\) 之间的时间延迟。
(B) F-T-LSTM-real 和 F-T-LSTM-imag 分别用于对高维复杂特征的实部和虚部进行建模。 (C) \(y(n)\) 和 \(x(n)\) 分别通过 STFT 转换为 \(Y\) 、 \(X\) 。估计的信号\(\hat{s}(n)\)是通过逆STFT 重构的。
对于顺序输入\(w \in \mathbb{R}^{2 \times N}\),其中\(N\)是音频采样点的数量,2 表示两个信号——\(y(n)\) 与 \(x(n)\) 堆叠。对输入信号 \(w\) 进行 STFT,我们得到复谱\(W=W_{r}+j W_{i}, W \in \mathbb{R}^{4 \times T \times F}\) ,其中输入复矩阵\(W_{r}\)和\(W_{i}\)分别表示具有相同张量维度\(\mathbb{R}^{2 \times T \times F}\)的 \(W\) 的实部和虚部。 \(T\) 表示帧数,\(F\) 表示 STFT 之后的频率维度。复卷积/反卷积滤波器 \(K\) 定义为 \(K=K_{r}+j K_{i}\),其中实值矩阵 \(K_{r}\)和\(K_{i}\)分别代表复核的实部和虚部。复运算\(W \circledast K\)定义为:
\[ H=\left(K_{r} * W_{r}-K_{i} * W_{i}\right)+j\left(K_{r} * W_{i}+K_{i} * W_{r}\right) \]\[ H=H_{r}+j H_{i}, H \in \mathbb{R}^{C \times M \times T}, H_{r} \text { and } H_{i} \in \mathbb{R}^{C \times N \times T} (2) \]\(C\)表示输出通道,\(M\)表示卷积/反卷积后的频率维度变化,\(N=M / 2\)。
实频谱的 F-T-LSTM 模块可以描述如下(虚频谱相同):
\[ \text { F-LSTM: }\left\{\begin{array}{l} U=\left[f\left(H_{r}^{\text {reshape }}[:, i,:]\right), i=1, \ldots, M\right] \\ V=H_{r}+U^{\text {reshape }} \end{array}\right. \]\[ \text { T-LSTM: }\left\{\begin{array}{l} Z=\left[h\left(V^{\text {reshape }}[:, i,:]\right), i=1, \ldots, T\right] \\ Z_{\text {out }}=V+Z^{\text {reshape }} \end{array}\right. (3) \]其中,\(H_{T}^{\text {reshape }}\)和\(U \in \mathbb{R}^{T \times N \times C}\)。\(U^{\text {reshape }}, Z^{\text {reshape }}, V\)和\(Z_{\text {out }} \in \mathbb{R}^{C \times N \times T}\)。\(V^{\text {reshape }}\) 和 \(Z \in \mathbb{R}^{N \times T \times C}\)。\(f(\cdot)\) 是 F-LSTM 定义的映射函数,它始终是双向 LSTM,应用于\(H_{r}^{\text {reshape }}\)的频率维度。\(h(\cdot)\)是T-LSTM定义的映射函数,扫描时间轴。复杂解码器之后是具有前瞻一帧的 Deepfilter[24],最后使用 [22] 中定义的 2 个复杂 LSTM 层来估计 $y(n) $ 的复杂掩码。
我们的模型配置的详细描述如表 1 所示。复杂的 Conv2d/Transpose-Conv2d 层的超参数以(内核大小、步幅、输出通道)格式给出。我们在每个 LSTM 之后省略了 Dense 层,它使维度与输入张量保持一致。
表 1:我们提出的方法的配置。
c-代表complex的缩写。 ×2 表示复核的实部和虚部。
 2.3 训练目标
2.3 训练目标
我们估计通过信号近似 (SA) 优化的复比率掩码 (CRM) [25]。 CRM可以定义为:
\[ \mathrm{CRM}=\frac{Y_{r} S_{r}+Y_{i} S_{i}}{Y_{r}^{2}+Y_{i}^{2}}+j \frac{Y_{r} S_{i}-Y_{i} S_{r}}{Y_{r}^{2}+Y_{i}^{2}} (4) \]其中 \(Y\) 和 \(S\) 分别表示 STFT 之后的 \(y(n)\) 和 \(s(n)\)。网络的最终预测掩码\(M=M_{r}+j M_{i}\)也可以用极坐标表示:
\[ \left\{\begin{array}{l} M_{\text {mag }}=\sqrt{M_{r}^{2}+M_{i}^{2}} \\ M_{\text {phase }}=\arctan 2\left(M_{i}, M_{r}\right) \end{array}\right. (5) \]估计的干净语音\(\hat{S}\)可以计算如下:
\[ S=Y_{\text {mag }} \cdot M_{\text {mag }} \cdot e^{Y_{\text {phase }}+M_{\text {phase }}} (6) \]2.4 损失函数损失函数基于 SI-SNR [26],它已被广泛用作评估指标。分段 SI-SNR (Seg-SiSNR) 不是计算整个话语的平均 SI-SNR 损失,而是将话语分割成不同的块,以便区分句子中单说话和双说话的情况。我们的实验证明 Seg-SiSNR 在 AEC 任务中比 SI-SNR 效果更好。 Seg-SiSNR 定义为:
\[ \begin{cases}s_{\text {target }} & :=(<\hat{s}, s>\cdot s) /\|s\|_{2}^{2} \\ e_{\text {noise }} & :=\hat{s}-s \\ \text { SI-SNR } & :=10 \log 10\left(\frac{\left\|s_{\text {target }}\right\|_{2}^{2}}{\left\|e_{\text {noise }}\right\|_{2}^{2}}\right) \\ \text { Seg-SiSNR } & :=\frac{1}{c} \sum_{i=1}^{c} \operatorname{SI-SNR}\left(\hat{s}_{\text {seg } i}, s_{\text {seg } i}\right)\end{cases} (7) \]其中\(s\)和\(\hat{S}\)分别是干净的和估计的时域波形。\(<\cdot, \cdot>\)表示两个向量之间的点积,\(\|\cdot\|_{2}\)是欧几里得范数(L2范数)。 \(c\) 表示从 \(s\)和 \(\hat{s}\)中划分出的块数。 \(*_{\operatorname{seg} i}\)表示第 \(i\) 个语音片段。我们计算 c = 1、10、20 的 Seg-SiSNR 损失,并将它们加在一起作为最终的损失函数。
3 实验 3.1 数据集我们对 AEC 挑战数据 [13] 进行了实验,以验证所提出的方法。为了训练网络,需要准备四种类型的信号:近端语音、背景噪声、远端语音和相应的回声信号。
对于近端语音 $s(n) $,官方合成数据集包含 10,000 个话语,我们选择前 500 个话语作为不参与训练的测试集。其余 9,500 个话语,以及从 LibriSpeech [27] train-clean-100 子集中随机选择的 20,000 个话语(约 70 小时)用于训练。
对于背景噪声 $v(n) $,我们从 DNS [28] 数据(大约 80 小时)中随机选择噪声,其中 20,000 个用于生成测试集,其余用于训练。
对于远端语音\(x(n)\)和回声信号\(d(n)\),与近端情况类似,使用官方合成数据集的前500句作为测试集。此外,我们使用AEC挑战赛提供的真实远端单人通话录音(约37小时),涵盖多种语音设备和回声信号延迟。
为了与另一种具有可重复代码的竞争方法——DTLN-AEC [15] 进行公平比较,我们还将 AEC 挑战 2020 中的数据仅用于训练和测试。为了区分不同数据上的结果,我们使用后缀 *-20 和 *-21 来分别区分 AEC challenge 2020 和 2021 中使用的数据集。
3.2 数据增强在线数据生成。我们在训练前准备近端语音\(s(n)\)、背景噪声\(v(n)\)、远端语音\(x(n)\)和回声信号\(d(n)\),并根据随机选择的信号对这四个信号进行组合噪声比 (SNR)、信号回波比 (SER) 或其他概率因素。在我们的实现中,\(\mathrm{SNR} \in[5,20] \mathrm{dB}\) 和 \(\mathrm{SER} \in[-10,13] \mathrm{dB}\)。在双方通话期间评估的 SNR 和 SER 定义为:
\[ \mathrm{SNR}=10 \log _{10}\left[\sum_{n} s^{2}(n) / \sum_{n} v^{2}(n)\right] (8) \]\[ \mathrm{SER}=10 \log _{10}\left[\sum_{n} s^{2}(n) / \sum_{n} d^{2}(n)\right] (9) \]其他概率因子设置如下。有 30% 的概率将 $x(n) $ 和 $d(n) $ 设置为零,这样可以模拟近端单讲的情况,噪声信号 $ (v(n)) $ 设置为 0 和 50 % 概率。对于即时数据生成,各种随机因素可以保证训练数据的多样性,尤其是在回波信号数据集不足的情况下。
远端信号的延迟。远端信号在被麦克风接收之前会经历各种延迟。如图 2 所示,这种延迟在实际条件下是无法避免的。设备的硬件性能和处理算法,以及通话过程中的网络波动,可能会引入延迟。在传统的基于 DSP 的方法中,需要一个时间延迟估计 (TDE) 模块来对齐麦克风和远端信号。然而,由于非线性变化和背景噪声干扰,在实际中TDE估计容易出现误差。我们将对齐的麦克风信号随机延迟 0 到 100 毫秒,以模拟此类错误。
增益变化。我们对回声信号 $d(n) $ 和远端语音 $x(n) $ 应用随机放大。具体来说,我们随机选择 $d(n) $ 和 $x(n) $之间的 3s 段衰减 20dB 到 30dB。随机衰减信号的概率为 20%。此外,通过简单的最大归一化,[0.3, 0.9] 的幅度范围随机应用于两个信号,这种变化使网络对幅度变化不敏感。
近端信号的混响。使用图像方法 [29] 生成房间脉冲响应 (RIR)。为了扩大数据多样性,我们模拟了 1000 个大小为 \(a \times b \times h\)m 的不同房间用于训练混合,其中\(a \in[5,8], b \in[3,5]\) 和$ h \in[3, 4] $。我们在每个房间中随机选择 10 个位置,具有随机的麦克风-扬声器 (M-L) 距离 ([0.5, 5]m) 来生成 RIR。 RIR 的长度设置为 0.5s,混响时间 (RT60) 从 [0.2, 0.7]s 中随机选择。总共创建了 10,000 个 RIR。我们使用前 500 个 RIR 生成测试集,其余用于训练。对于动态数据生成,RIR 仅用于以 50% 的概率与近端语音 \(s(n)\)进行卷积。远端语音 $x(n) $ 和回声信号 $d(n) $ 要么已经混响,要么已经在不同房间 [13] 中进行了真实录音,因此不需要混响。
3.3 性能指标所提出的方法是根据 ERLE [30] 评估单次通话期间的。语音质量感知评估 (PESQ) [31]、短时客观可理解性 (STOI) [32] 用于双方通话期间。 AEC 挑战还提供了基于平均 P.808 平均意见得分 (MOS) [33] 的主观评估结果。在本研究中,ERLE 定义为:
\[ \mathrm{ERLE}=10 \log _{10}\left[\sum_{n} y^{2}(n) / \sum_{n} \hat{s}^{2}(n)\right] (10) \]这种ERLE变体体现了系统实现的综合回声和噪声衰减,更接近实际应用场景。
3.4 实验设置窗口长度和跳数分别为 20ms 和 10ms。然后对每个时间帧应用 320 点短时傅里叶变换 (STFT) 以产生复光谱。我们的训练数据的块大小设置为 10s。我们的模型使用 Adam 优化器 [34] 训练了 100 个 epoch,初始学习率为 1e-3,如果两个 epoch 没有改善,学习率需要减半。模型的整个参数为1.4M,如果特别指出,使用SI-SNR loss进行训练或Seg-SiSNR loss。系统总延迟为40ms。我们网络的实时因子(RTF)为 0.4385,在单核 Intel(R) Xeon(R) CPU E5-2640@2.50GHz 上测试。一些处理过的音频片段可以在这个页面3中找到。
3.5 结果和分析 在表 2 中,我们比较了 AEC 挑战数据集中的不同方法。由于非线性失真和噪声干扰,WebRTC-AEC3 在 PESQ 和 STOI 的视图中效果不佳。我们的方法在所有条件下都优于 BLSTM [14](4 个 BLSTM 层,300 个隐藏单元)和 AEC 挑战基线 [13](2 个 GRU 层,322 个隐藏单元)。除了在频率和时间轴上循环的 DC-F-T-LSTM-CLSTM 之外,我们还尝试了在通道和时间轴上循环的 DC-C-T-LSTM-CLSTM 进行比较。在几乎相同数量的参数下,我们的实验证明在频率轴上进行递归更有效。与 DTLN-AEC-20 相比,DC-F-T-LSTM-CLSTM-20
明显以更少的参数带来了更好的性能。 Dataset21 表示 AEC 挑战 2021 数据集和来自 LibriSpeech 的 60 小时近端演讲。我们注意到 PESQ 随着使用更多真实数据而变得更糟,这是因为一些包含近端语音的无效远端单讲剪辑没有被消除。即使使用这些无效剪辑,使用 Seg-SiSNR 作为成本函数也显示出改进并获得了最佳结果。图 3 展示了我们的方法在相同训练数据集下的改进以及使用 Seg-SiSNR 损失抑制残余噪声的更好能力。
表 2:在双方对话的情况下,我们使用动态数据生成评估 PESQ 和 STOI,SER∈ [-13, 10]dB,SNR∈ [5, 20]dB。我们在盲测集中评估远端单话场景的 ERLE。
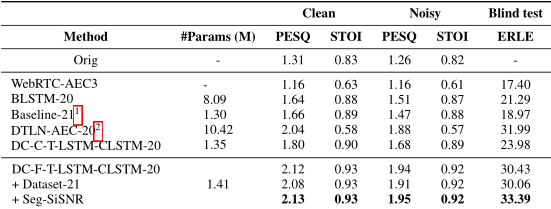
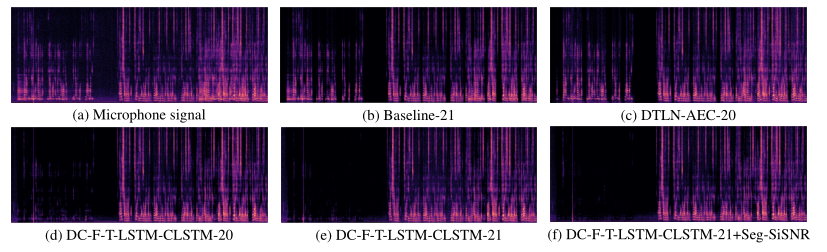
图 3:不同模型在真实双向盲测样本上的比较。
表 3 显示,除了 ST-NE 条件外,我们的方法显着优于 AEC 挑战基线。整体 MOS 提升高达 0.27。 ST-NE 的情况可能是由于动态生成训练数据时 SER ([−13, 10] dB) 和 SNR([5, 20] dB) 范围窄,导致 ST 的数据覆盖不足-NE 场景(高 SNR/SER 场景)并在此场景中导致可感知的语音失真。我们将在未来解决这个问题。
表 3:AEC 挑战盲测集的 MOS 主观评分。置信区间为 0.02(ST = 单方通话,DT = 双方通话,NE = 近端,FE = 远端,DT-ECHO 表示与残余回声更相关,DTOther 表示与其他退化更相关)。
 4 结论
4 结论
这项研究表明,我们提出的神经 AEC 系统 DC-F-T-LSTM-CLSTM 具有更小的参数大小和更低的运行时延迟,与竞争方法相比,可以实现更好的回声消除和噪声抑制性能。我们验证了幅度和相位信息可以更有效地与复杂操作和 F-T-LSTM 模块一起使用。使用 Seg-SiSNR 作为代价函数,可以进一步抑制残余回波和噪声。还报告了双方对话场景、背景噪声情况和真实录音的实验结果,证明我们的方法在具有挑战性的声学回声条件下是有效的。在未来的工作中,我们将优化数据生成策略以更好地适应真实的声学环境,并考虑较低复杂度和混合 DSP/神经网络方法。
5 参考文献[1] J. Benesty, M. M. Sondhi, and Y. Huang, Springer handbook of speech processing. Springer, 2007.
[2] D. Mansour and A. Gray, “Unconstrained frequency-domain adaptivefilter,” IEEE Transactions on Acoustics, Speech, and Signal Processing, vol. 30, no. 5, pp. 726–734, 1982.
[3] J.-S. Soo and K. Pang,“Multidelay block frequency domain adaptivefilter,” IEEE Transactions on Acoustics, Speech, and Signal Processing, vol. 38, no. 2, pp. 373–376, 1990.
[4] S. Gustafsson, R. Martin, P. Jax, and P. Vary,“A psychoacoustic approach to combined acoustic echo cancellation and noise reduction,” IEEE Transactions on Speech and Audio Processing,vol. 10, no. 5, pp. 245–256, 2002.
[5] D. A. Bendersky, J. W. Stokes, and H. S. Malvar,“Nonlinear residual acoustic echo suppression for high levels of harmonic distortion,” in 2008 IEEE International Conference on Acoustics, Speech and Signal Processing, 2008, pp. 261–264.
[6] E. Hänsler and G. Schmidt, Acoustic echo and noise control: a practical approach. John Wiley and Sons, 2005, vol. 40.
[7] V. Turbin, A. Gilloire, and P. Scalart,“Comparison of three postfiltering algorithms for residual acoustic echo reduction,” in 1997 IEEE International Conference on Acoustics, Speech, and Signal Processing, vol. 1, 1997, pp. 307–310 vol.1.
[8] S. Boll,“Suppression of acoustic noise in speech using spectral subtraction,” IEEE Transactions on acoustics, speech, and signal processing, vol. 27, no. 2, pp. 113–120, 1979.
[9] L. Ma, H. Huang, P. Zhao, and T. Su,“Acoustic echo cancellation by combining adaptive digitalfilter and recurrent neural network,”2020.
[10] A. Fazel, M. El-Khamy, and J. Lee,“Cad-aec: Context-aware deep acoustic echo cancellation,” in ICASSP 2020 - 2020 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), 2020, pp. 6919–6923.
[11] Z. Wang, Y. Na, Z. Liu, B. Tian, and Q. Fu,“Weighted recursive least squarefilter and neural network based residual echo suppression for the aec-challenge,” in ICASSP 2021 - 2021 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), 2021, pp. 141–145.
[12] J.-M. Valin, S. Tenneti, K. Helwani, U. Isik, and A. Krishnaswamy,“Low-complexity, real-time joint neural echo control and speech enhancement based on percepnet,” in ICASSP 2021- 2021 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), 2021, pp. 7133–7137.
[13] R. Cutler, A. Saabas, T. Parnamaa, M. Loide, S. Sootla, M. Purin, H. Gamper, S. Braun, K. Sorensen, R. Aichner, and S. Srinivasan,“Interspeech 2021 acoustic echo cancellation challenge: Datasets and testing framework,” in INTERSPEECH 2021, 2021.
[14] H. Zhang and D. Wang,“Deep learning for acoustic echo cancellation in noisy and double-talk scenarios,” Training, vol. 161,no. 2, p. 322, 2018.
[15] W. N. L. and M. B. T.,“Acoustic echo cancellation with the dualsignal transformation lstm network,” in ICASSP 2021 - 2021 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), 2021, pp. 7138–7142.
[16] N. L. Westhausen and B. T. Meyer,“Dual-signal transformation lstm network for real-time noise suppression,” arXiv preprint arXiv:2005.07551, 2020.
[17] H. Chen, T. Xiang, K. Chen, and J. Lu,“Nonlinear residual echo suppression based on multi-stream conv-tasnet,” 2020.
[18] Y. Luo and N. Mesgarani, “Conv-tasnet: Surpassing ideal time–frequency magnitude masking for speech separation,”IEEE/ACM Transactions on Audio, Speech, and Language Processing, vol. 27, no. 8, pp. 1256–1266, 2019.
[19] J.-H. Kim and J.-H. Chang,“Attention wave-u-net for acoustic echo cancellation,” Proc. Interspeech 2020, pp. 3969–3973, 2020.
[20] D. Stoller, S. Ewert, and S. Dixon,“Wave-u-net: A multi-scale neural network for end-to-end audio source separation,” arXiv preprint arXiv:1806.03185, 2018.
[21] H.-S. Choi, J.-H. Kim, J. Huh, A. Kim, J.-W. Ha, and K. Lee,“Phase-aware speech enhancement with deep complex u-net,”arXiv e-prints, pp. arXiv–1903, 2019.
[22] Y. Hu, Y. Liu, S. Lv, M. Xing, S. Zhang, Y. Fu, J. Wu, B. Zhang, and L. Xie,“Dccrn: Deep complex convolution recurrent network for phase-aware speech enhancement,” arXiv preprint arXiv:2008.00264, 2020.
[23] J. Li, A. Mohamed, G. Zweig, and Y. Gong,“Lstm time and frequency recurrence for automatic speech recognition,” in 2015 IEEE Workshop on Automatic Speech Recognition and Understanding (ASRU), 2015, pp. 187–191.
[24] W. Mack and E. A. P. Habets,“Deepfiltering: Signal extraction and reconstruction using complex time-frequencyfilters,” IEEE Signal Processing Letters, vol. 27, pp. 61–65, 2020.
[25] D. S. Williamson, Y. Wang, and D. Wang,“Complex ratio masking for monaural speech separation,” IEEE/ACM Transactions on Audio, Speech, and Language Processing, vol. 24, no. 3, pp. 483–492, 2016.
[26] E. Vincent, R. Gribonval, and C. Fevotte,“Performance measurement in blind audio source separation,” IEEE Transactions on Audio, Speech, and Language Processing, vol. 14, no. 4, pp. 1462–1469, 2006.
[27] V. Panayotov, G. Chen, D. Povey, and S. Khudanpur,“Librispeech: An asr corpus based on public domain audio books,”in 2015 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), 2015, pp. 5206–5210.
[28] C. K. Reddy, H. Dubey, K. Koishida, A. Nair, V. Gopal, R. Cutler, S. Braun, H. Gamper, R. Aichner, and S. Srinivasan,“Interspeech 2021 deep noise suppression challenge,” arXiv preprint arXiv:2101.01902, 2021.
[29] J. B. Allen and D. A. Berkley,“Image method for efficiently simulating small-room acoustics,” The Journal of the Acoustical Society of America, vol. 65, no. 4, pp. 943–950, 1979.
[30] S. Theodoridis and R. Chellappa, Academic Press Library in Signal Processing: Image, Video Processing and Analysis, Hardware, Audio, Acoustic and Speech Processing. Academic Press, 2013.
[31] A. W. Rix, J. G. Beerends, M. P. Hollier, and A. P. Hekstra, “Perceptual evaluation of speech quality (pesq)-a new method for speech quality assessment of telephone networks and codecs,” in 2001 IEEE International Conference on Acoustics, Speech, and Signal Processing. Proceedings (Cat. No. 01CH37221), vol. 2.IEEE, 2001, pp. 749–752.
[32] C. H. Taal, R. C. Hendriks, R. Heusdens, and J. Jensen,“A shorttime objective intelligibility measure for time-frequency weighted noisy speech,” in 2010 IEEE International Conference on Acoustics, Speech and Signal Processing, 2010, pp. 4214–4217.
[33] R. Cutler, B. Nadari, M. Loide, S. Sootla, and A. Saabas,“Crowdsourcing approach for subjective evaluation of echo impairment,”in ICASSP 2021-2021 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 2021, pp.406–410.
[34] D. P. Kingma and J. Ba,“Adam: A method for stochastic optimization,” arXiv preprint arXiv:1412.6980, 2014.