这是一个新开的每周六定期更新栏目,将本周arxiv上新出的联邦学习等感兴趣方向的文章进行总结。与之前精读文章不同,本栏目只会简要总结其研究内容、解决方法与效果。这篇作为栏目首发,可能不止本周内容(毕竟欠账太多了)。
量化-
A. T. Suresh, Z. Sun, J. H. Ro, and F. Yu, “Correlated quantization for distributed mean estimation and optimization,” arXiv:2203.04925 [cs, math], Mar. 2022, Accessed: Mar. 10, 2022. [Online]. Available: http://arxiv.org/abs/2203.04925
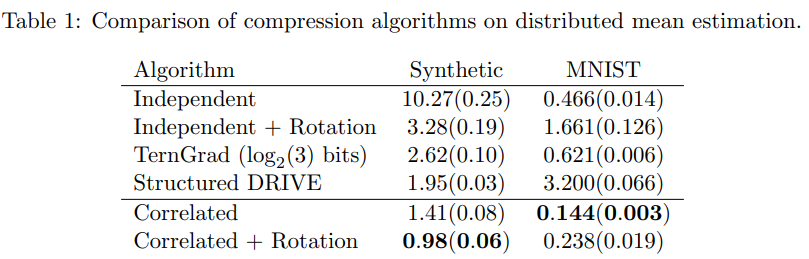
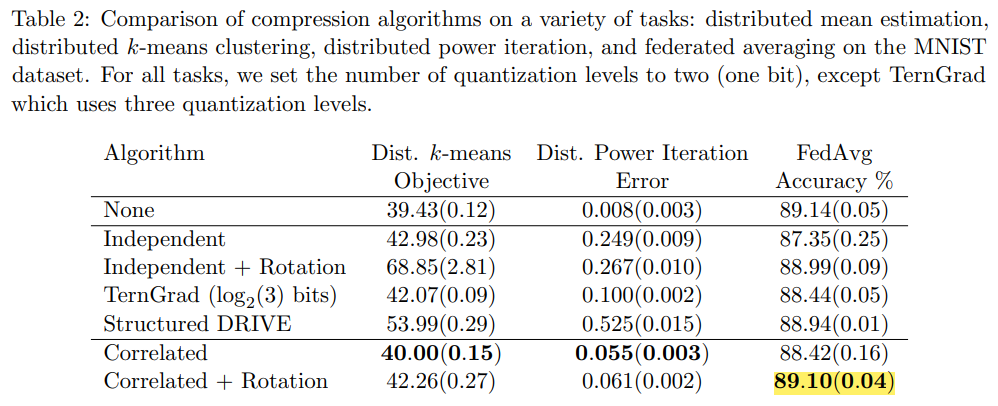
这是谷歌团队关于DME的最新研究成果。其中Suresh从2017年就深耕这一块,算是老朋友了,而Felix X. Yu刚好是之前Federated Learning with Only Positive Labels这篇文章的作者,算是新朋友。
这篇文章的特点在于提出了correlated quantization protocol,把量化的重点从以前的数据边界转移到了deviation of data points,得到了比传统随机量化更好的性能。虽然之前的工作就提到了当数据点有更好的集中性质时,可以获得更好的错误收敛表现,但都需要需要comcentration radius,location of the mean等先验知识,而本文则不需要这些边信息。
结果表现除了更高的收敛速率,结合FL之后也有了更高的准确率。可以看到在DME上是取得了较为明显的改善,不过对于具体应用上似乎改善较为有限。当然可能是因为MNIST过于简单了。
-
J. Wang et al., “FedLite: A Scalable Approach for Federated Learning on Resource-constrained Clients,” arXiv:2201.11865 [cs], Feb. 2022, Accessed: Mar. 12, 2022. [Online]. Available: http://arxiv.org/abs/2201.11865
这是CMU学生在谷歌实习时做的工作,作者列表里同样有Felix Yu。这篇文章之前投过会议,因为写作太差了被拒了,现在加了收敛性分析、梯度矫正等部分,写法上也细致很多。文章研究的是大型模型传输的问题,选择的方法是split learning,也就是每次只有一部分模型在用户端存储和训练,而大部分模型都在服务器端。为了进一步降低通信开销,文章用了聚类来得到梯度的质心从而进一步压缩,最终能带来490倍的通信开销下降。整个结构的关键点在于部分网络传输时如何收敛,如何选取合适的梯度进行聚类、以及后向传播时的梯度纠正到底有何作用。总的来说,这是一篇值得细读和复现的文章。
-
E. Agrell and B. Allen, “On the best lattice quantizers,” arXiv:2202.09605 [astro-ph, physics:gr-qc, physics:math-ph], Feb. 2022, Accessed: Mar. 11, 2022. [Online]. Available: http://arxiv.org/abs/2202.09605
将1996年Zamir and Feder的格量化的经典论文进行了推广。
-
S. S. Mahara, S. M., B. N. Bharath, and A. Murthy, “Multi-task Federated Edge Learning (MtFEEL) in Wireless Networks,” arXiv:2108.02517 [cs, math], Mar. 2022, Accessed: Mar. 10, 2022. [Online]. Available: http://arxiv.org/abs/2108.02517
这是一篇IIT团队的文章,有点三哥的特性,吹得神乎其技细看常规操作。作者研究的FL在multi-task领域,也就是每个用户的神经网络不完全相同(原来这个已经有很多工作了),而本文新加了瑞利平坦衰落信道下的传输和收敛性理论分析两个贡献点。算法上的创新在于将用户的loss进行加权平均,并利用一些bound来限制住估计值和真实值的距离,从而提高估计的准确度。服务器使用符号梯度反馈来得到personalized NN。
看算法似乎还是从用户梯度的差异性(或数据分布的相似度)来衡量相似度的,有一种聚类的感觉在里面。
最终在MNIST上的实验结果表明比FedAvg和FedSGD要好,不过没有比过sign SGD不知道是什么鬼。
-
C. Xu, Z. Hong, M. Huang, and T. Jiang, “Acceleration of Federated Learning with Alleviated Forgetting in Local Training,” arXiv:2203.02645 [cs], Mar. 2022, Accessed: Mar. 11, 2022. [Online]. Available: http://arxiv.org/abs/2203.02645
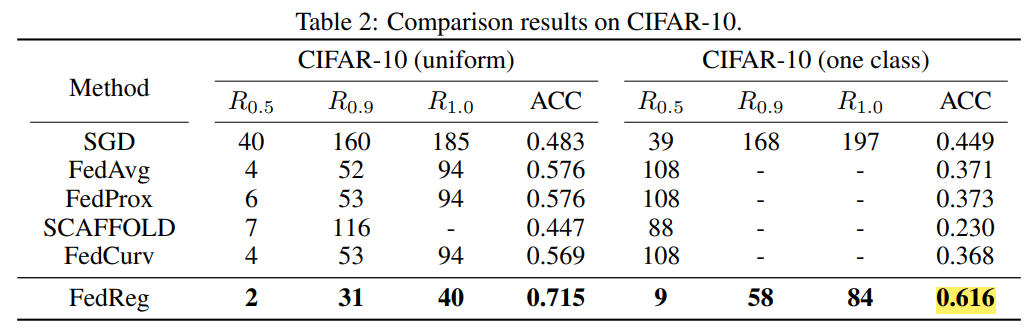
这是清华的ICLR2022文章,研究了如何对抗联邦学习中的异构性。作者认为现有方法较慢的原因在于本地学习会着重看到自己的信息,从而遗忘之前学到的知识,因此在考虑所有用户之前样本的loss产生较大增幅。因此作者提出FedReg算法来避免知识遗忘。具体做法时将global model学到的之前训练数据的数据编码成pseudo data,并且在本地训练时对此添加正则化。实验显示生成的pseudo data包含了与其他用户之前训练数据相同的Fisher information。在MNIST上的实验结果达到了0.978的准确率,在CIFAR10上也区的了比FedProx还要好的最佳性能,达到了0.616。可能的缺陷在于受调参的影响比较大。
这篇文章有开源的代码,可以好好学习。
-
J. Mori, I. Teranishi, and R. Furukawa, “Continual Horizontal Federated Learning for Heterogeneous Data,” arXiv:2203.02108 [cs], Mar. 2022, Accessed: Mar. 12, 2022. [Online]. Available: http://arxiv.org/abs/2203.02108
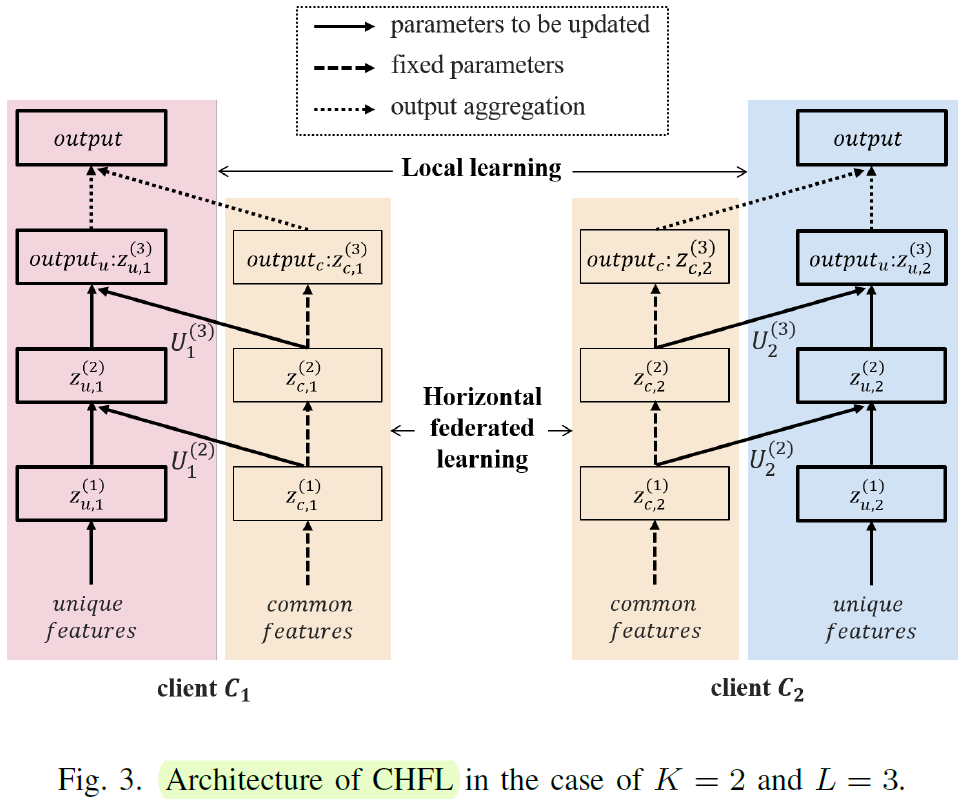
日本电气股份有限公司的文章,解决异构数据的出发点依然是解决连续训练中的遗忘问题(continue learning,catastrophic forgetting),与清华的思路异曲同工。这篇文章和我之前的思路是一致的,在异构数据中,对共有的标签进行联邦学习,对自己独有的异构数据进行本地独立学习。之前遇到的问题是没有找到这两种学习的合并方式,而这篇文章给出的方法是按照列划分,分别对应共有标签和特征标签。不过在仿真部分,他没有用常见的公开数据集,而是用的是forest covertype dataset等数据集,不太好比较性能。
-
S. Nikoloutsopoulos, I. Koutsopoulos, and M. K. Titsias, “Personalized Federated Learning with Exact Stochastic Gradient Descent,” arXiv:2202.09848 [cs], Feb. 2022, Accessed: Mar. 12, 2022. [Online]. Available: http://arxiv.org/abs/2202.09848
依旧是研究personlized federated learning的文章,来源于雅典经济与商业大学。与上一篇日本NEC集团的文章一样,都是考虑两种网络结构的组合,分别代表用户间的共有层和个性化的用户层。看来这种来自于FedPer (Arivazhagan et al., 2019)的思路已经并不新奇,只是训练方式稍有不同。常见的personalized FL方法有
- fine tuning a global model
- feature transfer:类似multi-task of feature transfer model(看来异构网络的训练与Multi-task learning结合的思路有很多研究)
本文提到的训练方式是先随机选取部分用户来根据本地数据训练用户层,在最后上传的时候,包括共有层地进行训练并上传梯度。
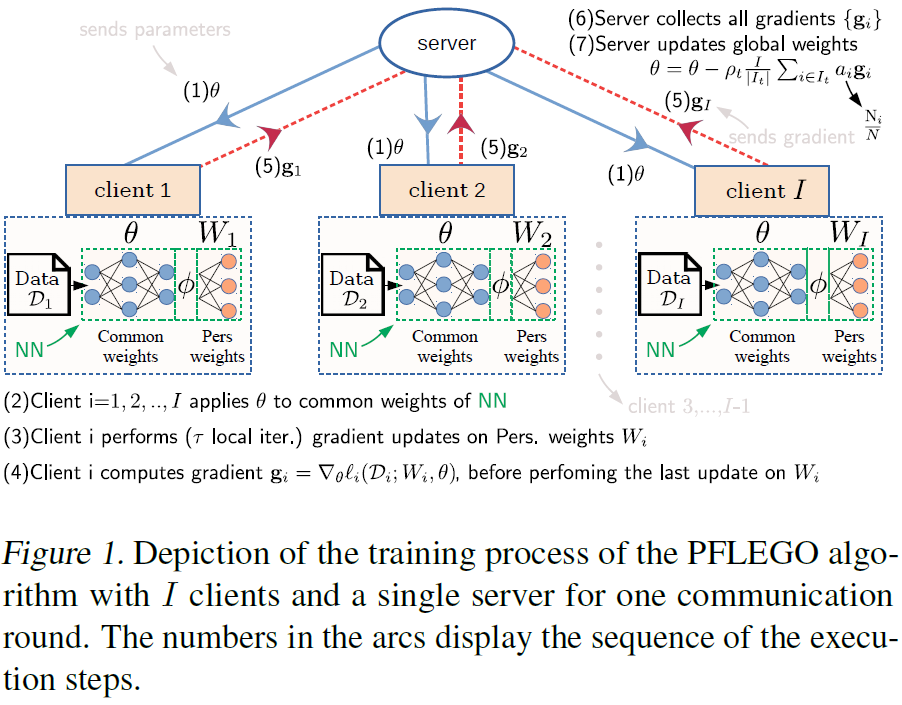
不过最终的结果看来,这个方法都不一定比FedAvg的效果好。估计在这种网络架构上研究不同训练方法的路子已经不太好走了。
-
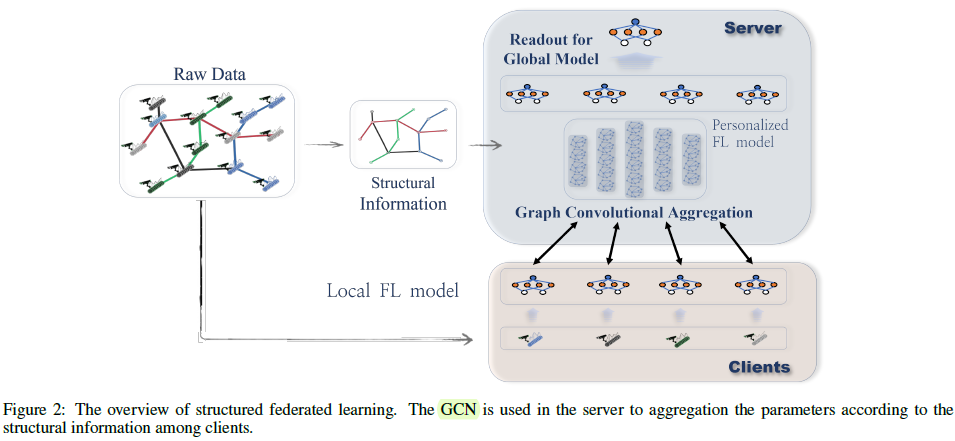
F. Chen, G. Long, Z. Wu, T. Zhou, and J. Jiang, “Personalized Federated Learning With Structure,” Mar. 2022, doi: 10.48550/arXiv.2203.00829.
同样是考虑异构网络,另外一篇悉尼科技大学的文章重点研究的是personalized FL (PFL),并在在knowledge sharing的基础上进一步考虑了用户间的结构信息。这里的结构信息其实就是图神经网络里的拓扑信息,具体实现上还是用户模型参数的相似度。在优化的实现上,看起来也依然是通过增加表示相关关系的正则项来实现的。
-
D. Makhija, X. Han, N. Ho, and J. Ghosh, “Architecture Agnostic Federated Learning for Neural Networks,” Feb. 2022, doi: 10.48550/arXiv.2202.07757.
这是UT Austin团队关于异构FL的解决方案,表面是打造personalised model,本质还是transfer learning 或者 knowledge distillation。作者说他考虑的是instance-level representations(又叫做proximal term),不过我理解和embedding应该大同小异。具体用的表示距离上的metric是centered kernel alignment (CKA),属于是不知道从哪儿找出来的指标,然后加在损失函数里面作为一个正则项。
\[\min _{\mathcal{W}_{i}} \mathcal{L}_{i}=\mathcal{F}\left(\mathcal{W}_{i}\right)+\eta \operatorname{CKA}\left(K_{i}, \bar{K}(t-1)\right) \] -
H. Cho, A. Mathur, and F. Kawsar, “FLAME: Federated Learning Across Multi-device Environments,” arXiv:2202.08922 [cs], Feb. 2022, Accessed: Mar. 12, 2022. [Online]. Available: http://arxiv.org/abs/2202.08922
这篇是CMU学生在诺基亚贝尔实验室实习的文章,技术性不多,更像是一篇调度相关的期刊文章。文章考虑异构FL的以下三个方面
- 以用户为中心的不同设备的时间调度
- 基于准确度与效率的设备选择
- 设备的模型个性化
或许是和业界结合的原因,提出了用户为中心的多设备FL其实比较有新意。设备的异构特性又很自然地引入到了FL的异构性当中,因此在训练中需要兼顾用户和设备的两个异构性。不过文章给出的用户异构性就是每个不同用户序列地训练,比较trivial。在设备选择上,直观地定义了多个变量,也就是statistical utility, system utility, time utility,作为选择的依据。在模型个性化上,也是加正则项的老套路。

其中model updata部分\((v_i-w^r)\)的正则就是用于确保用户模型的参数不会过于远离全局模型。另外这篇文章比较体现业界形态的就是提出了experiment testbed。最后在文章总结的personalization in FL也比较全面,值得参考。
-
E. Gasanov, A. Khaled, S. Horváth, and P. Richtárik, “FLIX: A Simple and Communication-Efficient Alternative to Local Methods in Federated Learning,” arXiv:2111.11556 [cs, math, stat], Feb. 2022, Accessed: Mar. 12, 2022. [Online]. Available: http://arxiv.org/abs/2111.11556
这是KAUST和普林斯顿合作的文章,看到作者Richtárik就知道又有硬核的收敛性分析了。依然考虑personalized FL,本文的思路是直接修改优化目标函数,
\[\min _{x \in \mathbb{R}^{d}} \tilde{f}(x) \stackrel{\text { def }}{=} \frac{1}{n} \sum_{i=1}^{n} f_{i}\left(\alpha_{i} x+\left(1-\alpha_{i}\right) x_{i}\right) \]其中\(x_i\)是每个用户本地数据的最小值,\(\alpha_i\)是每个用户的个性化系数。这个式子其实和正则项的形式很相近,只是把合并项拿到了自变量里面,同时集中的点从global model换成了本地的最优值。这种其实并不算深度学习了,主要是优化,在考虑\(L_i\)-smooth函数下进行分析。而且真要跑实验效果的话,超参\(\alpha\)感觉也需要autoML来处理。
-
O. Marfoq, G. Neglia, A. Bellet, L. Kameni, and R. Vidal, “Federated Multi-Task Learning under a Mixture of Distributions,” arXiv:2108.10252 [cs, math, stat], Feb. 2022, Accessed: Mar. 12, 2022. [Online]. Available: http://arxiv.org/abs/2108.10252
之前都不知道法国在机器学习这一块有多强,这篇法国国家信息与自动化研究所的NeurIPS 2021文章简直太猛了。在面对异构数据的时候,文章假设每个本地数据分布都是\(M\)个未知的潜在分布的混合,而这就为用户的知识聚合找到了原因。在这个想法下,一个personlized model是\(M\)个共享的模型部分的线性组合,用户联合地学习这\(M\)个部分,而个性化的部分就体现在混合权重不同。这个方法将现有的personalized FL算法甚至FedEM算法都表示为特例,包括
- Clustered FL
- personalization via model interpolation
- Federated MTL via task relationships
作者给出了开源的代码,结果显示比现有的算法效果都强。
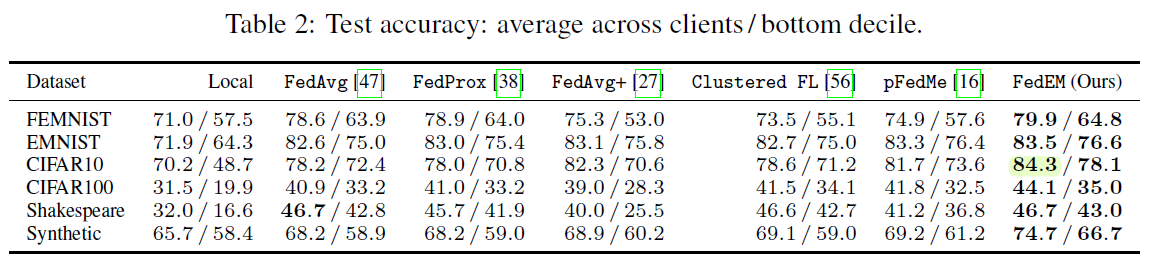
对于之后的研究方向,作者联系到了利用数据分布进行量化(这方面FedEM已经在不考虑个性化的前提下完成了)以及更好的隐私控制。
-
B. Zhao, Z. Liu, C. Chen, M. Kolar, Z. Zhang, and J. Zhou, “Adaptive Client Sampling in Federated Learning via Online Learning with Bandit Feedback,” arXiv:2112.14332 [cs], Mar. 2022, Accessed: Mar. 11, 2022. [Online]. Available: http://arxiv.org/abs/2112.14332
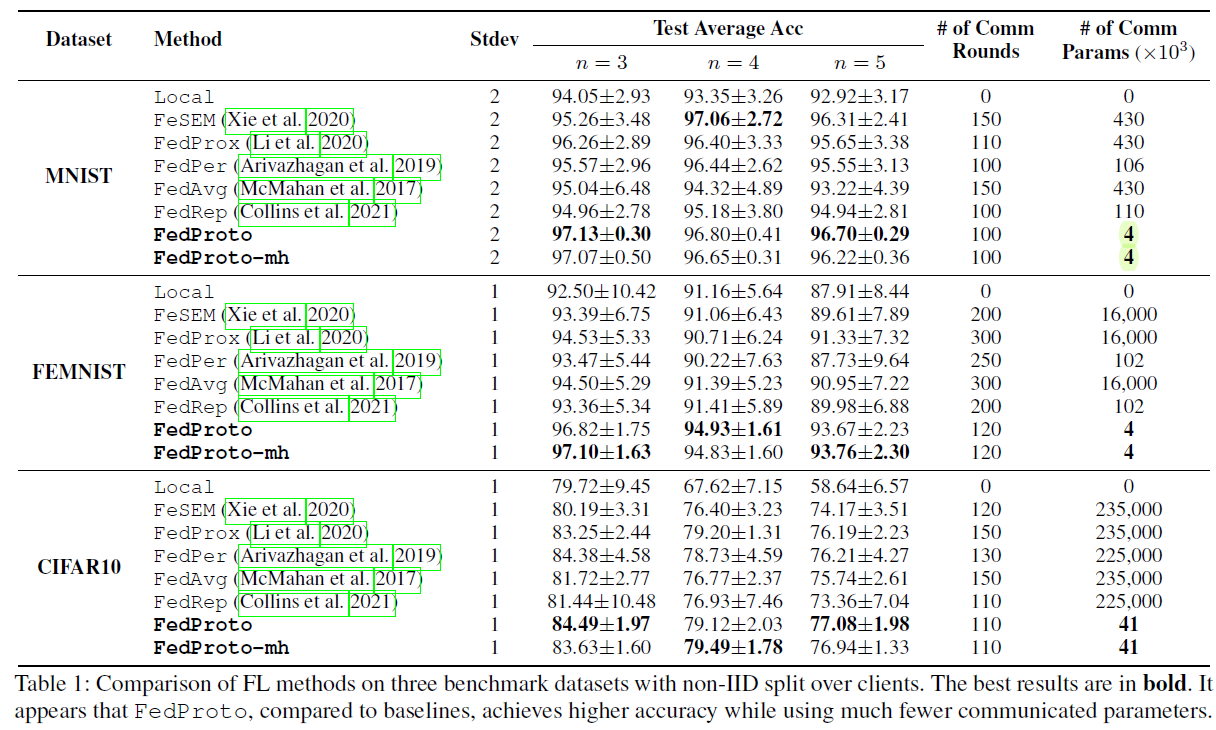
悉尼科技大学的AAAI 2022文章。同样是针对异构用户的misalignment问题,这篇文章的解决方法是用prototypes aggregation来代替传统的gradient aggregation。这里的prototype指的是the mean of multiple features,我理解的是对应的特征。这个思路其实和Federated Learning with Only Positive Labels这篇文章很相似,都是将输入先进行一个embedding,然后用embedding来进行分类。因此只要找到了好的embedding,那分类的难度其实不大。在训练的时候,本地用户在训练本地数据的同时,保证和聚合的global prototpye的距离尽量小,避免产生较大的分歧。
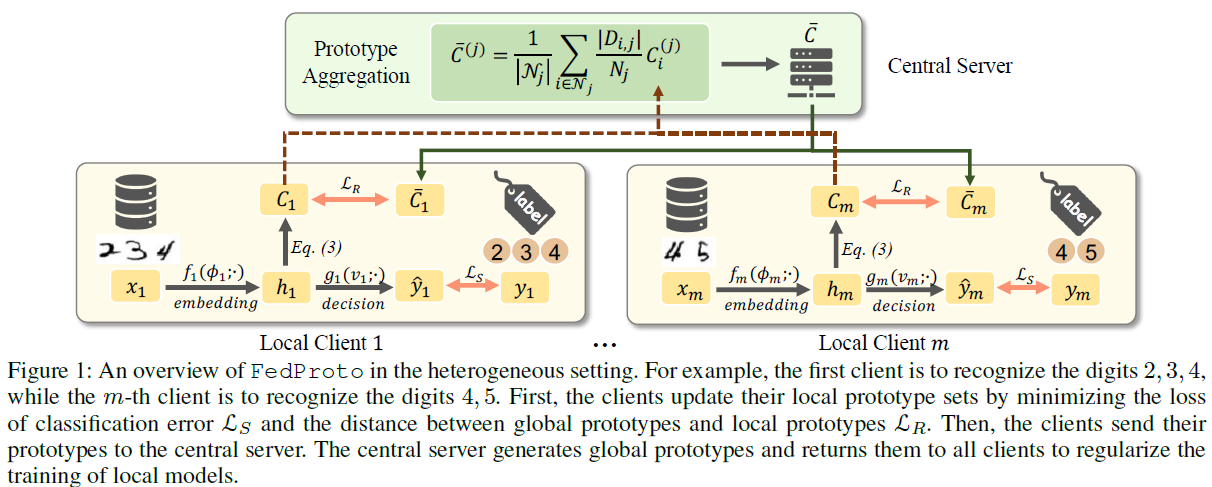
最终仿真结果里比较突出的一点是其传输的数据量大大降低,可能是用embedding的值代替了传输的网络梯度带来的好处。
-
G. Cheng, K. Chadha, and J. Duchi, “Federated Asymptotics: a model to compare federated learning algorithms,” arXiv:2108.07313 [cs, math, stat], Feb. 2022, Accessed: Mar. 12, 2022. [Online]. Available: http://arxiv.org/abs/2108.07313
这是斯坦福Duchi团队的文章,有很强的统计学色彩。一上来就是asymptotic risk之类的就看不懂了,做不来这种。
-
M. Sefidgaran, A. Gohari, G. Richard, and U. Şimşekli, “Rate-Distortion Theoretic Generalization Bounds for Stochastic Learning Algorithms,” Mar. 2022, doi: 10.48550/arXiv.2203.02474.
这篇巴黎理工学院的文章从信息论的角度研究了随机优化的泛化性。现有的泛化性分析方法包括
- mutual information between the data sample and the algorithm output
- compressibility of the hypothesis space
- fractal dimension of the hypothesis space
而这篇文章通过rate-distortion theory的角度对这三个分析角度结合成了一个数学框架,并且将“压缩错误率”和泛化误差联系了起来。
-
M. Fereydounian, A. Mokhtari, R. Pedarsani, and H. Hassani, “Provably Private Distributed Averaging Consensus: An Information-Theoretic Approach,” arXiv:2202.09398 [cs, math], Feb. 2022, Accessed: Mar. 11, 2022. [Online]. Available: http://arxiv.org/abs/2202.09398
这篇文章出自于宾大的团队,研究了去中心化下consensus averaging中隐私和收敛性的关系。其实distributed consensus problem是一个经典的问题,而且其收敛性质已经有广泛研究。然而,现有的交换本地信息的想法会泄露隐私信息,这正是本文改进的地方。文章提出算法来设计有噪声的信息,从而在保证原有速率的基础上,最小化本地值的隐私泄露。通过消息的互信息来量化泄漏的隐私量,最终得到了隐私与收敛时间的tradeoff。
如果要强行做安全相关的东西,这部分可以很好的与information-theoretic perspective相结合。
-
J. Liu, H. Zhao, D. Ma, K. Mei, and J. Wei, “Opening the Black Box of Deep Neural Networks in Physical Layer Communication,” arXiv:2106.01124 [cs, eess, math], Feb. 2022, Accessed: Mar. 11, 2022. [Online]. Available: http://arxiv.org/abs/2106.01124
国防科大发布的一篇会议短文,研究了在用autoencoder表征物理层通信系统并进行训练时,信息的流动。看起来还是仿真居多,不是很可靠,但是怎么结合信息论似乎还是个令人比较好奇的地方。
-
Y. Deng, M. M. Kamani, and M. Mahdavi, “Local SGD Optimizes Overparameterized Neural Networks in Polynomial Time,” arXiv:2107.10868 [cs, math], Feb. 2022, Accessed: Mar. 12, 2022. [Online]. Available: http://arxiv.org/abs/2107.10868
这是一篇宾州立的AISTATS 2022的文章,分析了在ReLU激活函数的深层神经网络下,local SGD和FedAvg能在多项式时间内收敛。相对于传统的gradient Lipschitzness条件,文章主要考虑以下三个方面
- semi gradient Lipschitzness
- shrinkage of local loss
- local model deviation analysis
最终表明即使ReLU网络不满足gradient Lipschitzness条件,本地梯度与全局参数之间的差异在本地SGD的动态特性下也不回差得太大。看起来convergence theory of NN依然是一个比较活跃的方向,而且乍一看也没有用分段线性这种无脑的思路。这篇文章没有对网络结构的超参进行研究,感觉是挺有意思的一篇文章。
-
D. J. Beutel et al., “Flower: A Friendly Federated Learning Research Framework,” arXiv:2007.14390 [cs, stat], Mar. 2022, Accessed: Mar. 12, 2022. [Online]. Available: http://arxiv.org/abs/2007.14390
这是剑桥大学等欧洲高校主导开发的FL架构,其实2020年7月就发布了,到现在断断续续已经是第五版,不知道这次放上来到底是有改动还是刷存在感。提出架构的原因还是在于从科研环境的仿真迁移到实际应用当中,而Flower主打的特色在于大规模的用户数量(15M)
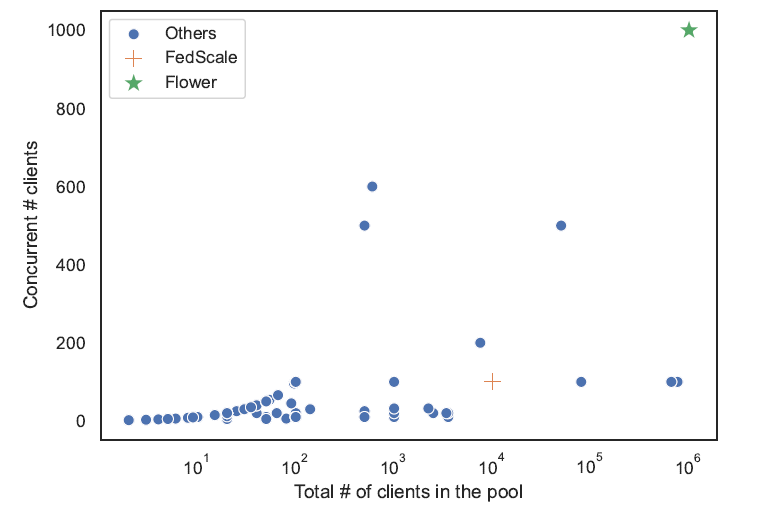
图片里x轴是总的用户数量,y轴是并发的用户数量,可以看到Flower明显得超过其他架构。同时架构中内置了诸多常用算法,虽然没有实现的必要,但是对于联邦学习而言,知道这些经典算法肯定是很有必要的。

我觉得这篇文章主要用的技术就是Virtual Client Engine (VCE),能够将inactive的用户的资源减少接近到零,从而提升可支持的用户数量。
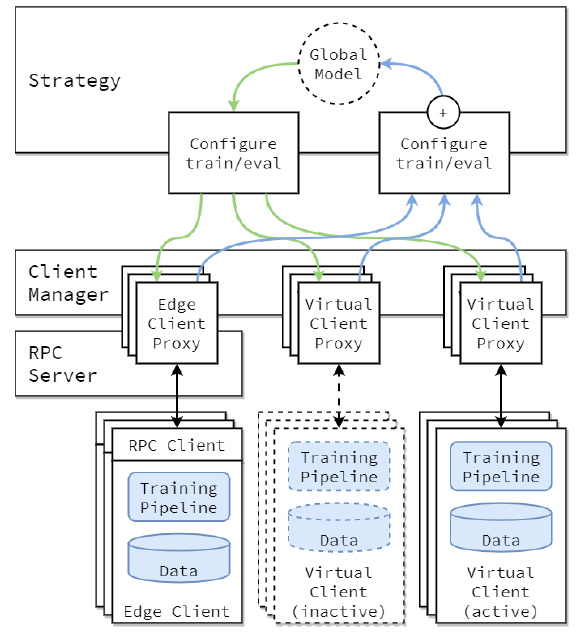
另外还有若干架构,如果之后要做这方面落地的工作可以再看看,否则目前用处不大,还是先好好看代码吧。
- J. Wang et al., “FedLite: A Scalable Approach for Federated Learning on Resource-constrained Clients,” arXiv:2201.11865 [cs], Feb. 2022, Accessed: Mar. 12, 2022. [Online]. Available: http://arxiv.org/abs/2201.11865
研究部分网络如何收敛,以及代码复现 - C. Xu, Z. Hong, M. Huang, and T. Jiang, “Acceleration of Federated Learning with Alleviated Forgetting in Local Training,” arXiv:2203.02645 [cs], Mar. 2022, Accessed: Mar. 11, 2022. [Online]. Available: http://arxiv.org/abs/2203.02645.
学习代码 - O. Marfoq, G. Neglia, A. Bellet, L. Kameni, and R. Vidal, “Federated Multi-Task Learning under a Mixture of Distributions,” arXiv:2108.10252 [cs, math, stat], Feb. 2022, Accessed: Mar. 12, 2022. [Online]. Available: http://arxiv.org/abs/2108.10252
数据分布与训练效果的关系 - M. Sefidgaran, A. Gohari, G. Richard, and U. Şimşekli, “Rate-Distortion Theoretic Generalization Bounds for Stochastic Learning Algorithms,” Mar. 2022, doi: 10.48550/arXiv.2203.02474.
网络泛化性与信息论的统一框架