大家好,我是【架构摆渡人】,一只十年的程序猿。这是实践经验系列的第十一篇文章,这个系列会给大家分享很多在实际工作中有用的经验,如果有收获,还请分享给更多的朋友。
前面有篇文章我们讲到用时间来代替自增ID进行分页排序,原因是因为接入了分布式ID,但是分布式ID不能够保证有序,只能保证全局唯一。
那么今天我们一起来探讨下,究竟能不能实现有序的分布式ID呢?
分布式ID的实现方式 号段模式号段模式是目前用的比较多的实现分布式ID的方式,号段模式通过预先获取一段范围,然后全部在内存中进行ID的分发,性能极高。
采用号段模式实现的开源框架也有很多,比如美团的Leaf,滴滴的Tinyid。对号段模式实现原理不了解的小伙伴可以查看下面的地址进行深入学习。号段模式想要实现递增比较难,文章后面我们一起聊聊有没有什么方式能够实现。
Leaf: https://github.com/Meituan-Dianping/Leaf
Tinyid: https://github.com/didi/tinyid
SnowflakeSnowflake 是 Twitter 开源的分布式ID生成算法,在国内用的也比较多。比如百度开源的uid-generator就是基于Snowflake算法进行改进。
uid-generator:https://github.com/baidu/uid-generator
Snowflake生成ID性能很好,而且也满足递增的要求。不过依赖机器上的时间,如果时间不一致就会有重复的问题。
Redis IncrRedis 可以直接使用Incr命令进行数字的递增,从而实现自增的ID。如果使用Redis实现分布式ID需要进行ID的持久化,否则重启后就没了会出现重复的问题。
既然要持久化,那就避免不了使用AOF或者RDB实现持久化。使用RDB可能会丢失数据,导致ID重复发生。使用AOF肯定要配置刷数据的模式为always,每次操作记录都同步到硬盘上,这样才能保证数据不丢失,但是性能较差。当然Redis 4.0还有混合模式(AOF+RDB)可以用也是一种不错的选择。
无论是单机还是集群环境下,某个key必定会路由到某一个节点。虽然Redis单机也能支持10万基本的QPS,假设你的ID需求超过了这个量级,这块就会成为瓶颈,因为你要保证自增,没办法水平扩容。
号段模式想有序怎么办?号段模式数据不会丢失,性能高,是一个很优秀的方案。但是号段模式没办法实现全局的递增ID,如果要实现全局递增,那么就不能拆分,得有一个固定的节点,所有请求都从这个节点获取ID才行。但是号段模式就是分段的特性,通过分段可以实现水平扩展,提升性能。
号段模式只能实现局部递增,比如我订单表接入了分布式ID,如果用号段模式,那么就会出现我下第一单的ID是20001,接着下第二单,ID可能就是10003。如果此时用的是ID降序排序,就会出现顺序错乱的问题,这也是之前文章里面为什么要用高精度的时间来排序。
这种情况下,是否只要保证同一个用户下的数据是递增的就可以,这就是局部递增。如果要想实现局部递增需要考虑下面几个问题:
- 固定路由
用户维度的递增,就需要将用户的请求路由到固定的ID服务节点,这样取出来的ID就是局部递增。
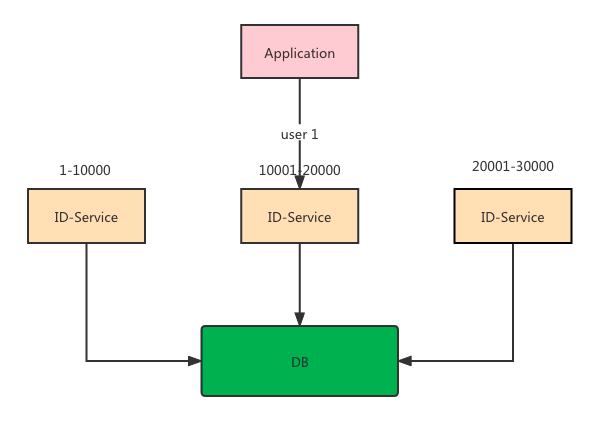
- ID服务某个节点挂掉或者重启
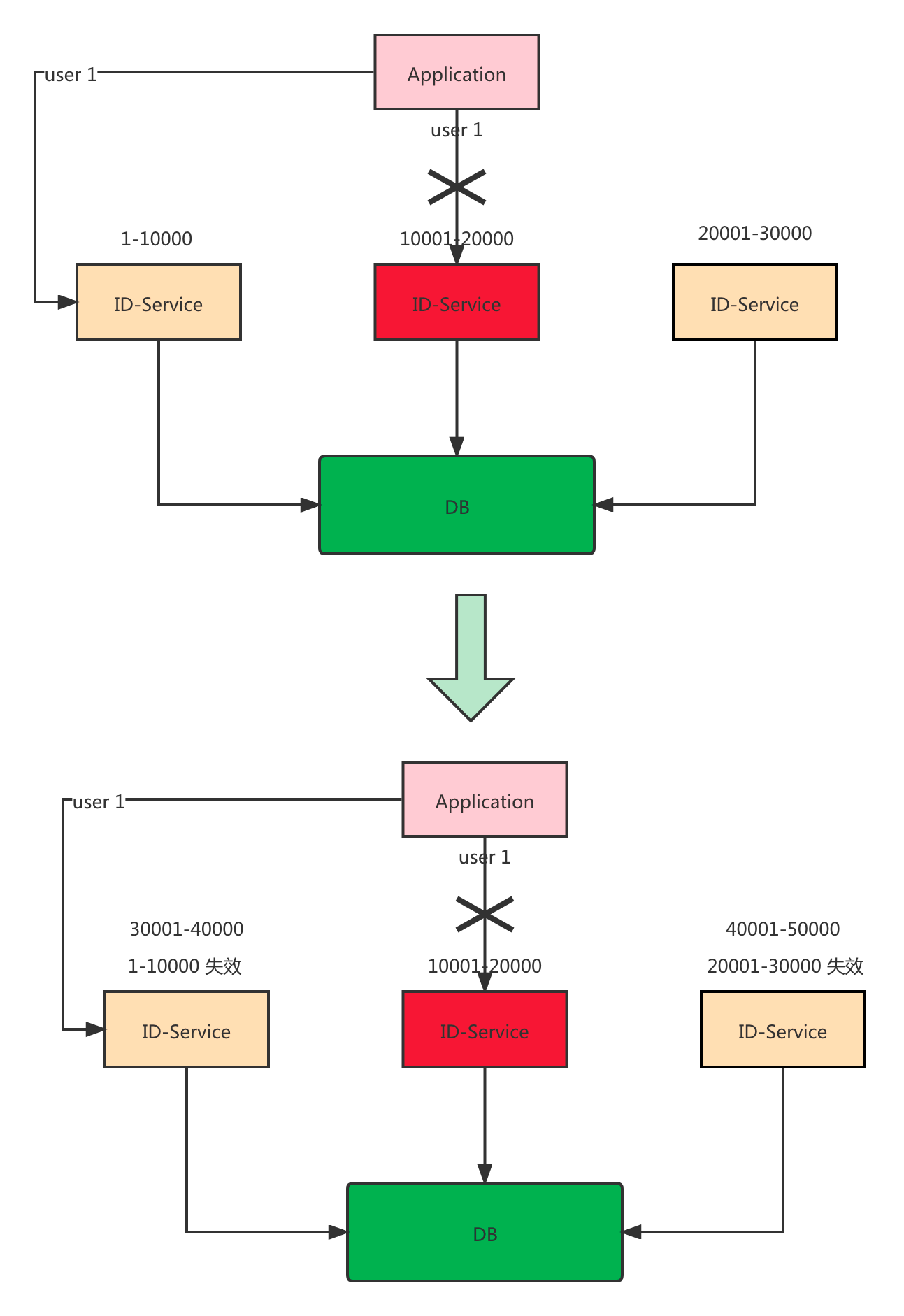
假设用户A一直是路由到 id-service-b 上面,此时 id-service-b 挂掉了,那就需要重新找个新的节点进行路由,问题来了,路由到新的节点,假设是 id-service-c。
而此时 id-service-c 上面的ID 段可能比 id-service-b大,如果大的话就没问题,还是递增。如果小的话就有问题了呀,所以这个问题要解决。
如何解决上面的问题呢?
个人感觉这个问题不太好解决,因为路由到某一个节点的用户是N,也不可能对这些用户现有的ID进行查询,判断是否大于即将路由的服务的ID段。整个逻辑太复杂了。
有一个简单的方式,就是当有固定路由需求的ID要进行路由切换的时候,全局加锁(此时并发量大的话会影响使用方的RT),将这个ID对应的所有段都清除,这样重新路由的时候就又申请了新的段,新的段肯定大于之前的段,也就是递增。
其实要想实现某个需求,背后的方式有很多。如何去选择适合,最优的方案这个是比较考验大家平时的积累和技术的广度。你得知道每种方案的原理是什么,差异点在哪,哪种成本更低,哪种能够完全符合业务需求。
原创:架构摆渡人(公众号ID:jiagoubaiduren),欢迎分享,转载请保留出处。
本文已收录至学习网站 http://cxytiandi.com/ ,里面有Spring Boot, Spring Cloud,分库分表,微服务,面试等相关内容。