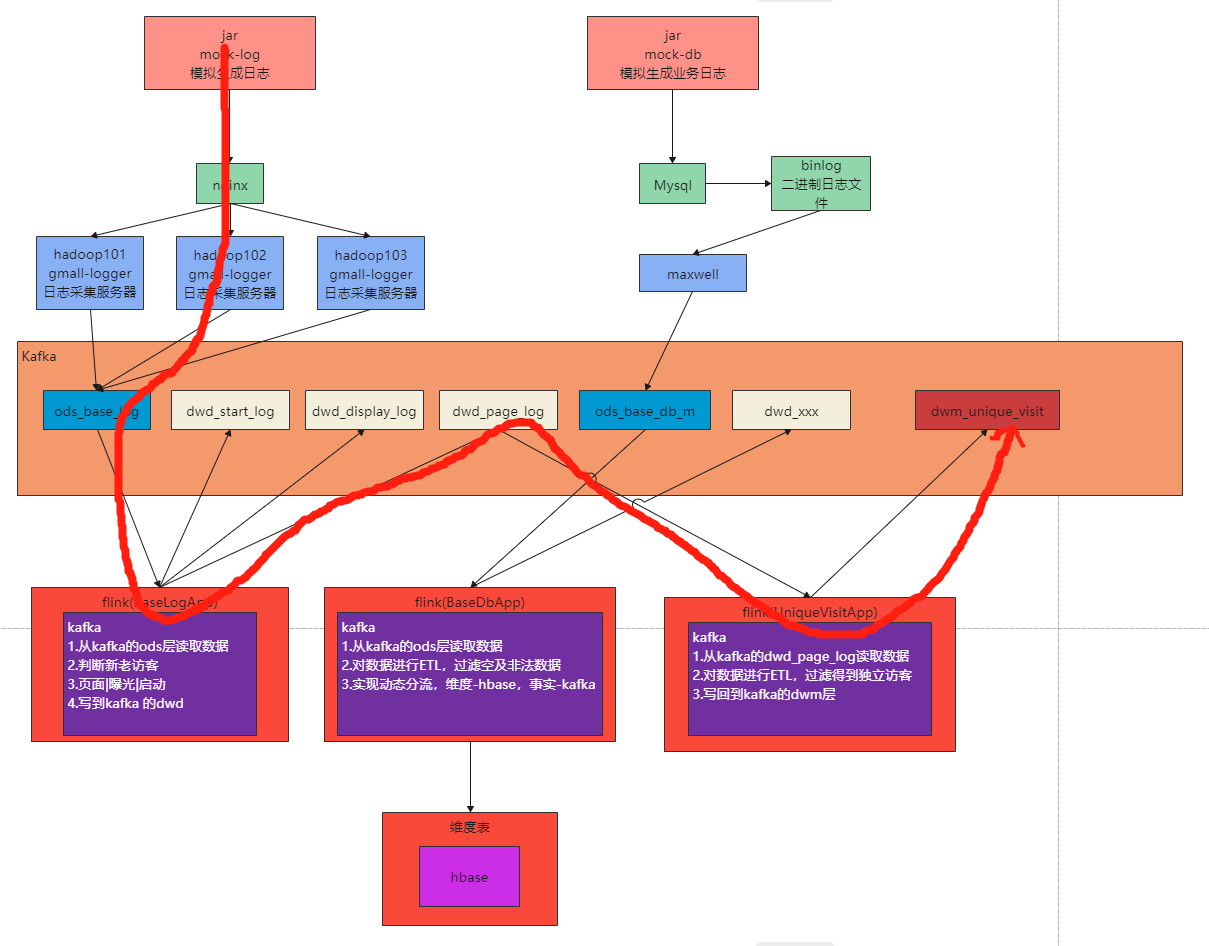
在上6节当中,我们已经完成了从ods层到dwd层的转换,包括日志数据和业务数据,下面我们开始做dwm层的任务。
DWM 层主要服务 DWS,因为部分需求直接从 DWD 层到DWS 层中间会有一定的计算量,而且这部分计算的结果很有可能被多个 DWS 层主题复用,所以部分 DWD 会形成一层 DWM,我们这里主要涉及业务:
-
访问UV计算
-
跳出明细计算
-
订单宽表
-
支付宽表
UV,全称是 Unique Visitor,即独立访客,对于实时计算中,也可以称为 DAU(Daily Active User),即每日活跃用户,因为实时计算中的uv通常是指当日的访客数。那么如何从用户行为日志中识别出当日的访客,那么有两点:
-
其一,是识别出该访客打开的第一个页面,表示这个访客开始进入我们的应用
-
其二,由于访客可以在一天中多次进入应用,所以我们要在一天的范围内进行去重
代码,新建任务UniqueVisitApp.java,我们要从kafka的ods层消费数据,主题为:dwd_page_log
package com.zhangbao.gmall.realtime.app.dwm;
import com.alibaba.fastjson.JSON;
import com.alibaba.fastjson.JSONObject;
import com.zhangbao.gmall.realtime.utils.MyKafkaUtil;
import org.apache.flink.configuration.Configuration;
import org.apache.flink.runtime.state.filesystem.FsStateBackend;
import org.apache.flink.streaming.api.CheckpointingMode;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.connectors.kafka.FlinkKafkaConsumer;
/**
* @author: zhangbao
* @date: 2021/9/12 19:51
* @desc: uv 计算
**/
public class UniqueVisitApp {
public static void main(String[] args) {
StreamExecutionEnvironment env = StreamExecutionEnvironment.createLocalEnvironmentWithWebUI(new Configuration());
//设置并行度
env.setParallelism(4);
//设置检查点
env.enableCheckpointing(5000, CheckpointingMode.EXACTLY_ONCE);
env.getCheckpointConfig().setCheckpointTimeout(60000);
env.setStateBackend(new FsStateBackend("hdfs://hadoop101:9000/gmall/flink/checkpoint/uniqueVisit"));
//指定哪个用户读取hdfs文件
System.setProperty("HADOOP_USER_NAME","zhangbao");
//从kafka读取数据源
String sourceTopic = "dwd_page_log";
String group = "unique_visit_app_group";
FlinkKafkaConsumer<String> kafkaSource = MyKafkaUtil.getKafkaSource(sourceTopic, group);
DataStreamSource<String> kafkaDs = env.addSource(kafkaSource);
//数据转换
SingleOutputStreamOperator<JSONObject> jsonObjDs = kafkaDs.map(obj -> JSON.parseObject(obj));
jsonObjDs.print("jsonObjDs >>>");
try {
env.execute("task uniqueVisitApp");
} catch (Exception e) {
e.printStackTrace();
}
}
}测试从kafka消费数据
-
启动服务:zk,kf,logger.sh ,hadoop
-
运行任务:BaseLogTask.java,UniqueVisitApp.java
-
执行日志生成服务器
-
查看控制台输出
目前任务执行流程
UniqueVisitApp程序接收到的数据
{
"common": {
"ar": "440000",
"uid": "48",
"os": "Android 11.0",
"ch": "xiaomi",
"is_new": "0",
"md": "Sumsung Galaxy S20",
"mid": "mid_9",
"vc": "v2.1.134",
"ba": "Sumsung"
},
"page": {
"page_id": "login",
"during_time": 4621,
"last_page_id": "good_detail"
},
"ts": 1631460110000
}从kafka的ods层取出数据之后,就该做具体的uv处理了。
1.首先用 keyby 按照 mid 进行分组,每组表示当前设备的访问情况
2.分组后使用 keystate 状态,记录用户进入时间,实现 RichFilterFunction 完成过滤
3.重写 open 方法用来初始化状态
4.重写 filter 方法进行过滤
-
可以直接筛掉 last_page_id 不为空的字段,因为只要有上一页,说明这条不是这个用户进入的首个页面。
-
状态用来记录用户的进入时间,只要这个 lastVisitDate 是今天,就说明用户今天已经访问过了所以筛除掉。如果为空或者不是今天,说明今天还没访问过,则保留。
-
因为状态值主要用于筛选是否今天来过,所以这个记录过了今天基本上没有用了,这里 enableTimeToLive 设定了 1 天的过期时间,避免状态过大。
package com.zhangbao.gmall.realtime.app.dwm;
import com.alibaba.fastjson.JSON;
import com.alibaba.fastjson.JSONObject;
import com.zhangbao.gmall.realtime.utils.MyKafkaUtil;
import org.apache.flink.api.common.functions.RichFilterFunction;
import org.apache.flink.api.common.state.StateTtlConfig;
import org.apache.flink.api.common.state.ValueState;
import org.apache.flink.api.common.state.ValueStateDescriptor;
import org.apache.flink.api.common.time.Time;
import org.apache.flink.configuration.Configuration;
import org.apache.flink.runtime.state.filesystem.FsStateBackend;
import org.apache.flink.streaming.api.CheckpointingMode;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.datastream.KeyedStream;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.connectors.kafka.FlinkKafkaConsumer;
import java.text.SimpleDateFormat;
import java.util.Date;
/**
* @author: zhangbao
* @date: 2021/9/12 19:51
* @desc: uv 计算
**/
public class UniqueVisitApp {
public static void main(String[] args) {
//webui模式,需要添加pom依赖
StreamExecutionEnvironment env = StreamExecutionEnvironment.createLocalEnvironmentWithWebUI(new Configuration());
// StreamExecutionEnvironment env1 = StreamExecutionEnvironment.createLocalEnvironment();
//设置并行度
env.setParallelism(4);
//设置检查点
env.enableCheckpointing(5000, CheckpointingMode.EXACTLY_ONCE);
env.getCheckpointConfig().setCheckpointTimeout(60000);
env.setStateBackend(new FsStateBackend("hdfs://hadoop101:9000/gmall/flink/checkpoint/uniqueVisit"));
//指定哪个用户读取hdfs文件
System.setProperty("HADOOP_USER_NAME","zhangbao");
//从kafka读取数据源
String sourceTopic = "dwd_page_log";
String group = "unique_visit_app_group";
FlinkKafkaConsumer<String> kafkaSource = MyKafkaUtil.getKafkaSource(sourceTopic, group);
DataStreamSource<String> kafkaDs = env.addSource(kafkaSource);
//数据转换
SingleOutputStreamOperator<JSONObject> jsonObjDs = kafkaDs.map(obj -> JSON.parseObject(obj));
//按照设备id分组
KeyedStream<JSONObject, String> keyByMid = jsonObjDs.keyBy(jsonObject -> jsonObject.getJSONObject("common").getString("mid"));
//过滤
SingleOutputStreamOperator<JSONObject> filterDs = keyByMid.filter(new RichFilterFunction<JSONObject>() {
ValueState<String> lastVisitDate = null;
SimpleDateFormat sdf = null;
@Override
public void open(Configuration parameters) throws Exception {
//初始化时间
sdf = new SimpleDateFormat("yyyyMMdd");
//初始化状态
ValueStateDescriptor<String> lastVisitDateDesc = new ValueStateDescriptor<>("lastVisitDate", String.class);
//统计日活dau,状态数据保存一天,过一天即失效
StateTtlConfig stateTtlConfig = StateTtlConfig.newBuilder(Time.days(1)).build();
lastVisitDateDesc.enableTimeToLive(stateTtlConfig);
this.lastVisitDate = getRuntimeContext().getState(lastVisitDateDesc);
}
@Override
public boolean filter(JSONObject jsonObject) throws Exception {
//上一个页面如果有值,则不是首次访问
String lastPageId = jsonObject.getJSONObject("page").getString("last_page_id");
if(lastPageId != null && lastPageId.length()>0){
return false;
}
//获取用户访问日期
Long ts = jsonObject.getLong("ts");
String mid = jsonObject.getJSONObject("common").getString("mid");
String lastDate = sdf.format(new Date(ts));
//获取状态日期
String lastDateState = lastVisitDate.value();
if(lastDateState != null && lastDateState.length()>0 && lastDateState.equals(lastDate)){
System.out.println(String.format("已访问! mid:%s,lastDate:%s",mid,lastDate));
return false;
}else {
lastVisitDate.update(lastDate);
System.out.println(String.format("未访问! mid:%s,lastDate:%s",mid,lastDate));
return true;
}
}
});
filterDs.print("filterDs >>>");
try {
env.execute("task uniqueVisitApp");
} catch (Exception e) {
e.printStackTrace();
}
}
}注:1.在测试时,发现uv没有数据,所以把BaseLogTask任务的侧输出流改一下,如下图所示:
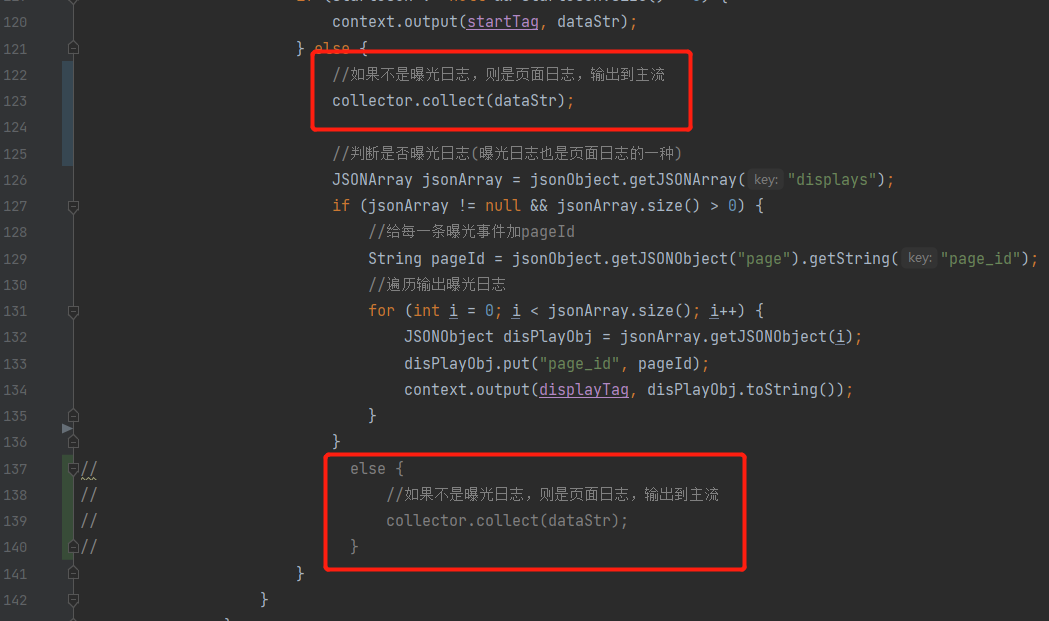
2.webui模式添加pom依赖
<!-- flink webui -->
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-runtime-web_2.12</artifactId>
<version>1.12.0</version>
</dependency>-
启动zk,kafka,logger.sh,hdfs,BaseLogTask,UniqueVisitApp
-
执行流程
-
模拟生成的日志jar >> nginx >> 日志采集服务 >> kafka(ods) >> baseLogApp(分流) >> kafka(dwd) >> UniqueVisitApp(独立访客) >> dwm_unique_visit
-