使用 TensorFlow和 TensorFlow Hub( TFHUB)构建渐进式增长生成对抗网络( Progressive GAN, PGGAN或 PROGAN)——一种能够生成全高清的具有照片级真实感图像的前沿技术。这项技术在顶级机器学习会议ICLR2018上提出时引起了轰动,以至于谷歌立即将其整合为 TensorFlow Hub中的几个模型之一。这项技术被深度学习的鼻祖之一 Yoshua Bengio称赞为“好得令人难以置信”,在其发布后,立即成为学术报告和实验项目的最爱。
本章将给出如下两个主要例子。
- PGGAN的关键创新部分的代码,具体来说,就是平滑地增大高分辨率层以及前面列出的其他3个创新点。
- 谷歌在TFHub上提供了一个预训练好的且易于下载的实现。TFHub是一个用于机器学习模型的新的集中式仓库,类似于 Docker Hub或 Conda以及PyPI。此复现能够进行潜在空间插值以控制生成样本的特征。这会简要涉及生成器潜在空间中的种子向量,以便获得想要的图片。
这里使用TFHub而不是像其他章那样从头开始实现 PGGAN,原因有如下3个。
- 尤其是对于从业人员,我们希望确保你了解到可以加快工作流程的软件工程最佳实践。想尝试快速用GAN解决问题吗?使用TFHub上的其中一种实现即可。TFHub现在有更多的实现,包括许多参考实现。因为这就是机器学习的发展方式——尽可能地使机器学习自动化,这样我们就可以专注于最重要的事情:产生影响。谷歌的 Cloud Automl和亚马逊的 Sagemaker是这种趋势的主要例子,甚至 Facebook最近都推出了 PyTorch Hub,所以两种主要机器学习框架现在都有一个仓库了。
- NVIDIA研究人员花了一到两个月的时间来运行最初的 PGGAN。任何人想独自运行它都是不切实际的,特别是在进行实验或出现错误情况下。TFHub也提供了一个完全可训练的PGGAN,因此,如果想利用做计算的日子来做其他事,你也可以从头训练!
- TFHub使我们可以跳过无关紧要的样板代码,而专注于实现重要的想法。
第2章中有一个较低分辨率的空间(潜在空间),可以为输出提供随机初始值,对于DCGAN以及PGGAN,初始训练的潜在空间具有语义上有意义的性质。这意味着可以找到向量偏移量,例如,将眼镜引入人脸图像,相同的偏移量会在新的图像中引入眼镜。还可以选择两个随机向量,然后在它们之间每次移动相等的增量,从而逐渐平滑地获得与第二个向量匹配的图像。
上述方法称为插值,如下图所示。(我们可以进行潜在空间插值,因为发送给生成器的潜在向量会产生一致的结果,这种结果在某些方面是可以预测的。如果考虑潜在向量的变化,不仅生成过程是可预测的,输出也不是参差不齐的,对微小的变化也不会剧出剧烈的反应。例如,想要一幅由两张脸混合生成的图像,在两个向量的平均值附近搜索即可)正如 BIGGAN论文的作者所说,从一个向量到另一个向量的有意义的转换表明GAN已经学习到了一些底层结构。

在前面的章节中,我们已经了解到使用GAN可以轻松实现哪些结果,难以实现哪些结果,还对模式崩溃(只展示了总体分布的几个样本)和缺乏收敛性(导致结果质量较差的原因之一)有了一定的了解。
芬兰 NVIDIA的一个团队发表了一篇论文,这篇论文成功击败了之前的许多前沿论文,这就是 Tero Karras等人所撰写的 Progressive Growing of GAN for Improved Qualin Stability, and Variation该论文有4个基本的创新点,让我们依次来看看。
1. 高分辨率层的渐进增长和平滑在深入研究 PGGAN的作用之前,我们先来看一个简单的类比!想象一下,俯瞰某处山区:山区有许多山谷,那里有漂亮的小溪和村庄,非常宜居。但是其间也会有许多山坡,它们崎岖不平,而且由于天气原因,通常不宜居住。我们用山谷和山坡类比损失函数,希望沿着山坡进入更好的山谷,以最小化损失。
我们可以把训练想象成将登山者放到这处山区的任意地方,让他顺着山坡往下的路进入山谷——这就是随机梯度下降所做的。但是,假设从一处非常复杂的山脉开始,登山者不知道该往哪个方向走。他周围的地势是崎岖不平的,以至于他很难弄清楚哪里是有宜居地的最宜人、最低的山谷。假如我们拉远画面并降低山脉的复杂度,使登山者对这一特定区域有一个高层次的了解。
随着登山者越来越接近山谷,我们再通过放大地形增加复杂性。这样不再只看到租糙像素化的构造,而是可以看到更精细的细节。这种方法的优势在于,当登山者沿着斜坡下山时,他可以很容易地进行一些小的优化以使旅行更加轻松,例如,他可以沿着一条干涸的小溪行走以更快地到达山谷。这就是渐进式増长(progressive growing):随着登山者的行进,提高地形的分辨率。
然而,如果你玩过一款沙箱类游戏,或者带着3D眼镜在谷歌地图上快速移动,就会知道快速增加周围地形的分辨率是惊心动魄且不愉快的——所有物体突然映入眼帘。因此,随着登山者越来越接近目标,我们渐进式地、平滑地并慢慢地引入更多的复杂性。
用专业术语来说,就是训练过程正在从几个低分辨率的卷积层发展到多个高分辨率的层。先训练早期的层,再引入更高分辨率的层——高分辨率层中的损失空间很难应对。从简单的(如经过几步训练得到的4x4)开始,最后到更复杂的(如经过多个时期训练的1024×1024),如下图所示。能看到如何从平滑的山脉开始,通过放大逐渐增加复杂性吗?实际上这就是添加额外层对损失函数的影响。这很方便,因为山区(损失函数)在平坦的情况下更容易导航。可以这样认为:当结构更复杂时(b)损失函数凹凸不平且难以导航(d),因为参数太多(尤其是在早期层中)会产生巨大的影响——通常会增加问题的维数。但是,如果最初删除部分复杂度(a),就可以在早期获得更容易导航的损失函数(c),并且只有我们确信自己处于损失空间近似正确的部分,才会増加复杂性。只有这样,オ能从(a)和(c)转变为(b)和(d)
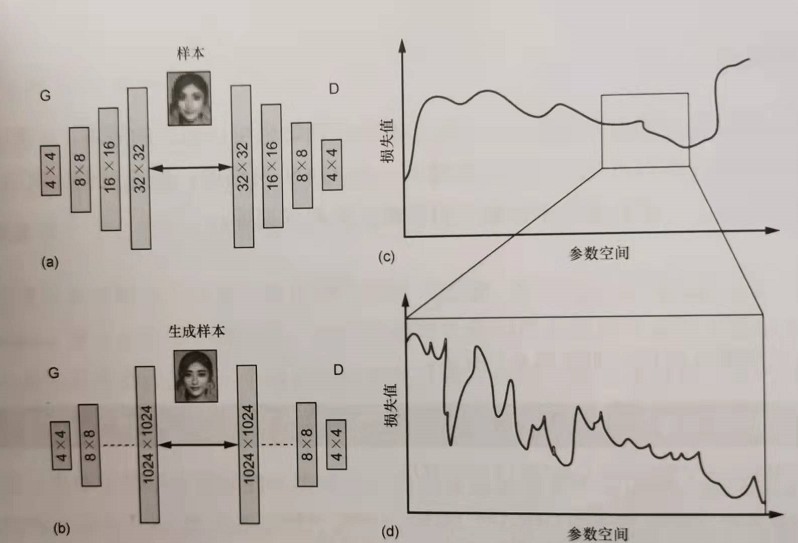
这种情况下的问题是,即便一次增加一个层(例如,从4x4到8×8),也会给训练带来巨大的影响。 PGGAN所做的就是平滑地增加这些层,如下图所示,训练了足够送代次数的16×16分辨率后(a),在生成器(G)中引入了另一个转置卷积,在判别器(D)中引入了另一个卷积,使G和D之间的“接口”为32×32。生成32×32层有两条路径:(1-a)乘以 简单地以最近邻插值增加尺度的层,这没有任何经过训练的参数,比较直接;(a)乘以额外的转置卷积的输出层,这需要训练,但最后会表现得更好。二者相连,以形成新的32×32的生成图像,a从0到1线性缩放,当a达到1时,从16×16开始的最近邻插值将完全为零。这种平滑的过渡机制极大地稳定了PGGAN架构以给系统适应更高的分辨率的时间。
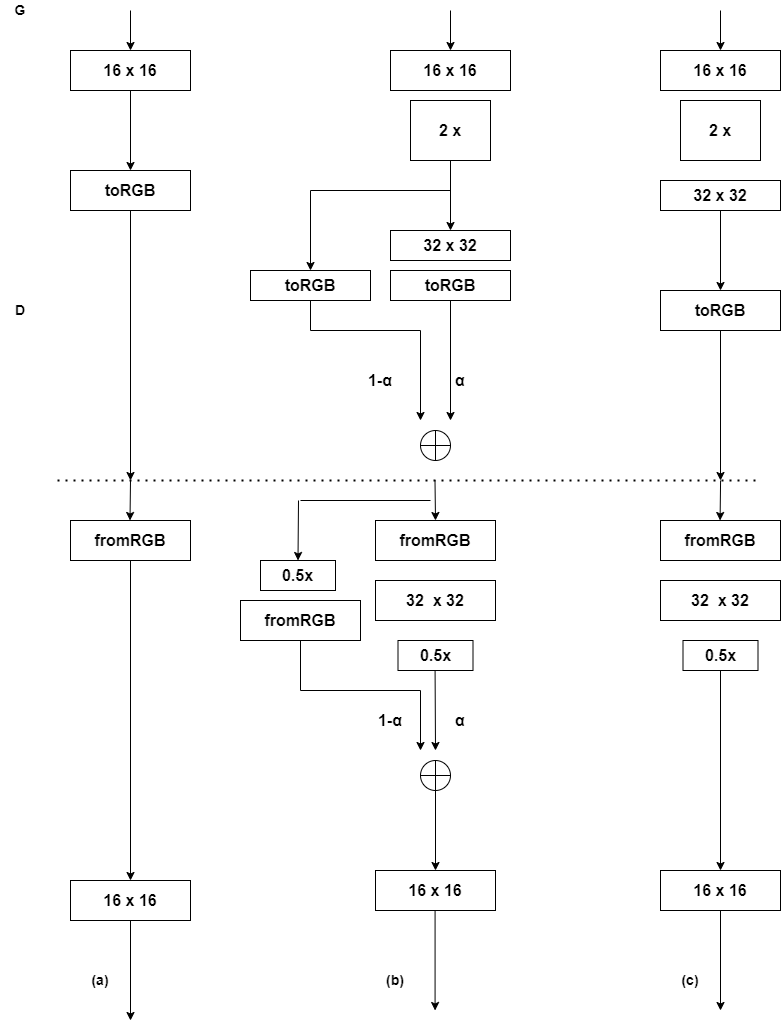
但不是立即跳到该分率,而是在通过参数\(\alpha\)(介于0和1之间,从0到1线性缩放)平滑地增加高分率的新层。\(\alpha\)会影响旧的但扩大规模的层和新生成的更大的层的利用程度。虚线下方的D部分,只是简单地缩小至1/2,再平滑地注入训练过的层以用于鉴別,如下图(b)所示,如果我们对这一新层有信心,保持在32×32(下图(c)),然后在恰当地训练好32×32分辨率的层之后,就准备再次增长。
2. 示例实现渐进式平滑增长的代码如下所示。
import tensorflow as tf
import keras as K
def upscale_layer(layer, upscale_factor):
height = layer.get_shape()[1]
width = layer.get_shape()[2]
size = (upscale_factor * height, upscale_factor * width)
upscaled_layer = tf.image.resize_nearest_neighbor(layer, size)
return upscaled_layer
def smoothly_merge_last_layer(list_of_layers, alpha):
last_fully_trained_layer = list_of_layers[-2]#如果使用的是tf而不是keras,要记得scope
last_layer_upscaled = upscale_layer(last_fully_trained_layer, 2)#现在有了最初训练过的层
larger_native_layer = list_of_layers[-1]#新加的层还没有完全训练
#assert(断言)用于判断一个表达式,在表达式条件为 false 的时候触发异常
#这确保可以运行合并代码
assert larger_native_layer.get_shape() == last_layer_upscaled.get_shape()
new_layer = (1-alpha) * upscaled_layer + larger_native_layer * alpha#利用广播功能
return new_layer
人们通常希望能够生成真实数据集中所有人的脸,而不是只能生成某个女人的一张照片。为此, Karras等人创造了一种方法,使判別器可以辨别所获取的样本是否足够多样。这种方法本质上是为判别器计算了一个额外的标量统计量。此统计量是生成器生成的或来自真实数据的小批量中所有像素的标准偏差。
这是一个非常简单而优雅的解决方案:现在判别器需要学习的是,如果正在评估的批量中图像的标准偏差很低,则该图像很可能是伪造的——因为真实数据所具有的偏差较大。生成器别无选择,只能增加生成样本的偏差,才有机会欺骗判别器。
上述内容理解起来很直观,技术实现起来也非常简单,因为它只应用在判别器中。考虑到我们还想最小化可训练参数的数量,只添加一个额外的数字似乎就够了。该数字作为特征图附加到判别器上——维度或tf. shape列表中的最后一个数字。
具体步骤如下。
(1)[4D—>3D] 计算批次中所有图像和所有通道(高度、宽度和颜色)的标准偏差,然后得到关于每个像素和每个通道的标准偏差的一个图像。
(2)[3D—>2D] 对所有通道的标准差取均值,得到像素的一个特征图或标准差矩阵,但是颜色通道折叠了。
(3)[2D一>标量/0D] 对前一个矩阵内所有像素的标准偏差取均值,以获得一个标量值。
def minibatch_std_layer(layer, group_size=4):
#如果使用的是Tensorflow而不是Keras,那么scope一个小批量组必须被group_size所整除(或<=)
group_size = K.backend.minimum(group_size, tf.shape(layer)[0])
#获得一些形状信息,以便快速调用和确保默认值
#从tf.shape中得到输入,因为pre-image维度通常在图形执行之前转换为None
shape = list(K.int_shape(input))
shape[0] = tf.shape(input)[0]
#改变形状,以便在小批量的水平上进行操作
#假设层是[Group(G), Mini-batch(M), Width(W), Height(H), Channel(C)]
minibatch = K.backend.reshape(layer, (group_size, -1, shape[1], shape[2], shape[3]))
#将均值集中于组[M, W, H, C]
minibatch -= tf.reduce_mean(minibatch, axis=0, keepdims=True)
#计算组[M, W, H, C]的方差
minibatch = tf.reduce_mean(K.backend.square(minibatch), axis = 0)
#计算组 [M,W,H,C] 的标准偏差
minibatch = K.backend.square(minibatch + 1e8)
#对特征图和像素取平均值 [M,1,1,1]
minibatch = tf.reduce_mean(minibatch, axis=[1,2,4], keepdims=True)
#转换标量值以适应组和像素
minibatch = K.backend.tile(minibatch, [group_size, 1, shape[2], shape[3]])
#附加一个特征图
return K.backend.concatenate([layer, minibatch], axis=1)
需要确保将所有权重\((w)\)归一化\((w')\)在一定范围内,这样\(w'=w/c\)就需要一个常数c,这个常数c对于每一层都是不同的,具体取决于权重矩阵的形状。这也确保了如果任何参数需要采取更大的操作来达到最优(因为它们往往变化更大),那么使用相关参数可以很容易做到。
RMSProp等人使用简单的标准正态初始化,然后在运行时缩放每层的权重。Adam允许不同参数的学习率不同,但它有一个陷阱。Adam通过参数的估计标准偏差来调整反向传播的梯度,从而确保该参数的大小与更新无关。Adam在不同的方向上有不同的学习率,但并不总是考虑动态范围——在给定的小批量中,维度或特征的变化有多大。这似乎解决了一个类似于权重初始化的问题。
def equalize_learning_rate(shape, gain, fan_in=None):
#默认为所有形状维度减去特征图维数的乘积——这给出了每个神经元的传入连接数
if fan_in is None: fan_in = np.prod(shape[:-1])
#这使用了初始化常量
std = gain / K.sqrt(fan_in)
#在调整之外创建一个常量
wscale = K.constant(std, name='wscale', dtype=np.float32)
#获取权重值,然后使用广播机制应用调整
adjusted_weights = K.get_value('layer', shape=shape,
initializer=tf.initializers.random_normal()) * wscale
return adjusted_weights
归一化特征的动机是为了使训练更加稳定。大多数网络都使用了某种形式的归一化。通常使用的是批归一化或其虚拟版本。下表部分概述了迄今为止在GAN中使用的归一化技术。为了使批归一化及其虚拟版本能够等效工作,我们必须拥有大量的小批处理,以便求各个样本的平均值。
基于“所有主要的实现使用了归一化”这一事实,我们可以断定它显然很重要,但是为什么不直接使用标准的批归一化呢?这是因为在想要达到的分辨率下,批归一化过于占用内存。我们必须想出使用少量样本(适用于使用并行网络图的GPU显存内存)仍然可以正常工作的一些办法。至此,我们了解了像素级特征归一化的需求从何而来以及为什么要进行像素级特征归一化。
如果从算法角度说,像素级归一化将在输入被送到下一层之前在每一层获得激活幅度。
像素级特征归一化
对每个特征图,执行
在位置(x,y)上获取该特征图(fm)的像素值。
为每个(x,y)构造一个向量,其中
a. \(v_{0, 0}=[fm_1的(0, 0)值,fm_2的(0, 0)值,...,fm_n的(0, 0)]值\)。
b. \(v_{0, 1}=[fm_1的(0, 1)值,fm_2的(0, 1)值,...,fm_n的(0, 1)]值\)。
...
c. \(v_{n, n}=[fm_1的(n, n)值,fm_2的(n, n)值,...,fm_n的(n, n)]值\)。
将步骤2中定义的每个向量\(v_{i,i}\)归一化得到单位标准值,称之为\(n_{i,i}\)。
将原来的张量形状传递到下一层。
结束
像素特征归一化的过程如下图所示。将图像中的所有点(步骤1)映射到一组向量(步骤2),然后对其进行归一化,以使它们都在同一范围内(通常在高维空间中介于0和1之间),这就是步骤3。
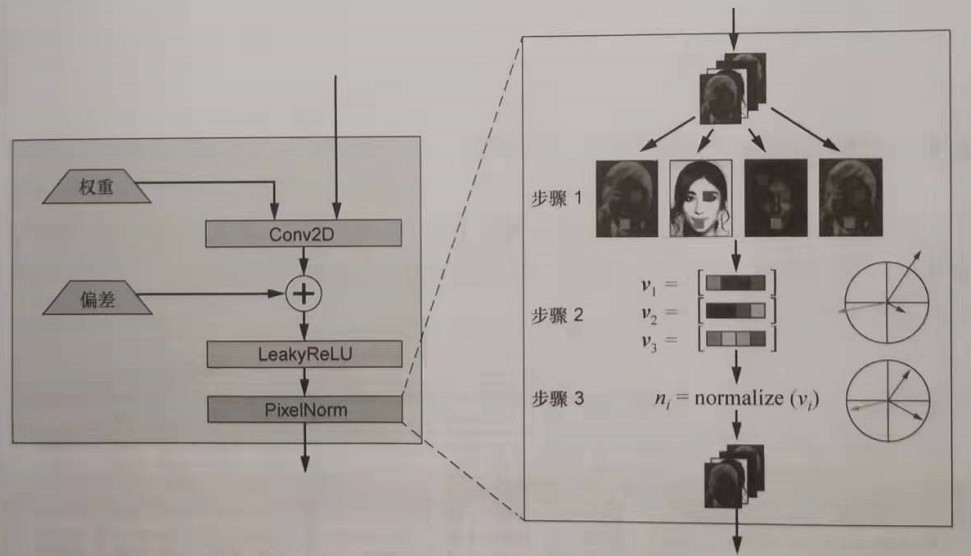
步骤3的准确描述如下式所示。
\[n_{(x, y)}=a_{(x, y)} / \sqrt{\frac{1}{N} \sum_{j=0}^{N-1}\left(a_{x, y}^{\prime}\right)^{2}+\varepsilon} \]上式将图中步骤2中构造的每个向量归ー化(除以根号下的表达式)。该表达式只是特定(x,y)像素每个平方值的平均值。另外增加了一个小的噪声项(\(\varepsilon\))。这只是确保不被零除的一种方法。
最后要注意的是,像素级特征归一化这一技巧仅用于生成器,因为两个网络都使用时,激活幅度的爆炸会导致军备竞赛(预防式的对抗)。
def pixelwise_feat_norm(inputs, **kwargs):
normalization_constant = K.backend.sqrt(K.backend.mean(
inputs**2, axis=-1, keepdims=True) + 1.0e-8)
return inputs / normalization_constant
导入hub模块并调用正确的URL后, Tensorflow会自行下载并导入模型,然后就可以开始使用了。这些模型在用于下载模型的同一个URL中有很好的文档记录,只需将它们输入测览器中即可。实际上,要获得经过预训练的 PGGAN,输入一个 import语句和一行代码即可。
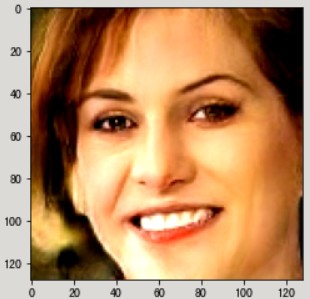
以下代码给出的是一个完整的代码示例,该代码根据latent_ vector中指定的随机种子生成一张人脸。输出如下图所示。
import matplotlib.pyplot as plt
import tensorflow as tf
#先安装pip install tensorflow_datasets -i https://pypi.douban.com/simple
#再安装pip install tensorflow_hub -i https://pypi.douban.com/simple
import tensorflow_hub as hub
import os
import getpass
#下载位置默认为本地临时目录
#但可以通过设置环境变量 TFHUB_CACHE_DIR进行自定义
os.environ["TFHUB_CACHE_DIR"] = "E:\keras\TFhub"
with tf.Graph().as_default():
module_url = 'E:./progan-128_1'#从本地中导入PGGAN
print("Loading model from {}".format(module_url))
module = hub.Module(module_url)
latent_dim = 512#运行时采样的潜在维度
latent_vector = tf.random.normal([1, latent_dim], seed=222)#改变种子得到不同人脸
interpolated_image = module(latent_vector)#使用该模块从潜在空间生成图像
#运行tf session得到(1, 128, 128, 3)的图像
with tf.compat.v1.Session() as session:
session.run(tf.compat.v1.global_variables_initializer())
image_out = session.run(interpolated_image)
plt.imshow(image_out.reshape(128, 128, 3))
plt.show()
- 借助最先进的 PGGAN技术,我们可以实现百万像素的合成图像。
- PGGAN技术具有4个关键的训练创新。
- 渐进式和平滑地增大高分辨率的层。
- 小批处理标准偏差,以强制所生成的样本多样化。
- 均衡学习率,确保在每个方向上采取适当大小的学习步骤。
- 像素特征向量归一化,确保生成器和判别器在竟争中不会失控。