随着图形硬件变得越来越通用和可编程化,采用实时3D图形渲染的应用程序已经开始探索传统渲染管线的替代方案,以避免其缺点。其中一项最流行的技术就是所谓的延迟渲染。这项技术主要是为了支持大量的动态灯光,而不需要一套复杂的着色器程序。

为了迎接这一章的项目,会对原来的代码有许多改动,并且会有许多引申的内容。
学习目标:
- 了解延迟渲染的工作流程
- 了解Pre-Z Pass、Reversed-Z
- 了解如何对G-Buffer进行优化
- 了解线性空间、Gamma空间和sRGB空间
DirectX11 With Windows SDK完整目录
Github项目源码
欢迎加入QQ群: 727623616 可以一起探讨DX11,以及有什么问题也可以在这里汇报。
前向渲染(Forward Rendering)的问题在设计渲染器时,最重要的一个方面是确定如何处理光照。这非常重要,因为它需要进行涉及到光照强度以及几何体表面一点的反射颜色的计算。通常它包含如下步骤:
- 基于光照类型和衰弱属性,确定哪些光照需要应用到当前的特定像素上
- 使用材质、表面属性以及刚才确定需要用到的光照来为每个像素计算颜色
- 确定这些像素是否在阴影中,即光照是否能打到该像素。
这种传统的处理方式通常叫做前向渲染。通过前向渲染,几何体使用大量存储在顶点属性数据、纹理、常量缓冲区中的表面属性来进行渲染。然后,根据输入的几何体对每个像素进行光栅化操作,结合材质数据对一个或多个灯光进行光照计算。最终的计算结果将输出到每个像素中,并且可能与之前存在渲染目标的结果进行累加。这种方式是直接且直观的,在可编程图形硬件出现之前,它是实时3D图形渲染的绝大部分方式。早期固定管线的GPU支持三种不同的光照类型:点光源、聚光灯、方向光。
而随着实时渲染引擎的发展以适应可编程硬件和更复杂的场景,这些基本的光照类型由于其灵活性和普遍性,大部分都被保留了下来。然而,它们的使用方式已经开始显示出它们的年迈。这是因为在现代硬件和API下,当它们开始支持大量的动态光源时,前向渲染暴露出几项关键的弱点:
第一个缺点是,光源的使用与场景中绘制的几何体的粒度(对象)挂钩。换句话说,当我们开启一个点光源,我们必须将其应用到在任何特定的绘制调用期间经过光栅化后的所有几何体当中。一开始我们可能注意不到这会带来什么样的问题,尤其是我们在场景中只是添加了少数几盏灯光。然而随着光源数目的增长,着色器的计算量开始剧增,选择性地应用光源就开始变得重要了,这么做是为了减少像素着色器中光照计算的执行次数。但因为我们只能在每次绘制之间完成光照的修改,导致我们在剔除不需要的灯光时受到了限制。那些灯光本应该只会影响到光栅化中的一小部分几何体的情况,我们却又不得不将那盏灯光应用到所有的几何体。虽然我们可以将场景中的网格分割成更小的部分来提升粒度,但这增加了当前帧的绘制调用的数目(从而导致CPU开销的提升)。这还增加了需要确定光照是否影响网格的相交测试的数目,给CPU带来了更大的负担。另一个相关的后果是我们在单批次渲染多个几何体实例的能力将会降低,因为单批次中所有几何体实例所使用的灯光数目必须是相同的,这些实例可能会出现在场景中的不同位置,它们本应该会受到不同灯光组合的影响。
另一个前向渲染的主要缺点是着色器程序的复杂性问题。为了控制大量的灯光和各种材质变化的灯光类型,可能会导致所需的着色器排列组合产生的数量激增。大量的着色器排列组合不是我们所期望的,因为这会增加内存的使用,以及着色器程序之间切换的开销。由于依赖于这些组合怎么被编译,它们还会显著增加编译的次数。使用多着色器程序的另一种选择是使用动态流控制,这将影响GPU的性能。另一种方法是一次只渲染一个灯光,并将结果添加到渲染目标中,这称为多通道渲染(multi-pass rendering)。然而,这种方法需要为多次变换和光栅化几何体付出代价。即便忽略掉与许多排列组合相关的问题,生成的像素着色器程序本身也可能变得非常昂贵和复杂。这是因为需要评估材质属性并对所有活动的光源执行必要的照明和阴影计算。这会使得着色器程序难以编写、维护和优化。它们的性能还与场景的过度绘制有关,因为过度绘制会产生甚至不可见的着色像素。一个只使用z深度的预处理可以显著减少过度绘制,但它的效率受到硬件中Hi-Z单元的实现的限制。着色器执行也会被浪费,因为像素着色器必须在至少2x2个四边形中进行,这对于具有许多小三角形的高度细分场景尤其不利。
这些缺陷共同导致很难在场景中扩展动态光照的数目,同时为实时应用保持足够的性能。然而如果你非常仔细地去看这些描述,你将会注意到所有这些缺陷根源自前向渲染固有的一个主要问题:光照与场景几何图形的光栅化紧密耦合。如果我们将这两个步骤进行解耦,我们就有可能限制或完全绕过其中的一些缺点。仔细观察光照过程中的第二步,我们可以发现为了计算光照,需要利用到材质属性和几何体表面属性。这意味着如果我们有这样一个步骤,在渲染过程中将所有需要的这些属性放入一个缓冲区中(我们通常叫它为几何缓冲区,或G-Buffer),紧接着我们就可以对所有场景中的灯光进行遍历,并为每个像素计算出光照相关的值,这正是延迟渲染的前提。
使用RTX 2070 Mobile渲染带1024点光源的Sponza场景,即便是开启了预视锥体剔除,总体*均帧数仅有35帧:
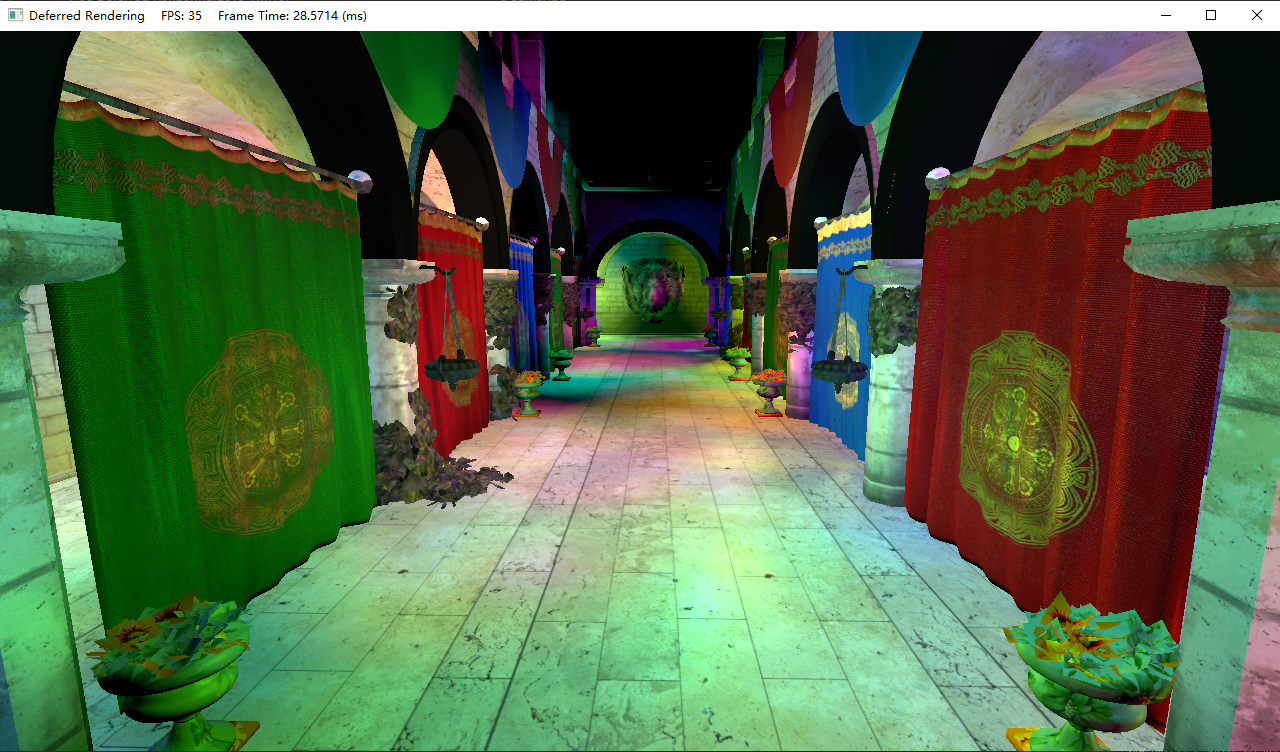
前向渲染也是有比较大的优化空间的,但现阶段我们只讲能够很快实现的部分。
在绘制一个复杂场景的时候,可能会出现某些区域三角形反复覆盖绘制的情况,增加了很多不必要的绘制。为此我们可以在进行正式渲染前,先对场景中的物体只做深度测试,不执行像素着色阶段;然后第二遍场景绘制的时候只绘制和深度缓冲区中深度值相等的像素。这样做可以有效减少像素着色器的执行次数。
Pre-Z Pass在C++端的代码实现也十分简单,具体可以参考项目中的代码。
延迟渲染管线注意:在测试帧数差距时务必使用Release模式。
延迟渲染管线的第一步是几何阶段:渲染所有的场景几何体到G-Buffer当中。这些缓冲区通常由一些渲染目标纹理所组成,但它们的各个通道用于逐像素存储几何体表面信息,例如表面法向量和材质属性等。
第二步是光照阶段。在这一步中,可以将渲染表示为当前光照影响屏幕区域的几何体的过程。对于每个待着色的像素片元,将从G-Buffer中采样几何体的信息,然后与光照的属性结合来确定对于该像素产生的光照贡献值,再与所有其它影响那一像素的光源的贡献值累加到一起,来确定最终表面的发光颜色。
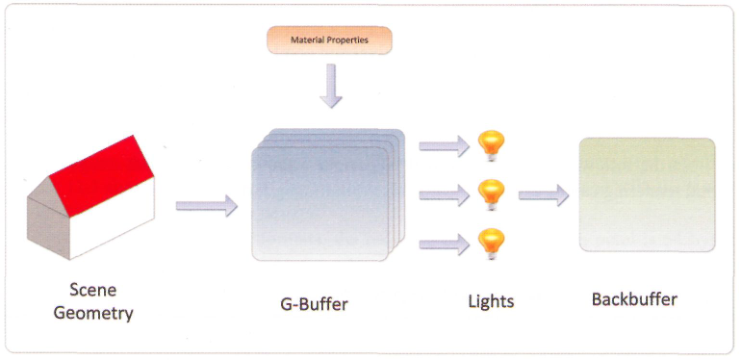
因为延迟渲染避免了前向渲染的主要缺陷(光照与几何体紧密耦合),它拥有下面这些优势:
- 着色器的组合数目将大幅减少,因为光照和阴影的计算可以移动到独立的着色器程序中进行。
- 可以更加频繁地批处理网格实例,因为我们在渲染场景几何体的时候不再需要光照参数。所以,对于网格的所有实例,活动的光源可以不需要相同。
- 不再需要在CPU执行工作来确定哪些灯光影响屏幕的不同区域。取而代之的是,碰撞体或屏幕空间四边形可以光栅化在灯光影响的屏幕部分上。深度和模板测试也可以用于进一步减少着色器执行的次数。
- 总共需要的着色器和渲染框架体系可以被简化,因为光照和几何体已经被解耦了。
这些优势使得延迟渲染在渲染引擎中非常流行。不幸的是,这种方法也会产生一些缺陷:
- 必须有大量的内存和带宽专门用于G-Buffer的生成和采样,因为它需要存储计算该像素所需的任何信息。
- 使用硬件MSAA变得困难,不是说使用延迟渲染就不能使用MSAA了。开启MSAA可能意味着连同G-Buffer的占用空间也会成倍的提升,而且可能带来显著提升的计算负担。
- 透明几何体的处理不能以不透明几何体处理的方式进行,因为它不能被渲染进G-Buffer。又因为G-Buffer仅仅能够保存单个表面的属性,且渲染透明几何体需要计算为多个重叠的逐像素光照,并将计算颜色的结果结合起来。
- 如果使用BRDF材质模型的话,这种方式将变得不再简单,因为计算像素最终的颜色已经被移到光照pass了
现假定我们的场景中只包含一系列的点光源,并且使用的是Phong光照模型,不引入阴影和SSAO,没有透明物体。对于材质,我们只用到漫反射贴图。
在几何阶段,有:
// ConstantBuffers.hlsl
cbuffer CBChangesEveryInstanceDrawing : register(b0)
{
matrix g_WorldInvTransposeView;
matrix g_WorldView;
matrix g_ViewProj;
matrix g_Proj;
matrix g_WorldViewProj;
}
cbuffer CBPerFrame : register(b1)
{
float4 g_CameraNearFar;
uint g_LightingOnly;
uint g_FaceNormals;
uint g_VisualizeLightCount;
uint g_VisualizePerSampleShading;
}
// Rendering.hlsl
//--------------------------------------------------------------------------------------
// 几何阶段
//--------------------------------------------------------------------------------------
Texture2D g_TextureDiffuse : register(t0);
SamplerState g_SamplerDiffuse : register(s0);
struct VertexPosNormalTex
{
float3 posL : POSITION;
float3 normalL : NORMAL;
float2 texCoord : TEXCOORD;
};
struct VertexPosHVNormalVTex
{
float4 posH : SV_POSITION;
float3 posV : POSITION;
float3 normalV : NORMAL;
float2 texCoord : TEXCOORD;
};
VertexPosHVNormalVTex GeometryVS(VertexPosNormalTex input)
{
VertexPosHVNormalVTex output;
output.posH = mul(float4(input.posL, 1.0f), g_WorldViewProj);
output.posV = mul(float4(input.posL, 1.0f), g_WorldView).xyz;
output.normalV = mul(float4(input.normalL, 0.0f), g_WorldInvTransposeView).xyz;
output.texCoord = input.texCoord;
return output;
}
对光照阶段,有:
// Rendering.hlsl
float3 ComputeFaceNormal(float3 pos)
{
return cross(ddx_coarse(pos), ddy_coarse(pos));
}
struct SurfaceData
{
float3 posV;
float3 posV_DX;
float3 posV_DY;
float3 normalV;
float4 albedo;
float specularAmount;
float specularPower;
};
SurfaceData ComputeSurfaceDataFromGeometry(VertexPosHVNormalVTex input)
{
SurfaceData surface;
surface.posV = input.posV;
// 右/下相邻像素与当前像素的位置差
surface.posV_DX = ddx_coarse(surface.posV);
surface.posV_DY = ddy_coarse(surface.posV);
// 该表面法线可用于替代提供的法线
float3 faceNormal = ComputeFaceNormal(input.posV);
surface.normalV = normalize(g_FaceNormals ? faceNormal : input.normalV);
surface.albedo = g_TextureDiffuse.Sample(g_SamplerDiffuse, input.texCoord);
surface.albedo.rgb = g_LightingOnly ? float3(1.0f, 1.0f, 1.0f) : surface.albedo.rgb;
// 将空漫反射纹理映射为白色
uint2 textureDim;
g_TextureDiffuse.GetDimensions(textureDim.x, textureDim.y);
surface.albedo = (textureDim.x == 0U ? float4(1.0f, 1.0f, 1.0f, 1.0f) : surface.albedo);
// 我们没有艺术资产相关的值来设置下面这些,现在暂且设置成看起来比较合理的值
surface.specularAmount = 0.9f;
surface.specularPower = 25.0f;
return surface;
}
//--------------------------------------------------------------------------------------
// 光照阶段
//--------------------------------------------------------------------------------------
struct PointLight
{
float3 posV;
float attenuationBegin;
float3 color;
float attenuationEnd;
};
// 大量的动态点光源
StructuredBuffer<PointLight> g_Light : register(t5);
// 这里分成diffuse/specular项方便后续延迟光照使用
void AccumulatePhong(float3 normal, float3 lightDir, float3 viewDir, float3 lightContrib, float specularPower,
inout float3 litDiffuse, inout float3 litSpecular)
{
float NdotL = dot(normal, lightDir);
[flatten]
if (NdotL > 0.0f)
{
float3 r = reflect(lightDir, normal);
float RdotV = max(0.0f, dot(r, viewDir));
float specular = pow(RdotV, specularPower);
litDiffuse += lightContrib * NdotL;
litSpecular += lightContrib * specular;
}
}
void AccumulateDiffuseSpecular(SurfaceData surface, PointLight light,
inout float3 litDiffuse, inout float3 litSpecular)
{
float3 dirToLight = light.posV - surface.posV;
float distToLight = length(dirToLight);
[branch]
if (distToLight < light.attenuationEnd)
{
float attenuation = linstep(light.attenuationEnd, light.attenuationBegin, distToLight);
dirToLight *= rcp(distToLight);
AccumulatePhong(surface.normalV, dirToLight, normalize(surface.posV),
attenuation * light.color, surface.specularPower, litDiffuse, litSpecular);
}
}
void AccumulateColor(SurfaceData surface, PointLight light,
inout float3 litColor)
{
float3 dirToLight = light.posV - surface.posV;
float distToLight = length(dirToLight);
[branch]
if (distToLight < light.attenuationEnd)
{
float attenuation = linstep(light.attenuationEnd, light.attenuationBegin, distToLight);
dirToLight *= rcp(distToLight);
float3 litDiffuse = float3(0.0f, 0.0f, 0.0f);
float3 litSpecular = float3(0.0f, 0.0f, 0.0f);
AccumulatePhong(surface.normalV, dirToLight, normalize(surface.posV),
attenuation * light.color, surface.specularPower, litDiffuse, litSpecular);
litColor += surface.albedo.rgb * (litDiffuse + surface.specularAmount * litSpecular);
}
}
// Forward.hlsl
//--------------------------------------------------------------------------------------
// 计算点光源着色
float4 ForwardPS(VertexPosHVNormalVTex input) : SV_Target
{
uint totalLights, dummy;
g_Light.GetDimensions(totalLights, dummy);
float3 litColor = float3(0.0f, 0.0f, 0.0f);
[branch]
// 用灰度表示当前像素接受的灯光数目
if (g_VisualizeLightCount)
{
litColor = (float(totalLights) * rcp(255.0f)).xxx;
}
else
{
SurfaceData surface = ComputeSurfaceDataFromGeometry(input);
for (uint lightIndex = 0; lightIndex < totalLights; ++lightIndex)
{
PointLight light = g_Light[lightIndex];
AccumulateColor(surface, light, litColor);
}
}
return float4(litColor, 1.0f);
}
对于ddx和ddy,在光栅化过程中,GPU会在同一时刻并行运行很多像素着色器(如32-64个一组)而不是逐像素来执行,然后这些像素将组织在2x2一组的像素分块中。
这里的偏导数对应的是这一像素块中的变化率。ddx就是拿右边像素的值减去左边像素的值,ddy则是拿下面像素的值减去上面像素的值。x和y为屏幕的坐标。
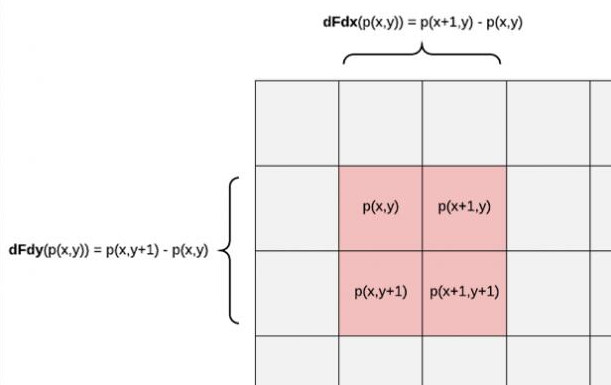
而ddx和ddy系列的函数只能用于像素着色器,是因为它需要依赖的是像素片元中的输入数据来求偏导。
例如,若传递的是posH,则有:
\[dFdx(posH(x,y))=posH(x+1,y)-posH(x,y)==(1,0,z(x+1,y)-z(x,y),0) \]我们可以通过对位置求偏导,来求出该像素点处所属三角表面的法线。
float3 ComputeFaceNormal(float3 pos)
{
return cross(ddx_coarse(pos), ddy_coarse(pos));
}
需要注意的是,通过这种方式求出来的法线,会和它对应三角面的所有像素用这种方式求出来的法线是*似相同的,但它不要求传入的顶点有法线数据,因此它适用于顶点没有法线属性的情况。在有顶点法线时,三角面内的像素法线是通过插值得到到的,看起来表面就会比较光滑。

此外ddx/ddy还有精度较低的ddx_coarse/ddy_coarse和精度较高的ddx_fine/ddx_fine版本
实际上,在对纹理进行采样时,选用哪一级的mipmap正是依赖于ddx和ddy的信息。屏幕空间的贴图uv偏导数过大表示贴图理我们过远,就会选择mipLevel更高的子纹理。

要使用延迟渲染,当前的图形库必须要能支持多渲染目标。在C++端,这是通过ID3D11DeviceContext::OMSetRenderTargets所提供的:
void ID3D11DeviceContext::OMSetRenderTargets(
UINT NumViews,
ID3D11RenderTargetView * const *ppRenderTargetViews,
ID3D11DepthStencilView *pDepthStencilView
);
对Direct3D 11来说,我们最多能够同时设置八个RTV,即像素着色器最多能够同时向八个纹理输出数据。
在HLSL,我们需要通过SV_Target[n]来指定当前变量输出到哪个渲染目标。例如:
struct PixelOut
{
float4 Normal_Specular : SV_Target0;
float4 Diffuse : SV_Target1;
};
PixelOut PS(PixelIn input)
{
// ...
}
回看前面的前向渲染的着色器代码,我们可以得知漫反射颜色、镜面反射颜色的计算公式为:
\[Diffuse=Albedo\times lightContrib \times (N\cdot L)\\ Specular= specAmount\times Albedo \times lightContrib \times (R\cdot V)^{specPow}\\ R=reflect(L, N) \]这里只以物体的漫反射贴图作为Albedo的贡献部分。lightContrib受光照强度和衰弱的影响,而衰弱的计算需要用到光源位置与表面位置。在不考虑优化的情况下,G-Buffer需要存放的信息有:
- 表面法线,3个float
- 漫反射系数Albedo,4个float
- 镜面反射强度系数和材质光滑程度SpecPower,2个float
- 像素点所处的世界坐标,3个float
为了让我们的G-Buffer包含所有需要用于计算上面公式的值,我们需要存储12个不同的浮点数到我们的G-Buffer渲染目标当中。因为在一张纹理中,每个像素最多存储4个值,我们使用3个G-Buffer就可以将它们全部存入。我们可以设计出如下的布局:
// | x | y | z | w |
// RT0: | Normal | SpecPower | float4
// RT1: | Albedo | float4
// RT2: | PositionV | SpecAmount | float4
// 注意:该版本的GBuffer与项目中的有差别
struct GBuffer
{
float4 normal_specPow : SV_Target0;
float4 albedo : SV_Target1;
float4 posV_specAmount : SV_Target2;
}
由于表面指向观察点的向量是通过eyePosW - surface.posW求得的,转换到观察空间后,观察点的坐标为原点,这样只需要传入surface.posV而不需要在常量缓冲区提供摄像机的eyePosW,但这样光源需要传入的也是light.posV,在光照计算时统一在观察空间进行。
在几何阶段,我们使用GeometryVS着色器处理顶点,使用下面基础版本的像素着色器将几何信息写入到GBuffer:
// GBuffer.hlsl
//--------------------------------------------------------------------------------------
// G-buffer 渲染
//--------------------------------------------------------------------------------------
void GBufferPS(VertexPosHVNormalVTex input, out GBuffer outputGBuffer)
{
SurfaceData surface = ComputeSurfaceDataFromGeometry(input);
outputGBuffer.normal_specPow = float4(surface.normalV, surface.specularPower);
outputGBuffer.albedo = surface.albedo;
outputGBuffer.posV_specAmount = float4(surface.posV, surface.specularAmount);
}
然后在光照阶段,我们的顶点着色器要能够覆盖全屏。可以使用如下的代码:
// FullScreenTriangle
// 使用一个三角形覆盖NDC空间
// (-1, 1)________ (3, 1)
// | | /
// (-1,-1)|___|/ (1, -1)
// | /
// (-1,-3)|/
float4 FullScreenTriangleVS(uint vertexID : SV_VertexID) : SV_Position
{
float4 output;
float2 grid = float2((vertexID << 1) & 2, vertexID & 2);
float2 xy = grid * float2(2.0f, -2.0f) + float2(-1.0f, 1.0f);
return float4(xy, 1.0f, 1.0f);
}
这样通过一个超大的三角形覆盖NDC空间,并且不需要提供输入布局和顶点缓冲区数据:
deviceContext->IASetInputLayout(nullptr);
deviceContext->IASetPrimitiveTopology(D3D11_PRIMITIVE_TOPOLOGY_TRIANGLELIST);
deviceContext->IASetVertexBuffers(0, 0, nullptr, nullptr, nullptr);
// ...
deviceContext->Draw(3, 0);
像素着色器的基础版本如下:
// Rendering.hlsl
struct SurfaceData
{
float3 posV;
float3 posV_DX; // 忽略
float3 posV_DY; // 忽略
float3 normalV;
float4 albedo;
float specularAmount;
float specularPower;
};
// GBuffer.hlsl
SurfaceData ComputeSurfaceDataFromGBuffer(uint2 posViewport)
{
// 从GBuffer读取数据
GBuffer rawData;
rawData.normal_specPow = g_GBufferTextures[0].Load(posViewport.xy).xyzw;
rawData.albedo = g_GBufferTextures[1].Load(posViewport.xy).xyzw;
rawData.posV_specAmount = g_GBufferTextures[2].Load(posViewport.xy).xyzw;
// 解码到合适的输出
SurfaceData data;
data.posV = rawData.posV_specAmount.xyz;
data.specularPower = rawData.posV_specAmount.w;
data.normalV = rawData.normal_specPow.xyz;
data.specularAmount = rawData.normal_specPow.w;
data.albedo = rawData.albedo;
return data;
}
// BasicDeferred.hlsl
// posViewport表示的是(屏幕坐标xy + 0.5偏移, NDC深度, 1)
float4 BasicDeferredPS(float4 posViewport : SV_Position) : SV_Target
{
uint totalLights, dummy;
g_Light.GetDimensions(totalLights, dummy);
float3 lit = float3(0.0f, 0.0f, 0.0f);
[branch]
if (g_VisualizeLightCount)
{
// 用亮度表示该像素会被多少灯光处理
lit = (float(totalLights) * rcp(255.0f)).xxx;
}
else
{
SurfaceData surface = ComputeSurfaceDataFromGBuffer(uint2(posViewport.xy));
// 避免对天空盒/背景像素着色
if (surface.posV.z < g_CameraNearFar.y)
{
for (uint lightIndex = 0; lightIndex < totalLights; ++lightIndex)
{
PointLight light = g_Light[lightIndex];
AccumulateColor(surface, light, lit);
}
}
}
return float4(lit, 1.0f);
}
渲染完场景后,还需要进行天空盒的渲染。现在的天空盒着色器代码基础版本为:
// SkyboxToneMap.hlsl
//--------------------------------------------------------------------------------------
// 使用天空盒几何体渲染
//--------------------------------------------------------------------------------------
TextureCube<float4> g_SkyboxTexture : register(t5);
Texture2D<float> g_DepthTexture : register(t6);
// 场景渲染的纹理
Texture2D<float4> g_LitTexture : register(t7);
struct SkyboxVSOut
{
float4 posViewport : SV_Position;
float3 skyboxCoord : skyboxCoord;
};
SkyboxVSOut SkyboxVS(VertexPosNormalTex input)
{
SkyboxVSOut output;
// 注意:不要移动天空盒并确保深度值为1(避免裁剪)
output.posViewport = mul(float4(input.posL, 0.0f), g_ViewProj).xyww;
output.skyboxCoord = input.posL;
return output;
}
float4 SkyboxPS(SkyboxVSOut input) : SV_Target
{
uint2 coords = input.posViewport.xy;
float3 lit = float3(0.0f, 0.0f, 0.0f);
float depth = g_DepthTexture.Load(coords);
// 检查天空盒的状态(注意:反转Z!)
// 如果不使用反转Z,则为depth >= 1.0f
[branch]
if (depth <= 0.0f && !g_VisualizeLightCount)
lit += g_SkyboxTexture.Sample(g_SamplerDiffuse, input.skyboxCoord).xyz;
else
lit += sampleLit;
return float4(lit, 1.0f);
}
除了FullScreenTriangleVS,上述着色器不是最终的版本。
由于渲染一帧的工作量主要来源于像素片元的执行数量和每个像素片元计算用到的光源数量,目前版本的延迟渲染相比前向渲染已经能够减少像素片元的数量,但即便如此,基础的延迟着色法的运行效率依然是低效的,因为目前我们渲染的每个像素仍然与场景中的所有光源所绑定,提升灯光数量都会引起渲染一帧工作量的显著增加。
此外,回顾之前的G-Buffer,如果这些元素都使用float4来存储的话,那么每渲染一个像素就需要驻留48字节。渲染1280x720分辨率需要占用42.2MB显存,而渲染1920x1080分辨率需要占用94.9MB显存。每帧都要驻留差不多100M的显存用于主要渲染,占用了比较多的显存带宽,对性能也会有一定的影响。当然,后续我们可以想办法对这些数据想办法进行一些处理,降低显存带宽的占用。
这样我们对延迟渲染的优化有两个确定的方向:
- 降低G-Buffer的占用空间及减少像素着色器的输出量
- 尽可能去掉对当前像素片元没有影响的光源以减少运算量
在这一章我们将讨论前者,下一章则对后者进行讨论。
G-Buffer相关的优化由于延迟渲染需要同时对一到多个渲染目标进行输出,这会占用较大的显存带宽。如果我们能降低输出的数目,这意味着能减小显存带宽的占用,以及G-Buffer所占用的显存空间。 为了降低G-Buffer的空间,我们可能会采用一些数学方法进行压缩/解压处理,即便这带来了更多的运算量,得益于现代GPU庞大的运算单元,使得给GPU进行更多运算带来的收益比增加显存带宽的占用要大得多。基于这个思想,我们将对存储在G-Buffer中的数据,基于他们的值域、精度需求、打包/解包的开销来寻找合适的存储类型。
法向量对于法线的压缩,我们有两种方向:
- 和之前的法线贴图有点类似,我们可以将其用有符号8位整数来存储(如
DXGI_FORMAT_R8G8B8A8_SNORM) - 考虑到法线是单位长度,我们可以考虑只用2个float来存储
在这里由于我们有SpecPower和SpecAmount两个float,选择第二种方式似乎是一个不错的选择,可以构成float4。并且我们实际上可以用DXGI_FORMAT_R16G16B16A16_FLOAT来减少8字节的占用。
考虑到法线的性质,我们可以用球面坐标系来表示一个法线。压缩/解压方式如下:
float2 CartesianToSpherical(float3 normal)
{
float2 s;
s.x = atan2(normal.y, normal.x) / 3.14159f;
s.y = normal.z;
return s;
}
float3 SphericalToCartesian(float2 p)
{
float2 sinCosTheta, sinCosPhi;
sincos(p.x * 3.14159f, sinCosTheta.x, sinCosTheta.y);
sinCosPhi = float2(sqrt(1.0f - p.y * p.y), p.y);
return float3(sinCosTheta.y * sinCosPhi.x,
sinCosTheta.x * sinCosPhi.x,
sinCosPhi.y
);
}
这种方式的主要缺点在于它需要使用三角函数(sin,cos,atan2),这些三角函数对运算单元的负担会比较大。如果能有其它的方法避免三角函数的话会更好一些
另一种办法是使用spheremap transformation。这种变换原来是用于将反射向量映射到[0, 1]范围,但它也适用于法向量。它的工作原理是存储在映射上的二维位置,每个位置对应球上的一个法线。具体做法如下:
float2 EncodeSphereMap(float3 normal)
{
return normalize(normal.xy) * (sqrt(-normal.z * 0.5f + 0.5f));
}
float3 DecodeSphereMap(float2 encoded)
{
float4 nn = float4(encoded, 1, -1);
float l = dot(nn.xyz, -nn.xyw);
nn.z = l;
nn.xy *= sqrt(l);
return nn.xyz * 2 + float3(0, 0, -1);
}
编码过程:
\[x'=\frac{x}{\sqrt{x^2+y^2}}\cdot\sqrt{0.5(1-z)}\\ y'=\frac{y}{\sqrt{x^2+y^2}}\cdot\sqrt{0.5(1-z)}\\ \]解码过程:
\[l=1-(x')^2-(y')^2=1-0.5(1-z)=0.5(1+z)\\ \sqrt{1-z^2}=\sqrt{x^2+y^2}\\ 2x'\sqrt{l}=\frac{2x}{\sqrt{x^2+y^2}}\cdot\sqrt{0.5(1-z)\cdot0.5(1+z)}=x\\ 2y'\sqrt{l}=\frac{2y}{\sqrt{x^2+y^2}}\cdot\sqrt{0.5(1-z)\cdot0.5(1+z)}=y\\ 2\cdot l-1=z \]整个运算过程最多就再用到开方,总体效率也比较理想。
漫反射颜色由于颜色的值域通常在[0, 1],这意味着我们可以使用无符号规格化的8位整数格式DXGI_FORMAT_R8G8B8A8_UNORM来存储。当然也可以将颜色值保存在sRGB空间,因为这通常用于漫反射纹理的存储格式。使用DXGI_FORMAT_R8G8B8A8_UNORM_SRGB会让硬件对像素着色器的输出执行sRGB转换。还有就是如果alpha通道不怎么需要用到的话也可以用DXGI_FORMAT_R10G10B16A2_UNORM来提升RGB的精度
位置通常需要高精度,且它要用于高频阴影计算/光照计算中。为了存储世界空间或观察空间中的坐标,甚至16位的浮点数格式通常不足以避免Artifacts。幸运的是,我们还有别的方式存储完整的XYZ值。在执行像素着色器的时候,屏幕空间坐标XY是可以通过SV_Position语义取得的,然后在渲染场景几何体的时候,通过用到的观察变换和投影变换矩阵是有可能恢复出观察空间或世界空间的坐标的。
对屏幕中的任意一个像素,都有一个表示从摄像机到像素位置对应远*面一点的方向向量。我们可以利用屏幕空间XY坐标来根据视锥体远*面的四个角点进行线性插值来构建方向向量,然后标准化(如果你在观察空间做这件事的话,就不需要再减去摄像机的位置)。如果几何体光栅化在当前像素位置,这意味着当前表面通过之前构建的方向向量从摄像机方向移动是可以接触到的。我们只要再有摄像机到表面的距离就可以构建出该表面的坐标了:
// 重建位置的过程,当前GBuffer需要提供一个float存储摄像机到表面的距离
// GBuffer顶点着色器
vOut.posV = mul(PosL, g_WorldView).xyz;
// GBuffer像素着色器
gBuffer.distance.x = length(gBuffer.posV);
// 光照阶段顶点着色器
vOut.ViewRay = posW - g_CamPosW;
// 光照阶段像素着色器
float3 viewRay = normalize(pIn.viewRay);
float viewDistance = g_TextureDistance.Sample(g_Sam, pIn.tex);
float3 posW = g_CamPosW + viewRay * viewDistance;

这为我们提供了一种灵活而又相当有效的方法,可以从存储在G-Buffer中的单一高精度值中重建位置。
然而如果我们只考虑观察空间的话,仍可以做进一步的优化:我们有办法避免存储多一个值,即通过透视投影的参数,我们可以从屏幕空间反推到观察空间。仔细观察下面的透视投影变换:
\[\begin{align} [x,y,z,1]\begin{bmatrix} m_{00} & 0 & 0 & 0 \\ 0 & m_{11} & 0 & 0 \\ 0 & 0 & m_{22} & 1 \\ 0 & 0 & m_{32} & 0 \\ \end{bmatrix}&=[m_{00}x,m_{11}y,m_{22}z+m_{32},z]\\ &\Rightarrow[\frac{m_{00}x}{z},\frac{m_{11}y}{z},m_{22}+\frac{m_{32}}{z}, 1] \end{align}\\ z_{ndc}=m_{22}+\frac{m_{32}}{z} \]其中ndc坐标我们可以通过像素着色器输入的屏幕坐标和屏幕宽高的信息求出来,这样逆变换的条件也足够了:
\[z=\frac{m_{32}}{z_{ndc}-m_{22}}\\ x=\frac{x_{ndc}\cdot z}{m_{00}}\\ y=\frac{y_{ndc}\cdot z}{m_{11}} \]在着色器代码中,重建观察空间坐标的方式如下:
float3 ComputePositionViewFromZ(float2 posNdc, float viewSpaceZ)
{
float2 screenSpaceRay = float2(posNdc.x / g_Proj._m00,
posNdc.y / g_Proj._m11);
float3 posV;
posV.z = viewSpaceZ;
posV.xy = screenSpaceRay.xy * posV.z;
return posV;
}
// ...
float2 gbufferDim;
uint dummy;
g_GBufferTextures[0].GetDimensions(gbufferDim.x, gbufferDim.y, dummy);
float2 screenPixelOffset = float2(2.0f, -2.0f) / gbufferDim;
float2 posNdc = (float2(posViewport.xy) + 0.5f) * screenPixelOffset.xy + float2(-1.0f, 1.0f);
// ndcZ = A + B/z => z = B/(ndcZ - A)
float viewSpaceZ = g_Proj._m32 / (ndcZ - g_Proj._m22);
float3 posV = ComputePositionViewFromZ(posNdc, viewSpaceZ);
然后是深度值的问题。观察空间的深度值在经过透视投影后变为:
\[d=a\frac{1}{z}+b \]其中a,b与*/远*面的设置关联。把重映射后的深度值等距采样,在该函数的图像如下:
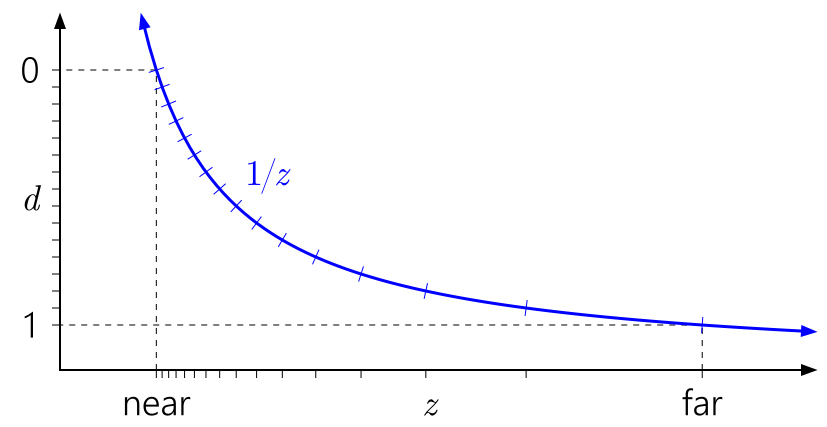
可以看到d的大部分区域落在了**面上。然而考虑浮点数的精度问题,它的数值分布大部分也是落在0上,如果选出浮点数能表示的0-1范围的所有d值,对应的图如下:
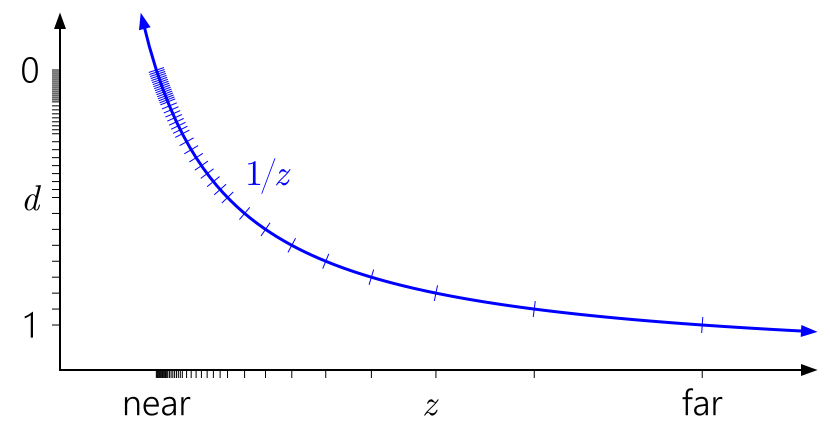
经过映射后发现这种现象被加剧了,绝大部分的点都被映射到**面上,这是一种浪费。且靠* 远*面 的z值,在经过映射后得到的d,受到精度的限制变得会更加难以区分,使得多个相*的深度值被映射到同一个d值的可能性被放大,导致出现Z-Fighting的问题。
一种广为人知的方法为反向Z,让**面映射到d=1,远*面映射到d=0:
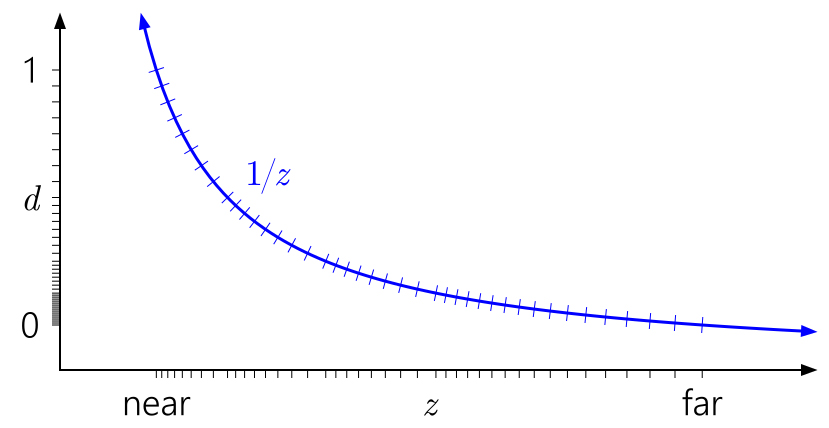
可以看到,反向Z可以利用浮点数的特性,让其在靠* 远*面 的分布也能变得较为均匀,从而较为良好地抵消掉重映射所带来的影响。这可以使Z-Fighting出现问题的可能性大幅降低。
为了使用反向Z,我们只需要在构造透视投影矩阵的时候,将*/远*面进行对调,并将深度测试从<修改为>。而在代码中,摄像机类的*/远*面不需要对调,而是在获取投影矩阵的时候在决定是否进行反向Z:
// 这里不需要对调
m_pCamera->SetFrustum(XM_PI / 3, AspectRatio(), 0.5f, 300.0f);
// 传入true说明反向Z,默认不传入为false
XMMATRIX P = m_pCamera->GetProjMatrixXM(true);
然后在清空深度缓冲区时用0清空:
m_pd3dImmediateContext->ClearDepthStencilView(m_pDepthBuffer->GetDepthStencil(), D3D11_CLEAR_DEPTH | D3D11_CLEAR_STENCIL, 0.0f, 0);
在深度测试时使用>=比较方式(使用>=是为了兼容Forward PreZ-Pass,在实际绘制时能同时处理>和=的情况):
m_pd3dImmediateContext->SetDepthStencilState(RenderStates::DSSGreaterEqual.Get(), 0);
首先复习一下超采样(SSAA)。现渲染WxH大小的屏幕,为了降低走样/锯齿的影响,可以使用2倍宽高的后备缓冲区及深度缓冲区,光栅化的操作量增大到了4倍左右,同样像素着色器的执行次数也增大到了原来的4倍左右。每个2x2的像素块对应原来的1个像素,通过对这2x2的像素块求*均值得到目标像素的颜色。
多重采样(MSAA)采用的是一种较为折中的方案。以4xMSAA为例,指的是单个像素需要按特定的模式对周围采样4次:
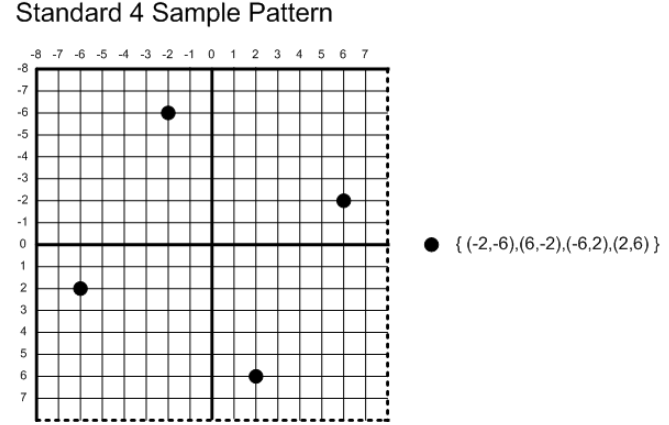
假定当前像素位置为(x+0.5,y+0.5),在D3D11定义的采样模式下,这四个采样点的位置为:(x+0.375, y+0.125)、(x+0.875, y+0.375)、(x+0.125, y+0.625)、(x+0.625, y+0.875)
在光栅化阶段,在一个像素区域内使用4个子采样点,但每个像素仍只执行1次像素着色器的计算。这4个子采样点都会计算自己的深度值,然后根据深度测试和三角形覆盖性测试来决定是否复制该像素的计算结果。为此深度缓冲区和渲染目标需要的空间依然为原来的4倍。
假设三角形1覆盖了2-3号采样,且通过了深度测试,则2-3号采样复制像素着色器得到的红色。此时渲染三角形2覆盖了1号采样,且通过了深度测试,则1号采样复制像素着色器得到的蓝色。在渲染完三角形后,对这四个采样点的颜色进行一个resolve操作,可以得到当前像素最终的颜色。这里我们可以认为是对这四个采样点的颜色求*均值。
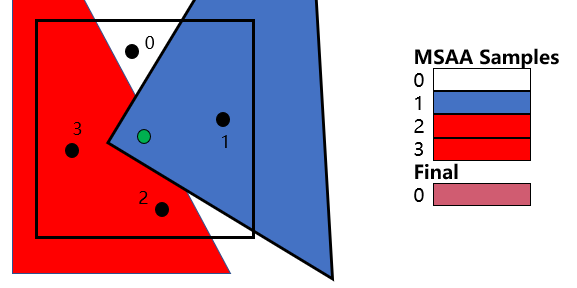
void ID3D11DeviceContext::ResolveSubresource(
ID3D11Resource *pDstResource, // [In]目标非多重采样资源
UINT DstSubresource, // [In]目标子资源索引
ID3D11Resource *pSrcResource, // [In]源多重采样资源
UINT SrcSubresource, // [In]源子资源索引
DXGI_FORMAT Format // [In]解析成非多重采样资源的格式
);
该API最常用于需要将当前pass的渲染目标结果作为下一个pass的输入。源/目标资源必须拥有相同的资源类型和相同的维度。此外,它们必须拥有兼容的格式:
- 已经确定的类型则要求必须相同:比如两个资源都是
DXGI_FORMAT_R8G8B8A8_UNORM,在Format中一样要填上 - 若有一个类型确定但另一个类型不确定:比如两个资源分别是
DXGI_FORMAT_R32_FLOAT和DXGI_FORMAT_R32_TYPELESS,在Format参数中必须指定DXGI_FORMAT_R32_FLOAT - 两个不确定类型要求必须相同:如
DXGI_FORMAT_R32_TYPELESS,那么在Format参数中可以指定DXGI_FORMAT_R32_FLOAT或DXGI_FORMAT_R32_UINT等
若后备缓冲区创建的时候指定了多重采样,正常渲染完后到呈现(Present)时会自动调用ResolveSubresource方法得到用于显示的非多重采样纹理。当然这仅限于交换链使用的是BLIT模型而非FLIP模型,因为翻转模型的后备缓冲区不能使用多重采样纹理,要使用MSAA我们需要另外新建一个等宽高的MSAA纹理先渲染到此处,然后ResolveSubresource到后备缓冲区。
前面我们已经知道了如果创建多重采样资源并作为渲染目标使用。而为了能够在着色器使用多重采样纹理,需要在HLSL声明如下类型的资源:
Texture2DMS<type, sampleCount> g_Texture : register(t*)
非多重采样的纹理设置的sampleCount是1,除了Texture2D类型,还可以传入到Texture2DMS<float4, 1>中使用
Texture2DMS类型只支持读取,不支持采样:
T Texture2DMS<T>::Load(
in int2 coord,
in int sampleIndex
);
延迟着色与多重采样的兼容性并不是很好,但不代表延迟着色不能使用多重采样。当然使用FXAA/TAA这些后处理会更好都是后话。现在需要补充多重采样与Direct3D 11相关的应用内容。
给延迟着色添加多重采样实际上是在几何阶段进行的,光照阶段完成的相当于是Resolve的操作。渲染流程如下:
-
在几何阶段:
- 创建同等MSAA采样频率的G-Buffer,然后将几何信息渲染到G-Buffer中
-
在光照阶段:
- 通过模板写入,标记出需要应用逐样本着色的区域(Per-Sample Shading),因为这是一件开销较大的事情
- 利用模板测试,在不需要逐样本着色的区域,我们使用样本0进行像素着色
- 同样利用模板测试,在需要逐样本着色的区域,对每个样本都调用像素着色
- 完成光照MSAA缓冲区的渲染后,我们在绘制天空盒时,对处于远*面的像素绘制天空盒的颜色;否则读取MSAA缓冲区在当前像素位置所有样本的颜色来完成Resolve。
如果我们对全屏区域进行逐样本着色,那本质上进行的就是SSAA(超采样)了。而真正需要逐样本着色的地方通常是位于物体边界的情况。逐样本着色的像素着色器需要添加SV_SampleIndex:
float4 PS(float4 posViewPort : SV_Position, uint sampleIndex : SV_SampleIndex) : SV_Target
{
// ...
}
目前的GBuffer布局如下:
struct GBuffer
{
float4 normal_specular : SV_Target0; // R16G16B16A16_FLOAT
float4 albedo : SV_Target1; // R8G8B8A8_UNORM
float2 posZGrad : SV_Target2; // R16G16_FLOAT
};
其中新增的posZGrad用于后面的逐样本绘制需求检测。目前这套G-Buffer每个像素只需要占据16字节,相比原来的48字节已经少了2/3的显存占用。当然,如果使用了4xMSAA又要开多4倍的显存。
几何阶段几何阶段的着色器如下:
//
// 源自Rendering.hlsl
//
VertexPosHVNormalVTex GeometryVS(VertexPosNormalTex input)
{
VertexPosHVNormalVTex output;
output.posH = mul(float4(input.posL, 1.0f), g_WorldViewProj);
output.posV = mul(float4(input.posL, 1.0f), g_WorldView).xyz;
output.normalV = mul(float4(input.normalL, 0.0f), g_WorldInvTransposeView).xyz;
output.texCoord = input.texCoord;
return output;
}
//
// GBuffer.hlsl
//
struct GBuffer
{
float4 normal_specular : SV_Target0;
float4 albedo : SV_Target1;
float2 posZGrad : SV_Target2; // ( d(x+1,y)-d(x,y), d(x,y+1)-d(x,y) )
};
// 法线编码
float2 EncodeSphereMap(float3 normal)
{
return normalize(normal.xy) * (sqrt(-normal.z * 0.5f + 0.5f));
}
//--------------------------------------------------------------------------------------
// G-buffer 渲染
//--------------------------------------------------------------------------------------
void GBufferPS(VertexPosHVNormalVTex input, out GBuffer outputGBuffer)
{
SurfaceData surface = ComputeSurfaceDataFromGeometry(input);
outputGBuffer.normal_specular = float4(EncodeSphereMap(surface.normalV),
surface.specularAmount,
surface.specularPower);
outputGBuffer.albedo = surface.albedo;
outputGBuffer.posZGrad = float2(ddx_coarse(surface.posV.z),
ddy_coarse(surface.posV.z));
}
顶点着色器使用GeometryVS,像素着色器使用GBufferPS,然后开启>或>=深度测试比较
光照阶段 使用模板标记出需要应用逐样本着色的区域// GBuffer.hlsl
struct GBuffer
{
float4 normal_specular : SV_Target0;
float4 albedo : SV_Target1;
float2 posZGrad : SV_Target2; // ( d(x+1,y)-d(x,y), d(x,y+1)-d(x,y) )
};
// 上述GBuffer加上深度缓冲区(最后一个元素) t1-t4
Texture2DMS<float4, MSAA_SAMPLES> g_GBufferTextures[4] : register(t1);
// 检查一个给定的像素是否需要进行逐样本着色
bool RequiresPerSampleShading(SurfaceData surface[MSAA_SAMPLES])
{
bool perSample = false;
const float maxZDelta = abs(surface[0].posV_DX.z) + abs(surface[0].posV_DY.z);
const float minNormalDot = 0.99f; // 允许大约8度的法线角度差异
[unroll]
for (uint i = 1; i < MSAA_SAMPLES; ++i)
{
// 使用三角形的位置偏移,如果所有的采样深度存在差异较大的情况,则有可能属于边界
perSample = perSample ||
abs(surface[i].posV.z - surface[0].posV.z) > maxZDelta;
// 若法线角度差异较大,则有可能来自不同的三角形/表面
perSample = perSample ||
dot(surface[i].normalV, surface[0].normalV) < minNormalDot;
}
return perSample;
}
// 使用逐采样(1)/逐像素(0)标志来初始化模板掩码值
void RequiresPerSampleShadingPS(float4 posViewport : SV_Position)
{
SurfaceData surfaceSamples[MSAA_SAMPLES];
ComputeSurfaceDataFromGBufferAllSamples(uint2(posViewport.xy), surfaceSamples);
bool perSample = RequiresPerSampleShading(surfaceSamples);
// 如果我们不需要逐采样着色,抛弃该像素片元(例如:不写入模板)
[flatten]
if (!perSample)
{
discard;
}
}
顶点着色器使用全屏三角形绘制,像素着色器使用RequiresPerSampleShadingPS,然后模板写入,对需要逐采样着色的像素标记为1,其余为0的默认进行逐像素着色
下图可以看到,红色的像素被标记为需要逐样本着色:

float3 DecodeSphereMap(float2 encoded)
{
float4 nn = float4(encoded, 1, -1);
float l = dot(nn.xyz, -nn.xyw);
nn.z = l;
nn.xy *= sqrt(l);
return nn.xyz * 2 + float3(0, 0, -1);
}
SurfaceData ComputeSurfaceDataFromGBufferSample(uint2 posViewport, uint sampleIndex)
{
// 从GBuffer读取数据
GBuffer rawData;
rawData.normal_specular = g_GBufferTextures[0].Load(posViewport.xy, sampleIndex).xyzw;
rawData.albedo = g_GBufferTextures[1].Load(posViewport.xy, sampleIndex).xyzw;
rawData.posZGrad = g_GBufferTextures[2].Load(posViewport.xy, sampleIndex).xy;
float zBuffer = g_GBufferTextures[3].Load(posViewport.xy, sampleIndex).x;
float2 gbufferDim;
uint dummy;
g_GBufferTextures[0].GetDimensions(gbufferDim.x, gbufferDim.y, dummy);
// 计算屏幕/裁剪空间坐标和相邻的位置
// 注意:需要留意DX11的视口变换和像素中心位于(x+0.5, y+0.5)位置
// 注意:该偏移实际上可以在CPU预计算但将它放到常量缓冲区读取实际上比在这里重新计算更慢一些
float2 screenPixelOffset = float2(2.0f, -2.0f) / gbufferDim;
float2 posNdc = (float2(posViewport.xy) + 0.5f) * screenPixelOffset.xy + float2(-1.0f, 1.0f);
float2 posNdcX = posNdc + float2(screenPixelOffset.x, 0.0f);
float2 posNdcY = posNdc + float2(0.0f, screenPixelOffset.y);
// 解码到合适的输出
SurfaceData data;
// 反投影深度缓冲Z值到观察空间
float viewSpaceZ = g_Proj._m32 / (zBuffer - g_Proj._m22);
data.posV = ComputePositionViewFromZ(posNdc, viewSpaceZ);
data.posV_DX = ComputePositionViewFromZ(posNdcX, viewSpaceZ + rawData.posZGrad.x) - data.posV;
data.posV_DY = ComputePositionViewFromZ(posNdcY, viewSpaceZ + rawData.posZGrad.y) - data.posV;
data.normalV = DecodeSphereMap(rawData.normal_specular.xy);
data.albedo = rawData.albedo;
data.specularAmount = rawData.normal_specular.z;
data.specularPower = rawData.normal_specular.w;
return data;
}
float4 BasicDeferred(float4 posViewport, uint sampleIndex)
{
uint totalLights, dummy;
g_Light.GetDimensions(totalLights, dummy);
float3 lit = float3(0.0f, 0.0f, 0.0f);
[branch]
if (g_VisualizeLightCount)
{
// 用亮度表示该像素会被多少灯光处理
lit = (float(totalLights) * rcp(255.0f)).xxx;
}
else
{
SurfaceData surface = ComputeSurfaceDataFromGBufferSample(uint2(posViewport.xy), sampleIndex);
// 避免对天空盒/背景像素着色
if (surface.posV.z < g_CameraNearFar.y)
{
for (uint lightIndex = 0; lightIndex < totalLights; ++lightIndex)
{
PointLight light = g_Light[lightIndex];
AccumulateColor(surface, light, lit);
}
}
}
return float4(lit, 1.0f);
}
float4 BasicDeferredPS(float4 posViewport : SV_Position) : SV_Target
{
return BasicDeferred(posViewport, 0);
}
顶点着色器使用全屏三角形绘制,像素着色器使用BasicDeferredPS,然后模板测试要求模板值为0才能进行着色,混合采用的是加法混合。由于在逐像素绘制的区域中,G-Buffer的4个子采样存的内容是相同的(某种意义上这也是一种浪费),我们可以直接取子采样0的信息进行着色。
通过模板测试来绘制逐样本着色的区域float4 BasicDeferredPerSamplePS(float4 posViewport : SV_Position,
uint sampleIndex : SV_SampleIndex) : SV_Target
{
float4 result;
if (g_VisualizePerSampleShading)
{
result = float4(1, 0, 0, 1);
}
else
{
result = BasicDeferred(posViewport, sampleIndex);
}
return result;
}
顶点着色器使用全屏三角形绘制,像素着色器使用BasicDeferredPerSamplePS,然后模板测试要求模板值为1才能进行着色,混合采用的是加法混合。
天空盒与场景的同时绘制// SkyboxToneMap.hlsl
//--------------------------------------------------------------------------------------
// 后处理, 天空盒等
// 使用天空盒几何体渲染
//--------------------------------------------------------------------------------------
TextureCube<float4> g_SkyboxTexture : register(t5);
Texture2DMS<float, MSAA_SAMPLES> g_DepthTexture : register(t6);
// 常规多重采样的场景渲染的纹理
Texture2DMS<float4, MSAA_SAMPLES> g_LitTexture : register(t7);
struct SkyboxVSOut
{
float4 posViewport : SV_Position;
float3 skyboxCoord : skyboxCoord;
};
SkyboxVSOut SkyboxVS(VertexPosNormalTex input)
{
SkyboxVSOut output;
// 注意:不要移动天空盒并确保深度值为1(避免裁剪)
output.posViewport = mul(float4(input.posL, 0.0f), g_ViewProj).xyww;
output.skyboxCoord = input.posL;
return output;
}
float4 SkyboxPS(SkyboxVSOut input) : SV_Target
{
uint2 coords = input.posViewport.xy;
float3 lit = float3(0.0f, 0.0f, 0.0f);
float skyboxSamples = 0.0f;
#if MSAA_SAMPLES <= 1
[unroll]
#endif
for (unsigned int sampleIndex = 0; sampleIndex < MSAA_SAMPLES; ++sampleIndex)
{
float depth = g_DepthTexture.Load(coords, sampleIndex);
// 检查天空盒的状态(注意:反向Z!)
if (depth <= 0.0f && !g_VisualizeLightCount)
{
++skyboxSamples;
}
else
{
lit += g_LitTexture.Load(coords, sampleIndex).xyz;
}
}
// 如果这里没有场景渲染,则渲染天空盒
[branch]
if (skyboxSamples > 0)
{
float3 skybox = g_SkyboxTexture.Sample(g_SamplerDiffuse, input.skyboxCoord).xyz;
lit += skyboxSamples * skybox;
}
// Resolve 多重采样(简单盒型滤波)
return float4(lit * rcp(MSAA_SAMPLES), 1.0f);
}
顶点着色器使用SkyboxVS,像素着色器使用SkyboxPS,光栅化取消背面裁剪。
C++端的变化目前对原来的代码做了比较多的改动,比较重要的包括:
- Model的ObjReader改为使用tinyobj的ObjReader,以能够导入Sponza模型,并对Model支持子模型级别的视锥体裁剪。
- 添加了TextureManager类以避免纹理的重复读取,内部使用DDSTextureLoader和stb_image读取纹理
- 使用DirectX-Graphics-Samples中MiniEngine的CameraController实现对FirstPersonCamera的*滑移动
- 添加ImGui应对逐渐复杂的选项控制
- 添加Texture2D、Depth2D和StructuredBuffer类
- 修改了RenderStates中部分状态
// ForwardEffect
// |-PreZ Pass
// | VS: GeometryVS
// | PS: nullptr
// | DepthStencilState: GreaterEqual
// |-Default Pass
// VS: GeometryVS
// PS: ForwardPS
// DepthStencilState: GreaterEqual
void GameApp::RenderForward(bool doPreZ)
{
float black[4] = { 0.0f, 0.0f, 0.0f, 1.0f };
m_pd3dImmediateContext->ClearRenderTargetView(m_pLitBuffer->GetRenderTarget(), black);
// 注意:反向Z的缓冲区,远*面为0
m_pd3dImmediateContext->ClearDepthStencilView(m_pDepthBuffer->GetDepthStencil(), D3D11_CLEAR_DEPTH | D3D11_CLEAR_STENCIL, 0.0f, 0);
D3D11_VIEWPORT viewport = m_pCamera->GetViewPort();
m_pd3dImmediateContext->RSSetViewports(1, &viewport);
// PreZ Pass
if (doPreZ)
{
m_pd3dImmediateContext->OMSetRenderTargets(0, 0, m_pDepthBuffer->GetDepthStencil());
m_pForwardEffect->SetRenderPreZPass(m_pd3dImmediateContext.Get());
m_Sponza.Draw(m_pd3dImmediateContext.Get(), m_pForwardEffect.get());
}
// 正常绘制
ID3D11RenderTargetView* pRTVs[1] = { m_pLitBuffer->GetRenderTarget() };
m_pd3dImmediateContext->OMSetRenderTargets(1, pRTVs, m_pDepthBuffer->GetDepthStencil());
m_pForwardEffect->SetRenderDefault(m_pd3dImmediateContext.Get());
m_pForwardEffect->SetLightBuffer(m_pLightBuffer->GetShaderResource());
m_Sponza.Draw(m_pd3dImmediateContext.Get(), m_pForwardEffect.get());
// 清除绑定
m_pd3dImmediateContext->OMSetRenderTargets(0, nullptr, nullptr);
}
}
这里使用LitBuffer作为场景渲染目标,使用GreaterEqual的深度比较是因为:如果没开PreZ Pass,正常绘制流程可以进行>的深度测试比较; 开了PreZ Pass的话先走一遍>=比较,然后在正式绘制的时候也能够只绘制深度值相等的像素。
天空盒与场景绘制到后备缓冲区// SkyboxToneMapEffect
// |-Default Pass
// | VS: SkyboxVS
// | PS: SkyboxPS
// | DepthStencilState: GreaterEqual
// | RasterizerState: NoCull
void GameApp::RenderSkyboxAndToneMap()
{
D3D11_VIEWPORT skyboxViewport = m_pCamera->GetViewPort();
// 感觉其实用0-1也没有什么问题,着色器那边会让PosH.z = PosH.w
skyboxViewport.MinDepth = 1.0f;
skyboxViewport.MaxDepth = 1.0f;
m_pd3dImmediateContext->RSSetViewports(1, &skyboxViewport);
m_pSkyboxEffect->SetRenderDefault(m_pd3dImmediateContext.Get());
m_pSkyboxEffect->SetViewMatrix(m_pCamera->GetViewMatrixXM());
// 注意:反转Z
m_pSkyboxEffect->SetProjMatrix(m_pCamera->GetProjMatrixXM(true));
m_pSkyboxEffect->SetSkyboxTexture(m_pTextureCubeSRV.Get());
m_pSkyboxEffect->SetLitTexture(m_pLitBuffer->GetShaderResource());
m_pSkyboxEffect->SetDepthTexture(m_pDepthBuffer->GetShaderResource());
// 由于全屏绘制,不需要用到深度缓冲区,也就不需要清空后备缓冲区了
m_pd3dImmediateContext->OMSetRenderTargets(1, m_pRenderTargetView.GetAddressOf(), nullptr);
m_Skybox.Draw(m_pd3dImmediateContext.Get(), m_pSkyboxEffect.get());
// 清除状态
m_pd3dImmediateContext->OMSetRenderTargets(0, nullptr, nullptr);
m_pSkyboxEffect->SetLitTexture(nullptr);
m_pSkyboxEffect->SetDepthTexture(nullptr);
m_pSkyboxEffect->Apply(m_pd3dImmediateContext.Get());
}
// DeferredEffect
// |-GBuffer Pass
// | VS: GeometryVS
// | PS: GBufferPS
// | DepthStencilState: GreaterEqual
void GameApp::RenderGBuffer()
{
// 注意:我们实际上只需要清空深度缓冲区,因为我们用天空盒的采样来替代没有写入的像素(例如:远*面)
// 这里我们使用深度缓冲区来重建位置且只有在视锥体内的位置会被着色
// 注意:反转Z的缓冲区,远*面为0
m_pd3dImmediateContext->ClearDepthStencilView(m_pDepthBuffer->GetDepthStencil(), D3D11_CLEAR_DEPTH | D3D11_CLEAR_STENCIL, 0.0f, 0);
D3D11_VIEWPORT viewport = m_pCamera->GetViewPort();
m_pd3dImmediateContext->RSSetViewports(1, &viewport);
m_pDeferredEffect->SetRenderGBuffer(m_pd3dImmediateContext.Get());
m_pd3dImmediateContext->OMSetRenderTargets(static_cast<UINT>(m_pGBuffers.size()), m_pGBufferRTVs.data(), m_pDepthBuffer->GetDepthStencil());
m_Sponza.Draw(m_pd3dImmediateContext.Get(), m_pDeferredEffect.get());
m_pd3dImmediateContext->OMSetRenderTargets(0, nullptr, nullptr);
}
// DeferredEffect
// |-Lighting Basic MaskStencil
// | VS: FullScreenTriangleVS
// | PS: RequiresPerSampleShadingPS
// | DepthStencilState: WriteStencil(1)
// |-Lighting Basic Deferred PerPixel
// | VS: FullScreenTriangleVS
// | PS: BasicDeferredPS
// | DepthStencilState: EqualStencil(0)
// | BlendState: Additive
// |-Lighting Basic Deferred PerSample
// | VS: FullScreenTriangleVS
// | PS: BasicDeferredPerSamplePS
// | DepthStencilState: EqualStencil(0)
// | BlendState: Additive
void DeferredEffect::ComputeLightingDefault(
ID3D11DeviceContext* deviceContext,
ID3D11RenderTargetView* litBufferRTV,
ID3D11DepthStencilView* depthBufferReadOnlyDSV,
ID3D11ShaderResourceView* lightBufferSRV,
ID3D11ShaderResourceView* GBuffers[4],
D3D11_VIEWPORT viewport)
{
std::string passStrs[] = {
"Lighting_Basic_MaskStencil_" + std::to_string(pImpl->m_MsaaSamples) + "xMSAA",
"Lighting_Basic_Deferred_PerPixel_" + std::to_string(pImpl->m_MsaaSamples) + "xMSAA",
"Lighting_Basic_Deferred_PerSample_" + std::to_string(pImpl->m_MsaaSamples) + "xMSAA"
};
// 清屏
const float zeros[4] = { 0.0f, 0.0f, 0.0f, 0.0f };
deviceContext->ClearRenderTargetView(litBufferRTV, zeros);
// 设置全屏三角形
deviceContext->IASetInputLayout(nullptr);
deviceContext->IASetPrimitiveTopology(D3D11_PRIMITIVE_TOPOLOGY_TRIANGLELIST);
deviceContext->IASetVertexBuffers(0, 0, nullptr, nullptr, nullptr);
deviceContext->RSSetViewports(1, &viewport);
// 使用模板标记出需要应用逐样本着色的区域
pImpl->m_pEffectHelper->SetShaderResourceByName("g_GBufferTextures[0]", GBuffers[0]);
pImpl->m_pEffectHelper->SetShaderResourceByName("g_GBufferTextures[1]", GBuffers[1]);
pImpl->m_pEffectHelper->SetShaderResourceByName("g_GBufferTextures[2]", GBuffers[2]);
pImpl->m_pEffectHelper->SetShaderResourceByName("g_GBufferTextures[3]", GBuffers[3]);
pImpl->m_pEffectHelper->SetShaderResourceByName("g_Light", lightBufferSRV);
if (pImpl->m_MsaaSamples > 1)
{
pImpl->m_pEffectHelper->GetEffectPass(passStrs[0])->Apply(deviceContext);
deviceContext->OMSetRenderTargets(0, 0, depthBufferReadOnlyDSV);
deviceContext->Draw(3, 0);
}
// 通过模板测试来绘制逐像素着色的区域
ID3D11RenderTargetView* pRTVs[1] = { litBufferRTV };
deviceContext->OMSetRenderTargets(1, pRTVs, depthBufferReadOnlyDSV);
pImpl->m_pEffectHelper->GetEffectPass(passStrs[1])->Apply(deviceContext);
deviceContext->Draw(3, 0);
// 通过模板测试来绘制逐样本着色的区域
if (pImpl->m_MsaaSamples > 1)
{
pImpl->m_pEffectHelper->GetEffectPass(passStrs[2])->Apply(deviceContext);
deviceContext->Draw(3, 0);
}
// 清空
deviceContext->OMSetRenderTargets(0, nullptr, nullptr);
ID3D11ShaderResourceView* nullSRVs[8]{};
deviceContext->VSSetShaderResources(0, 8, nullSRVs);
deviceContext->PSSetShaderResources(0, 8, nullSRVs);
}
void GameApp::DrawScene()
{
//
// 场景渲染部分
//
if (m_LightCullTechnique == LightCullTechnique::CULL_FORWARD_NONE)
RenderForward(false);
else if (m_LightCullTechnique == LightCullTechnique::CULL_FORWARD_PREZ_NONE)
RenderForward(true);
else if (m_LightCullTechnique == LightCullTechnique::CULL_DEFERRED_NONE){
RenderGBuffer();
m_pDeferredEffect->ComputeLightingDefault(
m_pd3dImmediateContext.Get(),
m_pLitBuffer->GetRenderTarget(),
m_pDepthBufferReadOnlyDSV.Get(),
m_pLightBuffer->GetShaderResource(),
m_pGBufferSRVs.data(),
m_pCamera->GetViewPort());
}
RenderSkyboxAndToneMap();
// ...
}
由于可改变的选项很多,演示起来也比较麻烦,这里只放出截屏,然后具体描述各自的功能
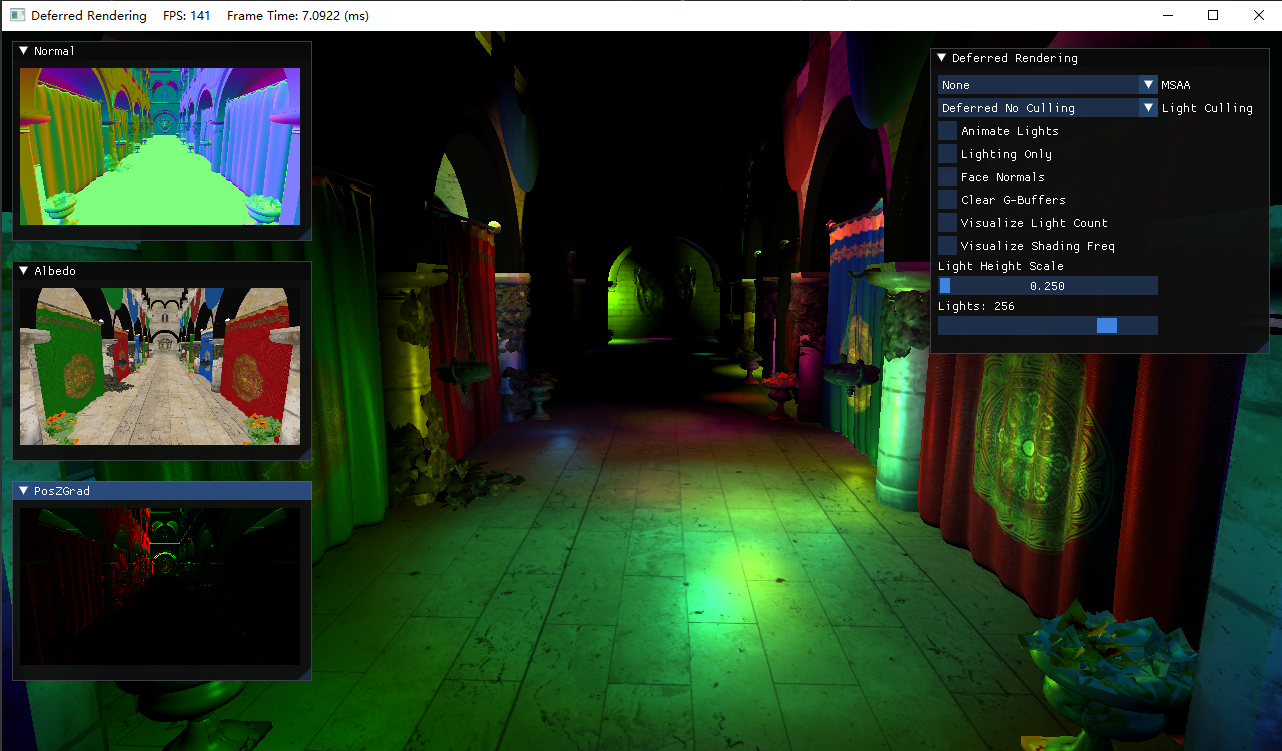
- MSAA:默认关闭,可选2x、4x、8x
- 光照裁剪模式:默认开启延迟渲染+无光照裁剪,可选前向渲染、带Pre-Z Pass的前向渲染
- Animate Lights:灯光的移动
- Face Normals:使用面法线
- Clear G-Buffer:默认不需要清除G-Buffer再来绘制,该选项开启便于观察G-Buffer中的图
- Visualize Light Count:可视化每个像素渲染的光照数,最大255。目前没有光照裁剪
- Visualize Shading Freq:在开启MSAA后,红色高亮的区域表示该像素使用的是逐样本着色
- Light Height Scale:将所有的灯光按一定比例抬高
- Lights:灯光数,2的指数幂
- Normal图:展示了从Normal_Specular G-Buffer还原出的世界坐标下的法线,经[-1, 1]到[0, 1]的映射
- Albedo图:展示了Albedo G-Buffer
- PosZGrad图:展示了观察空间下的PosZ的梯度
仔细看上面的图,会发现场景的显示总是显得比较暗淡,且不那么真实。经过后续观察发现,我们实际上还忽略了颜色空间的问题。接下来还得穿插一些知识补充。
线性空间和Gamma空间在物理世界中,如果光照强度增加一倍,那么亮度也会增加一倍,这是线性关系。
而历史上最早的显示器(阴极射线管)显示图像的时候,电压增加一倍,亮度并不意味着也会增加一倍。即输出亮度和电压并不是呈线性关系的,而是呈指数函数的非线性关系:
\[l=c^{2.2} \]2.2也叫该显示器的Gamma值,现代显示器的Gamma值也都大约是2.2。
下面的图展示了物理世界的线性空间(红线)和显示器输出的Gamma 2.2空间(蓝色曲线)的关系,横坐标表示电压,纵坐标表示亮度。
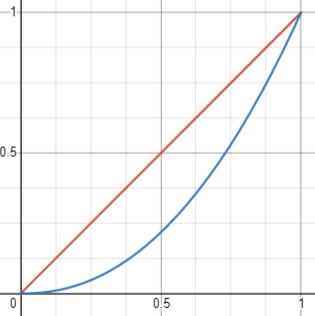
这种关系意味着当电压线性变化时,相对于真实世界来说,亮度的变化在暗处变化较慢,暗处所占的数据范围更广,使得颜色整体偏暗。原本假定我们的着色器是在线性空间中做运算,在输出结果到后备缓冲区后,显示器进行了一次Gamma2.2曲线的调整,这就导致出现了前面演示的结果。为此我们需要在显示器输出之前,进行一次伽马校正,将显示器的Gamma2.2调整给*衡掉,最终的观察结果就和人眼直接观察物理世界一样了。
伽马校正的具体做法是,在输出颜色前做一次1/2.2的幂运算,可以做到类似整体提亮的效果:
\[c_{out}=c_{in}^{\frac{1}{2.2}} \]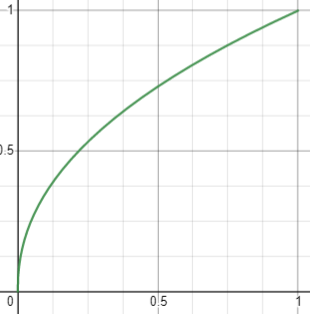
两次幂运算后可以使得最终呈现的颜色与线性颜色保持接*一致。下图展示了线性空间输出伽马校正后的颜色值与显示器Gamma 2.2调整后的最终颜色,可以看到线性空间的输出实际上是偏白的。

假设你用数码相机拍一张照片,你看了看照相机屏幕上显示的结果和物理世界是一样的。可是照相机要怎么保存这张图片,使得它在所有显示器上都一样呢?反推一下,那照片只能保存在Gamma0.45空间,经过显示器的Gamma2.2调整后,才和你现在看到的一样。换句话说,sRGB格式相当于对物理空间的颜色做了一次伽马校正。
目前可公开的情报有:
- 显示器的输出在Gamma2.2空间
- 伽马校正会将颜色转换到Gamma0.45空间
- 伽马校正和显示器输出*衡之后,结果就是Gamma1.0的线性空间
- sRGB类似于Gamma0.45空间
- 在线性颜色空间中,颜色可以进行加法和乘法。
- 在gamma空间中,颜色不可以进行加法,但可以进行乘法
- 在sRGB颜色空间中,颜色不可以进行加法和乘法。(这里区分gamma颜色空间和sRGB颜色空间是因为不是每个人都使用线性到sRGB的*似转换)
这意味着gamma空间或sRGB的颜色不能用于顶点属性,经过插值运算得不到正确的结果。
对于我们目前所使用的Sponza模型,它的漫反射贴图实际上都是位于sRGB的空间。如果我们使用R8G8B8A8_UNORM的格式来读取这些纹理,那么我们需要在对纹理采样后,先从sRGB空间转换到Linear RGB空间来运算:
float color = pow(g_TextureDiffuse.Sample(g_Sam, uv), 2.2f);
否则的话直接对利用sRGB颜色做光照计算会产生错误的结果。
注意:法线贴图等这些由计算机运算得到的纹理一般是在线性空间,不需要做额外处理。
在着色器的运算位于线性空间,我们需要在像素着色器输出前进行伽马校正:
return pow(litColor, 1.0f / 2.2f);
如果一个纹理位于sRGB颜色空间,我们可以在创建的时候指定DXGI_FORMAT_R8G8B8A8_UNORM_SRGB数据类型,这样硬件在进行采样的时候会自动进行sRGB到线性空间的变换
类似的,如果我们给后备缓冲区指定DXGI_FORMAT_R8G8B8A8_UNORM_SRGB数据类型,那么在写入的时候也会自动执行从线性空间到sRGB的转换。
为此,我们就不需要在着色器中编写任何有关颜色空间转换的代码从而保持一致行为。
注意:
- 一些游戏可以让用户使用自定义的gamma值来调整明亮度,而不是使用默认的sRGB编码方式。在这种情况下,我们可以使用
R8G8B8A8的后备缓冲区先完成前面的渲染,然后在最后的pass执行用户自定义gamma调整且不进行任何混合操作。- 如果后备缓冲区为
R8G8B8A8_UNORM_SRGB,但又希望某些纹理按原线性空间的颜色输出,则需要在绘制到后备缓冲区之前做一次pow(2.2)的处理取消伽马校正。比如调试显示法线贴图。
经过对sRGB纹理读取的处理,以及修改了后备缓冲区为sRGB后,可以看到场景明显变亮了许多:
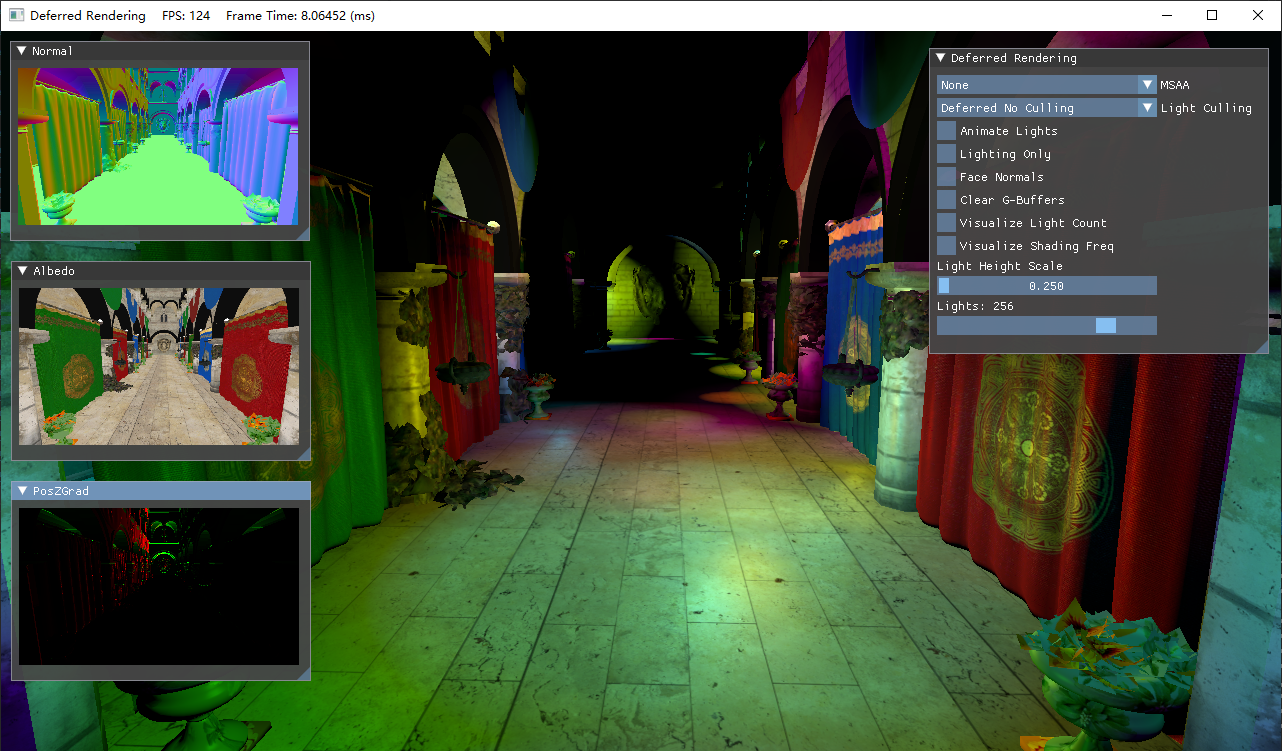
但ImGui的边框也受伽马校正的影响被直接提亮了,这并不是我们想要的结果。
ImGui的情况处理ImGui本身是对sRGB无动于衷的。根据sRGB and linear color spaces · Issue #578 · ocornut/imgui,我们可以利用ImGui提供的没有使用到的枚举值ImGuiConfigFlags_IsSRGB,然后需要对ImGui的源码做一些修改。
在imgui_impl_dx11.cpp大致382行的位置,我们使用如下代码替换vertexShader,使得能够根据ImGuiConfigFlags_IsSRGB的设置与否来决定是否需要去除伽马校正:
static const char* vertexShader = nullptr;
if (ImGui::GetIO().ConfigFlags & ImGuiConfigFlags_IsSRGB)
{
vertexShader =
"cbuffer vertexBuffer : register(b0) \
{\
float4x4 ProjectionMatrix; \
};\
struct VS_INPUT\
{\
float2 pos : POSITION;\
float4 col : COLOR0;\
float2 uv : TEXCOORD0;\
};\
\
struct PS_INPUT\
{\
float4 pos : SV_POSITION;\
float4 col : COLOR0;\
float2 uv : TEXCOORD0;\
};\
\
PS_INPUT main(VS_INPUT input)\
{\
PS_INPUT output;\
output.pos = mul( ProjectionMatrix, float4(input.pos.xy, 0.f, 1.f));\
output.col = pow(input.col, 2.2f);\
output.uv = input.uv;\
return output;\
}";
}
else
{
vertexShader =
"cbuffer vertexBuffer : register(b0) \
{\
float4x4 ProjectionMatrix; \
};\
struct VS_INPUT\
{\
float2 pos : POSITION;\
float4 col : COLOR0;\
float2 uv : TEXCOORD0;\
};\
\
struct PS_INPUT\
{\
float4 pos : SV_POSITION;\
float4 col : COLOR0;\
float2 uv : TEXCOORD0;\
};\
\
PS_INPUT main(VS_INPUT input)\
{\
PS_INPUT output;\
output.pos = mul( ProjectionMatrix, float4(input.pos.xy, 0.f, 1.f));\
output.col = input.col;\
output.uv = input.uv;\
return output;\
}";
}
需要注意的是我们对调试用的法线贴图和PosZGrad贴图去掉了伽马校正,但对Albedo图不做处理。
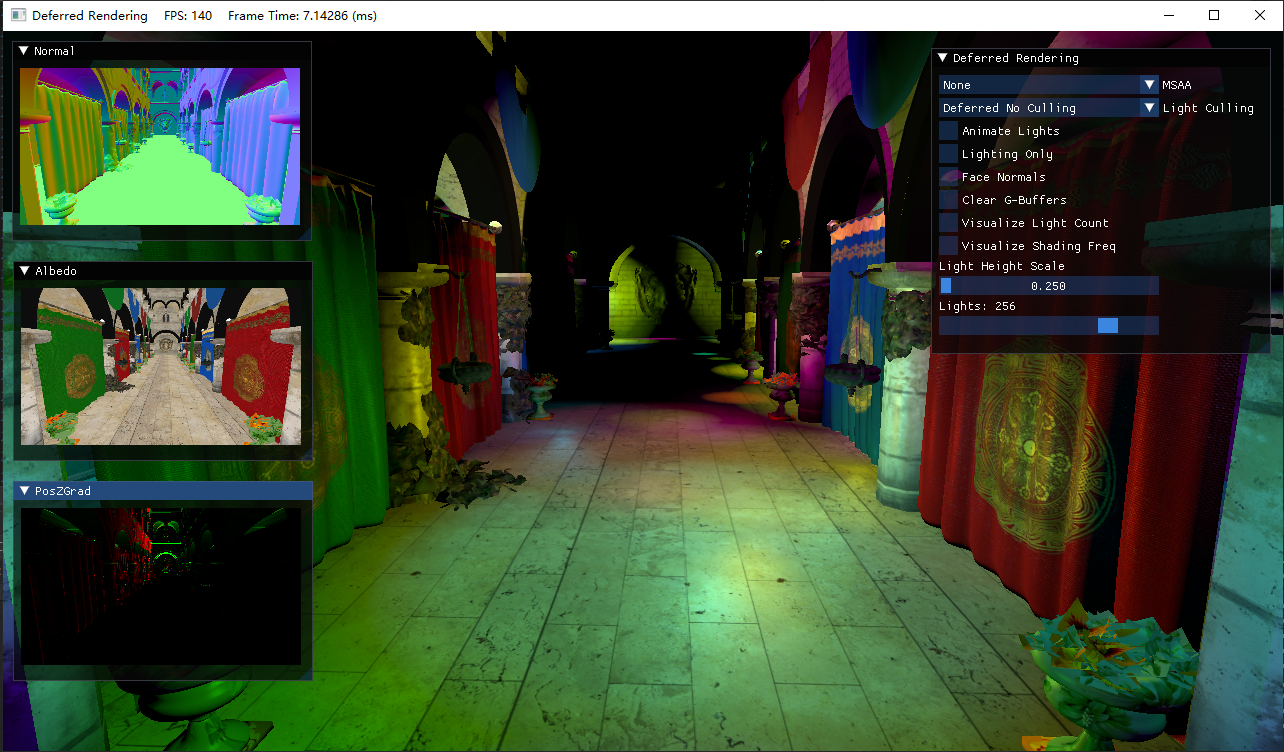
在下一章我们将会重点讨论光照裁剪技术。
补充&参考Depth Precision Visualized
Deferred Rendering for Current and Future Rendering Pipelines
Compact Normal Storage for small G-Buffers · Aras' website (aras-p.info)
Gamma、Linear、sRGB 和Unity Color Space,你真懂了吗?
sRGB and linear color spaces · Issue #578 · ocornut/imgui
DirectX11 With Windows SDK完整目录
Github项目源码
欢迎加入QQ群: 727623616 可以一起探讨DX11,以及有什么问题也可以在这里汇报。