 联邦学习做为一种特殊的分布式机器学习,仍然面临着分布式机器学习中存在的问题,那就是设计分布式的优化算法。 不过相比传统的分布式机器学习,它需要关注系统异质性(system heterogeneity)、统计异质性(statistical heterogeneity)和数据隐私性(data privacy)。系统异质性体现为昂贵的通信代价和节点随时可能宕掉的风险(容错);统计异质性数据的不独立同分布(Non-IID)和不平衡。由于以上限制,传统分布式机器学习的优化算法便不再适用,需要设计专用的联邦学习优化算法。
导引
联邦学习做为一种特殊的分布式机器学习,仍然面临着分布式机器学习中存在的问题,那就是设计分布式的优化算法。 不过相比传统的分布式机器学习,它需要关注系统异质性(system heterogeneity)、统计异质性(statistical heterogeneity)和数据隐私性(data privacy)。系统异质性体现为昂贵的通信代价和节点随时可能宕掉的风险(容错);统计异质性数据的不独立同分布(Non-IID)和不平衡。由于以上限制,传统分布式机器学习的优化算法便不再适用,需要设计专用的联邦学习优化算法。
导引
联邦学习做为一种特殊的分布式机器学习,仍然面临着分布式机器学习中存在的问题,那就是设计分布式的优化算法。
以分布式机器学习中常采用的client-server架构(同步)为例,我们常常会将各client节点计算好的局部梯度收集到server节点进行求和,然后再根据这个总梯度进行权重更新。
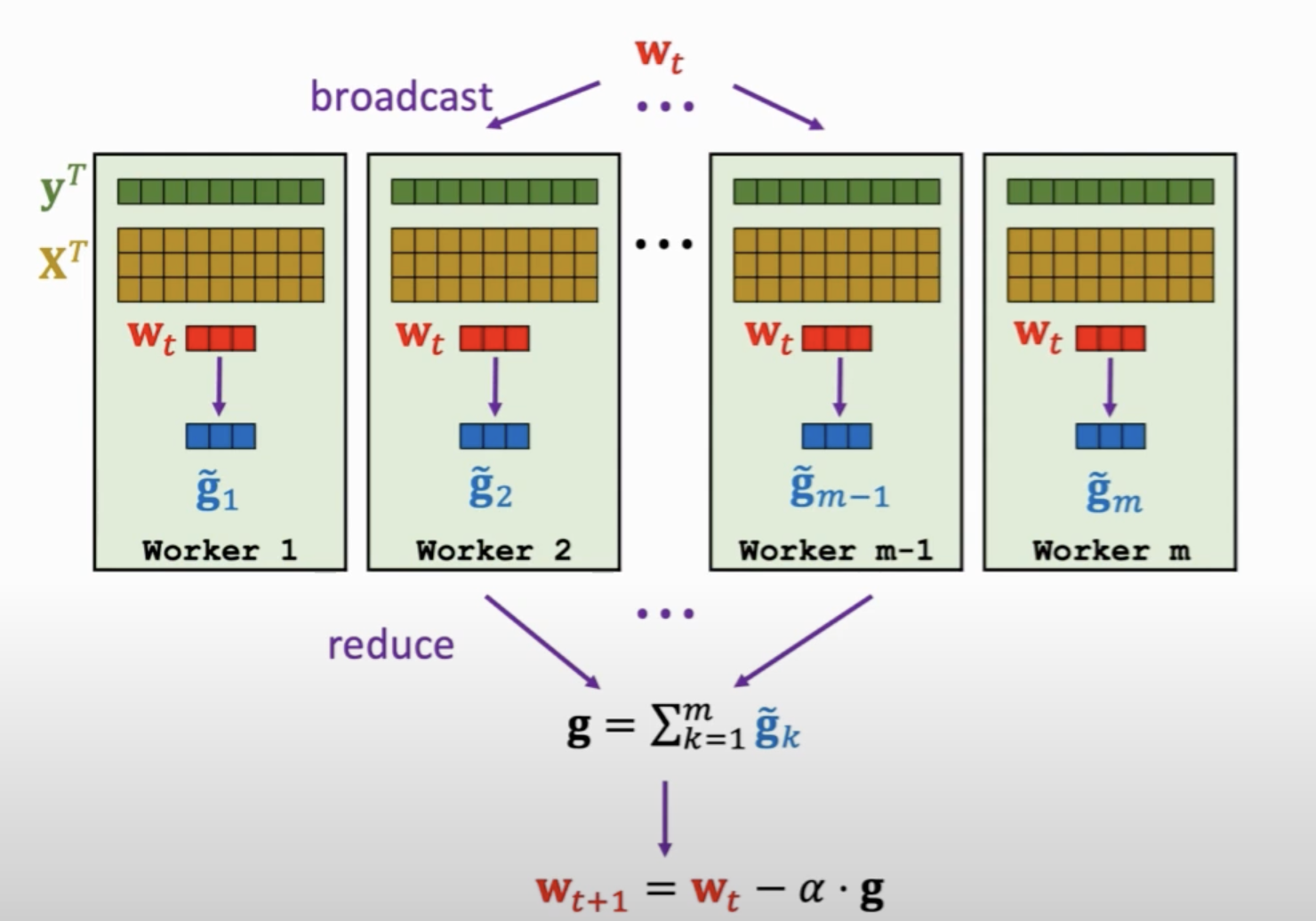
不过相比传统的分布式机器学习,它需要关注系统异质性(system heterogeneity)、统计异质性(statistical heterogeneity)和数据隐私性(data privacy
)。系统异质性体现为昂贵的通信代价和节点随时可能宕掉的风险(容错);统计异质性数据的不独立同分布(Non-IID)和不平衡。由于以上限制,传统分布式机器学习的优化算法便不再适用,需要设计专用的联邦学习优化算法。
举个例子,传统分布式机器学习中也提出了许多降低通信量的算法,包括近似牛顿法[1][2][3]、小样本平均[5]等,但这些算法只考虑了数据IID的情况,不能照搬过来。算法[4]没有假设数据IID,但是不适用深度学习,因为神经网络很难求对偶问题。
目前已经针对联邦学习提出了许多新的优化算法。同时,同时除了中心(centralized)化优化算法,针对联邦学习的去中心化(decentralized)优化算法也得到了广泛研究。
FedAvg——旨在减少通信的开山之作在联邦学习中,首先的不同便是通信代价。我们希望每轮通信能够在client上完成更多的运算(client端一般是用户手机等设备,充电的时候都可以计算),这也是联邦学习开山论文[6]提出的FedAvg算法的初衷。该算法是联邦学习领域最为基础的梯度聚合方法。
相比传统分布式机器学习方法在client节点只计算出梯度,FedAvg方法希望client节点能够多做一些运算,得到比梯度更好的下降方向。由于这个下降方向比梯度更好,所以可以收敛更快。而收敛快了,那么通信次数自然就少了。这就是该算法设计的基本想法。
该算法的每轮通信描述如下:
(1) 第\(k\)个client节点执行
- 从server接收全局模型参数\(w^t\)并令\(w_k=w^t\)。
- 执行\(E\)个局部epoch的SGD:\[w_k = w_k - \eta \nabla \mathcal{l}(w_k; b) \](此处将局部数据\(D_k\)划分为多个\(b\))
- 将新的\(w_k\)发往server。
(2) server节点执行
-
从\(K\)个client接收\(w_1^{t+1}、w_2^{t+1},...w_K^{t+1}\)
-
按(加权)平均更新模型参数:
其中\(t\)为第\(t\)轮迭代。可以看到相比传统分时机器学习中每个client计算完梯度就发给server,FedAvg计算完梯度后会直接更新局部参数,同时重复该过程多次。而对于server,会对client传来的参数进行加权平均。
注意,FedAvg还有一种变种写法如下:
(1) 第\(k\)个client节点执行
- 从server接收全局模型参数\(w^t\)并令\(w_k = w^t\)。
- 执行\(E\)个局部epoch的SGD:\[w_k = w_k - \eta \nabla \mathcal{l}(w_k; b) \](此处将局部数据\(D_k\)划分为多个\(b\))
- 将\(g_k = w_k-w^t\)发往server。
(2) server节点执行
-
从\(K\)个client接收\(g_1、g_2,...g_K\)
-
按(加权)平均更新模型参数:
两种写法本质上等效的。
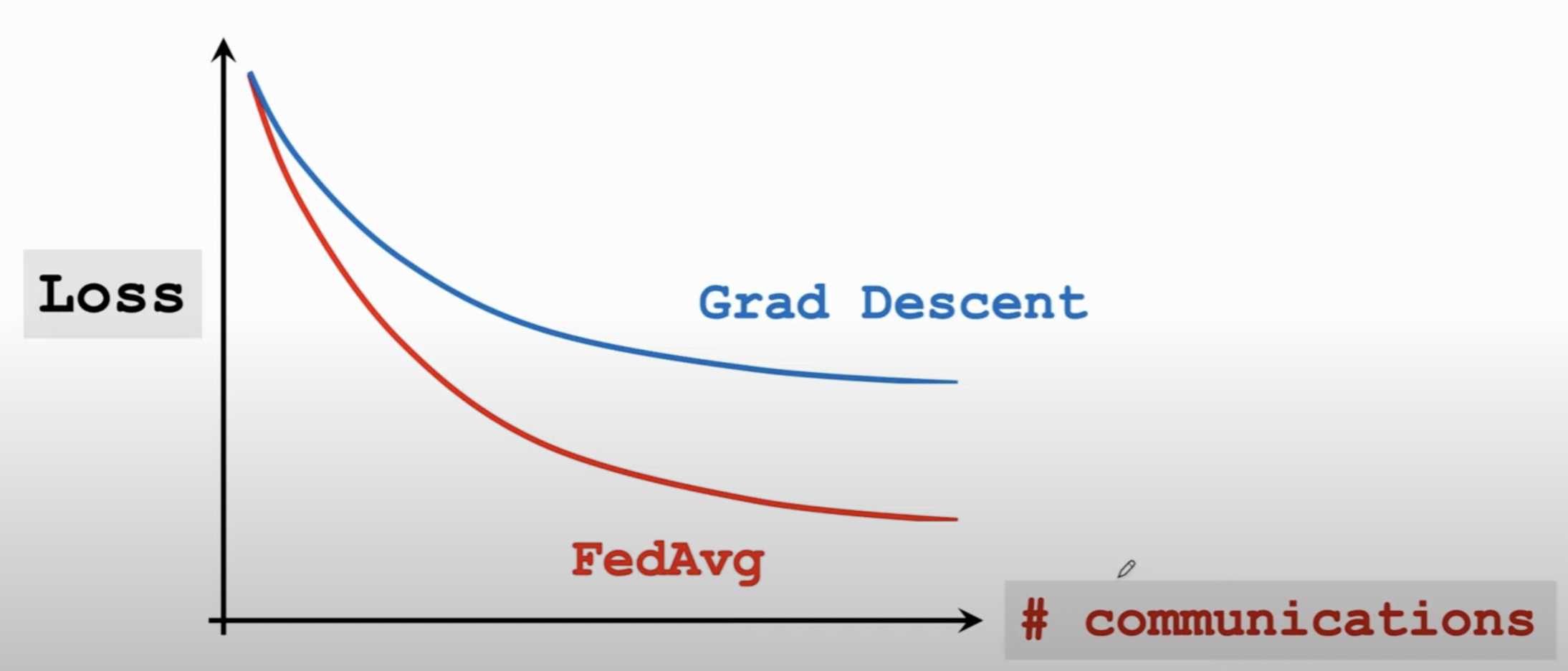
综上所述,FedAvg算法在通信次数相同的情况下,自然会收敛更快。如果实验对比FedAvg和传统分布式机器学习的SGD,我们会得到这样的结果:
不过这么做是有代价的,当client节点的计算量(以epoch来衡量)相同,那么FedAvg的收敛速度是不如传统SGD的。
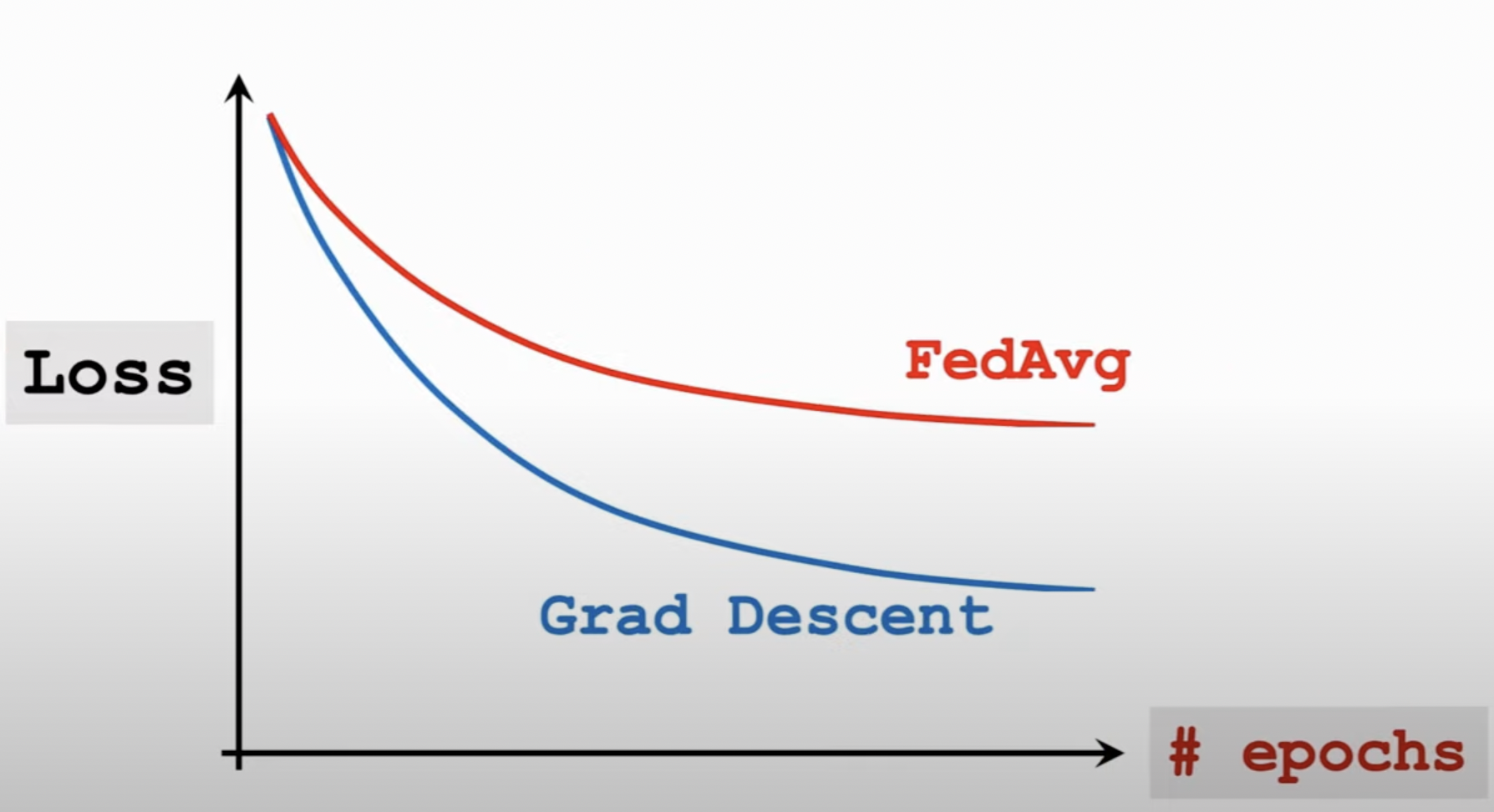
这是典型的以计算换通信策略。 而联邦学习中计算代价小,通信代价大,因此FedAvg算法很有用。该算法的作者已证明,FedAvg能够在Non-IID条件下收敛[7]。论文[8]以Gboard输入法背景下的单次预测任务为例,从工程上证明了FedAvg算法的优越性。
FedProx——关注掉队者FedProx[9]主要从系统异质性和统计异质性两个方向入手来改良FedAvg算法。不过,介于后来FedAvg算法已被证明在Non-IID数据集上本来能收敛[7],该算法的贡献还是在于提供了一个收敛更快、效果更好的算法。
我们知道,系统异质性下,FedAvg算法要求的每个节点执行的\(E\)个epoch的局部迭代可能无法得到保证,因为节点随时可能宕掉。FedProx作者还探究了统计异质性和系统异质性之间的相互作用,并认为系统异质性产生的掉队者(stragglers) 以及掉队者发往server的带偏差的参数信息会进一步增加统计异质性,最终影响收敛。因此,作者提出在client的优化目标函数中增加一个近端项,这样可以使优化算法更加稳定,最终使得FedProx在统计异质性下也收敛更快。
FedProx中server的操作和FedAvg相同,都是采用(加权)平均,但是其第\(k\)个client端不再是执行\(E\)轮的SGD,而是求解以下带近端项的优化问题:
\[\begin{aligned} w^{t+1}_k &=\underset{w}{\text{argmin}}h(w,w^t_k)\\ & = \mathcal{l}(w, D_k) + \frac{\mu}{2}||w-w^t_k||^2 \end{aligned} \]其中\(\mathcal{l}(w, D_k)\)为客户端原本的优化函数,\(\frac{\mu}{2}||w-w^t||^2\)为近端项。作者在论文中证明了近端项的添加能够使FedProx更好地适用于统计异质和系统异质的环境。
我们可以认为FedAvg是FedProx中将\(\mu\)设置为0,求解器设置为SGD,Epoch设置为\(E\)(当然这样就无法处理系统异质性)的特殊情况。
FedAvg+ ———用元学习做模型个性化在传统的联邦学习中,每个client节点联合联合训练出各一个全局的模型(在前文中即server节点的\(w_t\))。但是由于数据Non-IID,训练出的全局模型很难对每个局部节点都适用,不够“个性化”。
Jiang Y等人的这篇论文[10]首次采用了个性化联邦学习的思路:不求训练出一个全局的模型,而使每个节点训练各不相同的模型。作者在论文中采用模型不可知的元学习(Model Agnostic Meta Learning, MAML) 思路。元学习在给定小样本实例的条件下进行自适应,可以优化在异构任务上的表现,它由两个步骤构成:“meta training”——训练初始化模型/元模型和“meta testing”——使初始化模型在特定的任务下完成自适应。
作者认为传统的FedAvg算法[6]可以被解释为一种元学习算法。在此基础上再进行仔细的微调(fine-tuning)能够使全局模型少一些泛化性,但同时能够更容易个性化。我们将全局的已训练的模型称为初始化模型(initial model),将局部的已训练模型称为个性化模型(personalized model)。论文没有采用[11]中将训练初始化模型和模型个性化的操作分离,作者认为这样会陷入局部最优,作者提出的算法包括以下3个连续的步骤:
(1) 运行传统的FedAvg算法得到初始化模型,其中采用更大的\(E\),并使用带动量的SGD做为优化器。
(2) 采用FedAvg的变种算法对初始化模型进行微调: 此时采用Adam做为优化器,且迭代不再是采用\(E\)个epoch,而是先从\(D_k\)中随采样\(M\)个数据集\(\{D_{k,m}\}\)(\(M\)一般较小),然后进行如下的\(M\)个迭代步:
\[w_k = w_k - \eta \nabla \mathcal{l}(w_k; D_{k, m}) \](3) 对client进行进行个性化操作,采用和训练期间相同的优化器。
作者认为该算法能够得到更稳固的初始化模型,这样对于一些clients只有有限的甚至没有数据来做个性化的情况很有好处。
Clustered FL——多任务知识共享聚类联邦学习(CFL)[12]这篇论文针对数据Non-IID导致的局部最优,提出了一种新的联邦学习个性化方法:聚类(多任务)联邦学习。
CFL保持着个性化联邦学习的基本假设:每个节点训练各不相同的模型。但并没有采用元学习中初始化模型+自适应的措施,而是借用多任务学习中的常见手段,即让节点在训练的过程中就进行知识共享(可以参见我的博客《基于正则化的多任务学习》),而无需另设一个初始化模型。更具体的,CFL采用的是聚类多任务学习(clustered multitask learning),在训练的过程中将参数相似的节点划分为同一个节点簇,同一个节点簇共享参数的变化量\(g\),以此既能达到完成知识共享和相似的节点相互促进的目的。
聚类联邦学习算法的每轮通信描述如下:
(1) 第\(k\)个client节点执行
- 从server接收\(g_{c(k)}\)
- 另\(w_{old}=w_k=w_k + g_{c(k)}\)
- 执行\(E\)个局部epoch的SGD:\[w_k = w_k - \eta \nabla \mathcal{l}(w_k; b) \](此处将局部数据\(D_k\)划分为多个\(b\))
- 将\(g_k = w_k-w_{old}\)发往server。
- 重置使\(w_k = w_{old}\)。
(2) server节点执行
-
从\(K\)个client接收\(g_1、g_2,...g_K\)
-
对每一个簇\(c\in \mathcal{C}\),计算簇内平均参数变化:
- 根据不同节点参数变化量的余弦距离\(\alpha_{i,j}=\frac{\langle g_i, g_k\rangle}{||g_i||||g_j||}\)重新划分聚类簇。
CFL的簇划分算法采用的是不断进行二分裂的方式,无需指定簇的数量做为先验。该算法最重要的贡献就是簇间知识共享思想的引入(并不共享参数,而共享参数的变化量,注意和论文[15]中直接参数的平均进行区分)。
pFedMe—纯优化视角的个性化pFedMe[13]这篇论文继续瞄准联邦学习个性化,它的创新点是使用Moreau envelope(也称Moreau-Yosida正则化)做为client的正则损失函数。该算法比已有的许多算法收敛速度更快。
这个方法的一大贡献将个性化模型与全局模型同时进行优化求解,该方法按照与标准FedAvg相似的方法来更新全局模型(多了个一阶指数平滑),不过会以更低的复杂度来对个性化模型进行优化。
该篇论文算法的每轮通信描述如下:
(1) 第\(k\)个client节点执行
-
从server接收全局模型参数\(w^t\)并令\(w_k = w^t\)。
-
执行\(R\)轮局部迭代:
\[w_k = w_k - \eta \mu(w_k - \hat{\theta}_k(w_k)) \]其中
\[ \hat{\theta}_k(w_k)= \underset{\theta_k \in \mathbb{R}^d}{\text{argmin}} \{ \mathcal{l}(\theta_k, D_k) + \frac{\mu}{2}||\theta_k - w_k||^2 \} \] -
将新的\(w_k\)发往server。
(2) server节点执行
-
从\(K\)个client接收\(w_1^{t+1}、w_2^{t+1},...w_K^{t+1}\)
-
按与平均值的一次指数平滑更新模型参数:
\[w^{t+1} = (1-\beta)w^t + \beta \frac{1}{K} \sum_{k=1}^K w_k^{t+1} \]
其中重点在于client每轮局部迭代中求解Moreau envelope的部分,即求解\(\hat{\theta}_k(w_k)\)的部分。这里\(\theta_k\)表示第\(k\)个client的个性化模型,\(\mu\)参数用于控制全局模型参数\(w_k\)相对于个性化模型的强度。其中Moreau envelope部分可以采用任意迭代方法求解。
FedEM—混合分布假设与EM算法FedEM[14]这篇论文另辟蹊径,没有关注模型的个性化,而是考虑从优化算法上去提高联邦学习模型的精度,其中采用的手段有两点,一点是基于client节点数据满足混合分布的假设,使每个client节点训练由\(M\)个子模型集成所得的模型;二点是针对混合分布的假设,采用EM算法来做参数估计,提高了模型的整体精度。
该算法中心化形式的每轮通信描述如下:
(1) 第\(k\)个client节点执行
-
从server接收全局模型参数\(w^t\)并令\(w_k = w^t\)。
-
对每一个模型成分\(m\)(\(m=1,..., M\))以及每一个局部样本\(i\)(\(i=1,...,n_t\))执行\(\text{E}\)步骤
\[q_k(z^{(i)}_k=m)\leftarrow \frac{\pi _{km}\cdot \text{exp}\left(-\mathcal{l}(h_{w_{km}}(x_k^{(i)}), y_k^{(i)})\right)} {\sum_{m'=1}^M \pi _{km'}\cdot \text{exp}\left(-\mathcal{l}(h_{w_{km'}}(x_k^{(i)}), y_k^{(i)})\right)} \]对每一个模型成分\(m\)执行\(\text{M}\)步骤
\[ \pi_{km} = \frac{\sum_{i=1}^{n_t} q_k(z^{(i)}_k=m)}{n_t} \]对每一个模型成分\(m\)执行\(J\)轮局部迭代:
\[w_{km} = w_{km} - \eta_j\sum_{i\in \mathcal{I}}q_k(z^{(i)}_k=m)\cdot \nabla_{w_{km}}\mathcal{l}(h_{w_{km}}(x_k^{(i)}), y_k^{(i)}) \]\(\mathcal{I}\)为每轮迭代有放回地从\(1,2,...|D_k|\)中采的随机样本索引集合
-
将新的\(w_k\)发往server。
(2) server节点执行
-
从\(K\)个client接收\(w_1^{t+1}、w_2^{t+1},...w_K^{t+1}\)
-
对每一个模型成分\(m\)按(加权)平均更新模型参数:
该算法的中心化形式在许多数据集上精度都取得了SOTA的水平。
该算法的去中心化形式的每轮通信描述如下:
第\(k\)个client节点执行:
-
对每一个模型成分\(m\)(\(m=1,..., M\))以及每一个局部样本\(i\)(\(i=1,...,n_t\))执行\(\text{E}\)步骤
\[q_k(z^{(i)}_k=m)\leftarrow \frac{\pi _{km}\cdot \text{exp}\left(-\mathcal{l}(h_{w_{km}}(x_k^{(i)}), y_k^{(i)})\right)} {\sum_{m'=1}^M \pi _{km'}\cdot \text{exp}\left(-\mathcal{l}(h_{w_{km'}}(x_k^{(i)}), y_k^{(i)})\right)} \]对每一个模型成分\(m\)执行\(\text{M}\)步骤
\[ \pi_{km} = \frac{\sum_{i=1}^{n_t} q_k(z^{(i)}_k=m)}{n_t} \]对每一个模型成分\(m\)执行\(J\)轮局部迭代:
\[w_{km} = w_{km} - \eta_j\sum_{i\in \mathcal{I}}q_k(z^{(i)}_k=m)\cdot \nabla_{w_{km}}\mathcal{l}(h_{w_{km}}(x_k^{(i)}), y_k^{(i)}) \]\(\mathcal{I}\)为每轮迭代有放回地从\(1,2,...|D_k|\)中采的随机样本索引集合
-
将新的\(w_k\)发往其邻居节点
-
从邻居节点接收新的\(w_k\)
-
对每一个模型成分\(m\)按(加权)平均更新模型参数:
(其中加权参数\(\lambda\)为随机初始化)
引用-
[1] Shamir O, Srebro N, Zhang T. Communication-efficient distributed optimization using an approximate newton-type method[C]//International conference on machine learning. PMLR, 2014: 1000-1008.
-
[2] Wang S, Roosta F, Xu P, et al. Giant: Globally improved approximate newton method for distributed optimization[J]. Advances in Neural Information Processing Systems, 2018, 31.
-
[3] Mahajan D, Agrawal N, Keerthi S S, et al. An efficient distributed learning algorithm based on effective local functional approximations[J]. arXiv preprint arXiv:1310.8418, 2013.
-
[4] Smith V, Forte S, Chenxin M, et al. CoCoA: A general framework for communication-efficient distributed optimization[J]. Journal of Machine Learning Research, 2018, 18: 230.
-
[5] Zhang Y, Duchi J, Wainwright M. Divide and conquer kernel ridge regression: A distributed algorithm with minimax optimal rates[J]. The Journal of Machine Learning Research, 2015, 16(1): 3299-3340.
-
[6] McMahan B, Moore E, Ramage D, et al. Communication-efficient learning of deep networks from decentralized data[C]//Artificial intelligence and statistics. PMLR, 2017: 1273-1282.
-
[7] Stich S U. Local SGD converges fast and communicates little[C]///International Conference on Learning Representations, 2018.
-
[8] Hard A, Rao K, Mathews R, et al. Federated learning for mobile keyboard prediction[J]. arXiv preprint arXiv:1811.03604, 2018.
-
[9] Tian Li, Anit Kumar Sahu, Manzil Zaheer, Maziar Sanjabi, Ameet Talwalkar, and Virginia
Smith. “Federated Optimization in Heterogeneous Networks”. In: Third MLSys Conference.2020. -
[10] Jiang Y, Konečný J, Rush K, et al. Improving federated learning personalization via model agnostic meta learning[J]. arXiv preprint arXiv:1909.12488, 2019.Presented at NeurIPS FL workshop 2019.
-
[11] Sim K C, Zadrazil P, Beaufays F. An investigation into on-device personalization of end-to-end automatic speech recognition models[J]. In Interspeech, 2019.
-
[12] Sattler F, Müller K R, Samek W. Clustered federated learning: Model-agnostic distributed multitask optimization under privacy constraints[J]. IEEE transactions on neural networks and learning systems, 2020, 32(8): 3710-3722.
-
[13]
T Dinh C, Tran N, Nguyen J. Personalized federated learning with moreau envelopes[J]. Advances in Neural Information Processing Systems, 2020, 33: 21394-21405. -
[14] Marfoq O, Neglia G, Bellet A, et al. Federated multi-task learning under a mixture of distributions[J]. Advances in Neural Information Processing Systems, 2021, 34.
-
[15]
Liu B, Guo Y, Chen X. PFA: Privacy-preserving Federated Adaptation for Effective Model Personalization[C]//Proceedings of the Web Conference 2021. 2021: 923-934.