最近研究了一下opencv的 MorphologyEx这个函数的替代功能, 他主要的特点是支持任意形状的腐蚀膨胀,对于灰度图,速度基本和CV的一致,但是 CV没有针对二值图做特殊处理,因此,这个函数对二值图的速度和灰度是一样的,但是这个函数,如果使用的话,估计大部分还是针对二值图像,因此,我对二值图做了特别优化,速度可以做到是CV这个函数的4倍左右。
MorphologyEx的主要功能是对灰度图进行相关形态学的处理,比如腐蚀、膨胀、开闭等计算,其代码可以在github上找到:https://github.com/opencv/opencv/blob/master/modules/imgproc/src/morph.dispatch.cpp#L1160
opencv的这个代码,1000多行,从头看到尾,就没有看到几句和算法本身有关的内容,仔细看下里面有下面的代码:
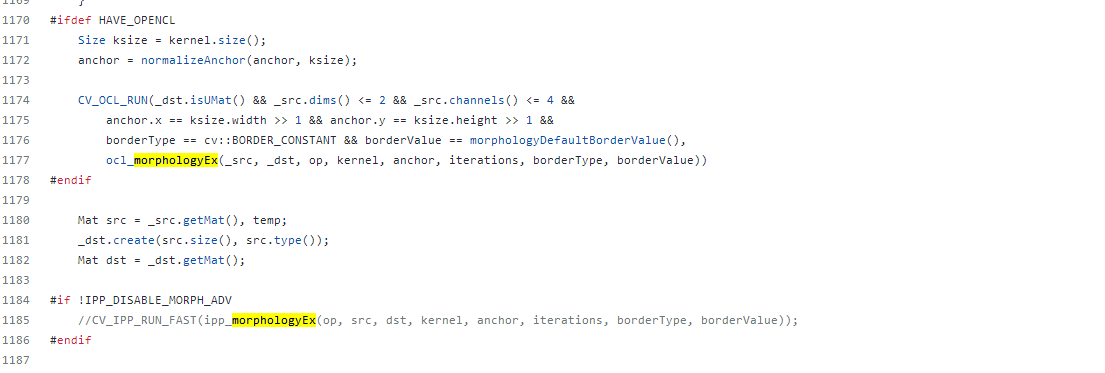
他不是调用Opencl就是使用IPP库,还是自己去想算法的优化吧。
其实这个算法的优化我在很多年前就一直在考虑,只是一直么有动手,主要是无思路。最近在研究模板匹配的时候,因为有需求,做了下带蒙版功能的NCC匹配,对于这个类似的算法也就有了想法。
在正常情况下,我们的核是矩形的或者是圆形的,对于矩形核,在SSE图像算法优化系列七:基于SSE实现的极速的矩形核腐蚀和膨胀(最大值和最小值)算法 一文中已经提出了优化算法,对于圆形半径,在【短道速滑八】圆形半径的图像最大值和最小值算法的实现及其实时优化(非二值图) 一文也提出了解决方案,两种方案都非常的高效和快速。
如果是任意形状的核,考虑到其无固定的规律,上述常规的优化手段都无法完成,如何弄呢。
我对这个算法想过很久,那么最近我得到的结论是肯定不能整体做优化,我想到的就是把蒙版区域按水平方向或者垂直方向分割成一条一条或者一列一列的小块,每个小块单独执行类似的算法,那么比如一个9*9的蒙版,如果其中的连续的小块有20个,那最多也就是标准矩形算法的20倍耗时(实际是不需要的,以为有很多公共计算),而矩形算法的速度是非常非常高效的。
实践了下,这个做法是有效的,而且也是相对来说高效的,但是后面想了下,为什么要分割成一条一条的呢,毕竟有很多条条的宽度或者高度是一样的,可以把他们作为一个整体合并成一个Rectangle,对一个Rectanle进行处理,和标准的矩形核的算法也不是一样的吗。
如下所示,如果按照列方向一次一个列,则有31个列,但是如果是将相同高的列合并,则只有19个,数量减少了近一半。

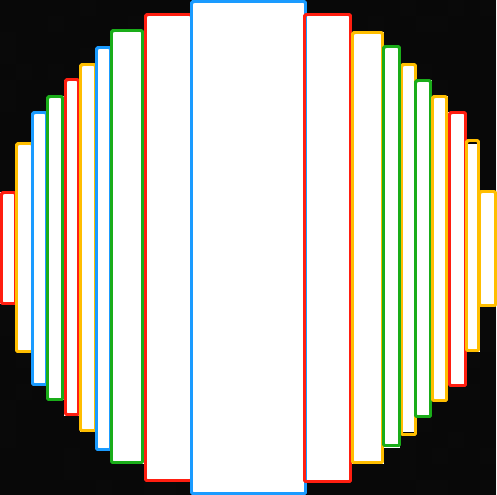
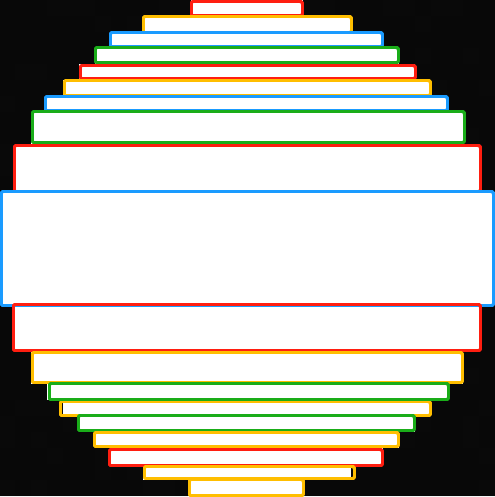
原图 列方向的分块矩形 行方向的分块矩形
实践表明,这种处理后,整体能有效的提高计算速度。
至于是选择列方向的分块矩形还是行方向的,则和算法本身的优化有一定的关系,比如在本例中,由于SIMD的特性,我们在计算腐蚀或者膨胀的时候,利用的有关的G值和H值在垂直方向计算时可方便的使用SIMD指令进行比较,因此,选择列方向的分块则更为有利。
那么对于二值图像的腐蚀和膨胀,我们在超越halcon速度的二值图像的腐蚀和膨胀,实现目前最快的半径相关类算法(附核心源码) 一文中有提高一种更为特别的优化手段。那么这个手段但让也可以用到本例中来。而在Opencv中,MorphologyEx函数是没有对这个做特殊处理的。
我们做下简单的速度比较:
对一副 500万像素的图进行 31*31的 椭圆蒙版进行处理,本例耗时约为95ms, CV耗时约为 250ms。
但是奇怪的是,如果在CV中把蒙版的尺寸设置为偶数,比如30*30,其执行速度会快很多,比如同样上述图,CV的耗时只有78毫秒了,和我这里速度差不多,目前还不知道这个问题是怎么引起的。
相关测试代码如下:
IplConvKernel *kernel0 = cvCreateStructuringElementEx(31, 31, 15, 15, CV_SHAPE_ELLIPSE); for (int i = 0; i < 100; i++) cvMorphologyEx(Src, Dest, NULL, kernel0, CV_MOP_DILATE, 1); cvReleaseStructuringElement(&kernel0); QueryPerformanceCounter(&t2); printf("Use Time:%f\n", (t2.QuadPart - t1.QuadPart)*1.0 / tc.QuadPart * 1000); IplConvKernel *kernel1 = cvCreateStructuringElementEx(30, 30, 15, 15, CV_SHAPE_ELLIPSE); QueryPerformanceCounter(&t1); for (int i = 0; i < 100; i++) cvMorphologyEx(Src, Dest, NULL, kernel1, CV_MOP_DILATE, 1); cvReleaseStructuringElement(&kernel1); QueryPerformanceCounter(&t2); printf("Use Time:%f\n", (t2.QuadPart - t1.QuadPart)*1.0 / tc.QuadPart * 1000); IplConvKernel *kernel2 = cvCreateStructuringElementEx(15, 15, 7, 7, CV_SHAPE_ELLIPSE); QueryPerformanceCounter(&t1); for (int i = 0; i < 100; i++) cvMorphologyEx(Src, Dest, NULL, kernel2, CV_MOP_DILATE, 1); cvReleaseStructuringElement(&kernel2); QueryPerformanceCounter(&t2); printf("Use Time:%f\n", (t2.QuadPart - t1.QuadPart)*1.0 / tc.QuadPart * 1000); IplConvKernel *kernel3 = cvCreateStructuringElementEx(14, 14, 7, 7, CV_SHAPE_ELLIPSE); QueryPerformanceCounter(&t1); for (int i = 0; i < 100; i++) cvMorphologyEx(Src, Dest, NULL, kernel3, CV_MOP_DILATE, 1); cvReleaseStructuringElement(&kernel3); QueryPerformanceCounter(&t2); printf("Use Time:%f\n", (t2.QuadPart - t1.QuadPart)*1.0 / tc.QuadPart * 1000);
CV的耗时统计如下(100次循环计算的耗时)。
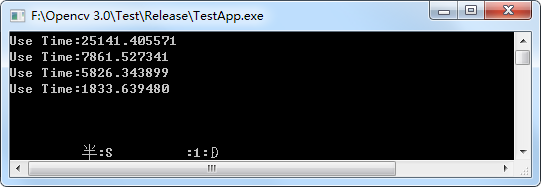
如果是同样一份大小的二值图像,在本例只需22ms,CV的耗时则还是和上面的一样。
这里也不得不说一句,Intel的IPP的优化功能真的也还是不错。
使用halcon的也做了类似的测试,halcon里对于规则的图像有一些特别的函数,比如 gray_dilation_rect, gray_dilation_shape,他的这些算子和我的标准优化的版本速度差不多。而对于其他的自定义形状,则要使用read_gray_se读取一个固定格式的文件。当然对于我们上面使用的椭圆, halcon已经有个一个定义好的函数gen_disc_se。
对于椭圆,在Halcon中我用下述代码测试:
read_image (Image, 'd:/1.bmp') gen_disc_se (SE, 'byte', 31, 31, 0) for J := 0 to 100 - 1 by 1 gray_dilation(Image, SE, ImageDilation) endfor
得到的速度结果非常吓人,循环100次也只要1600ms,那意味着每次只要16ms,比我这里要快5倍多,真是牛逼,然后看了下gray_dilation的说明文档,在Parallelization一项里有这个说明:Automatically parallelized on internal data level.即在在内部数据级别自动并行。同时观察上述代码运行时的CPU运行情况,CPU的使用率高达80%左右,我个人分析他内部是做了多核并行的。这样的话我还可以接受的。我的机器是4核单位,如果我的速度除以4,嗨嗨。
说到这,我正好也抽空研究了下read_gray_se这个函数,如果我要在Halcon里实现其他非规则形状的腐蚀,只能通过这个函数,这个函数的需要从文件里读取一些列数据,而这个文件我在百度搜索,基本没看到有详细的说明,Halcon帮助文档里到时有说明,不过有点晦涩,我这里正好解释下,也当做给自己做个笔记,不然时间长了,我自己也不记得了。
他对文件(文本文件)的要求如下:
第一行指明类型,可以是一下三个字符中的一种: 'byte', 'uint2' or 'real' 注意不要带引号,对于图像数据,一般用byte
第二行,是指 structuring element 的尺寸,宽度 + 空格 + 高度
第三行,这个比较重要,他的意思我们可以这样理解, 就是按照单行方向考虑,你需要计算腐蚀和膨胀的 连续区域的总数量。
接下来的每一行数据, 都必然是3个数字,每个数字之间用空格隔开, 第一个数据是指这个行所在的行号(以0为下标起点),第二个数据只区域的起点, 第三个数据只区域的 终点。
这些行的行数必须和第三行的数字对应,而且不能超过高度和宽度的范围。
接下来的数据就是Halcon独有的了,我的和CV的都不具有这个功能,他还能指定structuring element 每个位置对应的偏移量值,就在对应位置的元素值加上这个偏移量值作为计算腐蚀和膨胀的依据,可正可负。这个确实比较强大,但是测试表明,如果有这些值,函数的计算速度可能会急剧下降,比如前面的测试代码中gen_disc_se (SE, 'byte', 31, 31, 0), 如果更改为gen_disc_se (SE, 'byte', 31, 31, 1),100次的速度会立即增加到8秒多。
比如前面对应的31*31的椭圆区域的SE就可以用下述字符描述:
byte 31 31 31 0 12 18 1 9 21 2 7 23 3 6 24 4 5 25 5 4 26 6 3 27 7 2 28 8 2 28 9 1 29 10 1 29 11 1 29 12 0 30 13 0 30 14 0 30 15 0 30 16 0 30 17 0 30 18 0 30 19 1 29 20 1 29 21 1 29 22 2 28 23 2 28 24 3 27 25 4 26 26 5 25 27 6 24 28 7 23 29 9 21 30 12 18
不过,由这个结构,也可以窥探到,Halcon内部的Region结构可能用的是这种单行的RLE编码,而不是基于Rectangle的。
上面的例子可能不是很好,因为他正好是一行只有一个结构,其实一行是可以是有多个,比如下面的数据:
byte 5 5 8 0 1 4 1 0 0 1 3 3 2 2 3 2 4 4 3 0 4 4 0 1 4 4 4
本例相关测试结果可参考: https://files.cnblogs.com/files/Imageshop/MaskFilter.rar?t=1652089081

如果想时刻关注本人的最新文章,也可关注公众号:
