- [源码解析] TensorFlow 分布式之 MirroredStrategy 分发计算
- 0x1. 运行
- 1.1 基类 Strategy
- 1.2 StrategyExtendedV1
- 1.3 MirroredExtended
- 0x2. mirrored_run
- 2.1 call_for_each_replica
- 2.2 建立线程
- 2.3 线程定义
- 0x3. Context
- 3.1 ensure_initialized
- 3.2 TFE_ContextSetServerDef
- 3.3 EagerContextDistributedManager
- 3.4 UpdateContextWithServerDef
- 3.5 CreateRemoteContexts
- 3.6 CreateContextAsync
- 3.6.1 EagerClient
- 3.6.2 GrpcEagerClient
- 0x4. 通信协议
- 4.1 建立远端上下文
- 4.2 如何运行
- 0x5. Eager Service
- 5.1 AsyncServiceInterface
- 5.2 GrpcEagerServiceImpl
- 5.3 运行线程
- 5.4 业务实现 EagerServiceImpl
- 5.5 建立远端上下文
- 0x6. FunctionLibraryRuntime
- 6.1 接口 DistributedFunctionLibraryRuntime
- 6.2 EagerClusterFunctionLibraryRuntime
- 6.2.1 初始化
- 6.2.2 运行 component
- 6.3 远端 Worker
- 6.3.1 GrpcEagerServiceImpl
- 6.3.2 EagerServiceImpl
- 0x7. 总结
- 0xFF 参考
- 0x1. 运行
前一篇我们分析了MirroredStrategy 的基本架构和如何更新变量,本文我们来看看 MirroredStrategy 如何运行。具体希望了解的是,MirroredStrategy 通过什么方式在远端设备节点上运行训练方法(如何分发计算),MirroredStrategy 和我们之前分析的 TF 运行时怎么联系起来?和 master,worker 这些概念怎么联系起来?
安利两个github,都是非常好的学习资料,推荐。
https://github.com/yuhuiaws/ML-study
https://github.com/Jack47/hack-SysML
另外推荐西门宇少的最新大作让Pipeline在Transformer LM上沿着Token level并行起来——TeraPipe。
本系列其他文章是:
[翻译] TensorFlow 分布式之论文篇 "TensorFlow : Large-Scale Machine Learning on Heterogeneous Distributed Systems"
[翻译] TensorFlow 分布式之论文篇 "Implementation of Control Flow in TensorFlow"
[源码解析] TensorFlow 分布式环境(1) --- 总体架构
[源码解析] TensorFlow 分布式环境(2)---Master 静态逻辑
[源码解析] TensorFlow 分布式环境(3)--- Worker 静态逻辑
[源码解析] TensorFlow 分布式环境(4) --- WorkerCache
[源码解析] TensorFlow 分布式环境(5) --- Session
[源码解析] TensorFlow 分布式环境(7) --- Worker 动态逻辑
[源码解析] TensorFlow 分布式环境(8) --- 通信机制
[翻译] 使用 TensorFlow 进行分布式训练
[源码解析] TensorFlow 分布式 DistributedStrategy 之基础篇
[源码解析] TensorFlow 之 分布式变量
[源码解析] TensorFlow 分布式之 MirroredStrategy
0x1. 运行代码示例如下,我们需要从 strategy.run 开始看。
>>> def run(strategy):
... with strategy.scope():
... v = tf.Variable(0.)
... strategy.run(step_fn, args=(v,))
... return v
Strategy 的 run 方法是用 tf.distribution 对象分发计算的主要手段。它在每个副本上调用 fn 。如果 args 或 kwargs 有 tf.distribution.DistributedValues,当 "fn"在一个特定的副本上执行时,它将与对应于该副本的 "tf.distributed.DistributedValues" 的组件一起执行。
当 fn 在副本上下文被调用,fn 可以调用 tf.distribution.get_replica_context() 来访问诸如 all_reduce 等成员。 args 或 kwargs 中的所有参数可以是一个嵌套的张量结构,例如一个张量列表,在这种情况下,args 和 kwargs 将被传递给在每个副本上调用的 fn 。或者 args 或 kwargs 可以是包含张量或复合张量的 tf.compat.v1.TensorInfo.CompositeTensor 的 tf.distributedValues ,在这种情况下,每个 fn 调用将得到与其副本对应的 tf.distributedValues 的组件。
重要的是:根据 tf.distribution.Strategy 的实现和是否启用 eager execution, fn 可能被调用一次或多次。如果 fn 被注解为 tf.function 或者 tf.distribution.Strategy.run 在 tf.function 中被调用(默认情况下 tf.function 中禁止急切执行),fn 在每个副本中会被调用一次以生成 Tensorflow 图,然后被重新用于新输入的执行。
具体在 run 方法之中就是调用了 call_for_each_replica。
def run(self, fn, args=(), kwargs=None, options=None):
"""Invokes fn on each replica, with the given arguments.
This method is the primary way to distribute your computation with a
tf.distribute object. It invokes fn on each replica. If args or kwargs
have tf.distribute.DistributedValues , such as those produced by a
tf.distribute.DistributedDataset from
tf.distribute.Strategy.experimental_distribute_dataset or
tf.distribute.Strategy.distribute_datasets_from_function ,
when fn is executed on a particular replica, it will be executed with the
component of tf.distribute.DistributedValues that correspond to that
replica.
fn is invoked under a replica context. fn may call
tf.distribute.get_replica_context() to access members such as
all_reduce . Please see the module-level docstring of tf.distribute for the
concept of replica context.
All arguments in args or kwargs can be a nested structure of tensors,
e.g. a list of tensors, in which case args and kwargs will be passed to
the fn invoked on each replica. Or args or kwargs can be
tf.distribute.DistributedValues containing tensors or composite tensors,
i.e. tf.compat.v1.TensorInfo.CompositeTensor , in which case each fn call
will get the component of a tf.distribute.DistributedValues corresponding
to its replica. Note that arbitrary Python values that are not of the types
above are not supported.
IMPORTANT: Depending on the implementation of tf.distribute.Strategy and
whether eager execution is enabled, fn may be called one or more times. If
fn is annotated with tf.function or tf.distribute.Strategy.run is
called inside a tf.function (eager execution is disabled inside a
tf.function by default), fn is called once per replica to generate a
Tensorflow graph, which will then be reused for execution with new inputs.
Otherwise, if eager execution is enabled, fn will be called once per
replica every step just like regular python code.
Args:
fn: The function to run on each replica.
args: Optional positional arguments to fn . Its element can be a tensor,
a nested structure of tensors or a tf.distribute.DistributedValues .
kwargs: Optional keyword arguments to fn . Its element can be a tensor,
a nested structure of tensors or a tf.distribute.DistributedValues .
options: An optional instance of tf.distribute.RunOptions specifying
the options to run fn .
Returns:
Merged return value of fn across replicas. The structure of the return
value is the same as the return value from fn . Each element in the
structure can either be tf.distribute.DistributedValues , Tensor
objects, or Tensor s (for example, if running on a single replica).
"""
del options
if not isinstance(args, (list, tuple)):
raise ValueError(
"positional args must be a list or tuple, got {}".format(type(args)))
with self.scope():
# tf.distribute supports Eager functions, so AutoGraph should not be
# applied when the caller is also in Eager mode.
fn = autograph.tf_convert(
fn, autograph_ctx.control_status_ctx(), convert_by_default=False)
return self._extended.call_for_each_replica(fn, args=args, kwargs=kwargs)
因为 StrategyExtendedV1 是 StrategyExtendedV2 的派生类,所以无论是 StrategyExtendedV1 还是 StrategyExtendedV2 都会调用到 call_for_each_replica 方法。
def call_for_each_replica(self, fn, args=(), kwargs=None):
"""Run fn once per replica.
fn may call tf.get_replica_context() to access methods such as
replica_id_in_sync_group and merge_call() .
merge_call() is used to communicate between the replicas and
re-enter the cross-replica context. All replicas pause their execution
having encountered a merge_call() call. After that the
merge_fn -function is executed. Its results are then unwrapped and
given back to each replica call. After that execution resumes until
fn is complete or encounters another merge_call() . Example:
```python
# Called once in "cross-replica" context.
def merge_fn(distribution, three_plus_replica_id):
# sum the values across replicas
return sum(distribution.experimental_local_results(three_plus_replica_id))
# Called once per replica in distribution , in a "replica" context.
def fn(three):
replica_ctx = tf.get_replica_context()
v = three + replica_ctx.replica_id_in_sync_group
# Computes the sum of the v values across all replicas.
s = replica_ctx.merge_call(merge_fn, args=(v,))
return s + v
with distribution.scope():
# in "cross-replica" context
...
merged_results = distribution.run(fn, args=[3])
# merged_results has the values from every replica execution of fn .
# This statement prints a list:
print(distribution.experimental_local_results(merged_results))
```
Args:
fn: function to run (will be run once per replica).
args: Tuple or list with positional arguments for fn .
kwargs: Dict with keyword arguments for fn .
Returns:
Merged return value of fn across all replicas.
"""
_require_cross_replica_or_default_context_extended(self)
if kwargs is None:
kwargs = {}
with self._container_strategy().scope():
return self._call_for_each_replica(fn, args, kwargs)
_call_for_each_replica 是在 MirroredExtended 实现的,其调用了 mirrored_run。
def _call_for_each_replica(self, fn, args, kwargs):
return mirrored_run.call_for_each_replica(
self._container_strategy(), fn, args, kwargs)
mirrored_run 指的是 mirrored_run.py 文件提供的内容。
2.1 call_for_each_replica在 mirrored_run 之中,首先来到了 call_for_each_replica,其目的是在每个设备上调用 fn。
def call_for_each_replica(strategy, fn, args=None, kwargs=None):
"""Call fn on each worker devices(replica).
It's highly recommended to wrap the call to this function inside a
tf.function , otherwise the performance is poor.
Args:
strategy: tf.distribute.Strategy .
fn: function to call on each worker devices.
args: positional arguments to fn .
kwargs: keyword arguments to fn .
Returns:
Wrapped returned value of fn from all replicas.
"""
if args is None:
args = ()
if kwargs is None:
kwargs = {}
if isinstance(fn, def_function.Function):
# Don't lift up the tf.function decoration if fn is compiled with XLA
# and all devices are GPU. In this case we will use collectives to do
# cross-device communication, thus no merge_call is in the path.
if fn._jit_compile and all(
[_is_gpu_device(d) for d in strategy.extended.worker_devices]):
return _call_for_each_replica(strategy, fn, args, kwargs)
if strategy not in _cfer_fn_cache:
_cfer_fn_cache[strategy] = weakref.WeakKeyDictionary()
wrapped = _cfer_fn_cache[strategy].get(fn)
if wrapped is None:
# We need to wrap fn such that it triggers _call_for_each_replica inside
# the tf.function. We use _clone() instead of @tf.function wrapped
# call_for_each_replica() because we would like to retain the arguments to
# the @tf.function decorator of fn.
wrapped = fn._clone(
python_function=functools.partial(call_for_each_replica, strategy,
fn.python_function))
_cfer_fn_cache[strategy][fn] = wrapped
return wrapped(args, kwargs)
else:
# When a tf.function is wrapped to trigger _call_for_each_replica (see
# the other branch above), AutoGraph stops conversion at
# _call_for_each_replica itself (TF library functions are allowlisted).
# This makes sure that the Python function that originally passed to
# the tf.function is still converted.
fn = autograph.tf_convert(fn, autograph_ctx.control_status_ctx())
return _call_for_each_replica(strategy, fn, args, kwargs)
在 _call_for_each_replica 之中,会建立 _MirroredReplicaThread 来运行。每个设备会起动一个线程,并行执行fn,直至所有 fn 都完成。
def _call_for_each_replica(distribution, fn, args, kwargs):
"""Run fn in separate threads, once per replica/worker device.
Args:
distribution: the DistributionStrategy object.
fn: function to run (will be run once per replica, each in its own thread).
args: positional arguments for fn
kwargs: keyword arguments for fn .
Returns:
Merged return value of fn across all replicas.
Raises:
RuntimeError: If fn() calls get_replica_context().merge_call() a different
number of times from the available devices.
"""
run_concurrently = False
if not context.executing_eagerly():
# Needed for per-thread device, etc. contexts in graph mode.
ops.get_default_graph().switch_to_thread_local()
coord = coordinator.Coordinator(clean_stop_exception_types=(_RequestedStop,))
shared_variable_store = {}
devices = distribution.extended.worker_devices
threads = []
for index in range(len(devices)): # 遍历设备
variable_creator_fn = shared_variable_creator.make_fn(
shared_variable_store, index)
t = _MirroredReplicaThread(distribution, coord, index, devices,
variable_creator_fn, fn,
distribute_utils.caching_scope_local,
distribute_utils.select_replica(index, args),
distribute_utils.select_replica(index, kwargs))
threads.append(t)
for t in threads:
t.start()
# When fn starts should_run event is set on _MirroredReplicaThread
# ( MRT ) threads. The execution waits until
# MRT.has_paused is set, which indicates that either fn is
# complete or a get_replica_context().merge_call() is called. If fn is
# complete, then MRT.done is set to True. Otherwise, arguments
# of get_replica_context().merge_call from all paused threads are grouped
# and the merge_fn is performed. Results of the
# get_replica_context().merge_call are then set to MRT.merge_result .
# Each such get_replica_context().merge_call call returns the
# MRT.merge_result for that thread when MRT.should_run event
# is reset again. Execution of fn resumes.
try:
with coord.stop_on_exception():
all_done = False
while not all_done and not coord.should_stop():
done = []
if run_concurrently:
for t in threads:
t.should_run.set()
for t in threads:
t.has_paused.wait()
t.has_paused.clear()
if coord.should_stop():
return None
done.append(t.done)
else:
for t in threads:
t.should_run.set()
t.has_paused.wait()
t.has_paused.clear()
if coord.should_stop():
return None
done.append(t.done)
if coord.should_stop():
return None
all_done = all(done)
if not all_done:
if any(done):
raise RuntimeError("Some replicas made a different number of "
"replica_context().merge_call() calls.")
# get_replica_context().merge_call() case
merge_args = distribute_utils.regroup(
tuple(t.merge_args for t in threads))
merge_kwargs = distribute_utils.regroup(
tuple(t.merge_kwargs for t in threads))
# We capture the name_scope of the MRT when we call merge_fn
# to ensure that if we have opened a name scope in the MRT,
# it will be respected when executing the merge function. We only
# capture the name_scope from the first MRT and assume it is
# the same for all other MRTs.
mtt_captured_name_scope = threads[0].captured_name_scope
mtt_captured_var_scope = threads[0].captured_var_scope
# Capture and merge the control dependencies from all the threads.
mtt_captured_control_deps = set()
for t in threads:
mtt_captured_control_deps.update(t.captured_control_deps)
with ops.name_scope(mtt_captured_name_scope),\
ops.control_dependencies(mtt_captured_control_deps), \
variable_scope.variable_scope(mtt_captured_var_scope):
merge_result = threads[0].merge_fn(distribution, *merge_args,
**merge_kwargs)
for r, t in enumerate(threads):
t.merge_result = distribute_utils.select_replica(r, merge_result)
finally:
for t in threads:
t.should_run.set()
coord.join(threads)
return distribute_utils.regroup(tuple(t.main_result for t in threads))
_MirroredReplicaThread 的定义比较好理解:此线程在一个设备上运行方法。这里重要的是入口处调用了 context.ensure_initialized()。所以我们接下来要看看 Context 概念。
class _MirroredReplicaThread(threading.Thread):
"""A thread that runs() a function on a device."""
def __init__(self, dist, coord, replica_id, devices, variable_creator_fn, fn,
caching_scope, args, kwargs):
super(_MirroredReplicaThread, self).__init__()
self.coord = coord
self.distribution = dist
self.devices = devices
self.replica_id = replica_id
self.replica_id_in_sync_group = (
dist.extended._get_replica_id_in_sync_group(replica_id))
self.variable_creator_fn = variable_creator_fn
# State needed to run and return the results of fn .
self.main_fn = fn
self.main_args = args
self.main_kwargs = kwargs
self.main_result = None
self.done = False
# State needed to run the next merge_call() (if any) requested via
# ReplicaContext.
self.merge_fn = None
self.merge_args = None
self.merge_kwargs = None
self.merge_result = None
self.captured_name_scope = None
self.captured_var_scope = None
try:
self.caching_scope_entered = caching_scope.new_cache_scope_count
self.caching_scope_exited = caching_scope.cache_scope_exited_count
except AttributeError:
self.caching_scope_entered = None
self.caching_scope_exited = None
# We use a thread.Event for the main thread to signal when this
# thread should start running ( should_run ), and another for
# this thread to transfer control back to the main thread
# ( has_paused , either when it gets to a
# get_replica_context().merge_call or when fn returns). In
# either case the event starts cleared, is signaled by calling
# set(). The receiving thread waits for the signal by calling
# wait() and then immediately clearing the event using clear().
self.should_run = threading.Event()
self.has_paused = threading.Event()
# These fields have to do with inheriting various contexts from the
# parent thread:
context.ensure_initialized() # 确保初始化上下文
ctx = context.context() # 获取上下文
self.in_eager = ctx.executing_eagerly()
self.record_thread_local_summary_state()
self.record_thread_local_eager_context_state()
self.context_device_policy = (
pywrap_tfe.TFE_ContextGetDevicePlacementPolicy(
ctx._context_handle))
self.graph = ops.get_default_graph()
with ops.init_scope():
self._init_in_eager = context.executing_eagerly()
self._init_graph = ops.get_default_graph()
self._variable_creator_stack = self.graph._variable_creator_stack[:]
self._var_scope = variable_scope.get_variable_scope()
# Adding a "/" at end lets us re-enter this scope later.
self._name_scope = self.graph.get_name_scope()
if self._name_scope:
self._name_scope += "/"
if self.replica_id > 0:
if not self._name_scope:
self._name_scope = ""
self._name_scope += "replica_%d/" % self.replica_id
def run(self):
self.should_run.wait()
self.should_run.clear()
try:
if self.coord.should_stop():
return
self.restore_thread_local_summary_state()
self.restore_thread_local_eager_context_state()
if (self.caching_scope_entered is not None and
self.caching_scope_exited is not None):
distribute_utils.caching_scope_local.new_cache_scope_count = self.caching_scope_entered
distribute_utils.caching_scope_local.cache_scope_exited_count = self.caching_scope_exited
with self.coord.stop_on_exception(), \
_enter_graph(self._init_graph, self._init_in_eager), \
_enter_graph(self.graph, self.in_eager,
self._variable_creator_stack), \
context.device_policy(self.context_device_policy), \
_MirroredReplicaContext(self.distribution,
self.replica_id_in_sync_group), \
# 这里设定了某一个设备
ops.device(self.devices[self.replica_id]), \
ops.name_scope(self._name_scope), \
variable_scope.variable_scope(
self._var_scope, reuse=self.replica_id > 0), \
variable_scope.variable_creator_scope(self.variable_creator_fn):
self.main_result = self.main_fn(*self.main_args, **self.main_kwargs)
self.done = True
finally:
self.has_paused.set()
def record_thread_local_summary_state(self):
"""Record the thread local summary state in self."""
# TODO(slebedev): is this still relevant? the referenced bug is closed.
summary_state = summary_ops_v2._summary_state
self._summary_step = summary_state.step
self._summary_writer = summary_state.writer
self._summary_recording = summary_state.is_recording
self._summary_recording_distribution_strategy = (
summary_state.is_recording_distribution_strategy)
def restore_thread_local_summary_state(self):
"""Restore thread local summary state from self."""
summary_state = summary_ops_v2._summary_state
summary_state.step = self._summary_step
summary_state.writer = self._summary_writer
summary_state.is_recording = self._summary_recording
summary_state.is_recording_distribution_strategy = (
self._summary_recording_distribution_strategy)
def record_thread_local_eager_context_state(self):
ctx = context.context()
eager_context_state = ctx._thread_local_data
self._eager_context_op_callbacks = eager_context_state.op_callbacks
def restore_thread_local_eager_context_state(self):
ctx = context.context()
eager_context_state = ctx._thread_local_data
eager_context_state.op_callbacks = self._eager_context_op_callbacks
目前逻辑如下:
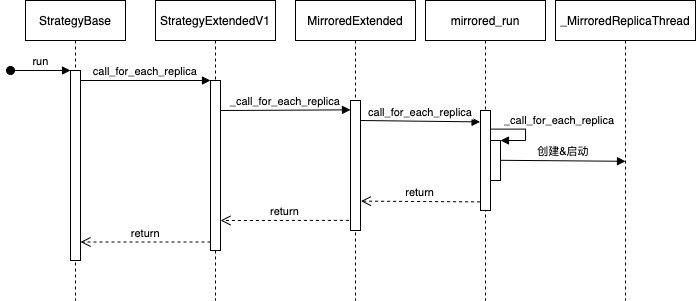
图 1 如何运行
具体逻辑大致如下,这里假定有两个设备,对应启动了两个线程。

现在本地启动了多个线程进行训练,我们接下来看看如何把计算分配到远端工作者之上。
0x3. Context之前我们接触的 TF 分布式都是基于 session 之上,但是在 TF 2 之中已经取消了 Session,我们需要找到一个和 session 对应的概念,这就是 context。Session 的作用是 TF runtime 交互,context 也有类似的作用,context 保存需要和 runtime 交互的所有信息,但是其生命周期远远比 session 长。可以认为 Context 在某种程度上起到了 TF 1 Session 概念环境之中 Master 的作用。
其定义如下,可以从注释之中看到,TF计划将其与Eager的关系再明确一下:
# TODO(agarwal): rename to EagerContext / EagerRuntime ?
# TODO(agarwal): consider keeping the corresponding Graph here.
class Context(object):
"""Environment in which eager operations execute."""
# TODO(agarwal): create and link in some documentation for `execution_mode`.
def __init__(self,
config=None,
device_policy=None,
execution_mode=None,
server_def=None):
"""Creates a new Context.
Args:
config: (Optional.) A `ConfigProto` protocol buffer with configuration
options for the Context. Note that a lot of these options may be
currently unimplemented or irrelevant when eager execution is enabled.
device_policy: (Optional.) What policy to use when trying to run an
operation on a device with inputs which are not on that device. When set
to None, an appropriate value will be picked automatically. The value
picked may change between TensorFlow releases. Defaults to
DEVICE_PLACEMENT_SILENT.
Valid values:
- DEVICE_PLACEMENT_EXPLICIT: raises an error if the placement is not
correct.
- DEVICE_PLACEMENT_WARN: copies the tensors which are not on the right
device but raises a warning.
- DEVICE_PLACEMENT_SILENT: silently copies the tensors. This might hide
performance problems.
- DEVICE_PLACEMENT_SILENT_FOR_INT32: silently copies int32 tensors,
raising errors on the other ones.
execution_mode: (Optional.) Policy controlling how operations dispatched
are actually executed. When set to None, an appropriate value will be
picked automatically. The value picked may change between TensorFlow
releases.
Valid values:
- SYNC: executes each operation synchronously.
- ASYNC: executes each operation asynchronously. These operations may
return "non-ready" handles.
server_def: (Optional.) A tensorflow::ServerDef proto. Enables execution
on remote devices. GrpcServers need to be started by creating an
identical server_def to this, and setting the appropriate task_indexes,
so that the servers can communicate. It will then be possible to execute
operations on remote devices.
Raises:
ValueError: If execution_mode is not valid.
"""
# This _id is used only to index the tensor caches.
# TODO(iga): Remove this when tensor caches are moved to C++.
self._id = _context_id_counter.increment_and_get()
self._tensor_cache_deleter = _TensorCacheDeleter(self._id)
_tensor_caches_map[self._id] = _TensorCaches()
self._config = config
self._thread_local_data = pywrap_tfe.EagerContextThreadLocalData(
self,
is_eager=lambda: default_execution_mode == EAGER_MODE,
device_spec=_starting_device_spec)
self._context_switches = _ContextSwitchStack(self.executing_eagerly())
self._context_handle = None
self._context_devices = None
self._seed = None
self._initialize_lock = threading.Lock()
self._initialized = False
if device_policy is None:
device_policy = DEVICE_PLACEMENT_SILENT
self._device_policy = device_policy
self._mirroring_policy = None
if execution_mode not in (None, SYNC, ASYNC):
raise ValueError("execution_mode should be None/SYNC/ASYNC. Got %s" %
execution_mode)
if execution_mode is None:
execution_mode = SYNC
self._default_is_async = execution_mode == ASYNC
self._use_tfrt = is_tfrt_enabled()
self._use_tfrt_distributed_runtime = None
self._run_eager_op_as_function = run_eager_op_as_function_enabled()
self._server_def = server_def
self._collective_ops_server_def = None
self._collective_leader = None
self._collective_scoped_allocator_enabled_ops = None
self._collective_use_nccl_communication = None
self._collective_device_filters = None
self._coordination_service = None
self._device_lock = threading.Lock()
self._physical_devices = None
self._physical_device_to_index = None
self._visible_device_list = []
self._memory_growth_map = None
self._virtual_device_map = {}
# Values set after construction
self._optimizer_jit = None
self._intra_op_parallelism_threads = None
self._inter_op_parallelism_threads = None
self._soft_device_placement = None
self._log_device_placement = None
self._enable_mlir_graph_optimization = None
self._optimizer_experimental_options = {}
_python_eager_context_create_counter.get_cell().increase_by(1)
我们接下来按照初始化流程走一下。
3.1 ensure_initializedPython context 是 CPP context 的 wrapper,ensure_initialized 是用来确保初始化的方法。
def ensure_initialized():
"""Initialize the context."""
context().ensure_initialized()
具体代码如下,其中调用了很多名字类似 TFE_ContextOptionsSetXXX 的设置函数。
def ensure_initialized(self):
"""Initialize handle and devices if not already done so."""
if self._initialized:
return
with self._initialize_lock:
if self._initialized:
return
assert self._context_devices is None
opts = pywrap_tfe.TFE_NewContextOptions()
try:
config_str = self.config.SerializeToString()
pywrap_tfe.TFE_ContextOptionsSetConfig(opts, config_str)
if self._device_policy is not None:
pywrap_tfe.TFE_ContextOptionsSetDevicePlacementPolicy(
opts, self._device_policy)
if self._mirroring_policy is not None:
pywrap_tfe.TFE_ContextOptionsSetMirroringPolicy(
opts, self._mirroring_policy)
if self._default_is_async == ASYNC:
pywrap_tfe.TFE_ContextOptionsSetAsync(opts, True)
if self._use_tfrt is not None:
pywrap_tfe.TFE_ContextOptionsSetTfrt(opts, self._use_tfrt)
if self._use_tfrt is not None and \
self._use_tfrt_distributed_runtime is not None:
pywrap_tfe.TFE_ContextOptionsSetTfrtDistributedRuntime(
opts, self._use_tfrt_distributed_runtime)
pywrap_tfe.TFE_ContextOptionsSetRunEagerOpAsFunction(
opts, self._run_eager_op_as_function)
context_handle = pywrap_tfe.TFE_NewContext(opts)
finally:
pywrap_tfe.TFE_DeleteContextOptions(opts)
if self._server_def is not None:
server_def_str = self._server_def.SerializeToString()
pywrap_tfe.TFE_ContextSetServerDef(context_handle, _KEEP_ALIVE_SECS,
server_def_str)
elif self._collective_ops_server_def is not None:
server_def_str = self._collective_ops_server_def.SerializeToString()
pywrap_tfe.TFE_EnableCollectiveOps(context_handle, server_def_str)
self._context_handle = context_handle
self._initialize_logical_devices()
self._initialized = True
我们用 TFE_ContextSetServerDef 来看看,其代码在 tensorflow/c/eager/c_api.cc。主要功能是调用了 GetDistributedManager() 的方法。
// Set server_def on the context, possibly updating it.
TF_CAPI_EXPORT extern void TFE_ContextSetServerDef(TFE_Context* ctx,
int keep_alive_secs,
const void* proto,
size_t proto_len,
TF_Status* status) {
#if defined(IS_MOBILE_PLATFORM)
status->status = tensorflow::errors::Unimplemented(
"TFE_ContextSetServerDef not supported on mobile");
#else // !defined(IS_MOBILE_PLATFORM)
tensorflow::ServerDef server_def;
if (!server_def.ParseFromArray(proto, proto_len)) {
status->status = tensorflow::errors::InvalidArgument(
"Invalid tensorflow.ServerDef protocol buffer");
return;
}
status->status =
tensorflow::unwrap(ctx)->GetDistributedManager()->SetOrUpdateServerDef(
server_def, /*reset_context=*/true, keep_alive_secs);
#endif // !IS_MOBILE_PLATFORM
}
EagerContextDistributedManager 的代码位于 tensorflow/core/common_runtime/eager/context_distributed_manager.cc。 其调用到了 UpdateContextWithServerDef。
Status EagerContextDistributedManager::SetOrUpdateServerDef(
const ServerDef& server_def, bool reset_context, int keep_alive_secs) {
if (server_def.has_cluster_device_filters()) {
if (reset_context) {
const auto& cdf = server_def.cluster_device_filters();
for (const auto& jdf : cdf.jobs()) {
const string remote_prefix = "/job:" + jdf.name() + "/task:";
for (const auto& tdf : jdf.tasks()) {
const int32_t task_index = tdf.first;
std::vector<string> device_filters(tdf.second.device_filters_size());
for (int i = 0; i < tdf.second.device_filters_size(); i++) {
device_filters[i] = tdf.second.device_filters(i);
}
const string remote_worker =
strings::StrCat(remote_prefix, task_index);
TF_RETURN_IF_ERROR(
context_->SetRemoteDeviceFilters(remote_worker, device_filters));
}
}
}
}
// 调用到了 UpdateContextWithServerDef
return UpdateContextWithServerDef(context_, server_def, reset_context,
keep_alive_secs);
}
UpdateContextWithServerDef 这里有几个关键步骤:
- 生成了 DistributedFunctionLibraryRuntime。
- 生成了 CreateContextRequest,调用 CreateRemoteContexts 来发送请求。
这里我们可以看到一系列看起来熟悉的名字,比如 grpc_server,curr_remote_workers,master_env,worker_session ..... 都是我们前面遇到的运行时概念。如此看来,虽然Session API不存在了,但是内部依然使用了这些概念,只是经由Context来重新组织封装。
tensorflow::DistributedFunctionLibraryRuntime* cluster_flr =
tensorflow::eager::CreateClusterFLR(context_id, context,
worker_session.get());
auto remote_mgr = std::make_unique<tensorflow::eager::RemoteMgr>(
/*is_master=*/true, context);
LOG_AND_RETURN_IF_ERROR(context->InitializeRemoteMaster(
std::move(new_server), grpc_server->worker_env(), worker_session,
std::move(remote_eager_workers), std::move(new_remote_device_mgr),
remote_workers, context_id, r, device_mgr, keep_alive_secs, cluster_flr,
std::move(remote_mgr)));
UpdateContextWithServerDef 的具体代码如下:
tensorflow::Status UpdateContextWithServerDef(
EagerContext* context, const tensorflow::ServerDef& server_def,
bool reset_context, int keep_alive_secs) {
// We don't use the TF_RETURN_IF_ERROR macro directly since that destroys the
// server object (which currently CHECK-fails) and we miss the error, instead,
// we log the error, and then return to allow the user to see the error
// message.
#define LOG_AND_RETURN_IF_ERROR(...) \
do { \
const ::tensorflow::Status _status = (__VA_ARGS__); \
if (TF_PREDICT_FALSE(!_status.ok())) { \
LOG(ERROR) << _status.error_message(); \
return _status; \
} \
} while (0);
string worker_name =
tensorflow::strings::StrCat("/job:", server_def.job_name(),
"/replica:0/task:", server_def.task_index());
// List of current remote workers before updating server_def. Unused if
// resetting the server_def.
std::vector<string> curr_remote_workers;
// List of updated remote workers.
std::vector<string> remote_workers;
// New server created for new server_def. Unused if updating server_def.
std::unique_ptr<tensorflow::ServerInterface> new_server;
tensorflow::GrpcServer* grpc_server;
if (reset_context) {
tensorflow::DeviceMgr* device_mgr =
AreLocalDevicesCompatible(context, server_def)
? context->local_device_mgr()
: nullptr;
LOG_AND_RETURN_IF_ERROR(tensorflow::NewServerWithOptions(
server_def, {device_mgr}, &new_server));
grpc_server = dynamic_cast<tensorflow::GrpcServer*>(new_server.get());
LOG_AND_RETURN_IF_ERROR(
ListRemoteWorkers(new_server.get(), worker_name, &remote_workers));
} else {
LOG_AND_RETURN_IF_ERROR(ListRemoteWorkers(context->GetServer(), worker_name,
&curr_remote_workers));
// No need to check the cast here, since ListRemoteWorkers already checks
// if the server is a GRPC server or not.
grpc_server = dynamic_cast<tensorflow::GrpcServer*>(context->GetServer());
LOG_AND_RETURN_IF_ERROR(grpc_server->UpdateServerDef(server_def));
LOG_AND_RETURN_IF_ERROR(
ListRemoteWorkers(grpc_server, worker_name, &remote_workers));
}
tensorflow::uint64 context_id = context->GetContextId();
tensorflow::uint64 context_view_id = context->GetContextViewId();
if (reset_context) {
context_id = tensorflow::EagerContext::NewContextId();
context_view_id = 0;
// Make master eager context accessible by local eager service, which might
// receive send tensor requests from remote workers.
LOG_AND_RETURN_IF_ERROR(
grpc_server->AddMasterEagerContextToEagerService(context_id, context));
}
std::unique_ptr<tensorflow::eager::EagerClientCache> remote_eager_workers;
LOG_AND_RETURN_IF_ERROR(
grpc_server->master_env()->worker_cache->GetEagerClientCache(
&remote_eager_workers));
// For cluster update, use a status group to aggregate statuses from
// * adding and removing remote devices
// * creating remote contexts on newly added workers
// * updating remote contexts on existing workers
// * updating the master context
// Note that we should not return immediately on errors in the middle of these
// updates to prevent cluster from having inconsistent context views.
//
// Unused if reset_context is True.
tensorflow::StatusGroup sg;
// When updating an existing context, populate the following lists with:
// * added_workers: set(remote_workers) - set(curr_remote_workers)
// * removed_workers: set(curr_remote_workers) - set(remote_workers)
// * existing_workers: set(curr_remote_workers) intersect set(remote_workers)
// * replaced_workers: workers with the same task names and potentially the
// same hostname:port s, but replaced by different processes
std::vector<string> added_workers;
std::vector<string> removed_workers;
std::vector<string> existing_workers;
std::vector<string> replaced_workers;
// New remote device manager created for new server_def. Unused if updating
// server_def.
std::unique_ptr<tensorflow::DynamicDeviceMgr> new_remote_device_mgr;
tensorflow::DynamicDeviceMgr* remote_device_mgr = nullptr;
if (reset_context) {
LOG_AND_RETURN_IF_ERROR(GetAllRemoteDevices(
remote_workers, grpc_server->master_env()->worker_cache,
&new_remote_device_mgr));
remote_device_mgr = new_remote_device_mgr.get();
} else {
context->ClearCachesAndDefaultExecutor();
remote_device_mgr = context->GetOwnedRemoteDeviceMgr();
std::sort(curr_remote_workers.begin(), curr_remote_workers.end());
std::sort(remote_workers.begin(), remote_workers.end());
DifferentiateWorkerLists(&curr_remote_workers, &remote_workers,
&added_workers, &removed_workers,
&existing_workers);
sg.Update(GetReplacedFromExistingWorkers(
&existing_workers, context_id, context->GetContextViewId(), server_def,
remote_eager_workers.get(), &replaced_workers));
if (!replaced_workers.empty()) {
// Treat replaced workers as removed then added back, so that we recreate
// remote devices and contexts, and re-register functions on those workers
removed_workers.insert(removed_workers.end(), replaced_workers.begin(),
replaced_workers.end());
added_workers.insert(added_workers.end(), replaced_workers.begin(),
replaced_workers.end());
for (const string& w : replaced_workers) {
existing_workers.erase(
std::remove(existing_workers.begin(), existing_workers.end(), w),
existing_workers.end());
}
}
sg.Update(RemoveRemoteDevicesFromMgr(removed_workers, remote_device_mgr));
sg.Update(AddRemoteDevicesToMgr(added_workers,
grpc_server->master_env()->worker_cache,
remote_device_mgr));
}
std::vector<tensorflow::DeviceAttributes> cluster_device_attributes;
remote_device_mgr->ListDeviceAttributes(&cluster_device_attributes);
std::vector<tensorflow::DeviceAttributes> local_device_attributes;
grpc_server->worker_env()->device_mgr->ListDeviceAttributes(
&local_device_attributes);
// This request make sure that we can create Rendezvous properly between
// Local and Remote context.
tensorflow::eager::CreateContextRequest base_request; // 生成了 CreateContextRequest
for (const auto& da : cluster_device_attributes) {
*base_request.add_cluster_device_attributes() = da;
}
for (const auto& da : local_device_attributes) {
*base_request.add_cluster_device_attributes() = da;
}
// Initialize remote eager workers.
if (reset_context) {
const tensorflow::Status s = CreateRemoteContexts(
context, remote_workers, context_id, context_view_id, keep_alive_secs,
server_def, remote_eager_workers.get(), context->Executor().Async(),
base_request);
} else {
if (sg.ok()) {
// Create remote contexts on the newly added workers only if the master
// has collected all device information from them (i.e., the
// GetAllRemoteDevices call returns succussfully). Note that in rare cases
// GetAllRemoteDevices can still fail even with RPCs configured to wait
// until the remote workers to become alive. If the master creates remote
// contexts on the workers whose devices are still not collected, those
// workers will be treated as existing workers subsequently, so the master
// will never get devices from them even with retrying UpdateServerDef.
sg.Update(CreateRemoteContexts(
context, added_workers, context_id, context_view_id + 1,
keep_alive_secs, server_def, remote_eager_workers.get(),
context->Executor().Async(), base_request));
}
if (!existing_workers.empty()) {
// The master's context_view_id will be incremented by one in the
// UpdateRemoteMaster call later. We want existing workers to also have
// the updated context_view_id, so we must set their context_view_id to
// the master's current context_view_id + 1.
sg.Update(UpdateRemoteContexts(context, existing_workers, added_workers,
removed_workers, context_id,
context_view_id + 1, server_def,
remote_eager_workers.get(), base_request));
}
}
auto session_name = tensorflow::strings::StrCat("eager_", context_id);
if (reset_context) {
tensorflow::RemoteRendezvous* r =
grpc_server->worker_env()->rendezvous_mgr->Find(context_id);
auto* device_mgr = grpc_server->worker_env()->device_mgr;
std::shared_ptr<tensorflow::WorkerSession> worker_session;
LOG_AND_RETURN_IF_ERROR(
grpc_server->worker_env()->session_mgr->CreateSession(
session_name, server_def, base_request.cluster_device_attributes(),
true));
LOG_AND_RETURN_IF_ERROR(
grpc_server->worker_env()->session_mgr->WorkerSessionForSession(
session_name, &worker_session));
// Initialize remote tensor communication based on worker session.
LOG_AND_RETURN_IF_ERROR(r->Initialize(worker_session.get()));
tensorflow::DistributedFunctionLibraryRuntime* cluster_flr =
tensorflow::eager::CreateClusterFLR(context_id, context,
worker_session.get());
auto remote_mgr = std::make_unique<tensorflow::eager::RemoteMgr>(
/*is_master=*/true, context);
LOG_AND_RETURN_IF_ERROR(context->InitializeRemoteMaster(
std::move(new_server), grpc_server->worker_env(), worker_session,
std::move(remote_eager_workers), std::move(new_remote_device_mgr),
remote_workers, context_id, r, device_mgr, keep_alive_secs, cluster_flr,
std::move(remote_mgr)));
// NOTE: We start the server after all other initialization, because the
// GrpcServer cannot be destroyed after it is started.
LOG_AND_RETURN_IF_ERROR(grpc_server->Start());
} else {
sg.Update(grpc_server->worker_env()->session_mgr->UpdateSession(
session_name, server_def, base_request.cluster_device_attributes(),
/*isolate_session_state=*/true));
sg.Update(context->UpdateRemoteMaster(context_id,
std::move(remote_eager_workers),
added_workers, removed_workers));
LOG_AND_RETURN_IF_ERROR(sg.as_summary_status());
}
#undef LOG_AND_RETURN_IF_ERROR
return tensorflow::Status::OK();
}
CreateRemoteContexts 方法会建立远端上下文,既然与远端有关系,就说明会用到gRPC机制。
tensorflow::Status CreateRemoteContexts(
EagerContext* context, const std::vector<string>& remote_workers,
tensorflow::uint64 context_id, tensorflow::uint64 context_view_id,
int keep_alive_secs, const tensorflow::ServerDef& server_def,
tensorflow::eager::EagerClientCache* remote_eager_workers, bool async,
const tensorflow::eager::CreateContextRequest& base_request) {
int num_remote_workers = remote_workers.size();
tensorflow::BlockingCounter counter(num_remote_workers);
std::vector<tensorflow::Status> statuses(num_remote_workers);
for (int i = 0; i < num_remote_workers; i++) {
const string& remote_worker = remote_workers[i];
tensorflow::DeviceNameUtils::ParsedName parsed_name;
if (!tensorflow::DeviceNameUtils::ParseFullName(remote_worker,
&parsed_name)) {
counter.DecrementCount();
continue;
}
tensorflow::core::RefCountPtr<tensorflow::eager::EagerClient> eager_client;
statuses[i] = remote_eager_workers->GetClient(remote_worker, &eager_client);
if (!statuses[i].ok()) {
counter.DecrementCount();
continue;
}
tensorflow::eager::CreateContextRequest request;
tensorflow::eager::CreateContextResponse* response =
new tensorflow::eager::CreateContextResponse();
request.set_context_id(context_id);
request.set_context_view_id(context_view_id);
*request.mutable_server_def() = server_def;
request.mutable_server_def()->set_job_name(parsed_name.job);
request.mutable_server_def()->set_task_index(parsed_name.task);
request.mutable_server_def()->mutable_default_session_config()->MergeFrom(
server_def.default_session_config());
std::vector<bool> filtered_device_mask;
context->FilterDevicesForRemoteWorkers(
remote_worker, base_request.cluster_device_attributes(),
&filtered_device_mask);
DCHECK_EQ(filtered_device_mask.size(),
base_request.cluster_device_attributes_size());
for (int i = 0; i < filtered_device_mask.size(); i++) {
if (filtered_device_mask[i]) {
const auto& da = base_request.cluster_device_attributes(i);
*request.add_cluster_device_attributes() = da;
}
}
request.set_async(async);
request.set_keep_alive_secs(keep_alive_secs);
request.set_lazy_copy_remote_function_inputs(true);
eager_client->CreateContextAsync(
&request, response,
[i, &statuses, &counter, response](const tensorflow::Status& s) {
statuses[i] = s;
delete response;
counter.DecrementCount();
});
}
counter.Wait();
tensorflow::StatusGroup sg;
for (int i = 0; i < num_remote_workers; i++) {
if (TF_PREDICT_FALSE(!statuses[i].ok())) {
sg.Update(statuses[i]);
}
}
return sg.as_summary_status();
}
CreateContextAsync 方法会发送 CreateContextRequest 请求。
3.6.1 EagerClientEagerClient 是 gRPC 的客户端接口。
// This is a base class that can be implemented by a variety of
// transports (e.g. gRPC which for each of the client methods makes an RPC).
class EagerClient : public core::RefCounted {
public:
~EagerClient() override {}
#define CLIENT_METHOD(method) \
virtual void method##Async(const method##Request* request, \
method##Response* response, \
StatusCallback done) = 0;
CLIENT_METHOD(CreateContext);
CLIENT_METHOD(UpdateContext);
CLIENT_METHOD(WaitQueueDone);
CLIENT_METHOD(KeepAlive);
CLIENT_METHOD(CloseContext);
#undef CLIENT_METHOD
#define CLIENT_CANCELABLE_METHOD(method) \
virtual void method##Async( \
CallOptions* call_opts, const method##Request* request, \
method##Response* response, StatusCallback done) = 0;
CLIENT_CANCELABLE_METHOD(Enqueue);
CLIENT_CANCELABLE_METHOD(RunComponentFunction);
#undef CLIENT_CANCELABLE_METHOD
// Feeds request into the request stream of EagerService::StreamingEnqueue.
// response will be filled with the response for this request . The
// 1-to-1 correspondence between requests and responses is a property
// of the current service implementation. When the response is received,
// done is invoked with the current status of the StreamingEnqueue call.
// The status can contain an error because of an earlier request in the
// current streaming call.
// The client initiates a streaming call the first time StreamingEnqueueAsync
// is invoked and keeps it open until some error condition.
// Similarly to the methods above, the request can be deleted as soon as
// StreamingEnqueueAsync returns.
virtual void StreamingEnqueueAsync(CallOptions* call_opts,
const EnqueueRequest* request,
EnqueueResponse* response,
StatusCallback done) = 0;
virtual bool allow_multiple_pending_requests() const = 0;
};
GrpcEagerClient 是 gRPC 的客户端实现。
class GrpcEagerClient : public EagerClient {
public:
GrpcEagerClient(const tensorflow::SharedGrpcChannelPtr& channel,
GrpcEagerClientThread* thread, const string& target)
: stub_(channel), thread_(thread), target_(target) {
// Hold a reference to make sure the corresponding EagerClientThread
// outlives the client.
thread_->Ref();
cq_ = thread->completion_queue();
}
~GrpcEagerClient() override { thread_->Unref(); }
bool allow_multiple_pending_requests() const override {
return EnableStreaming();
}
#define CLIENT_METHOD(method) \
void method##Async(const method##Request* request, \
method##Response* response, StatusCallback done) \
override { \
StatusCallback done_wrapped = callback_wrapper(std::move(done)); \
new RPCState<protobuf::Message>( \
&stub_, cq_, "/tensorflow.eager.EagerService/" #method, *request, \
response, std::move(done_wrapped), /*call_opts=*/nullptr, \
/*threadpool=*/nullptr, /*max_retries=*/0, /*fail_fast=*/true, \
&target_); \
}
CLIENT_METHOD(CreateContext);
CLIENT_METHOD(UpdateContext);
CLIENT_METHOD(WaitQueueDone);
CLIENT_METHOD(KeepAlive);
#undef CLIENT_METHOD
#define CLIENT_CANCELABLE_METHOD(method) \
void method##Async(CallOptions* call_opts, const method##Request* request, \
method##Response* response, StatusCallback done) \
override { \
StatusCallback done_wrapped = callback_wrapper(std::move(done)); \
new RPCState<protobuf::Message>( \
&stub_, cq_, "/tensorflow.eager.EagerService/" #method, *request, \
response, std::move(done_wrapped), call_opts, /*threadpool=*/nullptr, \
/*max_retries=*/0, /*fail_fast=*/true, &target_); \
}
CLIENT_CANCELABLE_METHOD(Enqueue);
CLIENT_CANCELABLE_METHOD(RunComponentFunction);
#undef CLIENT_CANCELABLE_METHOD
void CloseContextAsync(const CloseContextRequest* request,
CloseContextResponse* response,
StatusCallback done) override {
StatusCallback done_wrapped = callback_wrapper(std::move(done));
new RPCState<protobuf::Message>(
&stub_, cq_, "/tensorflow.eager.EagerService/CloseContext", *request,
response, std::move(done_wrapped), /*call_opts=*/nullptr,
/*threadpool=*/nullptr, /*max_retries=*/0, /*fail_fast=*/true,
&target_);
mutex_lock l(mu_);
const auto& it = enqueue_dispatchers_.find(request->context_id());
if (it != enqueue_dispatchers_.end()) {
it->second.CancelCall();
enqueue_dispatchers_.erase(it);
} else if (EnableStreaming()) {
LOG(ERROR) << "Remote EagerContext with id " << request->context_id()
<< " does not seem to exist.";
}
}
void StreamingEnqueueAsync(CallOptions* call_opts,
const EnqueueRequest* request,
EnqueueResponse* response,
StatusCallback done) override {
StatusCallback done_wrapped = callback_wrapper(std::move(done));
if (EnableStreaming()) {
mutex_lock l(mu_);
auto it = enqueue_dispatchers_.find(request->context_id());
if (it == enqueue_dispatchers_.end()) {
auto it_and_bool = enqueue_dispatchers_.emplace(
std::piecewise_construct,
std::forward_as_tuple(request->context_id()),
std::forward_as_tuple(
&stub_, cq_,
"/tensorflow.eager.EagerService/StreamingEnqueue"));
it = it_and_bool.first;
}
// TODO(haoyuzhang): Consider supporting cancellation for streaming RPC?
it->second.SendNextRequest(*request, response, std::move(done_wrapped));
} else {
Notification n;
Status status;
EnqueueAsync(call_opts, request, response,
[&n, &status](const Status& s) {
status.Update(s);
n.Notify();
});
n.WaitForNotification();
done_wrapped(status);
}
}
private:
::grpc::GenericStub stub_;
const GrpcEagerClientThread* thread_;
const string target_;
::grpc::CompletionQueue* cq_;
mutable mutex mu_;
std::unordered_map<uint64, StreamingRPCDispatcher<EnqueueResponse>>
enqueue_dispatchers_ TF_GUARDED_BY(mu_);
StatusCallback callback_wrapper(StatusCallback done) {
Ref();
return [this, done = std::move(done)](const Status& status) {
done(status);
this->Unref();
};
}
};
于是我们得到了目前具体逻辑如下:
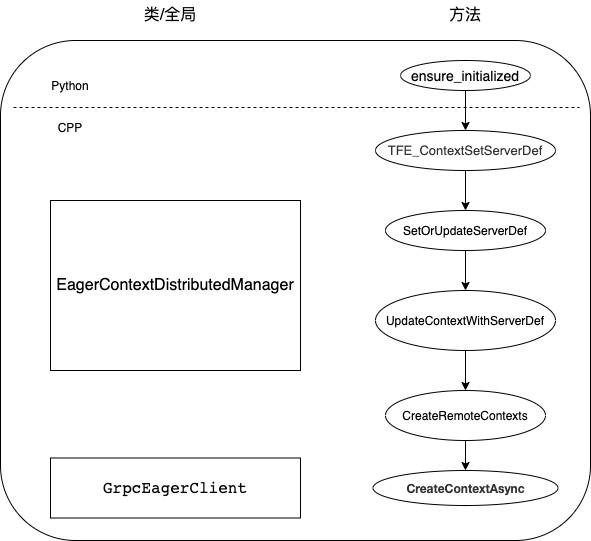
图 上下文相关逻辑
0x4. 通信协议此时我们发现了一个之前在runtime分析时候看到但是并没有分析过的 tensorflow/core/protobuf/eager_service.proto,我们就入手看看。
4.1 建立远端上下文我们首先看看如何建立远端上下文,具体消息定义如下:
message CreateContextRequest {
// Identifies the full cluster, and this particular worker's position within.
ServerDef server_def = 1;
// Whether the ops on the worker should be executed synchronously or
// asynchronously. By default, ops are executed synchronously.
bool async = 2;
// Number of seconds to keep the context alive. If more than keep_alive_secs
// has passed since a particular context has been communicated with, it will
// be garbage collected.
int64 keep_alive_secs = 3;
// This is the version for all the ops that will be enqueued by the client.
VersionDef version_def = 4;
// Device attributes in the cluster
repeated DeviceAttributes cluster_device_attributes = 6;
// The ID of the created context. This is usually a randomly generated number,
// that will be used to identify the context in future requests to the
// service. Contexts are not persisted through server restarts.
// This ID will be used for all future communications as well. It is essential
// that both ends use this ID for selecting a rendezvous to get everything to
// match.
fixed64 context_id = 7;
// The view ID of the context.
fixed64 context_view_id = 8;
// For a multi device function, if false, eagerly copy all remote inputs to
// the default function device; if true, lazily copy remote inputs to their
// target devices after function instantiation to avoid redundant copies.
bool lazy_copy_remote_function_inputs = 9;
reserved 5;
}
message CreateContextResponse {
// List of devices that are locally accessible to the worker.
repeated DeviceAttributes device_attributes = 2;
reserved 1;
}
其次看看如何运行方法。
message RunComponentFunctionRequest {
fixed64 context_id = 1;
Operation operation = 2;
// The output indices of its parent function.
repeated int32 output_num = 3;
}
message RunComponentFunctionResponse {
repeated TensorShapeProto shape = 1;
repeated TensorProto tensor = 2;
}
有了协议为基础,我们接下来看看对应的服务。
0x5. Eager ServiceEager 服务定义了一个 TensorFlow 服务,其代表一个远程 Eager 执行器(Eager executor),会在一组本地设备上(eagerly)执行操作。该服务将跟踪它所访问的各种客户端和设备,并允许客户端在它能够访问的任何设备上排队执行操作,并安排从/到任何对等体(peers)的数据传输。
一个客户端可以生成多个上下文,以便能够独立执行操作,但不能在两个上下文之间共享数据。注意:即使客户端生成的上下文应该是独立的,但低级别的tensorflow执行引擎不是,所以它们可能会共享一些数据(例如,设备的ResourceMgr)。
////////////////////////////////////////////////////////////////////////////////
//
// Eager Service defines a TensorFlow service that executes operations eagerly
// on a set of local devices, on behalf of a remote Eager executor.
//
// The service impl will keep track of the various clients and devices it has
// access to and allows the client to enqueue ops on any devices that it is able
// to access and schedule data transfers from/to any of the peers.
//
// A client can generate multiple contexts to be able to independently execute
// operations, but cannot share data between the two contexts.
//
// NOTE: Even though contexts generated by clients should be independent, the
// lower level tensorflow execution engine is not, so they might share some data
// (e.g. a Device's ResourceMgr).
//
////////////////////////////////////////////////////////////////////////////////
service EagerService {
// This initializes the worker, informing it about the other workers in the
// cluster and exchanging authentication tokens which will be used in all
// other RPCs to detect whether the worker has restarted.
rpc CreateContext(CreateContextRequest) returns (CreateContextResponse);
// This updates the eager context on an existing worker when updating the set
// of servers in a distributed eager cluster.
rpc UpdateContext(UpdateContextRequest) returns (UpdateContextResponse);
// This takes a list of Execute and DeleteTensorHandle operations and enqueues
// (in async mode) or executes (in sync mode) them on the remote server.
// All outputs of ops which were not explicitly deleted with
// DeleteTensorHandle entries will be assumed to be alive and are usable by
// future calls to Enqueue.
rpc Enqueue(EnqueueRequest) returns (EnqueueResponse);
// A streaming version of Enqueue.
// Current server implementation sends one response per received request.
// The benefit for using a streaming version is that subsequent requests
// can be sent without waiting for a response to the previous request. This
// synchronization is required in the regular Enqueue call because gRPC does
// not guarantee to preserve request order.
rpc StreamingEnqueue(stream EnqueueRequest) returns (stream EnqueueResponse);
// Takes a set of op IDs and waits until those ops are done. Returns any error
// in the stream so far.
rpc WaitQueueDone(WaitQueueDoneRequest) returns (WaitQueueDoneResponse);
// This takes an Eager operation and executes it in async mode on the remote
// server. Different from EnqueueRequest, ops/functions sent through this
// type of requests are allowed to execute in parallel and no ordering is
// preserved by RPC stream or executor.
// This request type should only be used for executing component functions.
// Ordering of component functions should be enforced by their corresponding
// main functions. The runtime ensures the following invarients for component
// functions (CFs) and their main functions (MFs):
// (1) MF1 -> MF2 ==> CF1 -> CF2 ("->" indicates order of execution);
// (2) MF1 || MF2 ==> CF1 || CF2 ("||" indicates possible parallel execution);
// (3) For CF1 and CF2 that come from the same MF, CF1 || CF2
// For executing ops/main functions, use Enqueue or StreamingEnqueue instead
// for correct ordering.
rpc RunComponentFunction(RunComponentFunctionRequest)
returns (RunComponentFunctionResponse);
// Contexts are always created with a deadline and no RPCs within a deadline
// will trigger a context garbage collection. KeepAlive calls can be used to
// delay this. It can also be used to validate the existence of a context ID
// on remote eager worker. If the context is on remote worker, return the same
// ID and the current context view ID. This is useful for checking if the
// remote worker (potentially with the same task name and hostname / port) is
// replaced with a new process.
rpc KeepAlive(KeepAliveRequest) returns (KeepAliveResponse);
// Closes the context. No calls to other methods using the existing context ID
// are valid after this.
rpc CloseContext(CloseContextRequest) returns (CloseContextResponse);
}
AsyncServiceInterface 是处理 RPC 的异步接口,后面的 GrpcEagerServiceImpl 就继承了 AsyncServiceInterface。
// Represents an abstract asynchronous service that handles incoming
// RPCs with a polling loop.
class AsyncServiceInterface {
public:
virtual ~AsyncServiceInterface() {}
// A blocking method that should be called to handle incoming RPCs.
// This method will block until the service shuts down.
virtual void HandleRPCsLoop() = 0;
// Starts shutting down this service.
//
// NOTE(mrry): To shut down this service completely, the caller must
// also shut down any servers that might share ownership of this
// service's resources (e.g. completion queues).
virtual void Shutdown() = 0;
};
GrpcEagerServiceImpl 属于 gRPC Service,运行在 Server 线程之中,这里重要的是成员变量 EagerServiceImpl,EagerServiceImpl 实现了具体业务逻辑。当收到消息时候,会使用 local_impl_.method(&call->request, &call->response)) 来调用具体逻辑。
EagerServiceImpl local_impl_;
GrpcEagerServiceImpl 具体定义如下:
// This class is a wrapper that handles communication for gRPC.
class GrpcEagerServiceImpl : public AsyncServiceInterface {
public:
template <class RequestMessage, class ResponseMessage>
using EagerCall = Call<GrpcEagerServiceImpl, grpc::EagerService::AsyncService,
RequestMessage, ResponseMessage>;
template <class RequestMessage, class ResponseMessage>
using StreamingCall =
ServerBidirectionalStreamingCall<GrpcEagerServiceImpl,
grpc::EagerService::AsyncService,
RequestMessage, ResponseMessage>;
GrpcEagerServiceImpl(const WorkerEnv* env,
::grpc::ServerBuilder* server_builder);
virtual ~GrpcEagerServiceImpl() {}
// Create a master context in eager service.
Status CreateMasterContext(const tensorflow::uint64 context_id,
EagerContext* context);
void HandleRPCsLoop() override;
void Shutdown() override;
private:
#define HANDLER(method) \
void method##Handler(EagerCall<method##Request, method##Response>* call) { \
env_->compute_pool->Schedule([this, call]() { \
call->SendResponse( \
ToGrpcStatus(local_impl_.method(&call->request, &call->response))); \
}); \
Call<GrpcEagerServiceImpl, grpc::EagerService::AsyncService, \
method##Request, method##Response>:: \
EnqueueRequest(&service_, cq_.get(), \
&grpc::EagerService::AsyncService::Request##method, \
&GrpcEagerServiceImpl::method##Handler, false); \
}
HANDLER(CreateContext);
HANDLER(UpdateContext);
HANDLER(WaitQueueDone);
HANDLER(KeepAlive);
HANDLER(CloseContext);
#undef HANDLER
void EnqueueHandler(EagerCall<EnqueueRequest, EnqueueResponse>* call) {
env_->compute_pool->Schedule([this, call]() {
auto call_opts = std::make_shared<CallOptions>();
call->SetCancelCallback([call_opts]() { call_opts->StartCancel(); });
call->SendResponse(ToGrpcStatus(local_impl_.Enqueue(
call_opts.get(), &call->request, &call->response)));
});
Call<GrpcEagerServiceImpl, grpc::EagerService::AsyncService, EnqueueRequest,
EnqueueResponse>::
EnqueueRequest(&service_, cq_.get(),
&grpc::EagerService::AsyncService::RequestEnqueue,
&GrpcEagerServiceImpl::EnqueueHandler,
/*supports_cancel=*/true);
}
void RunComponentFunctionHandler(
EagerCall<RunComponentFunctionRequest, RunComponentFunctionResponse>*
call) {
env_->compute_pool->Schedule([this, call]() {
auto call_opts = std::make_shared<CallOptions>();
call->SetCancelCallback([call_opts]() { call_opts->StartCancel(); });
local_impl_.RunComponentFunction(call_opts.get(), &call->request,
&call->response,
[call, call_opts](const Status& s) {
call->ClearCancelCallback();
call->SendResponse(ToGrpcStatus(s));
});
});
Call<GrpcEagerServiceImpl, grpc::EagerService::AsyncService,
RunComponentFunctionRequest, RunComponentFunctionResponse>::
EnqueueRequest(
&service_, cq_.get(),
&grpc::EagerService::AsyncService::RequestRunComponentFunction,
&GrpcEagerServiceImpl::RunComponentFunctionHandler,
/*supports_cancel=*/true);
}
// Called when a new request has been received as part of a StreamingEnqueue
// call.
// StreamingEnqueueHandler gets the request from the call and fills the
// response (also found in call ) by invoking the local EagerServiceImpl.
// The local EagerServiceImpl is invoked in a single-threaded thread pool. We
// do this to preserve request order. The local service can parallelize based
// on context_id in request if necessary. Remote contexts are created in async
// mode by default, so the local service impl just puts the request on eager
// executor queue.
void StreamingEnqueueHandler(
StreamingCall<EnqueueRequest, EnqueueResponse>* call) {
call->Ref();
enqueue_streaming_thread_.Schedule([this, call]() {
if (call->RefCountIsOne()) {
// This StreamingCall has already been shutdown. Don't need to anything.
call->Unref();
return;
}
// NOTE(fishx): Use the address of StreamingCall as the stream_id since we
// reuse the same StreamingCall for multiple requests in the same
// streaming connection.
Status status = local_impl_.Enqueue(
/*call_opts=*/nullptr, &call->request(), call->mutable_response(),
reinterpret_cast<uint64>(static_cast<void*>(call)));
if (status.ok()) {
call->SendResponse();
} else {
call->Finish(ToGrpcStatus(status));
}
call->Unref();
// We do not tell gRPC to accept a new StreamingEnqueue request because
// this method can be called multiple times for a given streaming call.
// The StreamingCall does this per call instead, after a call has been
// opened.
});
}
const WorkerEnv* const env_; // Not owned.
EagerServiceImpl local_impl_;
// A single-threaded thread pool to handle streaming enqueue rpc request.
thread::ThreadPool enqueue_streaming_thread_;
std::unique_ptr<::grpc::Alarm> shutdown_alarm_;
std::unique_ptr<::grpc::ServerCompletionQueue> cq_;
grpc::EagerService::AsyncService service_;
TF_DISALLOW_COPY_AND_ASSIGN(GrpcEagerServiceImpl);
};
GrpcServer 会在线程之中运行 GrpcEagerServiceImpl。这里省略了大多数代码,
Status GrpcServer::Init(const GrpcServerOptions& opts) {
eager_service_ = new eager::GrpcEagerServiceImpl(&worker_env_, &builder);
线程启动运行在 GrpcServer::Start() 之中:
Status GrpcServer::Start() {
mutex_lock l(mu_);
switch (state_) {
case NEW: {
eager_thread_.reset(
env_->StartThread(ThreadOptions(), "TF_eager_service",
[this] { eager_service_->HandleRPCsLoop(); }));
其响应 RPC 是在 HandleRPCsLoop 之中。
void GrpcEagerServiceImpl::HandleRPCsLoop() {
#define ENQUEUE_REQUEST(method) \
do { \
Call<GrpcEagerServiceImpl, grpc::EagerService::AsyncService, \
method##Request, method##Response>:: \
EnqueueRequest(&service_, cq_.get(), \
&grpc::EagerService::AsyncService::Request##method, \
&GrpcEagerServiceImpl::method##Handler, false); \
} while (0)
ENQUEUE_REQUEST(CreateContext);
EagerServiceImpl 是业务实现,我们只给出成员变量,后续会介绍相关方法。
// A TensorFlow Eager Worker runs ops and supports worker to worker
// Tensor transfer.
//
// See eager_service.proto for more details about each method.
// This class can be wrapped by specific classes that implement rpc transports
// over this (e.g. gRPC).
class EagerServiceImpl {
const WorkerEnv* const env_; // Not owned.
mutex contexts_mu_;
std::unordered_map<uint64, ServerContext*> contexts_
TF_GUARDED_BY(contexts_mu_);
std::unique_ptr<Thread> gc_thread_;
mutex gc_thread_shutdown_mu_;
condition_variable gc_thread_cv_;
bool shutting_down_ TF_GUARDED_BY(gc_thread_shutdown_mu_) = false;
TF_DISALLOW_COPY_AND_ASSIGN(EagerServiceImpl);
};
在接受到 CreateContextRequest 之后,Server 首先调用到 GrpcEagerServiceImpl 的 CreateContextHandler,然后调用到 EagerServiceImpl 的 CreateContext。看起来,context_id 类似于 session_id。Context 起到了之前我们分析过的 master 作用,所以下面代码之中,处处可见 worker_session。
Status EagerServiceImpl::CreateContext(const CreateContextRequest* request,
CreateContextResponse* response) {
{
mutex_lock l(contexts_mu_);
auto context_it = contexts_.find(request->context_id());
if (context_it != contexts_.end()) {
if (request->context_view_id() <
context_it->second->Context()->GetContextViewId()) {
return errors::InvalidArgument("EagerService:CreateContext failed. ",
"Context id: <", request->context_id(),
"> already exists.");
} else {
// For existing context with a stale context_view_id, close the old one
// and recreate with new view id. This is likely due to the worker
// disconnected and then reconnected after one or more cluster updates.
context_it->second->Unref();
contexts_.erase(context_it);
}
}
}
// 看起来,context_id 类似于 session_id
auto* r = env_->rendezvous_mgr->Find(request->context_id());
auto session_name =
tensorflow::strings::StrCat("eager_", request->context_id());
}
// 建立 worker_session
TF_RETURN_IF_ERROR(env_->session_mgr->CreateSession(
session_name, request->server_def(), request->cluster_device_attributes(),
true));
int64_t context_id = request->context_id();
std::function<void()> session_destroyer = [this, context_id, session_name]() {
env_->rendezvous_mgr->Cleanup(context_id);
auto s = env_->session_mgr->DeleteSession(session_name);
};
// 拿到 worker_session
std::shared_ptr<WorkerSession> worker_session;
TF_RETURN_IF_ERROR(env_->session_mgr->WorkerSessionForSession(
session_name, &worker_session));
// 拿到 DeviceMgr
tensorflow::DeviceMgr* device_mgr = worker_session->device_mgr();
// Initialize remote tensor communication based on worker session.
TF_RETURN_IF_ERROR(r->Initialize(worker_session.get()));
std::function<Rendezvous*(const int64_t)> rendezvous_creator =
[worker_session, this](const int64_t step_id) {
auto* r = env_->rendezvous_mgr->Find(step_id);
r->Initialize(worker_session.get()).IgnoreError();
return r;
};
// 建立上下文 EagerContext
SessionOptions opts;
opts.config = request->server_def().default_session_config();
tensorflow::EagerContext* ctx = new tensorflow::EagerContext(
opts, tensorflow::ContextDevicePlacementPolicy::DEVICE_PLACEMENT_SILENT,
request->async(), device_mgr, false, r, worker_session->cluster_flr(),
env_->collective_executor_mgr.get());
// Ownership will be transferred to the ServerContext, or else in an error
// case ctx will be deleted by this unref.
core::ScopedUnref unref_ctx(ctx);
// 列出远端 workers
std::vector<string> remote_workers;
worker_session->worker_cache()->ListWorkers(&remote_workers);
remote_workers.erase(std::remove(remote_workers.begin(), remote_workers.end(),
worker_session->worker_name()),
remote_workers.end());
// 列出远端 remote_eager_workers
std::unique_ptr<tensorflow::eager::EagerClientCache> remote_eager_workers;
TF_RETURN_IF_ERROR(worker_session->worker_cache()->GetEagerClientCache(
&remote_eager_workers));
// 建立 DistributedFunctionLibraryRuntime
DistributedFunctionLibraryRuntime* cluster_flr =
eager::CreateClusterFLR(request->context_id(), ctx, worker_session.get());
// 初始化 InitializeRemoteWorker
auto remote_mgr =
absl::make_unique<tensorflow::eager::RemoteMgr>(/*is_master=*/false, ctx);
Status s = ctx->InitializeRemoteWorker(
std::move(remote_eager_workers), worker_session->remote_device_mgr(),
remote_workers, request->context_id(), request->context_view_id(),
std::move(rendezvous_creator), cluster_flr, std::move(remote_mgr),
std::move(session_destroyer));
if (!s.ok()) {
return s;
}
#if !defined(IS_MOBILE_PLATFORM)
// 建立 EagerContextDistributedManager
const auto& config = request->server_def().default_session_config();
const bool enable_coordination =
!config.experimental().coordination_service().empty();
if (enable_coordination) {
auto dist_mgr = std::make_unique<EagerContextDistributedManager>(ctx);
ctx->SetDistributedManager(std::move(dist_mgr));
TF_RETURN_IF_ERROR(ctx->GetDistributedManager()->EnableCoordinationService(
config.experimental().coordination_service(), env_,
request->server_def(), worker_session->worker_cache()));
std::unique_ptr<CoordinationClientCache> client_cache;
TF_RETURN_IF_ERROR(
worker_session->worker_cache()->GetCoordinationClientCache(
&client_cache));
TF_RETURN_IF_ERROR(
ctx->GetDistributedManager()->GetCoordinationServiceAgent()->Initialize(
env_, request->server_def(), std::move(client_cache),
/*error_fn=*/[](Status s) {
LOG(ERROR) << "Coordination agent is set to error: " << s;
}));
}
#endif // !IS_MOBILE_PLATFORM
std::vector<DeviceAttributes> device_attributes;
device_mgr->ListDeviceAttributes(&device_attributes);
for (const auto& da : device_attributes) {
*response->add_device_attributes() = da;
}
{
mutex_lock l(contexts_mu_);
auto context_it = contexts_.find(request->context_id());
contexts_.emplace(request->context_id(),
new ServerContext(ctx, request->keep_alive_secs(), env_));
}
return Status::OK();
}
Worker 逻辑如下:

图 2 Worker 端建立上下文流程
整体逻辑如下:

图 3 建立上下文总体流程
至此,上下文环境我们分析完毕,远端分布式运行的基础也有了,我们接下来就要看看如何在远端运行训练代码。
0x6. FunctionLibraryRuntime前面代码之中,Client 使用如下语句来建立 FunctionLibraryRuntime。
tensorflow::DistributedFunctionLibraryRuntime* cluster_flr =
tensorflow::eager::CreateClusterFLR(context_id, context, worker_session.get());
Server 在 EagerServiceImpl::CreateContext 之中也使用如下语句来建立 FunctionLibraryRuntime。
DistributedFunctionLibraryRuntime* cluster_flr =
eager::CreateClusterFLR(request->context_id(), ctx, worker_session.get());
CreateClusterFLR 的定义在 tensorflow/core/distributed_runtime/eager/cluster_function_library_runtime.cc 之中。
DistributedFunctionLibraryRuntime* CreateClusterFLR(
const uint64 context_id, EagerContext* ctx, WorkerSession* worker_session) {
return new EagerClusterFunctionLibraryRuntime(
context_id, ctx, worker_session->remote_device_mgr());
}
于是我们引出了 FunctionLibraryRuntime 这个 TF 的核心概念。而 DistributedFunctionLibraryRuntime 就是其分布式实现。
6.1 接口 DistributedFunctionLibraryRuntimeDistributedFunctionLibraryRuntime 是基础 API 接口。
// Used to instantiate and run functions in a distributed system.
class DistributedFunctionLibraryRuntime {
public:
virtual ~DistributedFunctionLibraryRuntime() {}
// Instantiate a function on a remote target specified in options.target , by
// sending the name and definition of the function to the remote worker. The
// local handle is filled for the instantiated function data and can be used
// for subsequent run function calls on the remote target.
virtual void Instantiate(
const std::string& function_name,
const FunctionLibraryDefinition& lib_def, AttrSlice attrs,
const FunctionLibraryRuntime::InstantiateOptions& options,
FunctionLibraryRuntime::LocalHandle* handle,
FunctionLibraryRuntime::DoneCallback done) = 0;
// Run an instantiated remote function (specified by handle ) with a list of
// input Tensors in args and get its output Tensors in rets . The input
// tensor data will be sent with the function execution request, and must be
// available on the current caller side.
// opts.runner isn't used for execution.
virtual void Run(const FunctionLibraryRuntime::Options& opts,
FunctionLibraryRuntime::LocalHandle handle,
gtl::ArraySlice<Tensor> args, std::vector<Tensor>* rets,
FunctionLibraryRuntime::DoneCallback done) = 0;
// Run an instantiated remote function (specified by handle ) with a list of
// input Tensors or RemoteTensorHandles as args and get its output Tensors
// or TensorShapes in rets . When using RemoteTensorHandles as function
// inputs or TensorShapes as outputs, the corresponding tensor data will be
// resolved on the remote worker, so it is not required to be locally
// available on the caller side. Using RemoteTensorHandle inputs is not
// supported in TensorFlow v1 runtime.
virtual void Run(const FunctionLibraryRuntime::Options& opts,
FunctionLibraryRuntime::LocalHandle handle,
gtl::ArraySlice<FunctionArg> args,
std::vector<FunctionRet>* rets,
FunctionLibraryRuntime::DoneCallback done) = 0;
// Clean up a previously instantiated function on remote worker.
virtual void CleanUp(uint64 step_id,
FunctionLibraryRuntime::LocalHandle handle,
FunctionLibraryRuntime::DoneCallback done) = 0;
// DeviceMgr with *all* available devices (i.e., local and remote).
virtual DeviceMgr* remote_device_mgr() const = 0;
};
EagerClusterFunctionLibraryRuntime 是具体实现,用来在服务之间通过 RPC 来运行 function。
// EagerClusterFunctionLibraryRuntime contains methods to Instantiate and Run
// functions across processes by making RPCs through eager service.
class EagerClusterFunctionLibraryRuntime
: public DistributedFunctionLibraryRuntime {
public:
EagerClusterFunctionLibraryRuntime(const uint64 context_id, EagerContext* ctx,
DeviceMgr* remote_device_mgr)
: context_id_(context_id),
ctx_(ctx),
remote_device_mgr_(remote_device_mgr) {}
~EagerClusterFunctionLibraryRuntime() override{};
// Register a partition (i.e., component function) of a multi-device function
// on the remote target specified in options.target . This should be
// triggered as part of instantiating a multi-device function in
// ProcessFunctionLibraryRuntime.
void Instantiate(const string& function_name,
const FunctionLibraryDefinition& lib_def, AttrSlice attrs,
const FunctionLibraryRuntime::InstantiateOptions& options,
FunctionLibraryRuntime::LocalHandle* handle,
FunctionLibraryRuntime::DoneCallback done) override;
// Execute the component function specified by handle on its instantiated
// remote target. This should be triggered as part of driving a multi-device
// function execution in ProcessFunctionLibraryRuntime. Running the component
// function remotely is purely asynchronous, and multiple component functions
// with the same remote target are not executed in any particular ordering.
// The main function side must wait for all component functions to finish
// (i.e., the done callbacks triggered) before finishing its execution.
void Run(const FunctionLibraryRuntime::Options& opts,
FunctionLibraryRuntime::LocalHandle handle,
gtl::ArraySlice<Tensor> args, std::vector<Tensor>* rets,
FunctionLibraryRuntime::DoneCallback done) override;
// The component function inputs args and outputs rets may refer to remote
// tensors on a remote device, which will be lazily resolved remotely where
// the inputs/outputs are actually consumed.
void Run(const FunctionLibraryRuntime::Options& opts,
FunctionLibraryRuntime::LocalHandle handle,
gtl::ArraySlice<FunctionArg> args, std::vector<FunctionRet>* rets,
FunctionLibraryRuntime::DoneCallback done) override;
void CleanUp(uint64 step_id, FunctionLibraryRuntime::LocalHandle handle,
FunctionLibraryRuntime::DoneCallback done) override;
DeviceMgr* remote_device_mgr() const override { return remote_device_mgr_; }
private:
const uint64 context_id_;
EagerContext* ctx_;
DeviceMgr* remote_device_mgr_; // not owned.
struct FunctionData {
const string target;
const absl::optional<std::vector<int>> ret_indices;
core::RefCountPtr<EagerClient> eager_client;
std::unique_ptr<EagerOperation> op;
FunctionData(const string& target,
const absl::optional<std::vector<int>>& ret_indices,
EagerClient* eager_client, std::unique_ptr<EagerOperation> op)
: target(target),
ret_indices(ret_indices),
eager_client(core::RefCountPtr<EagerClient>(eager_client)),
op(std::move(op)) {
eager_client->Ref();
}
};
mutable mutex mu_;
std::vector<FunctionData> function_data_ TF_GUARDED_BY(mu_);
};
Instantiate 方法用来初始化。
void EagerClusterFunctionLibraryRuntime::Instantiate(
const string& function_name, const FunctionLibraryDefinition& lib_def,
AttrSlice attrs, const FunctionLibraryRuntime::InstantiateOptions& options,
FunctionLibraryRuntime::LocalHandle* handle,
FunctionLibraryRuntime::DoneCallback done) {
auto target = options.target;
auto released_op = std::make_unique<EagerOperation>(ctx_);
Status s =
released_op->Reset(function_name.c_str(), target.c_str(), true, nullptr);
core::RefCountPtr<eager::EagerClient> eager_client;
s = ctx_->GetClient(target, &eager_client);
const FunctionLibraryDefinition& func_lib_def =
options.lib_def ? *options.lib_def : lib_def;
auto request = std::make_shared<EnqueueRequest>();
auto response = std::make_shared<EnqueueResponse>();
request->set_context_id(context_id_);
RegisterFunctionOp* register_function =
request->add_queue()->mutable_register_function();
*register_function->mutable_function_def() =
*func_lib_def.Find(function_name);
register_function->set_is_component_function(true);
*register_function->mutable_library() =
func_lib_def.ReachableDefinitions(register_function->function_def())
.ToProto();
StripDefaultAttributesInRegisterFunctionOp(register_function);
const absl::optional<std::vector<int>>& ret_indices = options.ret_indices;
eager_client->EnqueueAsync(
/*call_opts=*/nullptr, request.get(), response.get(),
[this, request, response, handle, released_op = released_op.release(),
target, ret_indices, eager_client = eager_client.get(),
done](const Status& s) {
{
mutex_lock l(mu_);
*handle = function_data_.size();
function_data_.emplace_back(target, ret_indices, eager_client,
absl::WrapUnique(released_op));
}
done(s);
});
}
如果希望运行计算图,则会进入 EagerClusterFunctionLibraryRuntime 的 Run 方法,然后 RunComponentFunctionAsync 会调用 RPC 通知远端 worker。
void EagerClusterFunctionLibraryRuntime::Run(
const FunctionLibraryRuntime::Options& opts,
FunctionLibraryRuntime::LocalHandle handle,
gtl::ArraySlice<FunctionArg> args, std::vector<FunctionRet>* rets,
FunctionLibraryRuntime::DoneCallback done) {
FunctionData* function_data = nullptr;
{
mutex_lock l(mu_);
DCHECK_LE(handle, function_data_.size());
function_data = &function_data_[handle];
}
EagerClient* eager_client = function_data->eager_client.get();
EagerOperation* op = function_data->op.get();
auto request = std::make_shared<RunComponentFunctionRequest>();
auto response = std::make_shared<RunComponentFunctionResponse>();
request->set_context_id(context_id_);
eager::Operation* remote_op = request->mutable_operation();
if (function_data->ret_indices.has_value()) {
for (const int ret_index : function_data->ret_indices.value()) {
request->add_output_num(ret_index);
}
}
for (const auto& arg : args) {
if (arg.index() == 0) {
absl::get<Tensor>(arg).AsProtoTensorContent(
remote_op->add_op_inputs()->mutable_tensor());
} else {
remote_op->add_op_inputs()->mutable_remote_handle()->Swap(
absl::get<RemoteTensorHandle*>(arg));
}
}
// The remote component function should use the same op_id as its parent
// multi-device function's in order to get the global unique op_id generated
// by the master context.
if (opts.op_id.has_value()) {
remote_op->set_id(opts.op_id.value());
} else {
remote_op->set_id(kInvalidRemoteOpId);
}
remote_op->set_is_function(true);
remote_op->set_is_component_function(true);
remote_op->set_func_step_id(opts.step_id);
remote_op->set_name(op->Name());
op->Attrs().FillAttrValueMap(remote_op->mutable_attrs());
remote_op->set_device(function_data->target);
CancellationManager* cm = opts.cancellation_manager;
CancellationToken token = 0;
auto call_opts = std::make_shared<CallOptions>();
if (cm != nullptr) {
token = cm->get_cancellation_token();
const bool already_cancelled = !cm->RegisterCallback(
token,
[call_opts, request, response, done]() { call_opts->StartCancel(); });
if (already_cancelled) {
done(errors::Cancelled("EagerClusterFunctionLibraryRuntime::Run"));
return;
}
}
// Execute component function on remote worker using RunComponentFunction RPC.
// Different from executing remote functions with Enqueue, this method runs
// a function on remote worker without tying up a thread (i.e., pure
// asynchronously).
eager_client->RunComponentFunctionAsync(
call_opts.get(), request.get(), response.get(),
[request, response, rets, call_opts, cm, token,
done = std::move(done)](const Status& s) {
if (cm != nullptr) {
cm->TryDeregisterCallback(token);
}
if (!s.ok()) {
done(s);
return;
}
for (const auto& shape : response->shape()) {
rets->push_back(shape);
}
for (const auto& tensor_proto : response->tensor()) {
Tensor t;
if (t.FromProto(tensor_proto)) {
rets->push_back(std::move(t));
} else {
done(errors::Internal("Could not convert tensor proto: ",
tensor_proto.DebugString()));
return;
}
}
done(Status::OK());
});
}
然后发送 RunComponentFunctionRequest 给远端 Worker,远端 Worker 处理之后返回 RunComponentFunctionResponse。类逻辑如下,其中 ClusterFunctionLibraryRuntime 也是一个派生类,但是和我们分析关系不大。

图 4 DistributedFunctionLibraryRuntime 类逻辑
// ClusterFunctionLibraryRuntime contains methods to Instantiate and Run
// functions across processes by making RPCs through worker service.
class ClusterFunctionLibraryRuntime : public DistributedFunctionLibraryRuntime {
public:
ClusterFunctionLibraryRuntime(WorkerSession* worker_session,
bool create_worker_session_called,
DeviceMgr* remote_device_mgr)
: worker_session_(worker_session),
create_worker_session_called_(create_worker_session_called),
remote_device_mgr_(remote_device_mgr) {}
远端 Worker 首先调用到 GrpcEagerServiceImpl 的 RunComponentFunctionHandler,然后调用到 EagerServiceImpl 的 RunComponent。
6.3.1 GrpcEagerServiceImplRunComponentFunctionHandler 是一个宏,具体我们在分布式环境之中已经分析过。
#define ENQUEUE_REQUEST(method) \
do { \
Call<GrpcEagerServiceImpl, grpc::EagerService::AsyncService, \
method##Request, method##Response>:: \
EnqueueRequest(&service_, cq_.get(), \
&grpc::EagerService::AsyncService::Request##method, \
&GrpcEagerServiceImpl::method##Handler, false); \
} while (0)
ENQUEUE_REQUEST(RunComponentFunction);
EagerServiceImpl::RunComponentFunction 则处理具体业务,主要就是调用 EagerLocalExecuteAsync 完成具体执行。
void EagerServiceImpl::RunComponentFunction(
CallOptions* call_opts, const RunComponentFunctionRequest* request,
RunComponentFunctionResponse* response, StatusCallback done) {
ServerContext* context = nullptr;
Status s = GetServerContext(request->context_id(), &context);
core::ScopedUnref context_unref(context);
auto& operation = request->operation();
// This codepath should only be triggered for executing component function
if (!operation.is_function() || !operation.is_component_function()) {
done(errors::Internal(
"RunComponentFunction request can only be used to execute "
"component functions."));
return;
}
EagerContext* eager_context = context->Context();
EagerExecutor* eager_executor = &eager_context->Executor();
EagerOperation* op = new EagerOperation(eager_context);
int* num_retvals = new int(0);
s = GetEagerOperationAndNumRetvals(operation, eager_context, eager_executor,
op, num_retvals);
s = op->SetAttrBool("is_component_function", true);
auto* retvals = new absl::FixedArray<TensorHandle*>(*num_retvals);
std::vector<int32> output_nums;
for (const int32_t output_num : request->output_num()) {
output_nums.push_back(output_num);
}
auto cm = std::make_shared<CancellationManager>();
op->SetCancellationManager(cm.get());
call_opts->SetCancelCallback([cm] { cm->StartCancel(); });
context->Ref();
EagerLocalExecuteAsync(
op, retvals->data(), num_retvals,
[op, op_id = operation.id(), num_retvals, retvals, output_nums, cm,
call_opts, response, eager_context, context,
done = std::move(done)](const Status& status) {
call_opts->ClearCancelCallback();
auto wrapped_done = [&](const Status& status) {
context->Unref();
done(status);
delete op;
delete num_retvals;
delete retvals;
};
if (!status.ok()) {
wrapped_done(status);
return;
}
// The output device of a component function is the component device
// which is known on the default device of it's parent function.
wrapped_done(AddOpRetvalsToResponse(
eager_context, op_id, *num_retvals, output_nums, retvals->data(),
[response] { return response->add_tensor(); },
[response] { return response->add_shape(); }));
});
}
因此我们最终逻辑如下:

图 5 如何处理远端运行时
0x7. 总结我们总结一下本文所分析的成果:
-
本地多线程还是多进程计算?
MirroredStrategy 在本地会使用多线程进行训练:在 _call_for_each_replica 之中,会建立 _MirroredReplicaThread 来运行。每个设备会起动一个线程,并行执行fn,直至所有 fn 都完成。
每个线程的计算都会分配到远端工作者之上。
-
MirroredStrategy 和我们之前分析的 TF 运行时怎么联系起来?
Context 在某种程度上起到了 TF 1 Session 概念环境之中 Master 的作用,对计算进行分发。
在远端,Eager 服务定义了一个 TensorFlow 服务,它会在远端建立远端上下文,会把 Context 分发的计算在本地设备上执行操作。
-
如何分发计算?如何在远端运行训练代码?
EagerClusterFunctionLibraryRuntime 负责在服务之间通过 RPC 来运行 function。如果希望运行计算图,本地会进入 EagerClusterFunctionLibraryRuntime 的 Run 方法,然后 RunComponentFunctionAsync 会调用 RPC(发送 RunComponentFunctionRequest)通知远端 worker。
远端 Worker 首先调用到 GrpcEagerServiceImpl 的 RunComponentFunctionHandler,然后调用到 EagerServiceImpl 的 RunComponent。
EagerServiceImpl::RunComponentFunction 负责处理具体业务,主要就是调用 EagerLocalExecuteAsync 完成具体执行。
远端 Worker 处理之后返回 RunComponentFunctionResponse。
至此,MirroredStrategy 分析完毕。
0xFF 参考tensorflow源码解析之distributed_runtime
TensorFlow分布式训练
- TensorFlow内核剖析
- 源代码
Tensorflow分布式原理理解
TensorFlow架构与设计:概述
Tensorflow 跨设备通信
TensorFlow 篇 | TensorFlow 2.x 分布式训练概览