摘要论文地址:深度噪声抑制模型的性能优化
引用格式:Chee J, Braun S, Gopal V, et al. Performance optimizations on deep noise suppression models[J]. arXiv preprint arXiv:2110.04378, 2021.
我们研究了量级结构剪枝以加快深度噪声抑制(DNS)模型的推理时间。尽管深度学习方法在提高音频质量方面取得了显著的成功,但它们增加的复杂性阻碍了它们在实时应用中的部署。我们在基线上实现了7.25倍的推理加速,同时平滑了模型的性能退化。消融研究表明,我们提出的网络再参数化(即每层尺寸)是加速的主要驱动因素,而量级结构剪枝与直接训练较小尺寸的模型相比具有相当大的作用。我们报告推理速度,因为参数减少并不需要加速,并且我们使用精确的非侵入性客观语音质量度量来度量模型质量。
关键词:语音增强,降噪,实时,推理加速,结构化剪枝
1 引言在压缩深度学习方法方面已经做了很多工作,以便它们能够在许多音频增强应用的实时和硬件约束下有效地运行[1,2,3,4]。这种兴趣源于这样一个事实,即深度学习方法虽然通常提供卓越的音频增强,但与经典信号处理方法[1]相比,其计算复杂度更高。在实时应用程序中,计算复杂度成为主要约束。每个设备的可用内存不同,但每次计算的可用时间不变。因此,我们在推理速度方面测量和展示我们的压缩结果。计算内存或参数减少不是一个精确的代理-参见5.3节。
我们研究了结构化剪枝和微调的应用,以加速我们的基线CRUSE模型[1]。结构化剪枝的目的是寻找一个能很好地逼近原始网络的稠密子网络。这种类型的模型压缩立即转换为推理加速和降低存储成本,因为我们执行的是密集和更小的矩阵乘法。此外,我们为CRUSE体系结构类提出了一种新的可伸缩的每层参数配置,以指定经过修剪的网络大小。
1.1 贡献使用 CRUSE [1] 架构,我们展示了比基线模型最高 7.25 倍的加速,模型质量平稳下降。 消融研究表明,所提出的网络参数配置实际上是成功的可扩展性的原因。 我们的结构化剪枝方法并不比直接训练给定大小的模型更好。 结构化修剪的价值在于架构搜索:发现哪些网络参数化可以以最小的模型退化降低模型复杂性。
2 相关工作Tan 和 Wang [3, 4] 使用稀疏正则化、迭代修剪和基于聚类的量化来压缩 DNN 语音增强模型。 然而,他们使用 STOI 和 PESQ [5] 来评估压缩后的质量,这已被证明与主观质量的相关性较低 [6, 7](这个,STOI相关度较低,但是PESQ相关度还是可以的,并且几乎所有的语音增强论文都在使用PESQ,作者这里直接否定我很反对)。 此外,没有给出运行时基准来显示实际改进,使用的噪声抑制模型相对简单且不是最先进的(这样贬低别人的论文,也不会凸出你的论文有多优秀,不都是CNN和LSTM等一些神经元的组合吗?再说你的模型也没有跟人家的模型进行性能对比呀),训练和测试集也很简单。 因此,从这项研究中还不清楚,在一个更具挑战性的测试集(如[7])上,什么样的优化在一个一流的噪声抑制器上工作得很好。
Kim等人的[2]结合使用非结构化剪枝、量化和知识蒸馏来压缩关键词抽取模型。作者通过边缘计算来推动他们的工作,但没有提供任何复杂的测量来表明实际的改进。此外,没有对任何其他压缩方法进行比较。
2.1 深度噪声抑制Braun等人[1]开发了用于实时深度噪声抑制的CRUSE类模型。它基于U-Net体系结构[8],另一种DNS实时模型。与早期主要基于递归神经网络的网络架构不同,CRUSE属于卷积递归网络[8,12,13,14],后者的模型已达到性能饱和[9,10,11]。这些模型提高了性能,尽管计算成本限制了它们在消费设备上的实时部署。我们研究了CRUSE模型的两个版本,一个更复杂的模型称为CRUSE32,另一个不那么复杂的模型称为CRUSE16。
2.2 模型压缩剪枝的目的是去除部分神经网络,同时保持其准确性。它既可以删除稀疏矩阵(非结构化)[15]中的单个参数,也可以删除诸如通道或神经元(结构化)[16]等参数组。神经网络的剪枝策略有很多,但在ImageNet[17]上,简单的幅度剪枝已被证明比更复杂的方法更好。模型压缩的其他方法包括量化、矩阵分解和知识蒸馏[18]。Frankle和Carbin[15]提出了彩票假设(Lottery Ticket Hypothesis):密集随机初始化的神经网络包含稀疏的子网络(中奖彩票),这些子网络可以在相当epoch的内训练到与原始网络相当的准确性。Liu等人[16]的工作将重点放在结构化修剪上,并给出了一个不同的信息:微调修剪后的模型与直接以该大小训练模型相当,甚至更差。
3 实验方法我们采用了两种简单但重要的实验方法,可以更准确地评估现实场景中的性能。首先,我们在 ONNX 推理引擎 [19] 中提供运行时间结果。由于对背景噪声抑制有严格的实时性要求,因此推理时间至关重要。减少的参数计数不一定会使推理时间更快。例如,我们在ONNX运行时测试了稀疏剪枝模型(见5.3节),没有发现有意义的加速。测试结果在Intel Core i7-10610U CPU上进行。其次,使用INTERSPEECH 2021和ICASSP 2021 DNS挑战测试集[7,20]评估模型质量。我们使用一种新的非侵入性客观语音质量度量方法DNSMOS P.835[21](没有开源,只有微软公司和参加DNS挑战赛的人能用),采用ITU-T P.835[22]标准,该标准为语音(SIG)、背景(BAK)和总体(OVLR)质量提供单独的评分。DNSMOS P.835的语音皮尔逊相关系数为0.94,背景为0.98,总体与主观质量相比为0.98,这为快速修剪提供了足够的准确性。
4 通过修剪架构搜索进行性能优化我们的目标是提高CRUSE体系结构类的推理时间,同时保持最小的模型退化。我们研究的CRUSE体系结构由4对卷积编码器和反卷积解码器层组成,中央有一个并行的GRU层。该架构的完整细节可以在Braun等人的[1]中找到。因为DNS模型是在实时环境中操作的,所以我们将重点放在减少推理时间上。我们首先剖析CRUSE的推理时间,结果如表1所示。GRU操作主导了计算,所以我们将专注于压缩它们。

表1:分析CRUSE32以识别推理加速的主要目标
结构化剪枝需要调整每一层参数的数量。我们的DNS模型可以由一个长度为4的向量$[c_1, c_2, c_3, c_4]$来参数化。由于编码器-解码器层对之间的跳过连接,CRUSE对于GRU中心层是对称的。例如,$c_1$指定了第一卷积层的输出通道和第二卷积层的输入通道。$c_4$为最后一层卷积层的输出通道和GRU层的隐藏状态。表2指定了基准CRUSE32网络参数化,以及我们考虑的8个配置。

表2:CRUSE架构的结构化剪枝配置。模型内存是ONNX格式的。基准包括95%的置信区间。CRUSE{32,16}是Braun等人[1]的基线模型
我们开发了一个启发式的框架来调整CRUSE架构的大小。首先,通过剪枝配置参数降低GRU层的尺寸。这相当于修改网络参数化中的$c_4$。例如,对于P.625配置,修剪参数是0.625。因此,我们改变$c_4 \leftarrow (1 - 0.625)*256 = 96$。注意,我们还必须改变最后一个卷积层的输出通道。然后,我们加强所谓的“网络单调性”,$c_1 \leq c_2\leq c_3 \leq c_4$。这种单调性条件在神经网络结构设计中很常见,在神经网络中,信道数量通过网络增加[23,24]。回想一下,c3 = 128,因此$c_3 >c_4$。然后我们设置$c_3 \leftarrow c_4$来满足这个条件。我们提出的配置方案可以应用于其他U-Net[8]风格的体系结构,因为它只需要一个对称的编码器-解码器结构。
我们采用结构化幅度修剪来构建一个密集的子网络,其大小由我们的网络参数化指定。 考虑一个通用张量$W\in R^{d_1*...*d_p}$要构造一个降维$\hat{d}_i<d_i$的子张量$\hat{W}\in R^{d_1*...*d_{i-1}*\hat{d}_i*d_{i+1}*...*d_p}$,请选择维数$i$中的一组坐标,满足:
$$\widehat{\mathcal{J}}=\underset{\left.\mathcal{J} \subseteq\left\{1, \ldots, d_{i}\right\}\right|^{\left|d_{i}\right|}}{\operatorname{argmax}} \sum_{j \in \mathcal{J}}\left\|W_{i}^{j}\right\|$$
其中,$W_i^j$表示维度$i$在坐标$j$处索引的张量W。我们采用这种通用的结构化幅度裁剪方法来减少卷积层/反卷积的输入或输出通道数,以及GRU层的输入维数和隐藏维数。我们修剪了我们的基线 CRUSE32 模型。 微调对于在修剪后恢复模型精度至关重要。 我们使用与训练基线 CRUSE32 模型相同的优化超参数。
5 结果图1绘制了通过结构化幅度剪枝对表 2 中指定的配置实现的加速,对比得到的信号、背景和整体 DNSMOS P.835。 重要的是,结构化修剪在复杂性和模型质量之间实现了平滑的权衡。 这种权衡是相当平坦的。 我们可以降低复杂性而不会导致模型退化。 例如,与基线 CRUSE32 模型相比,内存减少 3.64 倍,推理速度提高 2.46 倍,只会导致整体 DNSMOS P.835 下降 0.01。 P.125 配置实现了比基线 CRUSE32 更高的 DNSMOS P.835,因为我们正在基线模型之上进行额外的再训练。 在极端情况下,7.25 倍的推理加速会导致 0.2 的整体 DNSMOS P.835 退化。 总的来说,我们已经证明 CRUSE 类模型在以前认为站不住脚的复杂程度下是可行的。
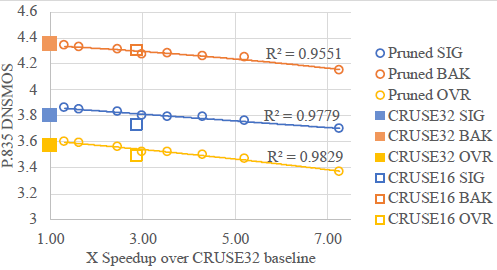
图1:通过结构化剪枝加速CRUSE类模型。DNSMOS P.835报告了2021年DNS挑战测试集[7,20]。具有$R^2$值的二次多项式趋势线
5.1 烧蚀研究我们在压缩 CRUSE 类模型时引入了两个新变量:网络重新参数化和结构化幅度修剪方法本身。 CRUSE16 模型遵循之前的网络参数化 [1],但参数数量是 CRUSE32 的一半。 在表 2 中,我们看到 CRUSE16 在内存和基准速度方面位于 P.500 和 P.5625 修剪配置之间。 然而,图 1 显示 CRUSE16 的信号较差,整体 DNSMOS P.835,BAK相同。 保持复杂性不变,我们在表 2 中的新网络参数化实现了卓越的音频质量。
表 3 显示了在给定配置中直接训练模型的结果,使用与修剪模型相同的训练 epoch 总数。 结果实际上无法区分,这表明结构化幅度修剪没有提供任何附加值。 结构化修剪的微调过程的额外调整并没有改善结果,见表 4。
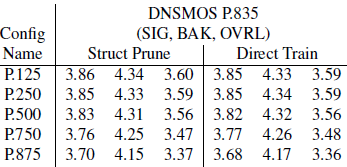
表3:修剪与直接训练一个配置
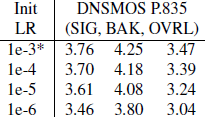
表 4:调整 LR 以进行结构化修剪微调。 (*)是选择的超参数,用于微调,直接训练,是原始的CRUSE32训练参数
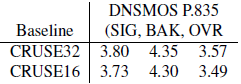
表5:DNSMOS P.835基线CRUSE32, CRUSE16模型
5.2 微调的价值表6中报告了DNSMOS P.835经过结构化幅度修剪后,再经过微调后的结果。我们看到,微调是恢复模型质量的关键。MOS分数增加了大约1分,差距很大。表7报告了经过非结构化(稀疏)剪枝和微调后的DNSMOS P.835。值得注意的是,我们发现非结构化剪枝并没有降低模型的质量。注意,Frac GRU 0.25非结构化设置不会修改任何卷积层,也不等同于P.250配置。随后,微调恢复的机会就少了。
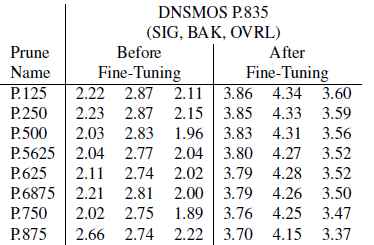
表 6:微调前后结构修剪后的 CRUSE32 模型的 DNSMOS P.835

表 7:微调前后非结构化(稀疏)剪枝 CRUSE32 模型的 DNSMOS P.835
5.3 稀疏性并不意味着推理加速尽管表7中的结果很有希望,但通过稀疏性减少参数计数并不容易转化为推理加速。表8给出了CRUSE32中GRU层稀疏幅度修剪的基准结果。GRU权重的一部分被设为零。时间不能用它们的置信区间来区分。这意味着ONNX运行时不提供从稀疏线性代数操作加速。为了从稀疏性实现加速,需要专门的稀疏推理支持。Neural Magic推理引擎[25]就是这样一个选择,但是在我们的实验中,我们发现对RNN层的支持仍处于开发阶段。
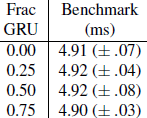
表 8:在 CRUSE32 中对 GRU 层进行非结构化(稀疏)幅度修剪的基准结果
6 结论与基线 CRUSE32 模型相比,我们实现了高达 7.25 倍的推理加速。 我们的实验表明,所提出的网络参数化(每层的大小)是我们加速结果的主要驱动因素,而不是结构化的幅度修剪。 这些结论支持Liu等人[16],因为结构化修剪的价值在于进行架构搜索。此外,我们选择的方法是测量推理速度,而不是使用参数计数作为代理,这揭示了从稀疏剪枝方法中实现实际收益的困难。我们提出的网络参数化只需要一个对称的编码器-解码器结构,因此可以应用于其他 U-Net 风格的架构。
7 参考[1] Sebastian Braun, Hannes Gamper, Chandan K.A. Reddy, and Ivan Tashev, Towards efficient models for real-time deep noise suppression, in ICASSP. IEEE, 2021.
[2] Jangho Kim, Simyung Chang, and Nojun Kwak, Pqk: Model compression via pruning, quantization, and knowledge distillation, INTERSPEECH, 2021.
[3] Ke Tan and DeLiang Wang, Compressing deep neural networks for efficient speech enhancement, in ICASSP. IEEE, 2021, pp. 8358 8362.
[4] Ke Tan and DeLiang Wang, Towards model compression for deep learning based speech enhancement, IEEE/ACM Transactions on Audio, Speech, and Language Processing, vol. 29, pp. 1785 1794, 2021.
[5] ITU-T recommendation P.862: Perceptual evaluation of speech quality (PESQ): An objective method for end-to-end speech quality assessment of narrow-band telephone networks and speech codecs, Feb 2001.
[6] Ross Cutler, Ando Saabas, Tanel Parnamaa, Markus Loide, Sten Sootla, Marju Purin, Hannes Gamper, Sebastian Braun, Karsten Sorensen, Robert Aichner, et al., INTERSPEECH 2021 acoustic echo cancellation challenge, in INTERSPEECH, 2021.
[7] Chandan KA Reddy, Harishchandra Dubey, Kazuhito Koishida, Arun Nair, Vishak Gopal, Ross Cutler, Sebastian Braun, Hannes Gamper, Robert Aichner, and Sriram Srinivasan, INTERSPEECH 2021 deep noise suppression challenge, in INTERSPEECH, 2021.
[8] D.Wang and K Tan, A convolutional recurrent neural network for real-time speech enhancement, in INTERSPEECH, 2018.
[9] F.Weninger, H. Erdogan, S.Watanabe, E. Vincent, J. Le Roux, J. R. Hershey, and B. Schuller, Speech enhancement with lstm recurrent neural networks and its applications to noise-robust asr, in Proc. Latent Variable Analysis and Signal Separation, 2015.
[10] D. S. Williamson and D. Wang, Time-frequency masking in the complex domain for speech dereverberation and denoising, in IEEE/ACM Trans. Audio, Speech, Lang. Process, 2017.
[11] R. Xia, S. Braun, C. Reddy, H. Dubey, R. Cutler, and I. Tashev, Weighted speech distortion losses for neural-network-based real-time speech enhancement, in ICASSP, 2020.
[12] M. Strake, B. Defraene, K. Fluyt, W. Tirry, and T. Fingschedit, Separate noise suppression and speech restoration: Lstmbased speech enhancement in two stages, in WASPAA, 2019.
[13] G. Wichern and A. Lukin, Low-latency approximation of bidirectional recurrent networks for speech denoising, in WASPAA, 2017.
[14] S Wisdom, J. R. Hershey, R. Wilsom, J. Thorpe, M. Chinen, B. Patton, and R. A. Saurous, Differentiable consistency constraints for improved deep speech enhancement, in ICASSP, 2019.
[15] Jonathan Frankle and Michael Carbin, The lottery ticket hypothesis: Finding sparse, trainable neural networks, International Conference on Learning Representations, 2019.
[16] Zhuang Liu, Mingjie Sun, Tinghui Zhou, Gao Huang, and Trevor Darrell, Rethinking the value of network pruning, International Conference on Learning Representations, 2019.
[17] Trevor Gale, Erich Elsen, and Sara Hooker, The state of sparsity in deep neural networks, arXiv preprint arXiv:1902.09574, 2019.
[18] Rahul Mishra, Prabhat Hari Gupta, and Tanima Dutta, A survey on deep neural network compression: challenges, overview, and solutions, arXiv preprint arXiv:2010.03954, 2021.
[19] ONNX Runtime developers, Onnx runtime, https://www. onnxruntime. ai, 2021.
[20] Chandan KA Reddy, Harishchandra Dubey, Vishak Gopal, Ross Cutler, Sebastian Braun, Hannes Gamper, Robert Aichner, and Sriram Srinivasan, ICASSP 2021 deep noise suppression challenge, ICASSP, 2021.
[21] Chandan Reddy, Vishak Gopal, and Ross Cutler, DNSMOS P.835: A non-intrusive perceptual objective speech quality metric to evaluate noise suppressors, arXiv preprint arXiv:2101.11665, 2021.
[22] Babak Naderi and Ross Cutler, Subjective evaluation of noise suppression algorithms in crowdsourcing, in INTERSPEECH, 2021.
[23] Karen Simonyan and Andrew Zisserman, Very deep convolutional networks for large-scale image recognition, in International Conference on Learning Representations, 2015.
[24] Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun, Deep residual learning for image recognition, in CVPR, 2016.
[25] Mark Kurtz, Justin Kopinsky, Rati Gelashvili, Alexander Matveev, John Carr, Michael Goin, William Leiserson, Sage Moore, Bill Nell, Nir Shavit, and Dan Alistarh, Inducing and exploiting activation sparsity for fast inference on deep neural networks, in ICML, Hal Daum e III and Aarti Singh, Eds. , Virtual, 13 18 Jul 2020, vol. 119 of Proceedings of Machine Learning Research, pp. 5533 5543, PMLR.