- [源码解析] TensorFlow 分布式环境(8) --- 通信机制
- 1. 机制
- 1.1 消息标识符
- 1.1.1 定义
- 1.1.2 创建
- 1.2 Rendezvous
- 1.2.1 接口类
- 1.2.2 基础实现 Rendezvous
- 1.2.3 跨进程 RemoteRendezvous
- 1.2.4 BaseRemoteRendezvous
- 1.2.5 RpcRemoteRendezvous
- 1.3 管理类
- 1.3.1 接口
- 1.3.2 BaseRendezvousMgr
- 1.1 消息标识符
- 2. 使用
- 2.1 Worker 接受
- 2.1.1 DoRunGraph
- 2.1.2 DoPartialRunGraph
- 2.2 GraphMgr 发送
- 2.1 Worker 接受
- 3. 发送
- 3.1 BaseRemoteRendezvous
- 3.2 LocalRendezvous
- 4. 接受
- 4.1 Client
- 4.1.1 RecvOutputsFromRendezvousAsync
- 4.1.2 BaseRemoteRendezvous
- 4.1.3 RpcRemoteRendezvous
- 4.1.4 RpcRecvTensorCall
- 4.1.5 GrpcRemoteWorker
- 4.2 Server
- 4.2.1 GrpcWorkerService
- 4.2.2 GrpcWorkerServiceThread
- 4.2.3 GrpcWorker
- 4.2.4 BaseRendezvousMgr
- 4.2.5 BaseRemoteRendezvous
- 4.2.6 LocalRendezvous
- 4.1 Client
- 0xFF 参考
- 1. 机制
当计算图在设备之间划分之后,跨设备的 PartitionGraph 之间可能存在着数据依赖关系,因此 TF 在它们之间插入 Send/Recv 节点,这样就完成数据交互。而在分布式模式之中,Send/Recv 通过 RpcRemoteRendezvous 完成数据交换,所以我们需要先看看 TF 之中的数据交换机制 Rendezvous。
迄今为止,在分布式机器学习之中,我们看到了太多的 Rendezvous,其大多出现在弹性和通信相关部分,虽然具体意义各有细微不同,但是基本意义都差不多,就是来自其法语单词的原意:会合,聚会,集会,约会等。TensorFlow的Rendezvous是消息传输的通信组件和交换机制。
本文依旧深度借鉴了两位大神:
[TensorFlow Internals] (https://github.com/horance-liu/tensorflow-internals),虽然其分析的不是最新代码,但是建议对 TF 内部实现机制有兴趣的朋友都去阅读一下,绝对大有收获。
https://home.cnblogs.com/u/deep-learning-stacks/ 西门宇少,不仅仅是 TensorFlow,其公共号还有更多其他领域,业界前沿。
本系列其他文章是:
[翻译] TensorFlow 分布式之论文篇 "TensorFlow : Large-Scale Machine Learning on Heterogeneous Distributed Systems"
[翻译] TensorFlow 分布式之论文篇 "Implementation of Control Flow in TensorFlow"
[源码解析] TensorFlow 分布式环境(1) --- 总体架构
[源码解析] TensorFlow 分布式环境(2)---Master 静态逻辑
[源码解析] TensorFlow 分布式环境(3)--- Worker 静态逻辑
[源码解析] TensorFlow 分布式环境(4) --- WorkerCache
[源码解析] TensorFlow 分布式环境(5) --- Session
[源码解析] TensorFlow 分布式环境(7) --- Worker 动态逻辑
1. 机制在分布式模式之中,对跨设备的边会进行分裂,在边的发送端和接收端会分别插入 Send 节点和 Recv 节点。
- 进程内的 Send 和 Recv 节点通过 IntraProcessRendezvous 实现数据交换。
- 进程间的 Send 和 Recv 节点通过 GrpcRemoteRendezvous 实现数据交换。
我们假设 Worker 0 有两个 GPU,当插入Send 节点和 Recv 节点,效果如下,其中 Worker 1 发送给 Worker 之间的代表进程间通过 GrpcRemoteRendezvous 实现数据交换,Worker 0 内部两个 GPU 之间的虚线箭头代表进程内部通过 IntraProcessRendezvous 实现数据交换,Worker 之间的实线箭头表示使用 RPC 进行数据交换。
当执行某次 step,如果两个 Worker 需要交互数据,则:
- 生产者 Sender 会先生成张量,放入本地 Table。
- 消费者 Receiver 向生产者发送 RecvTensorRequest 消息,消息之中携带二元组 (step_id, rendezvous_key)
- 生产者端 Worker 会从本地 Table 获取相应的 Tensor 数据,并通过 RecvTensorResponse 返回。
其中send/recv 的数据传输是通过 WorkerInterface 的派生类作为接口完成的,WorkerInterface 则基于底层的 gRPC 通信库。
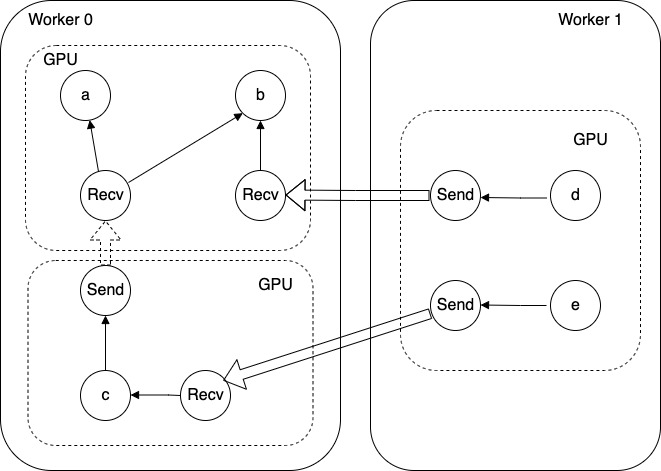
图 1 发送/接受
1.1 消息标识符我们在学习 PyTorch 分布式时候,就知道每次分布式通信都需要有一个全局唯一的标识符,比如:
- 使用 autogradMessageId 来表示一对 send/recv autograd 函数。每 send-recv 对被分配一个全局唯一的autograd_message_id 以唯一地标识该send-recv对。这对于在向后传播期间查找远程节点上的相应函数很有用。
- 此容器还负责维护全局唯一的消息 id,用来关联发送/接收自动微分函数对。格式是一个 64 位整数,前 16 位是工作者 id,后 48 位是 worker 内部自动递增的整数。
类似的,TF 也需要为每一个Send/Recv Pair 确定一个唯一的标识符,这样在多组消息并行发送时候,才不会发生消息错位。这个标识符就是 ParsedKey。
1.1.1 定义其定义如下:
- src_device:发送设备。
- src:和 src_device 信息相同,只不过是表示为结构体。
- src_incarnation:用于 debug,某个 worker 重启后,该值会发生变化,这样就可以区分之前挂掉的worker。
- dst_device:接收方设备。
- dst:和 dst_device 信息相同,只不过表示为结构体。
- edge_name:边名字,可以是张量名字,也可以是某种特殊意义的字符串。
// Parses the key constructed by CreateKey and parse src/dst device
// names into structures respectively.
struct ParsedKey {
StringPiece src_device;
DeviceNameUtils::ParsedName src;
uint64 src_incarnation = 0;
StringPiece dst_device;
DeviceNameUtils::ParsedName dst;
StringPiece edge_name;
ParsedKey() {}
ParsedKey(const ParsedKey& b) { *this = b; }
ParsedKey& operator=(const ParsedKey& b);
StringPiece FullKey() const { return buf_; }
private:
friend class Rendezvous;
friend class SendOp;
friend class RecvOp;
std::string buf_;
};
具体生成字符串 key 结果如下:
src_device ; HexString(src_incarnation) ; dst_device ; name ; frame_iter.frame_id : frame_iter.iter_id
具体代码如下:
/* static */
string Rendezvous::CreateKey(const string& src_device, uint64 src_incarnation,
const string& dst_device, const string& name,
const FrameAndIter& frame_iter) {
// NOTE: ';' is not used in the device name's job name.
//
// We include both sender and receiver in the key to facilitate
// debugging. For correctness, we only need to encode the receiver.
//
// "src_incarnation" is used to distinguish a worker when it
// restarts.
char buf[strings::kFastToBufferSize];
return strings::StrCat(
src_device, ";", strings::Uint64ToHexString(src_incarnation, buf), ";",
dst_device, ";", name, ";", frame_iter.frame_id, ":", frame_iter.iter_id);
}
然后系统会使用 ParseKey 方法来解析key,生成 ParsedKey。ParseKey 对输入 key 的前四个域做了映射,抛弃第五个域 frame_iter.frame_id : frame_iter.iter_id。其他都直接对应字面意思,只是 edge_name 对应了 name。
/* static */
Status Rendezvous::ParseKey(StringPiece key, ParsedKey* out) {
if (key.data() == out->buf_.data()) {
// Caller used our buf_ string directly, so we don't need to copy. (The
// SendOp and RecvOp implementations do this, for example).
DCHECK_EQ(key.size(), out->buf_.size());
} else {
// Make a copy that our StringPieces can point at a copy that will persist
// for the lifetime of the ParsedKey object.
out->buf_.assign(key.data(), key.size());
}
StringPiece s(out->buf_);
StringPiece parts[5];
for (int i = 0; i < 5; i++) {
parts[i] = ConsumeNextPart(&s, ';');
}
if (s.empty() && // Consumed the whole string
!parts[4].empty() && // Exactly five parts
DeviceNameUtils::ParseFullName(parts[0], &out->src) &&
strings::HexStringToUint64(parts[1], &out->src_incarnation) &&
DeviceNameUtils::ParseFullName(parts[2], &out->dst) &&
!parts[3].empty()) {
out->src_device = StringPiece(parts[0].data(), parts[0].size());
out->dst_device = StringPiece(parts[2].data(), parts[2].size());
out->edge_name = StringPiece(parts[3].data(), parts[3].size());
return Status::OK();
}
return errors::InvalidArgument("Invalid rendezvous key: ", key);
}
Rendezvous 是一个抽象,用于从生产者向消费者传递张量。一个 rendezvous 是一个通道(channels)的表(table)。每个通道都由一个 rendezvous 键来标记。该键编码为<生产者,消费者>对,其中生产者和消费者是 tensorflow 设备。
生产者调用 Send() 方法在一个命名的通道上发送一个张量。消费者调用 Recv() 方法从一个指定的通道接收一个张量。一个张量的序列可以从生产者传递给消费者。 消费者按照生产者发送的顺序接收它们。
消费者可以在张量产生之前或之后安全地请求张量。 消费者可以选择进行阻塞式调用或提供回调:无论哪种情况,消费者都会在张量可用时收到它。 生产者永远不会阻塞。
1.2.1 接口类RendezvousInterface 是接口类,定义了虚函数。ParsedKey 也是定义在这里(我们省略了这部分代码)。
class RendezvousInterface {
public:
struct Args {
DeviceContext* device_context = nullptr;
AllocatorAttributes alloc_attrs;
CancellationManager* cancellation_manager = nullptr; // not owned.
};
// The caller is a tensor producer and it sends a message (a tensor
// "val" and a bool "is_dead") under the given "key".
//
// {val, is_dead} is bundled as a message sent and received.
// Typically, is_dead is set by some control flow nodes
// (e.g., a not-taken branch). args is passed by Send to the
// Recv function to communicate any information that the Recv
// function might need. This is typically only necessary for
// Send/Recv on the same worker.
//
// Send() never blocks.
virtual Status Send(const ParsedKey& key, const Args& args, const Tensor& val,
const bool is_dead) = 0;
// Callback provided by a tensor consumer waiting on the rendezvous.
// It will be invoked when the tensor is available, or when a non-OK
// status arises in the production of that tensor. It also gets
// two Rendezvous::Args, one provided by the sender, the other by the
// receiver, which may be needed when a non-CPU device is in use
// by either side.
typedef std::function<void(const Status&, const Args&, const Args&,
const Tensor&, const bool)>
DoneCallback;
virtual void RecvAsync(const ParsedKey& key, const Args& args,
DoneCallback done) = 0;
// Synchronous wrapper for RecvAsync.
Status Recv(const ParsedKey& key, const Args& args, Tensor* val,
bool* is_dead, int64_t timeout_ms);
Status Recv(const ParsedKey& key, const Args& args, Tensor* val,
bool* is_dead);
// Aborts all pending and future Send/Recv with the given "status".
// StartAbort() does not wait for ongoing calls to finish.
// REQUIRES: !status.ok()
virtual void StartAbort(const Status& status) = 0;
protected:
virtual ~RendezvousInterface();
virtual bool is_cross_process() { return false; }
friend class ProcessFunctionLibraryRuntime;
};
Rendezvous 类提供了最基本的 Send、Recv 和 RecvAsync 的实现,也提供了 ParseKey 功能。
// A reference-counted implementation of RendezvousInterface.
//
// This class is used in cases where a rendezvous may be shared between multiple
// threads with no clear owner.
class Rendezvous : public RendezvousInterface, public core::RefCounted {
public:
class Factory {
public:
// Default to a factory that evaluates to false.
Factory() : valid_(false) {}
Factory(std::function<Status(const int64_t, const DeviceMgr*, Rendezvous**)>
create_fn,
std::function<Status(const int64_t)> cleanup_fn)
: valid_(true),
create_fn_(std::move(create_fn)),
cleanup_fn_(std::move(cleanup_fn)) {}
// If no clean up fn is provided, just put in a dummy.
// For backwards compatibility.
explicit Factory(
std::function<Status(const int64_t, const DeviceMgr*, Rendezvous**)>
create_fn)
: valid_(true),
create_fn_(std::move(create_fn)),
cleanup_fn_([](const int64_t step_id) { return Status::OK(); }) {}
explicit operator bool() const { return valid_; }
Status operator()(const int64_t step_id, const DeviceMgr* device_mgr,
Rendezvous** rendez) const {
return create_fn_(step_id, device_mgr, rendez);
}
Status CleanUp(const int64_t step_id) const { return cleanup_fn_(step_id); }
private:
bool valid_;
std::function<Status(const int64_t, const DeviceMgr*, Rendezvous**)>
create_fn_;
std::function<Status(const int64_t)> cleanup_fn_;
};
// Constructs a rendezvous key for the tensor of "name" sent from
// "src_device" to "dst_device". The tensor is generated in the frame
// and iteration specified by "frame_iter".
static std::string CreateKey(const std::string& src_device,
uint64 src_incarnation,
const std::string& dst_device,
const std::string& name,
const FrameAndIter& frame_iter);
static Status ParseKey(StringPiece key, ParsedKey* out);
};
RemoteRendezvous 继承了 Rendezvous,其只增加了一个纯虚函数 Initialize 方法。所有跨进程通信的派生类都需要重写此函数,因为需要借助 Session 成初始化工作。
RemoteRendezvous 可以处理两个远端进程之中生产者或消费者的情况,增加了与远程工作者协调的功能。RemoteRendezvous 遵循两阶段初始化策略:首先,对象被构建。最终,它们将被初始化。RendezvousMgrInterface 的客户端必须保证最终对返回的 RemoteRendezvous 调用了 nitialize 方法。
// RemoteRendezvous follow a 2-part initialization. First the objects are
// constructed. Eventually, they will be initialized. Clients of the
// RendezvousMgrInterface must guarantee to call Initialize on the returned
// RemoteRendezvous eventually.
//
// Partially initialized RemoteRendezvous must respect the Rendezvous interface
// (i.e. Send() must never block), however implementations are not expected to
// actually perform the underlying operations until after the RemoteRendezvous
// has been Initialize'd.
class RemoteRendezvous : public Rendezvous {
public:
// Fully construct the RemoteRendezvous.
virtual Status Initialize(WorkerSession* session) = 0;
protected:
bool is_cross_process() override { return true; }
};
因为跨进程通信存在不同协议,所以跨进程通信的各种 Rendezvous 都需要依据自己不同的协议来实现。所以 TF 在 RemoteRendezvous 和真正特化的各种 Rendezvous 中间加入了一个中间层 BaseRemoteRendezvous,这个类起到了承上启下的作用,提供了公共的 Send 和 Recv 方法,可以做到尽可能代码复用。
BaseRemoteRendezvous 主要成员变量是 Rendezvous* local_,代码之中大量使用了 BaseRecvTensorCall 作为参数,BaseRecvTensorCall 是通信的实体抽象。
// RemoteRendezvous is a Rendezvous which can handle either
// the producer or consumer being in a remote process.
//
// Buffering of Tensor values is delegated to a "local" Rendezvous
// obtained from NewLocalRendezvous(). This class just adds
// functionality to coordinate with remote workers.
class BaseRemoteRendezvous : public RemoteRendezvous {
public:
BaseRemoteRendezvous(const WorkerEnv* env, int64_t step_id);
// Upgrades the BaseRemoteRendezvous to full initialization.
Status Initialize(WorkerSession* session) override;
// Forwards to local_, where the Tensor "val" will be buffered and
// any waiting callback stored.
Status Send(const ParsedKey& key, const Rendezvous::Args& args,
const Tensor& val, const bool is_dead) override;
// This method is called only by the RecvOp. It tests to see
// whether the value will be produced by a local or remote device
// and handles accordingly. In the local case it forwards to
// local_, in the remote case it initiates an RPC request.
void RecvAsync(const ParsedKey& key, const Rendezvous::Args& args,
DoneCallback done) override;
void StartAbort(const Status& status) override;
// This method is called only by the local Worker, forwarded through
// the same method on RendezvousMgr. This occurs when the Worker
// has received a RecvTensor request, either locally or over the
// network. In either case it needs to retrieve a locally buffered
// value from local_, and give it to its caller.
//
// Runs "done" as soon as the tensor for "parsed" is available or an error
// is detected.
//
// REQUIRES: "parsed" is one that will be Saved into the local rendezvous.
void RecvLocalAsync(const ParsedKey& parsed, DoneCallback done);
protected:
virtual void RecvFromRemoteAsync(const Rendezvous::ParsedKey& parsed,
const Rendezvous::Args& args,
DoneCallback done) = 0;
// Returns true if "src" and "dst" are located in the same worker,
// and hence may use a local rendezvous.
virtual bool IsSameWorker(DeviceNameUtils::ParsedName src,
DeviceNameUtils::ParsedName dst);
// If aborted, aborts "call". Otherwise, adds "call" into active_.
void RegisterCall(BaseRecvTensorCall* call, const Rendezvous::Args& args);
// Removes "call" from active_ if "call" is in active_.
void DeregisterCall(BaseRecvTensorCall* call);
WorkerSession* session();
bool is_initialized();
~BaseRemoteRendezvous() override;
const WorkerEnv* const env_; // Not owned.
const int64_t step_id_;
private:
Rendezvous* local_; // Owns a Ref on this object.
mutable mutex mu_;
// Status given by StartAbort() if any.
Status status_ TF_GUARDED_BY(mu_);
WorkerSession* session_ TF_GUARDED_BY(mu_); // Not owned.
// Data structures to handle calls when partially initialized.
struct DeferredCall {
const ParsedKey parsed;
DoneCallback done;
DeferredCall(const ParsedKey& parsed, DoneCallback done);
};
std::vector<DeferredCall> deferred_calls_ TF_GUARDED_BY(mu_);
typedef std::function<void()> InactiveCallback;
std::unordered_map<BaseRecvTensorCall*, InactiveCallback> active_
TF_GUARDED_BY(mu_);
bool is_initialized_locked() TF_SHARED_LOCKS_REQUIRED(mu_) {
return session_ != nullptr;
}
// If "is_src" is true, checks that the rendezvous key "parsed"'s
// source is in this process. If "is_src" is false, checks that the
// rendezvous key "parsed"'s destination is in this process.
Status ValidateDevices(const Rendezvous::ParsedKey& parsed, bool is_src);
// Callback handling the case when a rendezvous has been
// accomplished in local_ and the consumer is local to this process.
// Tensor "in" will be copied into "out". The key "parsed" encodes
// the src and dst devices.
void SameWorkerRecvDone(const Rendezvous::ParsedKey& parsed,
const Rendezvous::Args& in_args,
const Rendezvous::Args& out_args, const Tensor& in,
Tensor* out, StatusCallback done);
// Must be called only if fully initialized.
void RecvLocalAsyncInternal(const ParsedKey& parsed, DoneCallback done);
TF_DISALLOW_COPY_AND_ASSIGN(BaseRemoteRendezvous);
};
class BaseRecvTensorCall {
public:
BaseRecvTensorCall() {}
virtual ~BaseRecvTensorCall() {}
virtual void Start(std::function<void()> recv_done) = 0;
virtual void StartAbort(const Status& s) = 0;
virtual Status status() const = 0;
private:
TF_DISALLOW_COPY_AND_ASSIGN(BaseRecvTensorCall);
};
在创建时候构建了一个 local Rendezvous,这个 local Rendezvous用来完成基本业务。
BaseRemoteRendezvous::BaseRemoteRendezvous(const WorkerEnv* env,
int64_t step_id)
: env_(env),
step_id_(step_id),
local_(NewLocalRendezvous()),
session_(nullptr) {}
Rendezvous* NewLocalRendezvous() { return new LocalRendezvousWrapper; }
LocalRendezvousWrapper 定义如下:
class LocalRendezvousWrapper : public Rendezvous {
public:
LocalRendezvousWrapper() : impl_(this) {}
Status Send(const ParsedKey& key, const Args& send_args, const Tensor& val,
const bool is_dead) override {
return impl_.Send(key, send_args, val, is_dead);
}
void RecvAsync(const ParsedKey& key, const Args& recv_args,
DoneCallback done) override {
impl_.RecvAsync(key, recv_args, std::move(done));
}
void StartAbort(const Status& status) override { impl_.StartAbort(status); }
private:
LocalRendezvous impl_;
TF_DISALLOW_COPY_AND_ASSIGN(LocalRendezvousWrapper);
};
我们接下来看看 BaseRemoteRendezvous 初始化方法,其中做了基础配置,比如设置session。
Status BaseRemoteRendezvous::Initialize(WorkerSession* session) {
std::vector<DeferredCall> deferred_calls;
{
mutex_lock l(mu_);
if (session_ != nullptr) {
if (session_->worker_name() == session->worker_name()) {
return Status::OK();
}
Status s = errors::Internal(
"Double init! Worker names would have changed from: ",
session_->worker_name(), " -> ", session->worker_name());
return s;
}
session_ = session;
std::swap(deferred_calls, deferred_calls_);
}
for (auto& call : deferred_calls) {
RecvLocalAsyncInternal(call.parsed, std::move(call.done));
}
return Status::OK();
}
RpcRemoteRendezvous 是 RemoteRendezvous 的 gRPC 协议实现。
class RpcRemoteRendezvous : public BaseRemoteRendezvous {
public:
RpcRemoteRendezvous(const WorkerEnv* env, int64_t step_id)
: BaseRemoteRendezvous(env, step_id) {}
protected:
void RecvFromRemoteAsync(const Rendezvous::ParsedKey& parsed,
const Rendezvous::Args& args,
DoneCallback done) override;
private:
~RpcRemoteRendezvous() override {}
TF_DISALLOW_COPY_AND_ASSIGN(RpcRemoteRendezvous);
};
BaseRecvTensorCall 对应的派生类是 RpcRecvTensorCall。
// Used only to retrieve tensors from remote processes.
class RpcRecvTensorCall : public BaseRecvTensorCall {
public:
RpcRecvTensorCall() : wi_(nullptr), dst_device_(nullptr) {}
void Init(WorkerInterface* wi, int64_t step_id, StringPiece key,
AllocatorAttributes alloc_attrs, Device* dst_device,
const Rendezvous::Args& recv_args, Rendezvous::DoneCallback done) {
wi_ = wi;
alloc_attrs_ = alloc_attrs;
dst_device_ = dst_device;
recv_args_ = recv_args;
done_ = std::move(done);
req_.set_step_id(step_id);
req_.set_rendezvous_key(key.data(), key.size());
req_.set_request_id(GetUniqueRequestId());
}
void Reset() {
// The RpcRemoteRendezvous using this object is responsible for calling
// ReleaseWorker() before Reset().
alloc_attrs_ = AllocatorAttributes();
dst_device_ = nullptr;
// We don't clear opts_ and assume that Init will set up the state for
// opts_ appropriately.
req_.Clear();
resp_.Clear();
{
mutex_lock l(mu_);
status_ = Status::OK();
}
done_ = nullptr;
}
~RpcRecvTensorCall() override {
// Since only the RpcRecvTensorFreeList will delete an
// RpcRecvTensorCall, we require that ReleaseWorker() has been called before
// the user releases a Call object to the free list.
CHECK_EQ(static_cast<WorkerInterface*>(nullptr), wi_)
<< "Leaking WorkerInterface in RpcRecvTensorCall destructor.";
}
void Start(std::function<void()> recv_done) override {
StartRTCall(std::move(recv_done));
}
void StartAbort(const Status& s) override {
{
mutex_lock l(mu_);
status_.Update(s);
}
opts_.StartCancel();
}
Status status() const override {
mutex_lock l(mu_);
return status_;
}
void ReleaseWorker(WorkerCacheInterface* worker_cache) {
DCHECK_NE(static_cast<WorkerInterface*>(nullptr), wi_)
<< "RpcRecvTensorCall::ReleaseWorker() called twice.";
worker_cache->ReleaseWorker(src_worker_, wi_);
wi_ = nullptr;
}
const Tensor& tensor() const { return resp_.tensor(); }
bool is_dead() const { return resp_.metadata().is_dead(); }
Device* dst_device() const { return dst_device_; }
const Rendezvous::Args& recv_args() const { return recv_args_; }
const Rendezvous::DoneCallback& done() const { return done_; }
private:
friend class RpcRemoteRendezvous;
// Start the main RecvTensor call, checking for an async abort.
void StartRTCall(std::function<void()> recv_done) {
resp_.InitAlloc(dst_device_, alloc_attrs_);
auto abort_checked = std::make_shared<Notification>();
auto cb = [this, abort_checked,
recv_done = std::move(recv_done)](const Status& s) {
// Make sure the Rendezvous abort checking is finished before running the
// callback, which might destroy the current call object.
abort_checked->WaitForNotification();
if (!s.ok()) {
mutex_lock l(mu_);
status_.Update(s);
}
recv_done();
};
wi_->RecvTensorAsync(&opts_, &req_, &resp_, std::move(cb));
// NOTE: Check if the rendezvous was aborted after sending out the RPC. The
// ordering is important because StartAbort could be called right before
// the RecvTensorAsync request registers its RPC cancellation to opts_.
// In that case, the previous StartAbort would not trigger the
// cancellation of this call.
Status s;
{
mutex_lock l(mu_);
s = status_;
}
if (!s.ok()) {
opts_.StartCancel();
}
// Notify that the abort check has finished.
abort_checked->Notify();
}
string src_worker_;
string src_rel_device_;
WorkerInterface* wi_; // Not owned.
AllocatorAttributes alloc_attrs_;
Device* dst_device_;
CallOptions opts_;
RecvTensorRequest req_;
TensorResponse resp_;
Rendezvous::Args recv_args_;
Rendezvous::DoneCallback done_;
mutable mutex mu_;
Status status_ TF_GUARDED_BY(mu_);
TF_DISALLOW_COPY_AND_ASSIGN(RpcRecvTensorCall);
};
目前的逻辑关系具体如下:
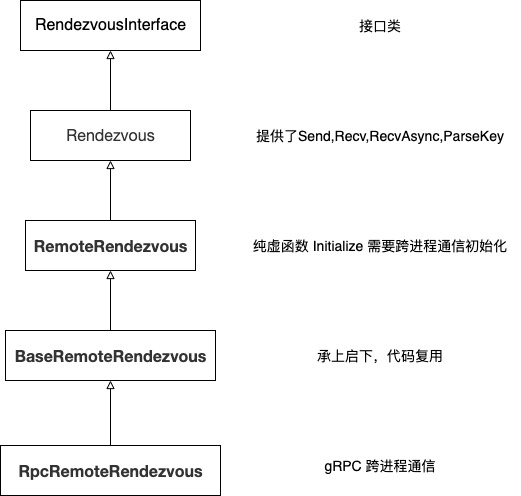
图 2 Rendezvous 逻辑关系
1.3 管理类RendezvousMgr 主要负责创建和销毁 RemoteRendezvous,其会跟踪一组本地的 rendezvous 实例,本工作者发送的所有张量都在 RendezvousMgr 中缓冲,直到张量被接收。 每个全局唯一的 "step_id" 对应于一个由 RendezvousMgr 管理的本地 rendezvous实例。
1.3.1 接口RendezvousMgrInterface 是接口类。
// RendezvousMgr keeps track of a set of local rendezvous instances.
// All tensors sent by this worker are buffered in a RendezvousMgr
// until the tensor is received. Each global unique "step_id"
// corresponds to one local rendezvous instance managed by a
// RendezvousMgr.
//
// E.g.,
// Rendezvous* rendez = worker_env->rendezvous_mgr->Find(0x8935);
// fork execution of an graph executor using "rendez" on thread 1;
// fork execution of another graph executor using "rendez" on thread 2;
// ...
// join threads 1 and 2;
//
// In the example above, execution in thread 1 and 2 communicates with
// each other by send/recv operations through the "rend".
//
// Tensors sent and recved through rendezvous managed by this
// RendezvousMgr must have keys generated by Rendezvous::CreateKey.
class RendezvousMgrInterface {
public:
RendezvousMgrInterface() {}
virtual ~RendezvousMgrInterface() {}
// Returns Rendezvous supporting send and recv among workers in the
// "step_id". The caller takes ownership of one reference on the
// returned Rendezvous instance.
//
// Note: the caller must guarantee to eventually call Initialize on the
// returned RemoteRendezvous
virtual RemoteRendezvous* Find(int64_t step_id) = 0;
// Finds the local rendezvous instance for the "step_id". Runs
// "done" when the tensor for "key" is produced or an error occurs.
//
// This method is used by the rpc handler of RecvTensor.
virtual void RecvLocalAsync(int64_t step_id,
const Rendezvous::ParsedKey& parsed,
Rendezvous::DoneCallback done) = 0;
// Synchronous wrapper for RecvLocalAsync.
virtual Status RecvLocal(int64_t step_id, const Rendezvous::ParsedKey& parsed,
Tensor* val, bool* is_dead) = 0;
// Removes rendezvous for "step_id".
//
// TODO(zhifengc): Have a background thread in worker that
// periodically calls CleanupAll().
virtual void Cleanup(int64_t step_id) = 0;
};
BaseRendezvousMgr 实现了基本功能,比如依据step_id查找Rendezvous。
class BaseRendezvousMgr : public RendezvousMgrInterface {
public:
explicit BaseRendezvousMgr(const WorkerEnv* worker_env);
~BaseRendezvousMgr() override;
// Returns Rendezvous supporting send and recv among workers in the
// "step_id". The caller takes ownership of one reference on the
// returned Rendezvous instance.
//
// Note: the caller must guarantee to eventually call Initialize on the
// returned RemoteRendezvous
RemoteRendezvous* Find(int64_t step_id) override;
// Finds the local rendezvous instance for the "step_id". Runs
// "done" when the tensor for "key" is produced or an error occurs.
//
// This method is used by the rpc handler of RecvTensor.
void RecvLocalAsync(int64_t step_id, const Rendezvous::ParsedKey& parsed,
Rendezvous::DoneCallback done) override;
// Synchronous wrapper for RecvLocalAsync.
Status RecvLocal(int64_t step_id, const Rendezvous::ParsedKey& parsed,
Tensor* val, bool* is_dead) override;
// Removes rendezvous for "step_id".
void Cleanup(int64_t step_id) override;
protected:
virtual BaseRemoteRendezvous* Create(int64_t step_id,
const WorkerEnv* worker_env) = 0;
private:
// Maps step_id to rendezvous.
typedef absl::flat_hash_map<int64_t, BaseRemoteRendezvous*> Table;
// Not owned.
const WorkerEnv* const worker_env_;
mutex mu_;
Table table_ TF_GUARDED_BY(mu_);
BaseRemoteRendezvous* FindOrCreate(int64_t step_id);
TF_DISALLOW_COPY_AND_ASSIGN(BaseRendezvousMgr);
};
在前面执行计算时候,我们看到了一些关于 Rendezvous 的使用,接下来我们就找几个情景来分析一下。
2.1 Worker 接受我们首先看看接受方的 worker。
2.1.1 DoRunGraphWorker 在 DoRunGraph 方法之中会接受张量。
void Worker::DoRunGraph(CallOptions* opts, RunGraphRequestWrapper* request,
MutableRunGraphResponseWrapper* response,
StatusCallback done) {
session->graph_mgr()->ExecuteAsync(
request->graph_handle(), step_id, session.get(), request->exec_opts(),
collector, response, cm, in,
[this, step_id, response, session, cm, out, token, collector,
device_profiler_session, opts, done](const Status& status) {
Status s = status;
if (s.ok()) {
// 接受张量
s = session->graph_mgr()->RecvOutputs(step_id, out);
}
});
}
RecvOutputs 方法如下,就是依据step_id获取一个Rendezvous,然后接受消息。
Status GraphMgr::RecvOutputs(const int64_t step_id, NamedTensors* out) {
Rendezvous* rendezvous = worker_env_->rendezvous_mgr->Find(step_id);
Status s = RecvOutputsFromRendezvous(rendezvous, out, Rendezvous::Args());
rendezvous->Unref();
size_t output_size = 0;
for (auto& p : *out) {
output_size += p.second.AllocatedBytes();
}
return s;
}
具体如下图所示,流程顺序如图上数字,其中第3步返回了一个Rendezvous,RecvOutputsFromRendezvous 是一个全局方法。
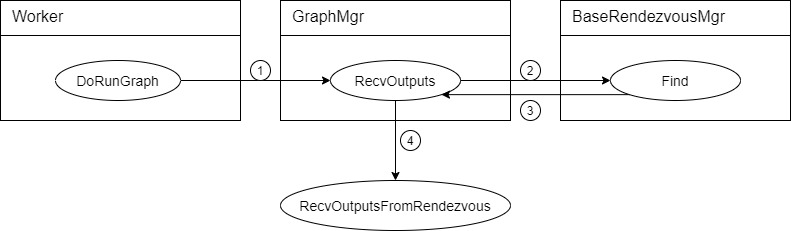
DoPartialRunGraph 会调用 RecvOutputsAsync 完成接受任务。
void Worker::DoPartialRunGraph(CallOptions* opts,
RunGraphRequestWrapper* request,
MutableRunGraphResponseWrapper* response,
StatusCallback done) {
const int64_t step_id = request->step_id();
const string& graph_handle = request->graph_handle();
Status s = recent_request_ids_.TrackUnique(
request->request_id(), "PartialRunGraph (Worker)", request);
std::shared_ptr<WorkerSession> session;
if (request->create_worker_session_called()) {
s = env_->session_mgr->WorkerSessionForSession(request->session_handle(),
&session);
} else {
session = env_->session_mgr->LegacySession();
}
GraphMgr::NamedTensors in;
GraphMgr::NamedTensors* out = new GraphMgr::NamedTensors;
s = PrepareRunGraph(request, &in, out);
auto finish = [done, out, opts](const Status& s) {
opts->ClearCancelCallback();
delete out;
done(s);
};
CancellationManager* cm = nullptr;
bool is_new_partial_run = partial_run_mgr_.FindOrCreate(step_id, &cm);
// Before we start doing anything, we set the RPC cancellation.
opts->SetCancelCallback([this, cm, step_id]() {
cm->StartCancel();
AbortStep(step_id);
});
// If this is a new partial run request, the request will need to start the
// executors.
if (is_new_partial_run) {
CancellationToken token;
token = cancellation_manager_.get_cancellation_token();
cancellation_manager_.RegisterCallback(token,
[cm]() { cm->StartCancel(); });
session->graph_mgr()->ExecuteAsync(
graph_handle, step_id, session.get(), request->exec_opts(),
nullptr /* collector */, nullptr /* response */, cm, in,
[this, token, step_id, session](Status s) {
cancellation_manager_.DeregisterCallback(token);
partial_run_mgr_.ExecutorDone(step_id, s);
});
} else {
// Send the partial run's new inputs.
s = session->graph_mgr()->SendInputs(step_id, in);
}
// 这里会调用到 RecvOutputsAsync 来接受张量
session->graph_mgr()->RecvOutputsAsync(
step_id, out, [this, out, request, response, step_id, finish](Status s) {
if (s.ok()) {
// Construct and return the resp.
for (const auto& p : *out) {
const string& key = p.first;
const Tensor& val = p.second;
response->AddRecv(key, val);
}
}
if (request->is_last_partial_run()) {
partial_run_mgr_.PartialRunDone(step_id, finish, s);
} else {
finish(s);
}
});
}
RecvOutputsAsync 这里调用了 RecvOutputsFromRendezvousAsync。
void GraphMgr::RecvOutputsAsync(const int64_t step_id, NamedTensors* out,
StatusCallback done) {
Rendezvous* rendezvous = worker_env_->rendezvous_mgr->Find(step_id);
std::vector<string> keys;
std::vector<Tensor>* received_keys = new std::vector<Tensor>;
keys.reserve(out->size());
received_keys->reserve(out->size());
for (const auto& p : *out) {
keys.push_back(p.first);
received_keys->push_back(p.second);
}
RecvOutputsFromRendezvousAsync(
rendezvous, nullptr, {}, keys, received_keys,
[done, rendezvous, received_keys, out, keys](const Status s) {
rendezvous->Unref();
size_t output_size = 0;
for (int i = 0, end = keys.size(); i < end; ++i) {
(*out)[keys[i]] = (*received_keys)[i];
output_size += (*out)[keys[i]].AllocatedBytes();
}
metrics::RecordGraphOutputTensors(output_size);
delete received_keys;
done(s);
});
}
具体如下图,流程顺序如图上数字,其中第3步返回了一个Rendezvous,RecvOutputsFromRendezvousAsync是一个全局方法。
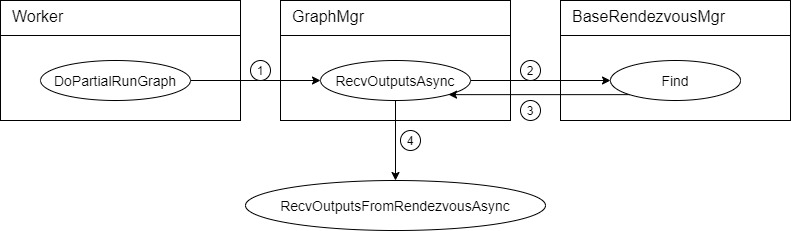
在 ExecuteAsync 之中会发送张量。
void GraphMgr::ExecuteAsync(const string& handle, const int64_t step_id,
WorkerSession* session, const ExecutorOpts& opts,
StepStatsCollector* collector,
MutableRunGraphResponseWrapper* response,
CancellationManager* cancellation_manager,
const NamedTensors& in, StatusCallback done) {
if (s.ok()) {
// 发送张量
s = SendTensorsToRendezvous(rendezvous, nullptr, {}, keys, tensors_to_send);
}
// 执行子计算图
StartParallelExecutors(
handle, step_id, item, rendezvous, ce_handle, collector, cost_graph,
cancellation_manager, session, start_time_usecs,
[item, rendezvous, ce_handle, done, start_time_usecs, input_size,
step_id](const Status& s) {
});
}
SendTensorsToRendezvous 如下:
Status SendTensorsToRendezvous(
RendezvousInterface* rendezvous, DeviceContext* device_context,
const std::vector<AllocatorAttributes>& alloc_attrs,
const std::vector<string>& keys, gtl::ArraySlice<Tensor> tensors_to_send) {
Rendezvous::ParsedKey parsed;
for (int i = 0; i < keys.size(); ++i) {
Rendezvous::Args rendez_args;
rendez_args.device_context = device_context;
if (!alloc_attrs.empty()) {
rendez_args.alloc_attrs = alloc_attrs[i];
}
TF_RETURN_IF_ERROR(Rendezvous::ParseKey(keys[i], &parsed));
TF_RETURN_IF_ERROR(
rendezvous->Send(parsed, rendez_args, tensors_to_send[i], false));
}
return Status::OK();
}
我们接下来就仔细分析一下如何接受和发送。
3. 发送我们首先看看发送流程。Send 过程并不涉及跨进程传输,所以和本地场景下的 Send 传输过程相同,这里只是把张量放到 Worker 的本地 Table 之中,完全不涉及跨网络传输,是非阻塞的。
3.1 BaseRemoteRendezvousSend 方法调用了 local_->Send 完成功能。
Status BaseRemoteRendezvous::Send(const Rendezvous::ParsedKey& parsed,
const Rendezvous::Args& args,
const Tensor& val, const bool is_dead) {
WorkerSession* sess = nullptr;
{
tf_shared_lock l(mu_);
if (!status_.ok()) return status_;
sess = session_;
}
if (!IsLocalDevice(sess->worker_name(), parsed.src_device)) {
return errors::InvalidArgument(
"Invalid rendezvous key (src): ", parsed.FullKey(), " @ ",
sess->worker_name());
}
// Buffers "val" and "device_context" in local_.
return local_->Send(parsed, args, val, is_dead);
}
LocalRendezvous::Send 会把张量插入到本地表。
Status LocalRendezvous::Send(const Rendezvous::ParsedKey& key,
const Rendezvous::Args& send_args,
const Tensor& val, const bool is_dead) {
uint64 key_hash = KeyHash(key.FullKey());
if (is_dead) {
static auto* rendezvous_dead_values_sent = monitoring::Counter<2>::New(
"/tensorflow/core/rendezvous_dead_values_sent",
"The number of dead values sent between a pair of devices.",
"send_device", "recv_device");
rendezvous_dead_values_sent
->GetCell(string(key.src_device), string(key.dst_device))
->IncrementBy(1);
}
mu_.lock();
if (!status_.ok()) {
// Rendezvous has been aborted.
Status s = status_;
mu_.unlock();
return s;
}
ItemQueue* queue = &table_[key_hash];
if (queue->head == nullptr || queue->head->type == Item::kSend) {
// There is no waiter for this message. Append the message
// into the queue. The waiter will pick it up when arrives.
// Only send-related fields need to be filled.
queue->push_back(new Item(send_args, val, is_dead));
mu_.unlock();
return Status::OK();
}
// There is an earliest waiter to consume this message.
Item* item = queue->head;
// Delete the queue when the last element has been consumed.
if (item->next == nullptr) {
table_.erase(key_hash);
} else {
queue->head = item->next;
}
mu_.unlock();
// Notify the waiter by invoking its done closure, outside the
// lock.
DCHECK_EQ(item->type, Item::kRecv);
(*item->recv_state.waiter)(Status::OK(), send_args, item->args, val, is_dead);
delete item;
return Status::OK();
}
此时逻辑如下,这里 Worker 0 指代的是一个工作者角色,并非是 Worker 类。

图 3 发送逻辑
4. 接受发送端现在已经把准备好的张量放入本地 table。接收端需要从发送端的 table 取出张量,这里就涉及了跨进程传输。接受的处理过程是:
- Recv方 是 Client,Recv 方将所需要的 Tensor 对应的 ParsedKey 拼接出来,然后向 Send 方发出 Request,ParsedKey 携带于 Request 之中。
- Send方 是 Server,接收到 Request 后,Send 方立即在本地 Table 中查找 Client 所需要的Tensor,找到后将 Tensor 封装成 Response 发送回 Recv 方。
这里重点是:数据传输由 recv 部分发起,向 Send 方主动发出请求来触发通信过程。这与我们常见的模式不同。我们知道,Worker 之中既有同步调用,也有异步调用,我们选择异步调用来看看。先提前给出一个发送接受流程让大家有个整体认识。下图之中虚线表示返回张量。
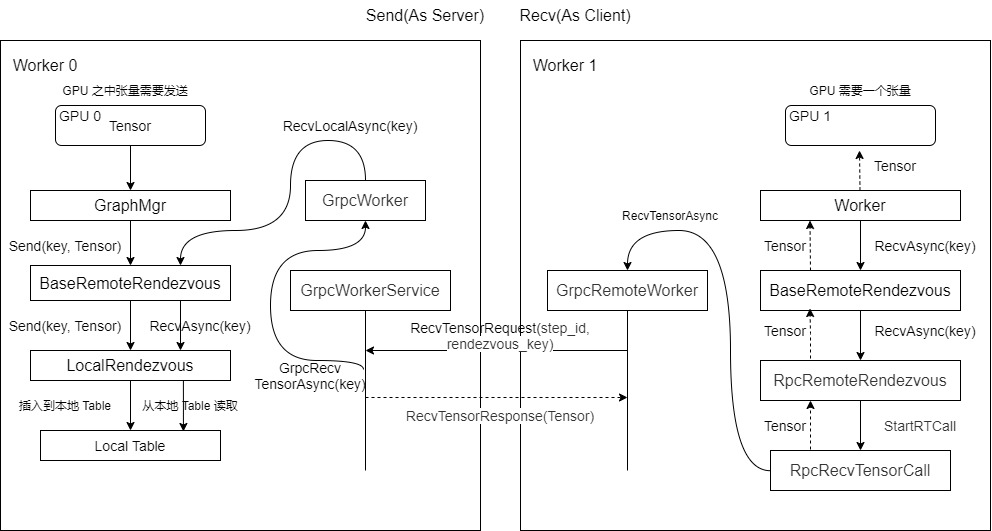
图 4 发送接受整体逻辑
4.1 Client客户端逻辑如下:
4.1.1 RecvOutputsFromRendezvousAsync全局函数 RecvOutputsFromRendezvousAsync 调用到了 rendezvous->RecvAsync。
void RecvOutputsFromRendezvousAsync(
RendezvousInterface* rendezvous, DeviceContext* device_context,
const std::vector<AllocatorAttributes>& alloc_attrs,
const std::vector<string>& keys, std::vector<Tensor>* received_tensors,
StatusCallback done) {
if (keys.empty()) {
done(Status::OK());
return;
}
received_tensors->reserve(keys.size());
std::vector<
std::tuple<string, Tensor*, Rendezvous::ParsedKey, AllocatorAttributes>>
arguments;
for (int i = 0; i < keys.size(); ++i) {
Rendezvous::ParsedKey parsed;
Status s = Rendezvous::ParseKey(keys[i], &parsed);
received_tensors->push_back(Tensor());
if (!s.ok()) {
done(s);
return;
}
AllocatorAttributes alloc_attr;
if (!alloc_attrs.empty()) {
alloc_attr = alloc_attrs[i];
}
arguments.emplace_back(keys[i], &((*received_tensors)[i]), parsed,
alloc_attr);
}
auto status_cb = new ReffedStatusCallback(std::move(done));
for (auto& p : arguments) {
const string& key = std::get<0>(p);
Tensor* val = std::get<1>(p);
Rendezvous::ParsedKey parsed = std::get<2>(p);
Rendezvous::Args rendez_args;
rendez_args.device_context = device_context;
rendez_args.alloc_attrs = std::get<3>(p);
status_cb->Ref();
rendezvous->RecvAsync(
parsed, rendez_args,
[val, key, status_cb](const Status& s,
const Rendezvous::Args& send_args,
const Rendezvous::Args& recv_args,
const Tensor& v, const bool is_dead) {
Status status = s;
if (status.ok()) {
*val = v;
if (is_dead) {
status = errors::InvalidArgument("The tensor returned for ", key,
" was not valid.");
}
}
status_cb->UpdateStatus(status);
status_cb->Unref();
});
}
status_cb->Unref();
}
因为不在一个进程之内,所以调用到了 RecvFromRemoteAsync。
void BaseRemoteRendezvous::RecvAsync(const ParsedKey& parsed,
const Rendezvous::Args& recv_args,
DoneCallback done) {
Status s = ValidateDevices(parsed, false /*!is_src*/);
profiler::ScopedMemoryDebugAnnotation op_annotation("RecvAsync", step_id_);
// Are src and dst in the same worker?
if (IsSameWorker(parsed.src, parsed.dst)) { // 在同一个worker里面
// Recv the tensor from local_.
local_->RecvAsync(
parsed, recv_args,
[this, parsed, done](
const Status& status, const Rendezvous::Args& send_args,
const Rendezvous::Args& recv_args, const Tensor& in, bool is_dead) {
Tensor* out = new Tensor;
StatusCallback final_callback = [done, send_args, recv_args, out,
is_dead](const Status& s) {
done(s, send_args, recv_args, *out, is_dead);
delete out;
};
if (status.ok()) {
SameWorkerRecvDone(parsed, send_args, recv_args, in, out,
std::move(final_callback));
} else {
final_callback(status);
}
});
return;
} else { // 不在同一个worker里面
RecvFromRemoteAsync(parsed, recv_args, std::move(done));
}
}
RpcRemoteRendezvous 检查各项参数,准备 RpcRecvTensorCall,之后启动 call->Start(),Start() 里面调的是 StartRTCall()。RpcRecvTensorCall 继承了 BaseRecvTensorCall 这个抽象基类,是一次 gRPC 调用的抽象,其封装了复杂的后续调用链。这里关键点是如下两句,就是如何使用对应的 Worker 设置 RpcRecvTensorCall:
WorkerInterface* rwi = worker_cache->GetOrCreateWorker(call->src_worker_);
call->Init(rwi, step_id_, parsed.FullKey(), recv_args.alloc_attrs, dst_device,
recv_args, std::move(done));
完整代码如下:
void RpcRemoteRendezvous::RecvFromRemoteAsync(
const Rendezvous::ParsedKey& parsed, const Rendezvous::Args& recv_args,
DoneCallback done) {
CHECK(is_initialized());
Status s;
// Prepare a RecvTensor call that can handle being aborted.
// 生成一个 Call
RpcRecvTensorCall* call = get_call_freelist()->New();
// key.src_device identifies a remote device.
if (!DeviceNameUtils::SplitDeviceName(parsed.src_device, &call->src_worker_,
&call->src_rel_device_)) {
s = errors::Internal(parsed.src_device,
" is invalid remote source device.");
}
WorkerSession* sess = session();
std::shared_ptr<WorkerCacheInterface> worker_cache =
sess->GetSharedWorkerCache();
// The worker will be released in a subsequent call to
// sess->worker_cache()->ReleaseWorker() (if the call has not yet been
// initialized) or call->ReleaseWorker() (if it has been initialized).
// 拿到对应的 Worker
WorkerInterface* rwi = worker_cache->GetOrCreateWorker(call->src_worker_);
Device* dst_device;
if (s.ok()) {
s = sess->device_mgr()->LookupDevice(parsed.dst_device, &dst_device);
}
if (!s.ok()) {
if (rwi != nullptr) {
sess->worker_cache()->ReleaseWorker(call->src_worker_, rwi);
}
get_call_freelist()->Release(call);
done(s, Args(), recv_args, Tensor{}, false);
return;
}
// 用 Worker 来初始化
call->Init(rwi, step_id_, parsed.FullKey(), recv_args.alloc_attrs, dst_device,
recv_args, std::move(done));
// Record "call" in active_ so that it can be aborted cleanly.
RegisterCall(call, recv_args);
// Start "call".
Ref();
call->Start([this, call, worker_cache]() {
// Removes "call" from active_. Prevent StartAbort().
DeregisterCall(call);
// If StartAbort was called prior to DeregisterCall, then the
// current status should be bad.
Status s = call->status();
// NOTE: *session() can potentially be deleted before we return from
// call->done()(...), so we must release the worker before calling the
// callback.
call->ReleaseWorker(session()->worker_cache());
call->done()(s, Args(), call->recv_args(), call->tensor(), call->is_dead());
get_call_freelist()->Release(call);
Unref();
});
}
RpcRecvTensorCall 的 Start 方法如下,结果又来到了 StartRTCall。
void RpcRecvTensorCall::Start(std::function<void()> recv_done) override {
StartRTCall(std::move(recv_done));
}
RpcRecvTensorCall::StartRTCall 之中,会调用 Worker 的 RecvTensorAsync 来完成传输,其实就是 GrpcRemoteWorker 的 RecvTensorAsync。
// Start the main RecvTensor call, checking for an async abort.
void RpcRecvTensorCall::StartRTCall(std::function<void()> recv_done) {
resp_.InitAlloc(dst_device_, alloc_attrs_);
auto abort_checked = std::make_shared<Notification>();
auto cb = [this, abort_checked,
recv_done = std::move(recv_done)](const Status& s) {
// Make sure the Rendezvous abort checking is finished before running the
// callback, which might destroy the current call object.
abort_checked->WaitForNotification();
if (!s.ok()) {
mutex_lock l(mu_);
status_.Update(s);
}
recv_done();
};
wi_->RecvTensorAsync(&opts_, &req_, &resp_, std::move(cb));
// NOTE: Check if the rendezvous was aborted after sending out the RPC. The
// ordering is important because StartAbort could be called right before
// the RecvTensorAsync request registers its RPC cancellation to opts_.
// In that case, the previous StartAbort would not trigger the
// cancellation of this call.
Status s;
{
mutex_lock l(mu_);
s = status_;
}
if (!s.ok()) {
opts_.StartCancel();
}
// Notify that the abort check has finished.
abort_checked->Notify();
}
RecvTensorAsync 方法的缩减版本如下,于是我们回到了熟悉的 Worker 流程。
void GrpcRemoteWorker::RecvTensorAsync(CallOptions* call_opts, const RecvTensorRequest* request, TensorResponse* response, StatusCallback done) override {
IssueRequest(request, response, recvtensor_, callback, call_opts);
}
目前我们完成了下图的右半部分,如图上圆圈所示。
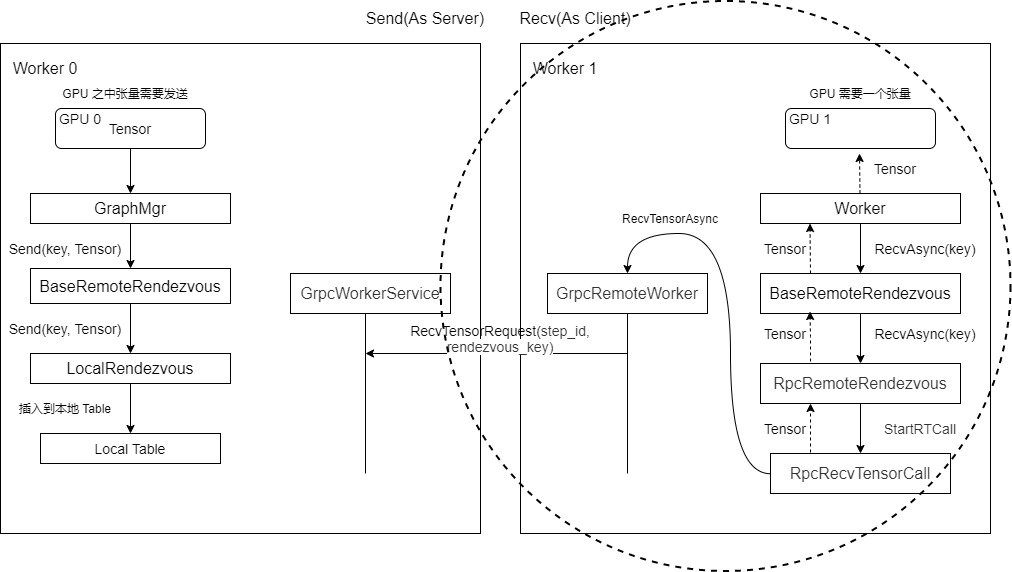
现在我们来到了 Server 端,其实就是张量发送方。接收到 RecvTensorRequest 之后的逻辑如下:
4.2.1 GrpcWorkerServiceGrpcWorkerServiceThread::HandleRPCsLoop 之中有一个 for 循环,插入了 1000 个处理机制,设定了 GrpcWorkerMethod::kRecvTensor 由 EnqueueRecvTensorRequestRaw() 处理。这是事先缓存,为了加速处理,而且 EnqueueRecvTensorRequestRaw 之中在处理一个消息之后,会调用 EnqueueRequestForMethod 再次插入一个处理机制。
void GrpcWorkerServiceThread::HandleRPCsLoop() {
// TODO(ncteisen): This may require performance engineering. We can
// change the number of threads, the number of handlers per thread,
// or even decide to specialize certain threads to certain methods.
SETUP_FOR_REQUEST(GetStatus, 1, false);
SETUP_FOR_REQUEST(CreateWorkerSession, 1, false);
SETUP_FOR_REQUEST(DeleteWorkerSession, 1, false);
SETUP_FOR_REQUEST(CleanupAll, 1, false);
SETUP_FOR_REQUEST(RegisterGraph, 1, false);
SETUP_FOR_REQUEST(DeregisterGraph, 1, false);
SETUP_FOR_REQUEST(Logging, 1, false);
SETUP_FOR_REQUEST(Tracing, 1, false);
SETUP_FOR_REQUEST(CompleteGroup, 10, true);
SETUP_FOR_REQUEST(CompleteInstance, 10, true);
SETUP_FOR_REQUEST(GetStepSequence, 10, true);
SETUP_FOR_REQUEST(RecvBuf, 500, true);
SETUP_FOR_REQUEST(RunGraph, 100, true);
SETUP_FOR_REQUEST(CleanupGraph, 100, false);
SETUP_FOR_REQUEST(MarkRecvFinished, 10, false);
// TODO(ncteisen): Determine a better policy for enqueuing the
// appropriate number of each request type.
for (int i = 0;
i < gtl::FindWithDefault(
queue_depth_, static_cast<int>(GrpcWorkerMethod::kRecvTensor),
1000);
++i) {
EnqueueRecvTensorRequestRaw(); // 设置
}
void* tag;
bool ok;
while (cq_->Next(&tag, &ok)) {
UntypedCall<GrpcWorkerServiceThread>::Tag* callback_tag =
static_cast<UntypedCall<GrpcWorkerServiceThread>::Tag*>(tag);
CHECK(callback_tag);
callback_tag->OnCompleted(this, ok);
}
}
这里会再次插入,会设定由 GrpcWorkerServiceThread::RecvTensorHandlerRaw 继续处理 GrpcWorkerMethod::kRecvTensor。
void EnqueueRecvTensorRequestRaw() {
mutex_lock l(shutdown_mu_);
if (!is_shutdown_) {
Call<GrpcWorkerServiceThread, grpc::WorkerService::AsyncService,
RecvTensorRequest, ::grpc::ByteBuffer>::
EnqueueRequestForMethod(
worker_service_, cq_.get(),
static_cast<int>(GrpcWorkerMethod::kRecvTensor),
&GrpcWorkerServiceThread::RecvTensorHandlerRaw,
true /* supports cancel*/);
}
}
GrpcWorkerServiceThread 是服务端处理请求的线程类。这里就是调用 GrpcWorker 来继续处理。这里使用了 WorkerCall 来作为参数。WorkerCall 是服务端处理一次 gRPC 请求和响应的类,是个别名。
using WorkerCall =
Call<GrpcWorkerServiceThread, grpc::WorkerService::AsyncService,
RequestMessage, ResponseMessage>;
代码具体如下:
void GrpcWorkerServiceThread::RecvTensorHandlerRaw(
WorkerCall<RecvTensorRequest, ::grpc::ByteBuffer>* call) {
Schedule([this, call]() {
CallOptions* call_opts = new CallOptions;
call->SetCancelCallback([call_opts]() { call_opts->StartCancel(); });
worker_->GrpcRecvTensorAsync(
call_opts, &call->request, &call->response,
[call, call_opts](const Status& s) {
call->ClearCancelCallback();
delete call_opts;
if (!s.ok()) {
VLOG(3) << "Bad response from RecvTensor:" << s;
}
call->SendResponse(ToGrpcStatus(s));
});
});
EnqueueRecvTensorRequestRaw();
}
GrpcWorker 是真正负责处理请求逻辑的 Worker,是 GrpcRemoteWorker 的服务端版本。GrpcWorker::GrpcRecvTensorAsync 逻辑是:
- 会获取 rendezvous。使用 rendezvous_mgr->RecvLocalAsync 将客户端所需要的 Tensor 从本地 Table 查找出来。
- 调用 grpc::EncodeTensorToByteBuffer(is_dead, tensor, cache_enabled, response) 把张量编码。
- 然后在 callback 之中调用 CopyDeviceToHost 把张量从 GPU 拷贝到 CPU。
- 最后利用 gRPC 发送回客户端。
// GrpcRecvTensorAsync: unlike the other Worker methods, which use protocol
// buffers for a response object, to avoid extra protocol buffer serialization
// overhead we generate our response directly into a ::grpc::ByteBuffer object
void GrpcWorker::GrpcRecvTensorAsync(CallOptions* opts,
const RecvTensorRequest* request,
::grpc::ByteBuffer* response,
StatusCallback done) {
const int64_t request_id = request->request_id();
const int64_t step_id = request->step_id();
bool cache_enabled = (response_cache_ != nullptr && request_id != 0);
auto do_response = [response, done, cache_enabled](const Tensor& tensor,
bool is_dead,
const Status& status) {
if (status.ok()) {
grpc::EncodeTensorToByteBuffer(is_dead, tensor, cache_enabled, response);
}
done(status);
};
// If response cache is enabled and the response cache already contains the
// request, we delegate this retry request to the response cache. Otherwise,
// we add the request to the response cache and start the computation to
// retrieve the requested data.
if (cache_enabled &&
response_cache_->QueueRequest(request_id, step_id, do_response)) {
return;
}
auto rendezvous_done = [this, request_id, do_response, cache_enabled](
const Tensor& tensor, bool is_dead,
const Status& status) {
if (cache_enabled) {
// Data is ready. Process all pending requests in the response cache.
response_cache_->OnRequestFinished(request_id, tensor, is_dead, status);
} else {
do_response(tensor, is_dead, status);
}
};
auto fail = [&rendezvous_done](const Status& status) {
rendezvous_done(Tensor(), false, status);
};
Status s = recent_request_ids_.TrackUnique(
request_id, "RecvTensor (GrpcWorker)", *request);
const string& key = request->rendezvous_key();
Rendezvous::ParsedKey parsed;
s = Rendezvous::ParseKey(key, &parsed);
Device* src_dev = nullptr;
if (s.ok()) {
s = PrepareRecvTensor(parsed, &src_dev);
}
// Request the tensor associated with the rendezvous key.
// Note that we log the cancellation here but do not abort the current step.
// gRPC can generate cancellations in response to transient network failures,
// and aborting the step eliminates the opportunity for client side retries.
// Repeated client failures will eventually cause the step to be aborted by
// the client.
opts->SetCancelCallback(
[step_id]() { LOG(WARNING) << "RecvTensor cancelled for " << step_id; });
env_->rendezvous_mgr->RecvLocalAsync(
step_id, parsed,
[opts, rendezvous_done, src_dev, request](
const Status& status, const Rendezvous::Args& send_args,
const Rendezvous::Args& recv_args, const Tensor& val,
const bool is_dead) {
opts->ClearCancelCallback();
if (status.ok()) {
// DMA can only be used for Tensors that do not fall into
// the following three odd edge cases: 1) a zero-size
// buffer, 2) a dead tensor which has an uninit value, and
// 3) the tensor has the on_host allocation attribute,
// i.e. it's in CPU RAM *independent of its assigned
// device type*.
const bool on_host = send_args.alloc_attrs.on_host();
{
// Non-DMA cases.
if (src_dev->tensorflow_gpu_device_info() && (!on_host)) {
DeviceContext* send_dev_context = send_args.device_context;
AllocatorAttributes alloc_attrs;
alloc_attrs.set_gpu_compatible(true);
alloc_attrs.set_on_host(true);
Allocator* alloc = src_dev->GetAllocator(alloc_attrs);
Tensor* copy = new Tensor(alloc, val.dtype(), val.shape());
// "val" is on an accelerator device. Uses the device_context to
// fill the copy on host.
StatusCallback copy_ready = [rendezvous_done, copy,
is_dead](const Status& s) {
// The value is now ready to be returned on the wire.
rendezvous_done(*copy, is_dead, s);
delete copy;
};
CopyDeviceToHost(&val, alloc, alloc, request->rendezvous_key(),
src_dev, copy, send_dev_context, copy_ready);
return;
}
}
}
rendezvous_done(val, is_dead, status);
});
}
BaseRendezvousMgr::RecvLocalAsync 会从本地 Table 查找张量。
void BaseRendezvousMgr::RecvLocalAsync(int64_t step_id,
const Rendezvous::ParsedKey& parsed,
Rendezvous::DoneCallback done) {
auto rendez = FindOrCreate(step_id);
auto done_cb = [rendez, done = std::move(done)](
const Status& s, const Rendezvous::Args& send_args,
const Rendezvous::Args& recv_args, const Tensor& v,
bool dead) {
rendez->Unref();
done(s, send_args, recv_args, v, dead);
};
rendez->RecvLocalAsync(parsed, std::move(done_cb));
}
其实,最终调用到了 RecvLocalAsyncInternal,其关键代码是 local_->RecvAsync。
void BaseRemoteRendezvous::RecvLocalAsync(const ParsedKey& parsed,
DoneCallback done) {
// Test whether the rendezvous is initialized using a shared lock, to avoid
// the need for exclusive access in the common case.
if (TF_PREDICT_FALSE(!is_initialized())) {
mutex_lock l(mu_);
if (!is_initialized_locked()) {
// RecvLocalAsync can be called (due to an incoming RecvTensor RPC from a
// remote worker) before the RunStep (or PartialRunStep) RPC from the
// master arrives. RecvLocalAsync thus buffers the arguments until after
// the RemoteRendezvous is Initialize()'d, when it completes the
// rendezvous logic. At some point after Initialize() is called, a Tensor
// is produced locally that will then be sent in response to the incoming
// RPC.
DeferredCall call(parsed, std::move(done));
deferred_calls_.push_back(call);
return;
}
}
RecvLocalAsyncInternal(parsed, std::move(done));
}
void BaseRemoteRendezvous::RecvLocalAsyncInternal(const ParsedKey& parsed,
DoneCallback done) {
Status s = ValidateDevices(parsed, true /* is_src */);
if (!s.ok()) {
done(s, Args(), Args(), Tensor(), false);
return;
}
local_->RecvAsync(parsed, Args(), std::move(done));
}
LocalRendezvous::RecvAsync 完成了从本地 table 读取张量的操作。
void LocalRendezvous::RecvAsync(const Rendezvous::ParsedKey& key,
const Rendezvous::Args& recv_args,
Rendezvous::DoneCallback done) {
uint64 key_hash = KeyHash(key.FullKey());
mu_.lock();
if (!status_.ok()) {
// Rendezvous has been aborted.
Status s = status_;
mu_.unlock();
done(s, Rendezvous::Args(), recv_args, Tensor(), false);
return;
}
ItemQueue* queue = &table_[key_hash];
if (queue->head == nullptr || queue->head->type == Item::kRecv) {
// There is no message to pick up.
// Only recv-related fields need to be filled.
CancellationManager* cm = recv_args.cancellation_manager;
CancellationToken token = CancellationManager::kInvalidToken;
bool already_cancelled = false;
if (cm != nullptr) {
// Increment the refcount when cancellation manager is present, to make
// sure the rendezvous outlives the recv and its cancel callbacks.
// This refcount is dropped in exactly one of the following cases:
// (1) Recv registers cancellation callback to cm, and then cm is
// cancelled, unref in the cancellation callback;
// (2) Recv registers cancellation callback to cm, but cm is already
// cancelled, unref in the already_cancelled check;
// (3) Recv is successful, and item done callback finishes deregistering
// the cancellation callback, unref in the item done callback;
// (4) Recv is successful, but the item done callback fails to deregister
// the cancellation callback because cm already StartCancel, in this
// case the cancellation callback will be invoked by the cm anyway,
// unref in the cancellation callback.
if (rc_owner_) rc_owner_->Ref();
token = cm->get_cancellation_token();
already_cancelled = !cm->RegisterCallback(token, [this, token, key_hash] {
Item* item = nullptr;
{
mutex_lock l(mu_);
ItemQueue* queue = &table_[key_hash];
// Find an item in the queue with a cancellation token that matches
// token, and remove it.
if (queue->head != nullptr && queue->head->type == Item::kRecv) {
for (Item *prev = nullptr, *curr = queue->head; curr != nullptr;
prev = curr, curr = curr->next) {
if (curr->recv_state.cancellation_token == token) {
item = curr;
if (queue->head->next == nullptr) {
// We have a single-element queue, so we can erase it from
// the table.
table_.erase(key_hash);
} else {
// Remove the current item from the queue.
if (curr == queue->head) {
DCHECK_EQ(prev, nullptr);
queue->head = curr->next;
} else {
DCHECK_NE(prev, nullptr);
prev->next = curr->next;
}
if (queue->tail == curr) {
queue->tail = prev;
}
}
break;
}
}
}
}
if (item != nullptr) {
(*item->recv_state.waiter)(
StatusGroup::MakeDerived(
errors::Cancelled("RecvAsync is cancelled.")),
Rendezvous::Args(), item->args, Tensor(), /*is_dead=*/false);
delete item;
}
// Unref case (1) and (4)
if (rc_owner_) rc_owner_->Unref();
});
}
if (already_cancelled) {
mu_.unlock();
// Unref case (2)
if (rc_owner_) rc_owner_->Unref();
done(StatusGroup::MakeDerived(
errors::Cancelled("RecvAsync is cancelled.")),
Rendezvous::Args(), recv_args, Tensor(), /*is_dead=*/false);
return;
}
// TODO(b/143786186): Investigate moving the allocation of Item outside
// the lock.
if (cm != nullptr) {
// NOTE(mrry): We must wrap done with code that deregisters the
// cancellation callback before calling the done callback, because the
// cancellation manager may no longer be live after done is called.
queue->push_back(new Item(
recv_args,
[this, cm, token, done = std::move(done)](
const Status& s, const Rendezvous::Args& send_args,
const Rendezvous::Args& recv_args, const Tensor& v, bool dead) {
// TryDeregisterCallback returns true when the cancellation callback
// is successfully deregistered. If it fails because the CM already
// StartAbort, Unref will happen inside the cancellation callback
// when called by the CM.
if (cm->TryDeregisterCallback(token)) {
// Unref case (3)
if (this->rc_owner_) this->rc_owner_->Unref();
}
done(s, send_args, recv_args, v, dead);
},
token));
} else {
queue->push_back(new Item(recv_args, std::move(done), token));
}
mu_.unlock();
return;
}
// A message has already arrived and is queued in the table under
// this key. Consumes the message and invokes the done closure.
Item* item = queue->head;
// Delete the queue when the last element has been consumed.
if (item->next == nullptr) {
table_.erase(key_hash);
} else {
queue->head = item->next;
}
mu_.unlock();
// Invoke done() without holding the table lock.
DCHECK_EQ(item->type, Item::kSend);
done(Status::OK(), item->args, recv_args, *item->send_state.value,
item->send_state.is_dead);
delete item;
}
最终补齐了之前图的所有逻辑。或者我们也可以从另一种角度来看,如下图所示:
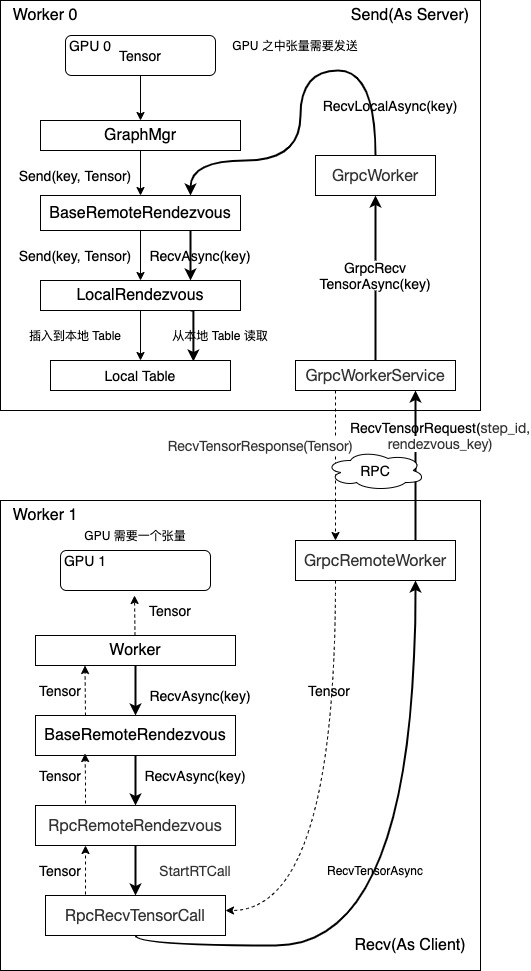
TensorFlow架构与设计:概述
TensorFlow内核剖析
TensorFlow架构与设计:OP本质论
[译] TensorFlow 白皮书
2017TensorFlow开发者峰会
https://jcf94.com/2018/02/28/2018-02-28-tfunpacking3/
TensorFlow 拆包(五):Distributed
TensorFlow Architecture
『深度长文』Tensorflow代码解析(五)
什么是in-graph replication和between-graph replication?
[腾讯机智] TensorFlow源码解析(1): 创建会话
05tensorflow分布式会话
第八节,配置分布式TensorFlow
TensorFlow 分布式(Distributed TensorFlow)
tensorflow源码解析之distributed_runtime
Distributed TensorFlow: A Gentle Introduction
一文说清楚Tensorflow分布式训练必备知识
TensorFlow中的Placement启发式算法模块——Placer
TensorFlow的图切割模块——Graph Partitioner
TensorFlow中的通信机制——Rendezvous(一)本地传输
TensorFlow分布式采坑记
TensorFlow技术内幕(九):模型优化之分布式执行
Tensorflow架构流程]