举例:你点了一份外卖,在无法获知外卖进度的情况下,配送员送外卖是不等人的,到了发现没人取会直接走,所以你只能苦苦等着,时不时去门口看送到没有,无法干别的事情。优化方式就是约定让配送员送到后打电话告知就行,这里打电话就是属于一种中断。
定义:中断其实是一种异步的事件处理机制,可以提高系统的并发处理能力。由于中断处理程序会打断其他进程的运行,所以为了较少对正常进程运行的调度的影响,中断处理程序就需要尽可能快地运行。
b>问题举例:如果定了两份外卖,一份主食一份饮料,并且由两个不同的配送进行配送,你与两个配送员都约定了打电话取外卖。当第一份外卖送到时,你与配送员打了个长长的电话,商量发票的处理问题。那么,第二个配送员到后给你打电话发现一直被占线(关闭了中断响应),第二个配送员之后走掉(丢失了一个中断)
缺点:中断处理程序在响应中断时,会临时关闭中断。也就是会导致上一次的中断处理完成前,其他中断都不能响应,可能存在中断丢失。
2,软中断 a>定义Linux将中断处理过程分成了两个阶段,也就是上半部和下半部:
- 上半部用来快速处理中断,它在中断禁止模式下运行,主要处理跟硬件紧密相关的或时间敏感的工作。直接处理硬件请求,硬中断快速响应
- 下半部用来延时处理上半部未完成的工作,通常以内核线程的方式运行。由内核触发,软中断延迟执行
举例:解决两份外卖的问题,第一份外卖,上半部:与配送员沟通见面再谈事情,然后挂断;下半部:取外卖并商量发票问题。第二份外卖由于第一个配送员并未占用过多时间,可以正常接听。
实际上,上半部会打断CPU正在执行的任务,然后立即执行中断处理程序。而下半部以内核线程的方式执行,并且每个CPU都对应一个软中断内核线程,名字为“ksoftirqd/CPU编号”,比如:0号CPU对应的软中断内核线程的名字为ksoftirqd/0
b>查看软中断和内核线程proc文件系统就是一种内核空间和用户空间进行通信的机制,可以用来查看内核的数据结构,用来动态修改内核的配置。
- /proc/softirqs 提供了软中断的运行情况
- /proc/interrupts 提供了硬中断的运行情况
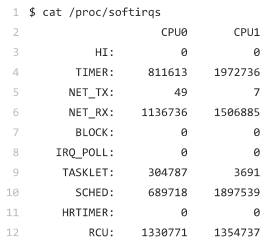
在查看/proc/softirqs文件内容时,需要注意一下两点:
- 软中断的类型,也就是这个界面中第一列的内容。从第一列可以看到,软中断包括了10个类别,分别对应不同的工作类型。比如 NET_RX 表示网络接收的中断,而 NET_TX 表示网络发送中断
- 软中断在不同CPU上的表现。正常情况下,同一种中断在不同CPU上的累积次数应该差不多。比如 NET_RX 在CPU0 和 CPU1 上的中断次数基本是 同一数量级,相差不大。不过TASKLET在不同CPU上的分布并不均匀。TASKLET是最常用的软中断实现机制,每个TASKLET只运行一次就结束,并且只在调用它的函数所在的CPU上运行。
使用两台虚拟机,其中一台用作Web服务器,来模拟性能问题;另一台用作Web服务器的客户端
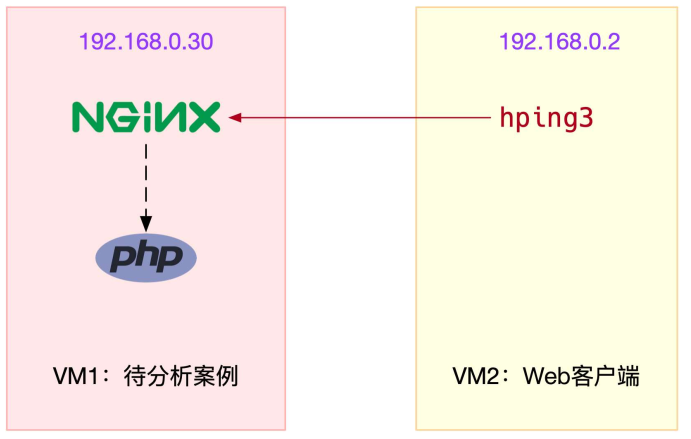
VM1上启动应用

VM2上测试应用

使用hping3模拟请求,发现VM1系统响应变慢

VM1上分析,使用top

可以查看到,CPU负载为0,就绪队列仅有1个running,CPU使用率仅为3.3%和4.4%,但都在软中断上,那么分析问题有可能就出现在软中断上。
观察proc文件系统的软中断情况。其中参数指的是系统运行以来的累积中断次数,故而需要关注中断次数的变化速率。

其中TIMER(定时中断)、NET_RX(网络接收)、SCHED(内核调度)、RCU(RCU锁)等这几个软中断都在不停变化。而其中NET_RX,也就是网络数据包接收软中断的变化速率最快。
sar工具使用,sar可以用来查看系统的网络收发情况,不仅可以观察网络收发的吞吐量(BPS,每秒收发的字节数),还可以观察网络收发的PPS(每秒收发的网络帧数)。
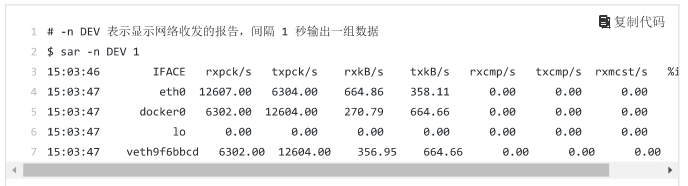
- 第一列:报告的时间
- 第二列:IFACE表示网卡
- 第三、四列:rxpck/s 和 txpck/s 分别表示每秒接收、发送的网络帧数,也就是PPS
- 第五、六列:rxkB/s 和 txkB/s 分别表示每秒接收、发送的千字节数,也就是BPS
对网卡eth0来说,每秒接收的网络帧数比较大,达到了12607,而发送的网络帧数则比较小,只有6304;每秒接收的节数有664KB,发送的字节有 358 KB
docker和veth9f6bbcd 的数据跟 eth0 基本一致,只是发送与接收想法,发送的数据较大而接收的数据较小。这是Linux内部网桥转发导致的,不必关注。这是linux内部网络桥转发导致的。分析eth0:接收的PPS较大为12607,但是BPS却很小为664KB,计算为:664*1024/12607 = 54字节,说明平均每个网络帧只有54字节,很小的网络帧也就是小包问题。
采用tcpdump抓取eth0上的包查看,通过-i eth0选项指定网卡eth0,通过tcp port 80选项指定TCP协议的80端口:

从tcpdump的输出,可以发现:
- 192.168.0.2.18238 > 192.168.0.30.80,表示网络帧从192.168.0.2的18238端口发送到192.168.0.30的80端口,也就是从运行hping3机器的18238端口发送网络帧,目的为Nginx所在机器的80端口。
- Flag [S] 表示是一个SYN包。
结合sar的发现,PPS超过12000,可以确定这就是从192.168.0.2这个地址发送的SYN FLOOD攻击。至于SYN FLOOD攻击最简单的解决方法,就是从交换机或者硬件防火墙中封掉来源IP,这样SYNFLOOD网络帧就不会发送到服务器中。