前言关注公众号【程序员白泽】,带你走进一个不一样的程序员/学生党
最近一直在写《手撕MySQL系列》文章,我发现自己的切入点有一些问题,虽尝试深入探究MySQL中的一些关键特性,但对于MySQL的知识掌握不太能够形成较好的体系化的知识网络。我感到在对全局了解不够清晰的时候,去深究一个知识点往往会事倍功半。所以打算通过这篇文章,分析SQL语句从头到尾的执行,串连一下MySQL当中的基础知识点。
当然希望借助一篇文章深入剖析MySQL所有的关键特性是不够的,后面也会继续更新《手撕MySQL》系列,只是可能会调整写作的切入角度,尽可能帮助阅读文章的同学建立体系化的知识网络。
基础架构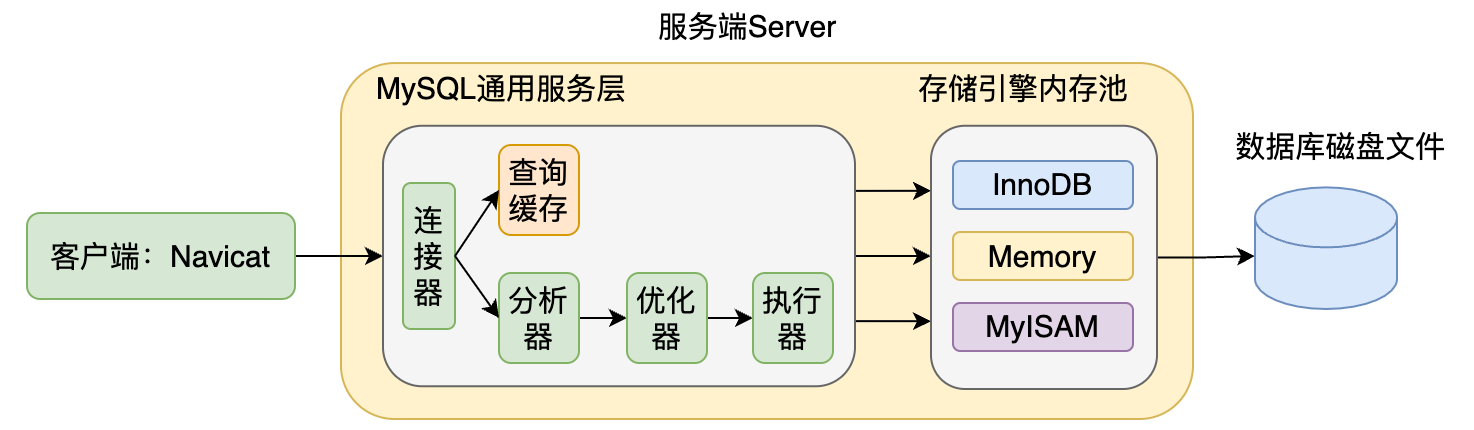
- 客户端:Navicat是一款我们常用的数据库操作工具,通过该数据库客户端软件我们去建立数据库连接,输入SQL语句并提交执行命令。
- 服务端Server:首先要明确的是,客户端运行时是一个进程,那么发起连接,执行SQL等命令都有一个接收进程,那就是MySQL的服务端进程 (你刚开始学MySQL时总是听到启动MySQL服务就是指这个进程) ,借助MySQL服务端进程去处理所有从客户端发起的数据库操作,并且最后将改动持久化到数据库磁盘文件上。
- 存储引擎内存池:将MySQL服务端拆解成两个部分时因为存储引擎是针对表而言的,对于不同的表可以选择不同的存储引擎,并利用其相应的特性满足对应的业务需求,我们在创建一张表的时候最后写的
engine=innodb就是在指定选择的存储引擎,从5.5版本开始,如果不指定存储引擎,则默认使用InnoDB。 - 通用服务层:这一部分包含了MySQL中的通用核心服务,所有跨存储引擎的功能都在这里,包括连接器、查询缓存、分析器、优化器、执行器、以及内置的函数表达式等等 (图上还有很多没画出来,后面的文章中也会逐渐补充进来) 。
- 数据库磁盘文件:这一部分的作用是持久化数据库数据,服务端Server终究是一个运行的进程,所有的数据都是临时存放在内存当中,而我们最终的目的自然是维护一份永久的数据库文件。 (当然不是说内存就不重要,相反,因为客户端操作数据库必然会频繁修改磁盘上的文件,想要操作数据就得先将磁盘中的目标文件页读到内存中,在内存中操作完成之后,再把改动之后的数据页刷新回磁盘,而磁盘IO性能较低,合理使用内存或者说缓存的技术可以减少磁盘IO次数,大大提高数据库访问的性能,这一部分将在后面逐渐介绍) 。
接下来分析下面这条查询语句的执行过程
select * from T where id = 1
- 连接器:首先通过客户端如Navicat连接到这个数据库服务进程 (需要输入目标服务器的IP、端口、用户名、密码) ,而负责与建立连接的就是连接器,负责校验用户名密码,以及获取对应权限。
- 查询缓存:以key-value形式存储一条查询语句对应的结果,如果当前输入的SQL在查询缓存中,可以直接返回查询结果而不用重复执行,但是查询缓存在MySQL8.0被废弃,原因是一条查询缓存对应的表如果发生了修改,则针对这个表的查询缓存都将失效而被清除,如果表更新频率比较高,则会大大提高查询缓存的失效可能,缓存利用率很低,还会额外占用内存开销。
- 分析器:分析器只是一个概称,它的工作是将SQL语句通过解析器成一颗对应的解析树,然后交由预处理器进一步检查解析树的各个部分的语法是否合法,包括对应的表、字段是否存在、名称是否合法等,不合法就抛出错误,通过分析器分析之后合法,则再交由优化器进行分析。
- 优化器:这里先简单理解成一条查询语句涉及的表可能在不同的字段上建立了多个索引,也有可能涉及多个表,这里需要优化器去分析得到一个最优的执行方案(效率最高),比如选择走哪个索引,选择多个表之间的连接顺序等。
- 执行器:校验是否有权限访问SQL中涉及的表,然后配合对应的存储引擎,根据优化器给出的执行方案执行一个SQL,最后返回查询结果。
看到这里你大概对MySQL如何执行一条查询语句的执行流程大概有了概念,也初步熟悉了其中会涉及到的一些 “功能组件” ,但你还不太满足,MySQL的redo log、bin log在哪呢?面试老爱问了! (undo log这里先不提)接下来分析下面这条更新语句的执行过程
update T set a = 0 where id = 1
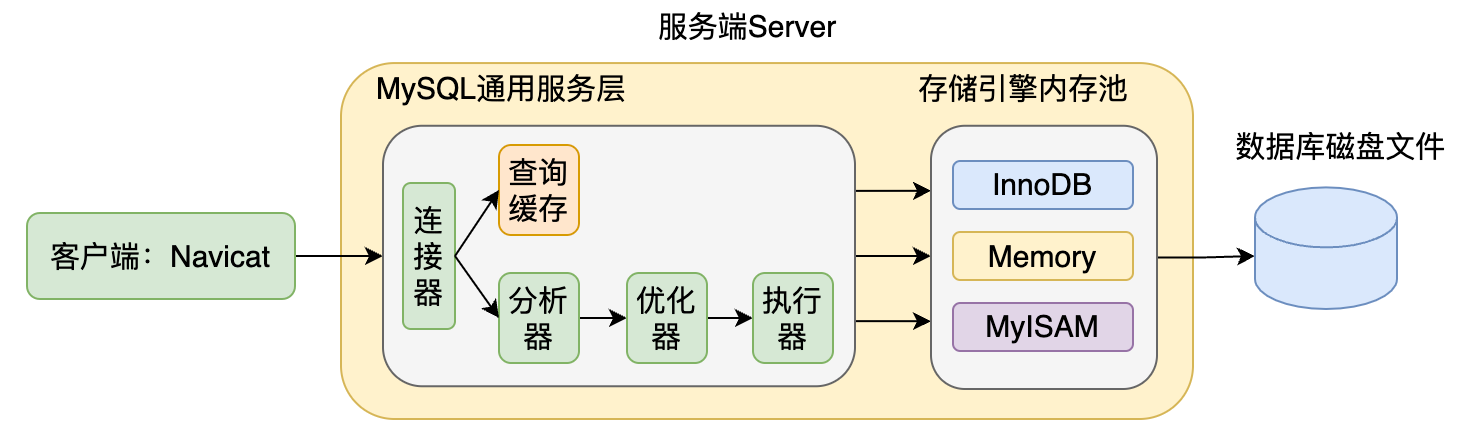
与查询语句相同,执行更新语句也要经过上面那张图中从连接器到执行器的部分,这里我再放一下。区别在于更新表对数据库磁盘文件造成了变更,而查询语句没有。而且前面也提到,MySQL通过一些机制合理减少磁盘IO次数,提升数据库访问性能与可靠性。这里就要介绍一下更新操作中涉及到的两种物理日志文件,redo log和bin log(MySQL服务端内存中也有对应着的日志缓存)。
redo log是InnoDB引擎持有的日志文件(bin log是MySQL通用层的日志文件),也就是说一张表选择InnoDB引擎,在执行更新语句时会同时产生redo和bin两种物理日志文件。 这里先介绍redo log:
前面说了,MySQL通过一些机制可以减少磁盘IO,以及提升数据库可靠性。redo log功不可没,在InnoDB引擎内存池中,维护着redo log。
具体来说,在执行上面那条更新语句的时候,InnoDB引擎会将涉及到的记录读取到内存中(只有对应记录在内存中才可以开始更新),更新对应这条记录的内存(此时磁盘中的这条记录还没更新,但内存中更新了),再将更新记录到redo log缓存。之后redo log缓存会按照一些规则刷新到磁盘文件中的redo log物理文件。而那些在内存中与物理磁盘不同的记录称之为脏页,脏页会通过一种叫checkpoint的规则去刷新到磁盘上(此时才是真的完成了更新)。
上面大概描述了InnoDB引擎在更新时选择先将更新日志记录下来,再最后修改磁盘(称之为WAL技术—Write-Ahead Logging),这样设计的作用是即使MySQL服务因为意外宕机时,之前的更新记录依旧保存在redo log磁盘文件中 (如果只是单纯依赖redo log缓存,则掉电后会遗失这部分数据,而不使用redo log则每次更新表的操作就得进行磁盘IO,无法优化,性能低下) 。
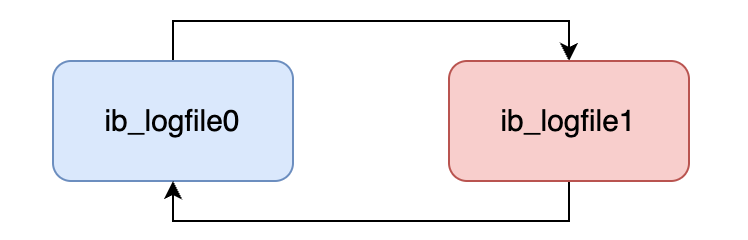
从上面我们可以看到重做日志文件侧重于数据库崩溃时的数据恢复,以及涉及脏页的刷新时机,因此InnoDB引擎对于redo log文件的设计是循环写的,并没有给予无限的增长空间,如下图,如果有两个大小为1G的redo log磁盘文件,则随着redo log缓存逐渐刷新到磁盘上,这两个文件会逐渐被填满,并循环覆盖。因此如果即将被覆盖的redo log代表的操作(脏页)还没有刷新到磁盘,则会触发checkpoint,刷新这些脏页,只要磁盘完成修改,则对应的redo log磁盘文件可以被覆盖掉(这是checkpoint的某一个触发条件)。
bin log是很容易拿来与redo log进行比较的,它是MySQL通用层实现的,记录对数据库表的变更操作,不记录查询,而且由于历史原因,InnoDB引擎是后来出现的,bin log被用于日志归档(较长时间跨度的数据恢复/主从复制),而redo log则侧重于崩溃时保留改动的数据。
下面给出几个bin log与redo log的不同点:
redo log是物理日志,记录的是某条记录发生了什么改动;bin log是逻辑日志,记录的是语句的原始逻辑(bin log也可以选择记录日志的模式)。bin log称为归档日志(可能会根据需求保留过去一个月的数据库变更),因此它是追加写入的,没有大小限制;redo log是循环写入,有大小限制。(这主要是因为侧重的功能不同)redo log是InnoDB引擎层的,bin log是MySQL通用层的。
那么对于使用InnoDB的表,执行上面那条update语句时,redo log和bin log是如何配合工作的呢?步骤简化之后如下:
- 判断表T的id=1的记录是否在内存中
- 不在则先从磁盘读入内存
- 在内存中,将id=1的这条记录的a字段修改为0
- 将修改操作写入磁盘redo log,此时redo log处于prepare状态
- 将修改操作写入磁盘bin log
- 提交事物,将redo log修改为commit状态
二阶段提交的由来是redo log的状态经历了从prepare到commit两个阶段的变化,而二阶段提交的目的就是为了使bin log和redo log在配合使用时,在遇到宕机等情况时数据恢复能保持逻辑上的一致。
如果不使用两阶段提交,只有单一的修改磁盘redo log和磁盘bin log则会有以下两种问题:
- 先写
bin log,后写redo log,在写入bin log之后,服务器宕机,此时redo log未写入,则本地磁盘中将丢失对于数据的更改(也丢失了修改的脏页),而bin log归档文件中已经写入了修改逻辑,那么用这个bin log进行数据恢复或者主从复制会使得与当前数据库表数据之间出现不同。 - 先写
redo log,后写bin log,在写入redo log之后,服务器宕机,此时bin log未写入,则本地磁盘中将保留对数据的修改,但是bin log归档文件中没有记录这个修改逻辑。那么用这个bin log进行数据恢复或者主从复制依旧会使得与当前数据库表数据之间出现不同。
使用两阶段可以通过redo log的状态判断本次修改是否在bin log和redo log上都完成了记录,结合回滚和补充提交机制,从而确保数据在两种日志文件中的逻辑一致性。
如果有任何意见请在评论区积极留言关注公众号【程序员白泽】,带你走进一个不一样的程序员/学生党,公众号回复【简历】可以获得我正在使用的简历模板,平时也会同步更新文章。希望大家都能收获心仪的offer~