- [源码解析] TensorFlow 分布式之 ClusterCoordinator
- 1. 思路
- 1.1 使用
- 1.2 问题点
- 2. 定义
- 2.1 Schedule
- 2.2 Join
- 2.3 Done
- 2.4 Fetch
- 3. 数据
- 3.1 建立数据集
- 3.2 PerWorkerDistributedDataset
- 3.3 PerWorkerDatasetFromDatasetFunction
- 3.4 _create_per_worker_resources
- 3.5 PerWorkerValues
- 4. Cluster
- 4.1 定义
- 4.2 Schedule
- 4.3 停止
- 5. 任务 Closure
- 5.1 执行
- 5.2 取消
- 5.3 ResourceClosure
- 6. 队列
- 6.1 定义
- 6.2 插入取出
- 6.3 等待
- 6.4 异常&结束
- 6.5 停止
- 7.4 Worker
- 7.1 定义
- 7.2 处理
- 7.2.1 等待
- 7.2.2 处理任务
- 7.3 数据
- 7.4 停止
- 7.5 与 Strategy 联系
- 8. Failover
- 8.1 策略
- 8.2 工作者失败
- 8.3 参数服务器或者协调器故障
- 8.4 返回 RemoteValue
- 8.5 错误报告
- 8.6 WorkerPreemptionHandler
- 8.6.1 配置
- 8.6.2 等待
- 8.6.3 handler
- 9. 总结
- 0xFF 参考
- 1. 思路
本文我们主要来看看ParameterServerStrategy如何分发计算,也就是ClusterCoordinator如何运作。这是TF分布式的最后一篇。
安利两个github,都是非常好的学习资料,推荐。
https://github.com/yuhuiaws/ML-study
https://github.com/Jack47/hack-SysML
另外推荐西门宇少的最新大作让Pipeline在Transformer LM上沿着Token level并行起来——TeraPipe。
本系列其他文章是:
[翻译] TensorFlow 分布式之论文篇 "TensorFlow : Large-Scale Machine Learning on Heterogeneous Distributed Systems"
[翻译] TensorFlow 分布式之论文篇 "Implementation of Control Flow in TensorFlow"
[源码解析] TensorFlow 分布式环境(1) --- 总体架构
[源码解析] TensorFlow 分布式环境(2)---Master 静态逻辑
[源码解析] TensorFlow 分布式环境(3)--- Worker 静态逻辑
[源码解析] TensorFlow 分布式环境(4) --- WorkerCache
[源码解析] TensorFlow 分布式环境(5) --- Session
[源码解析] TensorFlow 分布式环境(7) --- Worker 动态逻辑
[源码解析] TensorFlow 分布式环境(8) --- 通信机制
[翻译] 使用 TensorFlow 进行分布式训练
[源码解析] TensorFlow 分布式 DistributedStrategy 之基础篇
[源码解析] TensorFlow 之 分布式变量
[源码解析] TensorFlow 分布式之 MirroredStrategy
[源码解析] TensorFlow 分布式之 MirroredStrategy 分发计算
[源码解析] TensorFlow 分布式之 ParameterServerStrategy V1
[源码解析] TensorFlow 分布式之 ParameterServerStrategy V2
1. 思路TensorFlow 2 推荐使用一种基于中央协调的架构来进行参数服务器训练。每个工作者和参数服务器都运行一个 tf.distribution.Server,在此基础上,一个协调者任务负责在工作者和参数服务器上创建资源,调度功能,并协调训练。协调器使用 tf.distribution.experimental.coordinator.ClusterCoordinator 来协调集群,使用 tf.distribution.experimental.ParameterServerStrategy 来定义参数服务器上的变量和工作者的计算。
ClusterCoordinator 是一个用于安排和协调远程函数执行的对象。该类用于创建容错(fault-tolerant)资源和调度函数到远程 TensorFlow 服务器。目前该类不支持独立使用,它应该与旨在与之合作的 tf.distribution 策略一起使用。ClusterCoordinator 类目前只适用于和 tf.distribution.experimental.ParameterServerStrategy 一起工作。

在使用 ParameterServerStrategy 定义所有的计算后,用户可以使用 tf.distribution.experimental.coordinator.ClusterCoordinator 类来创建资源并将训练步骤分配给远程工作者。
首先,我们来创建一个 ClusterCoordinator 对象并传入策略对象。
strategy = tf.distribute.experimental.ParameterServerStrategy(cluster_resolver=...)
coordinator = tf.distribute.experimental.coordinator.ClusterCoordinator(strategy)
其次,创一个属于每个工作者(per-worker)的数据集和一个迭代器。在下面代码的 per_worker_dataset_fn 中,建议将 dataset_fn 包裹到 strategy.distribution_datasets_from_function 中,以允许无缝高效的把数据预取(prefetching )到 GPU。
@tf.function
def per_worker_dataset_fn():
return strategy.distribute_datasets_from_function(dataset_fn)
per_worker_dataset = coordinator.create_per_worker_dataset(per_worker_dataset_fn)
per_worker_iterator = iter(per_worker_dataset)
最后一步是使用 ClusterCoordinator.schedule 将计算分配给远程工作者。
- schedule 方法把一个 tf.function 插入队列,并立即返回一个 future-like 的 RemoteValue 。队列之中的函数将被派发给后台线程中的远程工作者,RemoteValue 将被异步填充结果。
- 用户可以使用 join 方法( ClusterCoordinator.join )来等待所有被规划(scheduled)的函数执行。
@tf.function
def step_fn(iterator):
return next(iterator)
num_epoches = 4
steps_per_epoch = 5
for i in range(num_epoches):
accuracy.reset_states()
for _ in range(steps_per_epoch):
coordinator.schedule(step_fn, args=(per_worker_iterator,))
# Wait at epoch boundaries.
coordinator.join()
print ("Finished epoch %d, accuracy is %f." % (i, accuracy.result().numpy()))
下面是如何得到 RemoteValue 的结果。
loss = coordinator.schedule(step_fn, args=(per_worker_iterator,))
print ("Final loss is %f" % loss.fetch())
用户也可以启动所有的步骤(steps),并在等待完成时做一些事情。
for _ in range(total_steps):
coordinator.schedule(step_fn, args=(per_worker_iterator,))
while not coordinator.done():
time.sleep(10)
# Do something like logging metrics or writing checkpoints.
依据前面的代码,我们总结出来问题点如下:
- Worker 如何知道使用哪些设备?
- 如何具体执行用户函数?
- 如何获取数据?
接下来我们就尝试通过分析代码来回答这些问题。
2. 定义ClusterCoordinator 的主要思路如下。
- 协调者不是训练工作者之一,相反,它负责创建资源,如变量和数据集,调度 "tf.function",保存检查点等等。
- 为了使训练工作顺利进行,协调者派遣 "tf.function" 在远程工作者上执行。
- 在收到协调者的请求后,工作者通过从参数服务器读取变量、执行操作和更新参数服务器上的变量来执行 "tf.function"。
- 每个工作者只处理来自协调者的请求,并与参数服务器进行通信。而不与集群中的其他工作者直接互动。

ClusterCoordinator 定义具体如下,我们可以看到,其主要是配置了 _strategy 成员变量,生成了 _cluster 成员变量。
@tf_export("distribute.experimental.coordinator.ClusterCoordinator", v1=[])
class ClusterCoordinator(object):
def __new__(cls, strategy):
# ClusterCoordinator is kept as a single instance to a given Strategy .
if strategy._cluster_coordinator is None:
strategy._cluster_coordinator = super(
ClusterCoordinator, cls).__new__(cls)
return strategy._cluster_coordinator
def __init__(self, strategy):
"""Initialization of a ClusterCoordinator instance.
Args:
strategy: a supported tf.distribute.Strategy object. Currently, only
tf.distribute.experimental.ParameterServerStrategy is supported.
Raises:
ValueError: if the strategy being used is not supported.
"""
if not getattr(self, "_has_initialized", False):
if not isinstance(strategy,
parameter_server_strategy_v2.ParameterServerStrategyV2):
raise ValueError(
"Only tf.distribute.experimental.ParameterServerStrategy "
"is supported to work with "
" tf.distribute.experimental.coordinator.ClusterCoordinator "
"currently.")
self._strategy = strategy
self.strategy.extended._used_with_coordinator = True
self._cluster = Cluster(strategy)
self._has_initialized = True
def __del__(self):
self._cluster.stop()
@property
def strategy(self):
"""Returns the Strategy associated with the ClusterCoordinator ."""
return self._strategy
由 ClusterCoordinator 对象提供的最重要的 API 是 schedule,其会分派 tf.function 到一个工作者,以便异步执行,具体如下:
- 该方法是非阻塞的,因为它把 fn 插入队列,并立即返回 tf.distribution.experimental.coordinator.RemoteValue 对象。fn 排队等待稍后执行。
- 在队列之中排队的函数将被派发给后台线程中的远程工作者来异步执行,他们的 RemoteValue 将被异步赋值。
- 由于 schedule 不需要分配一个工作者,传递进来的 tf.function 可以在任何可用的工作者上执行。
- 可以调用 fetch 来等待函数执行完成,并从远程工作者那里获取其输出。另一方面,也可以调用 tf.distribution.experimental.coordinator.ClusterCoordinator.join 来等待所有预定的函数完成。
失败和容错的策略如下:
- 由于工作者在执行函数的任何时候都可能失败,所以函数有可能被部分执行,但是 tf.distribution.experimental.coordinator.ClusterCoordinator 保证在这些事件中,函数最终将在任何可用的工作者上执行。
- schedule 保证 fn 至少在工作者上执行一次;如果其对应的工作者在执行过程中失败,由于函数的执行不是原子性的,所以一个函数可能被执行多次。
- 如果被执行的工作者在结束之前变得不可用,该函数将在另一个可用的工作者上重试。
- 如果任何先前安排的函数出现错误,schedule 将抛出其中任何一个错误,并清除到目前为止收集的错误。用户可以在返回的 tf.distribution.experimental.coordinator.RemoteValue 上调用 fetch 来检查它们是否已经执行、失败或取消,如果需要,可以重新安排相应的函数。当 schedule 引发异常时,它保证没有任何函数仍在执行。
Schedule 的具体定义如下,数据迭代器作为参数之一会和 fn 一起被传入。
def schedule(self, fn, args=None, kwargs=None):
"""Schedules fn to be dispatched to a worker for asynchronous execution.
This method is non-blocking in that it queues the fn which will be
executed later and returns a
tf.distribute.experimental.coordinator.RemoteValue object immediately.
fetch can be called on it to wait for the function execution to finish
and retrieve its output from a remote worker. On the other hand, call
tf.distribute.experimental.coordinator.ClusterCoordinator.join to wait for
all scheduled functions to finish.
schedule guarantees that fn will be executed on a worker at least once;
it could be more than once if its corresponding worker fails in the middle
of its execution. Note that since worker can fail at any point when
executing the function, it is possible that the function is partially
executed, but tf.distribute.experimental.coordinator.ClusterCoordinator
guarantees that in those events, the function will eventually be executed on
any worker that is available.
If any previously scheduled function raises an error, schedule will raise
any one of those errors, and clear the errors collected so far. What happens
here, some of the previously scheduled functions may have not been executed.
User can call fetch on the returned
tf.distribute.experimental.coordinator.RemoteValue to inspect if they have
executed, failed, or cancelled, and reschedule the corresponding function if
needed.
When schedule raises, it guarantees that there is no function that is
still being executed.
At this time, there is no support of worker assignment for function
execution, or priority of the workers.
args and kwargs are the arguments passed into fn , when fn is
executed on a worker. They can be
tf.distribute.experimental.coordinator.PerWorkerValues and in this case,
the argument will be substituted with the corresponding component on the
target worker. Arguments that are not
tf.distribute.experimental.coordinator.PerWorkerValues will be passed into
fn as-is. Currently, tf.distribute.experimental.coordinator.RemoteValue
is not supported to be input args or kwargs .
Args:
fn: A tf.function ; the function to be dispatched to a worker for
execution asynchronously. Regular python funtion is not supported to be
scheduled.
args: Positional arguments for fn .
kwargs: Keyword arguments for fn .
Returns:
A tf.distribute.experimental.coordinator.RemoteValue object that
represents the output of the function scheduled.
Raises:
Exception: one of the exceptions caught by the coordinator from any
previously scheduled function, since the last time an error was thrown
or since the beginning of the program.
"""
if not isinstance(fn,
(def_function.Function, tf_function.ConcreteFunction)):
raise TypeError(
" tf.distribute.experimental.coordinator.ClusterCoordinator.schedule "
" only accepts a tf.function or a concrete function.")
# Slot variables are usually created during function tracing time; thus
# schedule needs to be called within the strategy.scope() .
with self.strategy.scope():
self.strategy.extended._being_scheduled = True
remote_value = self._cluster.schedule(fn, args=args, kwargs=kwargs)
self.strategy.extended._being_scheduled = False
return remote_value
Join 方法的作用是阻塞直到所有预定的函数都执行完毕,其具体特点如下:
- 如果任何先前安排的函数产生错误,join 将因为抛出一个错误而失败,并清除到目前为止收集的错误。如果发生这种情况,一些先前安排的函数可能没有被执行。
- 用户可以对返回的 tf.distribution.experimental.coordinator.RemoteValue 调用 fetch 来检查它们是否已经执行、失败或取消了。
- 如果一些已经取消的函数需要重新安排,用户应该再次调用 schedule 。
- 当 join 返回或抛出异常时,它保证没有任何函数仍在执行。
def join(self):
"""Blocks until all the scheduled functions have finished execution.
If any previously scheduled function raises an error, join will fail by
raising any one of those errors, and clear the errors collected so far. If
this happens, some of the previously scheduled functions may have not been
executed. Users can call fetch on the returned
tf.distribute.experimental.coordinator.RemoteValue to inspect if they have
executed, failed, or cancelled. If some that have been cancelled need to be
rescheduled, users should call schedule with the function again.
When join returns or raises, it guarantees that there is no function that
is still being executed.
Raises:
Exception: one of the exceptions caught by the coordinator by any
previously scheduled function since the last time an error was thrown or
since the beginning of the program.
"""
self._cluster.join()
Done 方法返回所有分发的函数是否已经执行完毕。如果任何先前分发的函数引发错误,done'将会失败。
def done(self):
"""Returns whether all the scheduled functions have finished execution.
If any previously scheduled function raises an error, done will fail by
raising any one of those errors.
When done returns True or raises, it guarantees that there is no function
that is still being executed.
Returns:
Whether all the scheduled functions have finished execution.
Raises:
Exception: one of the exceptions caught by the coordinator by any
previously scheduled function since the last time an error was thrown or
since the beginning of the program.
"""
return self._cluster.done()
Fetch 会获取 remote values 的结果。
def fetch(self, val):
"""Blocking call to fetch results from the remote values.
This is a wrapper around
tf.distribute.experimental.coordinator.RemoteValue.fetch for a
RemoteValue structure; it returns the execution results of
RemoteValue s. If not ready, wait for them while blocking the caller.
Example:
```python
strategy = ...
coordinator = tf.distribute.experimental.coordinator.ClusterCoordinator(
strategy)
def dataset_fn():
return tf.data.Dataset.from_tensor_slices([1, 1, 1])
with strategy.scope():
v = tf.Variable(initial_value=0)
@tf.function
def worker_fn(iterator):
def replica_fn(x):
v.assign_add(x)
return v.read_value()
return strategy.run(replica_fn, args=(next(iterator),))
distributed_dataset = coordinator.create_per_worker_dataset(dataset_fn)
distributed_iterator = iter(distributed_dataset)
result = coordinator.schedule(worker_fn, args=(distributed_iterator,))
assert coordinator.fetch(result) == 1
```
Args:
val: The value to fetch the results from. If this is structure of
tf.distribute.experimental.coordinator.RemoteValue , fetch() will be
called on the individual
tf.distribute.experimental.coordinator.RemoteValue to get the result.
Returns:
If val is a tf.distribute.experimental.coordinator.RemoteValue or a
structure of tf.distribute.experimental.coordinator.RemoteValue s,
return the fetched tf.distribute.experimental.coordinator.RemoteValue
values immediately if they are available, or block the call until they are
available, and return the fetched
tf.distribute.experimental.coordinator.RemoteValue values with the same
structure. If val is other types, return it as-is.
"""
def _maybe_fetch(val):
if isinstance(val, RemoteValue):
return val.fetch()
else:
return val
return nest.map_structure(_maybe_fetch, val)
除了调度远程函数,ClusterCoordinator 还帮助在所有工作者上创建数据集,并当一个工作者从失败中恢复时重建这些数据集。用户可以通过调用 dataset_fn 来在worker设备上创建数据集。使用例子如下:
strategy = tf.distribute.experimental.ParameterServerStrategy(
cluster_resolver=...)
coordinator = tf.distribute.experimental.coordinator.ClusterCoordinator(
strategy=strategy)
@tf.function
def worker_fn(iterator):
return next(iterator)
def per_worker_dataset_fn():
return strategy.distribute_datasets_from_function(
lambda x: tf.data.Dataset.from_tensor_slices([3] * 3))
per_worker_dataset = coordinator.create_per_worker_dataset(
per_worker_dataset_fn)
per_worker_iter = iter(per_worker_dataset)
remote_value = coordinator.schedule(worker_fn, args=(per_worker_iter,))
assert remote_value.fetch() == 3
上面代码使用了 create_per_worker_dataset 在worker上创建数据集,这些数据集由 dataset_fn 生成,并返回一个代表这些数据集的集合。在这样的数据集集合上调用 iter 会返回一个 tf.distribution.experimental.coordinator.PerWorkerValues,它是一个迭代器的集合,其中的迭代器已经被放置在各个工作者上。
需要注意,不支持在迭代器的 "PerWorkerValues"上直接调用 "next"。该迭代器应该是作为一个参数传递给 tf.distribution.experimental.coordinator.ClusterCoordinator.schedule 。当计划的函数即将被工作者执行时,该函数将收到与该工作者相对应的单个迭代器。该函数可以对该迭代器调用 next 方法。
目前,schedule 方法假定工作者都是相同的,因此假设不同工作者上的数据集是一样的,除非它们包含 dataset.shuffle 操作,并且没有设置随机种子,在这种情况下,它们的洗牌方式会不同。正因为如此,建议将数据集无限地重复,并安排有限的步骤,而不是依赖于数据集的 OutOfRangeError 来结束。
def create_per_worker_dataset(self, dataset_fn):
"""Create dataset on workers by calling dataset_fn on worker devices.
This creates the given dataset generated by dataset_fn on workers
and returns an object that represents the collection of those individual
datasets. Calling iter on such collection of datasets returns a
tf.distribute.experimental.coordinator.PerWorkerValues , which is a
collection of iterators, where the iterators have been placed on respective
workers.
Calling next on a PerWorkerValues of iterator is unsupported. The
iterator is meant to be passed as an argument into
tf.distribute.experimental.coordinator.ClusterCoordinator.schedule . When
the scheduled function is about to be executed by a worker, the
function will receive the individual iterator that corresponds to the
worker. The next method can be called on an iterator inside a
scheduled function when the iterator is an input of the function.
Currently the schedule method assumes workers are all the same and thus
assumes the datasets on different workers are the same, except they may be
shuffled differently if they contain a dataset.shuffle operation and a
random seed is not set. Because of this, we also recommend the datasets to
be repeated indefinitely and schedule a finite number of steps instead of
relying on the OutOfRangeError from a dataset.
Args:
dataset_fn: The dataset function that returns a dataset. This is to be
executed on the workers.
Returns:
An object that represents the collection of those individual
datasets. iter is expected to be called on this object that returns
a tf.distribute.experimental.coordinator.PerWorkerValues of the
iterators (that are on the workers).
"""
return values_lib.get_per_worker_dataset(dataset_fn, self)
get_per_worker_dataset 则返回 PerWorkerDatasetFromDataset 或者 PerWorkerDatasetFromDatasetFunction。
def get_per_worker_dataset(dataset_or_dataset_fn, coordinator):
if callable(dataset_or_dataset_fn):
return PerWorkerDatasetFromDatasetFunction(dataset_or_dataset_fn,
coordinator)
else:
return PerWorkerDatasetFromDataset(dataset_or_dataset_fn, coordinator)
PerWorkerDistributedDataset 代表了从一个数据集建立的工作者使用的分布式数据集。
class PerWorkerDatasetFromDataset(PerWorkerDatasetFromDatasetFunction):
"""Represents worker-distributed datasets created from a dataset."""
def __init__(self, dataset, coordinator):
"""Makes an iterable from datasets created by the given dataset.
It creates a dataset_fn which deserializes a dataset from a graph under the
hood.
Args:
dataset: A tf.data.Dataset, a DistributedDataset or a
DistributedDatasetsFromFunction
coordinator: a ClusterCoordinator object, used to create dataset
resources.
"""
if isinstance(dataset, input_lib.DistributedDataset):
original_dataset = dataset._original_dataset
serialized = serialize_dataset_to_graph(original_dataset)
def dataset_fn():
deserialized = deserialize_dataset_from_graph(
serialized, original_dataset.element_spec)
dataset.build(dataset_to_replace=deserialized)
return dataset
elif isinstance(dataset, input_lib.DistributedDatasetsFromFunction):
def dataset_fn():
dataset.build()
return dataset
elif isinstance(dataset, dataset_ops.Dataset):
serialized = serialize_dataset_to_graph(dataset)
def dataset_fn():
return deserialize_dataset_from_graph(serialized, dataset.element_spec)
else:
raise ValueError("Unexpected dataset type!")
super(PerWorkerDatasetFromDataset, self).__init__(dataset_fn, coordinator)
PerWorkerDistributedDataset 代表了从一个数据集方法建立的工作者使用的分布式数据集。
在 iter 之中有:
-
调用 _create_per_worker_iterator 得到一个 iter(dataset)。
-
调用 self._coordinator._create_per_worker_resources 为每工作者生成一个 iterator。
-
最后返回一个 PerWorkerDistributedIterator。
class PerWorkerDatasetFromDatasetFunction(object):
"""Represents worker-distributed datasets created from dataset function."""
def __init__(self, dataset_fn, coordinator):
"""Makes an iterable from datasets created by the given function.
Args:
dataset_fn: A function that returns a Dataset .
coordinator: a ClusterCoordinator object, used to create dataset
resources.
"""
def disallow_variable_creation(next_creator, **kwargs):
raise ValueError("Creating variables in dataset_fn is not allowed.")
if isinstance(dataset_fn, def_function.Function):
with variable_scope.variable_creator_scope(disallow_variable_creation):
dataset_fn = dataset_fn.get_concrete_function()
elif not isinstance(dataset_fn, tf_function.ConcreteFunction):
with variable_scope.variable_creator_scope(disallow_variable_creation):
dataset_fn = def_function.function(dataset_fn).get_concrete_function()
self._dataset_fn = dataset_fn
self._coordinator = coordinator
self._element_spec = None
def __iter__(self):
# We would like users to create iterators outside tf.function s so that we
# can track them.
if (not context.executing_eagerly() or
ops.get_default_graph().building_function):
raise RuntimeError(
"__iter__() is not supported inside of tf.function or in graph mode.")
def _create_per_worker_iterator():
dataset = self._dataset_fn()
return iter(dataset)
# If PerWorkerDatasetFromDatasetFunction.__iter__ is called multiple
# times, for the same object it should only create and register resource
# once. Using object id to distinguish different iterator resources.
per_worker_iterator = self._coordinator._create_per_worker_resources(
_create_per_worker_iterator)
# Setting type_spec of each RemoteValue so that functions taking these
# RemoteValues as inputs can be traced.
for iterator_remote_value in per_worker_iterator._values:
iterator_remote_value._type_spec = (
input_lib.get_iterator_spec_from_dataset(
self._coordinator.strategy, self._dataset_fn.structured_outputs))
return PerWorkerDistributedIterator(per_worker_iterator._values)
@property
def element_spec(self):
"""The type specification of an element of this dataset.
This property is subject to change without notice.
"""
return self._dataset_fn.structured_outputs.element_spec
_create_per_worker_resources 会调用各个工作者的方法来让每个工作者得到数据。
def _create_per_worker_resources(self, fn, args=None, kwargs=None):
"""Synchronously create resources on the workers.
The resources are represented by
tf.distribute.experimental.coordinator.RemoteValue s.
Args:
fn: The function to be dispatched to all workers for execution
asynchronously.
args: Positional arguments for fn .
kwargs: Keyword arguments for fn .
Returns:
A tf.distribute.experimental.coordinator.PerWorkerValues object, which
wraps a tuple of tf.distribute.experimental.coordinator.RemoteValue
objects.
"""
results = []
for w in self._cluster.workers:
results.append(w.create_resource(fn, args=args, kwargs=kwargs))
return PerWorkerValues(tuple(results))
PerWorkerValues 是一个容纳 value 列表的容器,每个工作者对应一个 value。Tf.distribution.experimental.coordinator.PerWorkerValues 包含一个值的集合,其中每个值都位于其相应的工作者上,当被用作 tf.distribution.experimental.coordinator.ClusterCoordinator.schedule() 的 args 或 kwargs 时,某一个工作者的特定值将被传递到该工作者上执行的函数中。
创建 tf.distribution.experimental.coordinator.PerWorkerValues 对象的唯一路径是通过在 ClusterCoordinator.create_per_worker_dataset 返回的分布式数据集实例上调用 iter 。目前还不支持创建自定义 tf.distribution.experimental.coordinator.PerWorkerValues 的机制。
@tf_export("distribute.experimental.coordinator.PerWorkerValues", v1=[])
class PerWorkerValues(composite_tensor.CompositeTensor):
"""A container that holds a list of values, one value per worker.
tf.distribute.experimental.coordinator.PerWorkerValues contains a collection
of values, where each of the values is located on its corresponding worker,
and upon being used as one of the args or kwargs of
tf.distribute.experimental.coordinator.ClusterCoordinator.schedule() , the
value specific to a worker will be passed into the function being executed at
that corresponding worker.
Currently, the only supported path to create an object of
tf.distribute.experimental.coordinator.PerWorkerValues is through calling
iter on a ClusterCoordinator.create_per_worker_dataset -returned
distributed dataset instance. The mechanism to create a custom
tf.distribute.experimental.coordinator.PerWorkerValues is not yet supported.
"""
def __init__(self, values):
for v in values:
if not isinstance(v, RemoteValue):
raise AssertionError(
" PerWorkerValues should only take RemoteValue s.")
self._values = tuple(values)
@property
def _type_spec(self):
return PerWorkerValuesTypeSpec(
self._values[0]._type_spec,
type(self))
获取数据的逻辑如下:
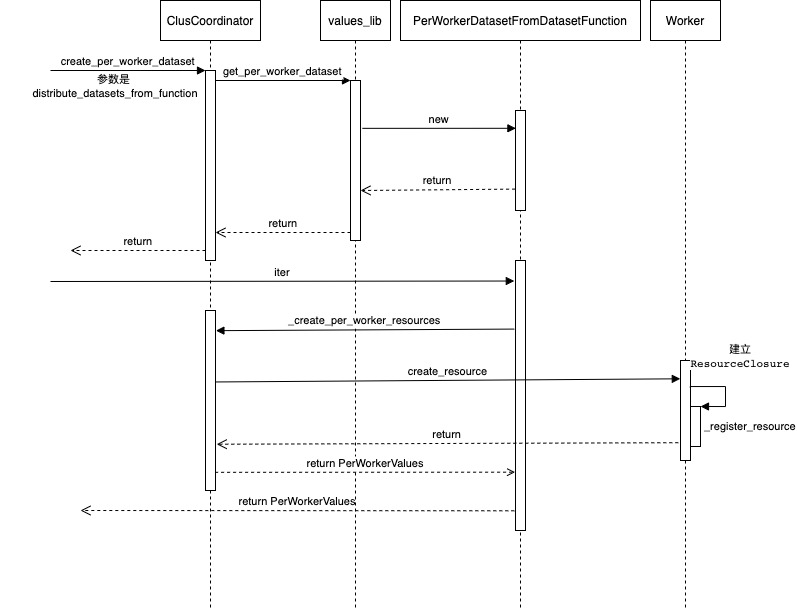
Cluster 才是业务执行者。
4.1 定义Cluster 是一个工作者集群。在初始化方法之中,会做如下处理:
- 设置如何忽略参数服务器暂时错误。
- 设定工作者的设备名字。
- 生成一系列工作者。
这里要注意的是如何忽略因为工作者瞬时连接错误而报告的故障。
- 工作者和参数服务器之间的瞬时连接问题会由工作者转达给协调者,这将导致协调者认为存在参数服务器故障。
- 瞬时与永久的参数服务器故障之间的区别是工作者报告的数量。当这个环境变量设置为正整数 K 时,协调器忽略最多 K 个失败报告,也就是说,只有超过 K 个执行错误,并且这些错误是因为同一个参数服务器实例导致的,我们才认为参数服务器实例遇到了失败。
class Cluster(object):
"""A cluster with workers.
We assume all function errors are fatal and based on this assumption our
error reporting logic is:
1) Both schedule and join can raise a non-retryable error which is the
first error seen by the coordinator from any previously scheduled functions.
2) When an error is raised, there is no guarantee on how many previously
scheduled functions have been executed; functions that have not been executed
will be thrown away and marked as cancelled.
3) After an error is raised, the internal state of error will be cleared.
I.e. functions can continue to be scheduled and subsequent calls of schedule
or join will not raise the same error again.
Attributes:
failure_handler: The failure handler used to handler worker preemption
failure.
workers: a list of Worker objects in the cluster.
"""
def __init__(self, strategy):
"""Initializes the cluster instance."""
self._num_workers = strategy._num_workers
self._num_ps = strategy._num_ps
# 如何忽略参数服务器暂时错误
self._transient_ps_failures_threshold = int(
os.environ.get("TF_COORDINATOR_IGNORE_TRANSIENT_PS_FAILURES", 3))
self._potential_ps_failures_lock = threading.Lock()
self._potential_ps_failures_count = [0] * self._num_ps
self._closure_queue = _CoordinatedClosureQueue()
self.failure_handler = WorkerPreemptionHandler(context.get_server_def(),
self)
# 设定 worker 的设备名字
worker_device_strings = [
"/job:worker/replica:0/task:%d" % i for i in range(self._num_workers)
]
# 生成 Workers
self.workers = [
Worker(i, w, self) for i, w in enumerate(worker_device_strings)
]
这个类提供的最重要的API是 "schedule"/"join" 这对函数。"schedule" API是非阻塞的,它把一个 "tf.function "插入队列,并立即返回一个 "RemoteValue"。
def schedule(self, function, args, kwargs):
"""Schedules function to be dispatched to a worker for execution.
Args:
function: The function to be dispatched to a worker for execution
asynchronously.
args: Positional arguments for fn .
kwargs: Keyword arguments for fn .
Returns:
A RemoteValue object.
"""
closure = Closure(
function,
self._closure_queue._cancellation_mgr,
args=args,
kwargs=kwargs)
self._closure_queue.put(closure)
return closure.output_remote_value
def join(self):
"""Blocks until all scheduled functions are executed."""
self._closure_queue.wait()
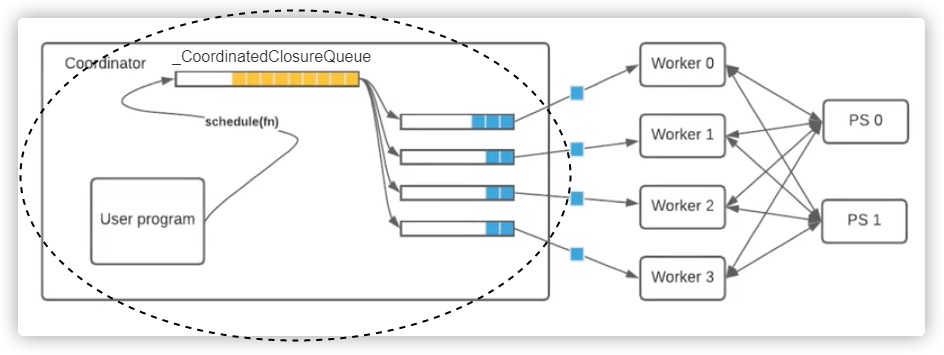
具体逻辑如下,虚线表示数据集被传入,这里的 Queue 是 from six.moves import queue 引入的 queue.Queue,我们接下来在_CoordinatedClosureQueue之中会见到。

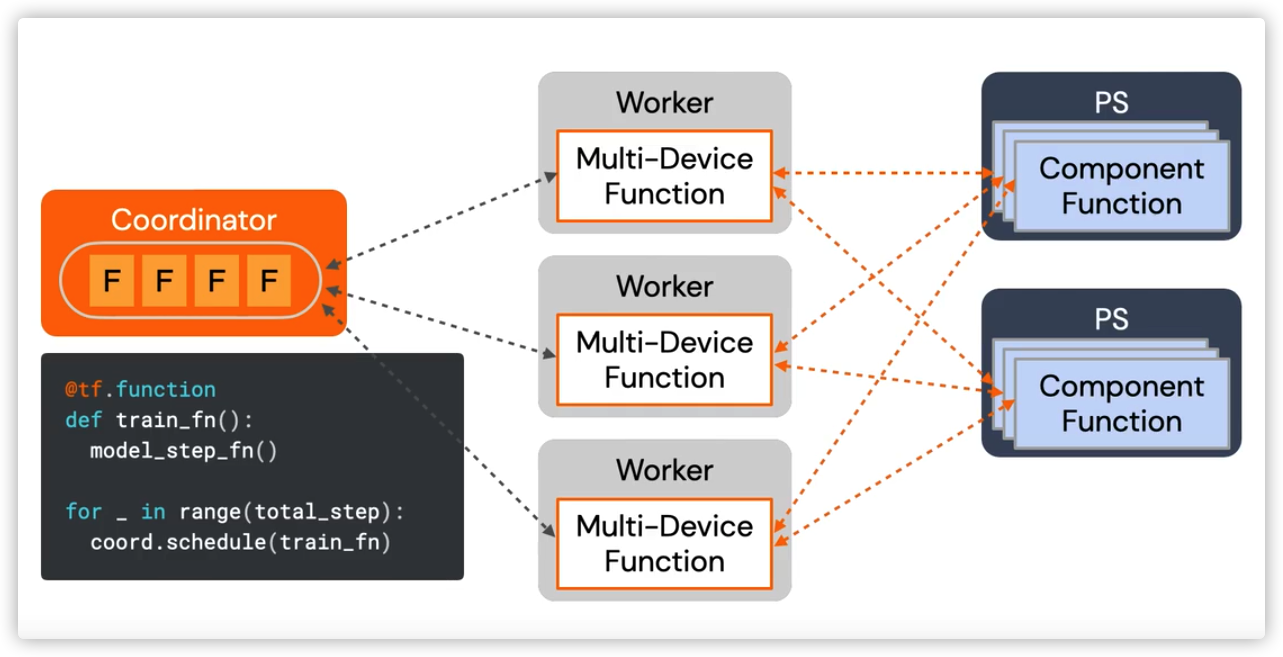
或者我们从官方文档图来看,目前完成的是左边圆圈部分。
停止代码如下,具体是调用队列的处理方法。
def stop(self):
"""Stop worker, worker preemption threads, and the closure queue."""
self.failure_handler.stop()
for worker in self.workers:
worker.stop()
self._closure_queue.stop()
def done(self):
"""Returns true if all scheduled functions are executed."""
return self._closure_queue.done()
Closure 的作用是把任务封装起来,并且提供了其他功能。
class Closure(object):
"""Hold a function to be scheduled and its arguments."""
def __init__(self, function, cancellation_mgr, args=None, kwargs=None):
if not callable(function):
raise ValueError("Function passed to ClusterCoordinator.schedule must "
"be a callable object.")
self._args = args or ()
self._kwargs = kwargs or {}
_disallow_remote_value_as_input(self._args)
_disallow_remote_value_as_input(self._kwargs)
if isinstance(function, def_function.Function):
replica_args = _select_worker_slice(0, self._args)
replica_kwargs = _select_worker_slice(0, self._kwargs)
# Note: no need to handle function registration failure since this kind of
# failure will not raise exceptions as designed in the runtime. The
# coordinator has to rely on subsequent operations that raise to catch
# function registration failure.
# Record the function tracing overhead. Note that we pass in the tracing
# count of the def_function.Function as a state tracker, so that metrics
# will only record the time for actual function tracing (i.e., excluding
# function cache lookups).
with metric_utils.monitored_timer(
"function_tracing", state_tracker=function._get_tracing_count):
self._concrete_function = function.get_concrete_function(
*nest.map_structure(_maybe_as_type_spec, replica_args),
**nest.map_structure(_maybe_as_type_spec, replica_kwargs))
elif isinstance(function, tf_function.ConcreteFunction):
self._concrete_function = function
if hasattr(self, "_concrete_function"):
# If we have a concrete function, we get to retrieve the output type spec
# via the structured_output.
output_type_spec = func_graph.convert_structure_to_signature(
self._concrete_function.structured_outputs)
self._function = cancellation_mgr.get_cancelable_function(
self._concrete_function)
else:
# Otherwise (i.e. what is passed in is a regular python function), we have
# no such information.
output_type_spec = None
self._function = function
self.output_remote_value = RemoteValueImpl(self, output_type_spec)
Closure 的 execute_on 负责运行,具体是在指定的设备上执行 self._function,就是用户自定义的 function。需要注意的是,with context.executor_scope(worker.executor) 使用了 context。
def execute_on(self, worker):
"""Executes the closure on the given worker.
Args:
worker: a Worker object.
"""
replica_args = _select_worker_slice(worker.worker_index, self._args)
replica_kwargs = _select_worker_slice(worker.worker_index, self._kwargs)
e = (
_maybe_rebuild_remote_values(worker, replica_args) or
_maybe_rebuild_remote_values(worker, replica_kwargs))
if e:
if not isinstance(e, InputError):
e = InputError(e)
self.output_remote_value._set_error(e)
return
with ops.device(worker.device_name): # 在指定设备上
with context.executor_scope(worker.executor): # 通过上下文
with metric_utils.monitored_timer("closure_execution"):
output_values = self._function( # 运行用户的参数
*nest.map_structure(_maybe_get_remote_value, replica_args),
**nest.map_structure(_maybe_get_remote_value, replica_kwargs))
self.output_remote_value._set_values(output_values)
Self._function 是用户自定义的 function,我们再给出一个方法示例,可以看出来可以使用 strategy.run 把训练方法分发到远端工作者进行训练。
@tf.function
def worker_fn(iterator):
def replica_fn(inputs):
batch_data, labels = inputs
# calculate gradient, applying gradient, metrics update etc.
strategy.run(replica_fn, args=(next(iterator),))
用户可以设置取消 Closure,就是在返回值之中做下设置。
def mark_cancelled(self):
self.output_remote_value._set_error(
errors.CancelledError(
None, None, "The corresponding function is "
"cancelled. Please reschedule the function."))
ResourceClosure 是派生类,把 Closure 用 RemoteValue 包装起来。实际上使用的都是 ResourceClosure。
class ResourceClosure(Closure):
def build_output_remote_value(self):
if self._output_remote_value_ref is None:
# We need to remember the Closure object in the RemoteValue here.
ret = RemoteValueImpl(self, self._output_type_spec)
self._output_remote_value_ref = weakref.ref(ret)
return ret
else:
return self._output_remote_value_ref()
_CoordinatedClosureQueue 是任务所在的队列。
6.1 定义from six.moves import queue
class _CoordinatedClosureQueue(object):
"""Manage a queue of closures, inflight count and errors from execution.
This class is thread-safe.
"""
def __init__(self):
# self._inflight_closure_count only tracks the number of inflight closures
# that are "in generation". Once an error occurs, error generation is
# incremented and all subsequent arriving closures (from inflight) are
# considered "out of generation".
self._inflight_closure_count = 0
self._queue_lock = threading.Lock()
# Condition indicating that all pending closures (either queued or inflight)
# have been processed, failed, or cancelled.
self._stop_waiting_condition = threading.Condition(self._queue_lock)
# Condition indicating that an item becomes available in queue (not empty).
self._closures_queued_condition = threading.Condition(self._queue_lock)
self._should_process_closures = True
# Condition indicating that a queue slot becomes available (not full).
# Note that even with "infinite" queue size, there is still a "practical"
# size limit for the queue depending on host memory capacity, and thus the
# queue will eventually become full with a lot of enqueued closures.
self._queue_free_slot_condition = threading.Condition(self._queue_lock)
# Condition indicating there is no inflight closures.
self._no_inflight_closure_condition = threading.Condition(self._queue_lock)
# Use to cancel in-flight closures.
self._cancellation_mgr = cancellation.CancellationManager()
self._queue = queue.Queue(maxsize=_CLOSURE_QUEUE_MAX_SIZE)
self._error = None
# The following is a lock to make sure when wait is called and before it
# returns no put can be executed during this period. It is because wait
# won't know what to do with newly put closures. This lock adds an cutoff
# for wait so that closures put into the queue while waiting would not be
# taken responsible by this wait .
#
# We cannot reuse the self._queue_lock since when wait waits for a
# condition, the self._queue_lock will be released.
#
# We don't use a reader/writer's lock on purpose to reduce the complexity
# of the code.
self._put_wait_lock = threading.Lock()
Put 和 get 方法分别负责插入和取出。
def put(self, closure):
"""Put a closure into the queue for later execution.
If mark_failed was called before put , the error from the first
invocation of mark_failed will be raised.
Args:
closure: The Closure to put into the queue.
"""
with self._put_wait_lock, self._queue_lock:
self._queue_free_slot_condition.wait_for(lambda: not self._queue.full())
self._queue.put(closure, block=False)
self._raise_if_error()
self._closures_queued_condition.notify()
def get(self, timeout=None):
"""Return a closure from the queue to be executed."""
with self._queue_lock:
while self._queue.empty() and self._should_process_closures:
if not self._closures_queued_condition.wait(timeout=timeout):
return None
if not self._should_process_closures:
return None
closure = self._queue.get(block=False)
self._queue_free_slot_condition.notify()
self._inflight_closure_count += 1
return closure
Put_back 则负责把 closure 重新放回queue。
def put_back(self, closure):
"""Put the closure back into the queue as it was not properly executed."""
with self._queue_lock:
if self._inflight_closure_count < 1:
raise AssertionError("There is no inflight closures to put_back.")
if self._error:
closure.mark_cancelled()
else:
self._queue_free_slot_condition.wait_for(lambda: not self._queue.full())
self._queue.put(closure, block=False)
self._closures_queued_condition.notify()
self._inflight_closure_count -= 1
if self._inflight_closure_count == 0:
self._no_inflight_closure_condition.notifyAll()
方法 wait 会等待所有 closures 结束。
def wait(self, timeout=None):
"""Wait for all closures to be finished before returning.
If mark_failed was called before or during wait , the error from the
first invocation of mark_failed will be raised.
Args:
timeout: A float specifying a timeout for the wait in seconds.
Returns:
True unless the given timeout expired, in which case it returns False.
"""
with self._put_wait_lock, self._queue_lock:
while (not self._error and
(not self._queue.empty() or self._inflight_closure_count > 0)):
if not self._stop_waiting_condition.wait(timeout=timeout):
return False
self._raise_if_error()
return True
Mark_failed 和 done 则是处理结束和异常的一套组合。
def mark_failed(self, e):
"""Sets error and unblocks any wait() call."""
with self._queue_lock:
# TODO(yuefengz): maybe record all failure and give users more
# information?
if self._inflight_closure_count < 1:
raise AssertionError("There is no inflight closures to mark_failed.")
if self._error is None:
self._error = e
self._inflight_closure_count -= 1
if self._inflight_closure_count == 0:
self._no_inflight_closure_condition.notifyAll()
self._stop_waiting_condition.notifyAll()
def done(self):
"""Returns true if the queue is empty and there is no inflight closure.
If mark_failed was called before done , the error from the first
invocation of mark_failed will be raised.
"""
with self._queue_lock:
self._raise_if_error()
return self._queue.empty() and self._inflight_closure_count == 0
Stop 和 _cancel_all_closures 负责暂停 closures。
def stop(self):
with self._queue_lock:
self._should_process_closures = False
self._closures_queued_condition.notifyAll()
def _cancel_all_closures(self):
"""Clears the queue and sets remaining closures cancelled error.
This method expects self._queue_lock to be held prior to entry.
"""
self._cancellation_mgr.start_cancel()
while self._inflight_closure_count > 0:
self._no_inflight_closure_condition.wait()
while True:
try:
closure = self._queue.get(block=False)
self._queue_free_slot_condition.notify()
closure.mark_cancelled()
except queue.Empty:
break
# The cancellation manager cannot be reused once cancelled. After all
# closures (queued or inflight) are cleaned up, recreate the cancellation
# manager with clean state.
# Note on thread-safety: this is triggered when one of theses
# ClusterCoordinator APIs are called: schedule , wait , and done . At the
# same time, no new closures can be constructed (which reads the
# _cancellation_mgr to get cancellable functions).
self._cancellation_mgr = cancellation.CancellationManager()
def _raise_if_error(self):
"""Raises the error if one exists.
If an error exists, cancel the closures in queue, raises it, and clear
the error.
This method expects self._queue_lock to be held prior to entry.
"""
if self._error:
logging.error("Start cancelling closures due to error %r: %s",
self._error, self._error)
self._cancel_all_closures()
try:
raise self._error
finally:
self._error = None
Worker 是函数的执行者。
7.1 定义Worker 的定义如下,其启动了一个线程来运行 _process_queue。
class Worker(object):
"""A worker in a cluster.
Attributes:
worker_index: The index of the worker in the cluster.
device_name: The device string of the worker, e.g. "/job:worker/task:1".
executor: The worker's executor for remote function execution.
failure_handler: The failure handler used to handler worker preemption
failure.
"""
def __init__(self, worker_index, device_name, cluster):
self.worker_index = worker_index
self.device_name = device_name
# 这里会有一个executor
self.executor = executor.new_executor(enable_async=False)
self.failure_handler = cluster.failure_handler
self._cluster = cluster
self._resource_remote_value_refs = []
self._should_worker_thread_run = True
# Worker threads need to start after Worker 's initialization.
threading.Thread(target=self._process_queue,
name="WorkerClosureProcessingLoop-%d" % self.worker_index,
daemon=True).start()
New_executor 会调用 TFE_NewExecutor。
def new_executor(enable_async):
handle = pywrap_tfe.TFE_NewExecutor(enable_async)
return Executor(handle)
TFE_NewExecutor 定义在 tensorflow/c/eager/c_api_experimental.cc,其生成了 TFE_Executor。
TFE_Executor* TFE_NewExecutor(bool is_async) {
return new TFE_Executor(is_async);
}
TFE_Executor 定义如下,Executor类是会话执行器的抽象,在 TF2 之中,也有 EagerExecutor。
struct TFE_Executor {
explicit TFE_Executor(bool async)
: owned_executor(new tensorflow::EagerExecutor(async)) {}
explicit TFE_Executor(tensorflow::EagerExecutor* executor)
: owned_executor(nullptr), unowned_executor(executor) {}
tensorflow::EagerExecutor* executor() {
return owned_executor == nullptr ? unowned_executor : owned_executor.get();
}
std::unique_ptr<tensorflow::EagerExecutor> owned_executor;
tensorflow::EagerExecutor* unowned_executor;
};
_process_queue 方法会从 queue 之中取出 Closure,然后运行任务。
def _process_queue(self):
"""Function running in a worker thread to process closure queues."""
self._maybe_delay()
while self._should_worker_thread_run:
closure = self._cluster._closure_queue.get()
if not self._should_worker_thread_run or closure is None:
return
self._process_closure(closure)
# To properly stop the worker and preemption threads, it is important that
# ClusterCoordinator object is not held onto so its __del__ can be
# called. By removing the reference to the closure that has already been
# processed, we ensure that the closure object is released, while
# getting the next closure at above self._cluster._closure_queue.get()
# call.
del closure
_process_queue 之中首先会调用 _maybe_delay 等待环境变量配置。
def _maybe_delay(self):
"""Delay if corresponding env vars are set."""
# If the following two env vars variables are set. Scheduling for workers
# will start in a staggered manner. Worker i will wait for
# TF_COORDINATOR_SCHEDULE_START_DELAY * i seconds, not exceeding
# TF_COORDINATOR_SCHEDULE_START_DELAY_MAX .
delay_secs = int(os.environ.get("TF_COORDINATOR_SCHEDULE_START_DELAY", "0"))
delay_cap = int(
os.environ.get("TF_COORDINATOR_SCHEDULE_START_DELAY_MAX", "0"))
if delay_cap:
delay_secs = min(delay_secs * self.worker_index, delay_cap)
if delay_secs > 0:
logging.info("Worker %d sleeping for %d seconds before running function",
self.worker_index, delay_secs)
time.sleep(delay_secs)
_process_queue 之中接着会调用 _process_closure 来运行 closure。
def _process_closure(self, closure):
"""Runs a closure with preemption handling."""
try:
with self._cluster.failure_handler.wait_on_failure(
on_failure_fn=lambda: self._cluster._closure_queue.put_back(closure),
on_recovery_fn=self._set_resources_aborted,
worker_device_name=self.device_name):
closure.execute_on(self)
with metric_utils.monitored_timer("remote_value_fetch"):
# Copy the remote tensor to local (the coordinator) in case worker
# becomes unavailable at a later time.
closure.output_remote_value.get()
self._cluster._closure_queue.mark_finished()
except Exception as e:
# Avoid logging the derived cancellation error
if not isinstance(e, errors.CancelledError):
logging.error(
"/job:worker/task:%d encountered the following error when "
"processing closure: %r:%s", self.worker_index, e, e)
closure.output_remote_value._set_error(e)
self._cluster._closure_queue.mark_failed(e)
我们接下来看看如何把数据读取放到工作者上运行。前面提到了,在 _create_per_worker_resources 会调用 create_resource,为每一个工作者建立其自己的资源。
def create_resource(self, function, args=None, kwargs=None):
"""Synchronously creates a per-worker resource represented by a RemoteValue .
Args:
function: the resource function to be run remotely. It should be a
tf.function , a concrete function or a Python function.
args: positional arguments to be passed to the function.
kwargs: keyword arguments to be passed to the function.
Returns:
one or several RemoteValue objects depending on the function return
values.
"""
# Some notes about the concurrency: currently all the activities related to
# the same worker such as creating resources, setting resources' aborted
# status, and executing closures happen on the same thread. This allows us
# to have simpler logic of concurrency.
closure = ResourceClosure(
function,
self._cluster.closure_queue._cancellation_mgr,
args=args,
kwargs=kwargs)
resource_remote_value = closure.build_output_remote_value()
self._register_resource(resource_remote_value)
# The following is a short-term solution to lazily create resources in
# parallel.
resource_remote_value._set_aborted()
return resource_remote_value
_register_resource 则会把每个 Worker 的资源注册到 Worker 之上。
def _register_resource(self, resource_remote_value):
if not isinstance(resource_remote_value, RemoteValue):
raise ValueError("Resource being registered is not of type "
" tf.distribute.experimental.coordinator.RemoteValue .")
self._resource_remote_value_refs.append(weakref.ref(resource_remote_value))
逻辑如下,虚线表述数据流。用户通过 put 方法向队列之中放入 Closure,Worker 通过 put 方法从队列获取 Closure 执行。

Stop 等一系列方法负责停止。
def stop(self):
"""Ensure the worker thread is closed."""
self._should_worker_thread_run = False
def _set_resources_aborted(self):
for weakref_resource in self._resource_remote_value_refs:
resource = weakref_resource()
if resource:
resource._set_aborted() # pylint: disable=protected-access
def _set_dead(self):
raise NotImplementedError("_set_dead is not implemented.")
至此,我们其实还没有正式和 Strategy 联系起来,我们再用一个例子来看看,这里会发现,传递给 coordinator 的方法之中,会调用 strategy.run(replica_fn, args=(next(iterator),)),这样就和 strategy 联系起来了。
strategy = ...
coordinator = tf.distribute.experimental.coordinator.ClusterCoordinator(
strategy)
def dataset_fn():
return tf.data.Dataset.from_tensor_slices([1, 1, 1])
with strategy.scope():
v = tf.Variable(initial_value=0)
@tf.function
def worker_fn(iterator):
def replica_fn(x):
v.assign_add(x)
return v.read_value()
return strategy.run(replica_fn, args=(next(iterator),)) # 这里正式联系起来
distributed_dataset = coordinator.create_per_worker_dataset(dataset_fn)
distributed_iterator = iter(distributed_dataset)
result = coordinator.schedule(worker_fn, args=(distributed_iterator,))
assert coordinator.fetch(result) == 1
应对失败的总体策略大致如下:
-
当发现一个工作者失败了,Coordinator 把 function 再次放入队列,然后发给另一个工作者执行,同时启动一个后台线程等待恢复,如果恢复了,则用资源来重建这个工作者,继续分配工作。
-
因此,一些工作者的失败并不妨碍集群继续工作,这使得集群之中的实例可以偶尔不可用(例如,可抢占或spot 实例)。但是协调者和参数服务器必须始终可用,这样集群才能取得进展。
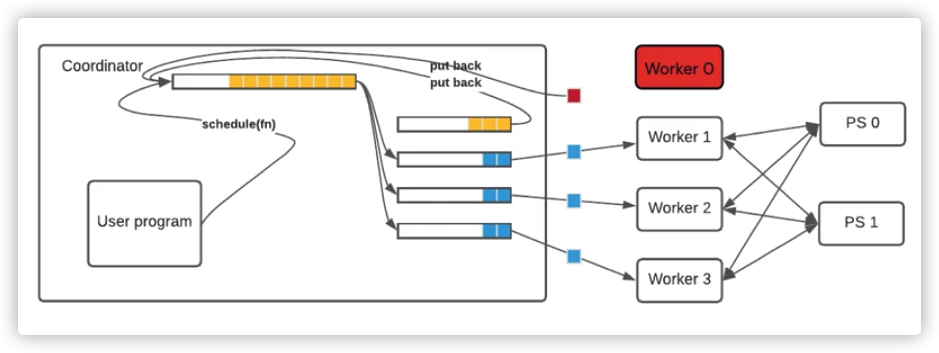
当发生工作者失败(failure)时候,具体逻辑如下:
- ClusterCoordinator 类与 tf.distribution.experimental.ParameterServerStrategy 一起使用时,具有内置的工作者故障容错功能。也就是说,当一些工作者由于任何原因,协调器无法联系上它们,这些工作者的训练进度将继续由其余工作者完成。
- 在工作者恢复时,之前提供的数据集函数(对于自定义训练循环,可以是 ClusterCoordinator.create_per_worker_dataset,或者是 tf.keras.utils.experimental.DatasetCreator 用于 Model.fit )将被调用到工作者身上,以重新创建数据集。
- 当一个失败的工作者恢复之后,在使用通过 create_per_worker_dataset 创建的数据被重新建立后,它将被添加到函数执行中。
当参数服务器失败时,schedule,join 或 done 会引发 tf.errors.UnavailableError。在这种情况下,除了重置失败的参数服务器外,用户还应该重新启动协调器,使其重新连接到工作者和参数服务器,重新创建变量,并加载检查点。如果协调器发生故障,在用户把它重置回来之后,程序会自动连接到工作者和参数服务器,并从检查点继续前进。因为协调器本身也可能变得不可用。因此建议使用某些工具以便不丢失训练进度:
- 因此,在用户的程序中,必须定期保存检查点文件,并在程序开始时恢复。如果 "tf.keras.optimizers.Optimizer" 被应用 checkpoint,在从检查点恢复后,其 "iterations" 属性会大致显示已经进行的步骤数。这可以用来决定在训练完成前还需要多少个 epochs 和步骤(steps)。
- 对于 Model.fit,你应该使用 BackupAndRestore 回调,它可以自动处理进度的保存和恢复。
- 对于一个自定义的训练循环,你应该定期检查模型变量,并在训练开始前从检查点(如果有的话)加载模型变量。如果优化器有检查点,训练进度可以从 optimizer.iterations 中大致推断出来。
checkpoint_manager = tf.train.CheckpointManager(
tf.train.Checkpoint(model=model, optimizer=optimizer),
checkpoint_dir,
max_to_keep=3)
if checkpoint_manager.latest_checkpoint:
checkpoint = checkpoint_manager.checkpoint
checkpoint.restore(
checkpoint_manager.latest_checkpoint).assert_existing_objects_matched()
global_steps = int(optimizer.iterations.numpy())
starting_epoch = global_steps // steps_per_epoch
for _ in range(starting_epoch, num_epoches):
for _ in range(steps_per_epoch):
coordinator.schedule(step_fn, args=(per_worker_iterator,))
coordinator.join()
checkpoint_manager.save()
如果一个函数被成功执行,就可以成功获取到 RemoteValue。这是因为目前在执行完一个函数后,返回值会立即被复制到协调器。如果在复制过程中出现任何工作者故障,该函数将在另一个可用的工作者上重试。因此,如果你想优化性能,你可以安排(schedule)一个没有返回值的函数。
8.5 错误报告一旦协调器发现一个错误,如来自参数服务器的 UnavailableError 或其他应用错误,如来自 tf.debugging.check_numerics 的 InvalidArgument,它将在引发错误之前取消所有 pending 和排队(queued)的函数。获取它们相应的 RemoteValue 将引发一个 CancelledError 。
在引发错误后,协调器将不会引发相同的错误或任何引发一个来自已取消函数的错误。
ClusterCoordinator 假设所有的函数错误都是致命的,基于这个假设,其的错误报告逻辑是:
- Schedule 和 join 都可以引发一个不可重试的错误,这是协调者从任何先前安排的函数中看到的第一个错误。
- 当一个错误被抛出时,不保证有多少先前安排的功能被执行;没有被执行的功能将被丢弃并被标记为取消。
- 在一个错误被抛出后,错误的内部状态将被清除。
WorkerPreemptionHandler 是处理失败的主要模块,其定义如下:
class WorkerPreemptionHandler(object):
"""Handles worker preemptions."""
def __init__(self, server_def, cluster):
self._server_def = server_def
self._cluster = cluster
self._cluster_update_lock = threading.Lock()
self._cluster_due_for_update_or_finish = threading.Event()
self._worker_up_cond = threading.Condition(self._cluster_update_lock)
self._error_from_recovery = None
self._should_preemption_thread_run = True
self._preemption_handler_thread = threading.Thread(
target=self._preemption_handler,
name="WorkerPreemptionHandler",
daemon=True)
self._preemption_handler_thread.start()
在 Cluster 生成时,会把 WorkerPreemptionHandler 配置进来。
self.failure_handler = WorkerPreemptionHandler(context.get_server_def(), self)
在处理 closure 时,会用 wait_on_failure 包裹一层用来处理错误。
def _process_closure(self, closure):
"""Runs a closure with preemption handling."""
assert closure is not None
try:
with self._cluster.failure_handler.wait_on_failure(
on_failure_fn=lambda: self._cluster._closure_queue.put_back(closure),
on_recovery_fn=self._set_resources_aborted,
worker_device_name=self.device_name):
closure.execute_on(self)
WorkerPreemptionHandler 的 wait_on_failure 方法如下:
@contextlib.contextmanager
def wait_on_failure(self,
on_failure_fn=None,
on_transient_failure_fn=None,
on_recovery_fn=None,
worker_device_name="(unknown)"):
"""Catches worker preemption error and wait until failed workers are back.
Args:
on_failure_fn: an optional function to run if preemption happens.
on_transient_failure_fn: an optional function to run if transient failure
happens.
on_recovery_fn: an optional function to run when a worker is recovered
from preemption.
worker_device_name: the device name of the worker instance that is passing
through the failure.
Yields:
None.
"""
try:
yield
except (errors.OpError, InputError) as e:
# If the error is due to temporary connectivity issues between worker and
# ps, put back closure, ignore error and do not mark worker as failure.
if self._cluster._record_and_ignore_transient_ps_failure(e):
if on_transient_failure_fn:
on_transient_failure_fn()
return
# Ignoring derived CancelledErrors to tolerate transient failures in
# PS-worker communication, which initially exposed as an UnavailableError
# and then lead to sub-function cancellation, subsequently getting
# reported from worker to chief as CancelledError.
# We do not mark either worker or PS as failed due to only CancelledError.
# If there are real (non-transient) failures, they must also be reported
# as other errors (UnavailableError most likely) in closure executions.
if isinstance(e, errors.CancelledError) and "/job:" in str(e):
if on_transient_failure_fn:
on_transient_failure_fn()
return
# This reraises the error, if it's not considered recoverable; otherwise,
# the following failure recovery logic run. At this time, only worker
# unavailability is recoverable. PS unavailability as well as other
# errors in the user function is not recoverable.
self._validate_preemption_failure(e)
if on_failure_fn:
on_failure_fn()
with self._cluster_update_lock:
self._cluster_due_for_update_or_finish.set()
self._worker_up_cond.wait(_WORKER_MAXIMUM_RECOVERY_SEC)
if self._error_from_recovery:
try:
raise self._error_from_recovery
finally:
self._error_from_recovery = None
if on_recovery_fn:
with self.wait_on_failure(
on_recovery_fn=on_recovery_fn,
on_transient_failure_fn=on_transient_failure_fn,
worker_device_name=worker_device_name):
on_recovery_fn()
_validate_preemption_failure 定义如下:
def _validate_preemption_failure(self, e):
"""Validates that the given exception represents worker preemption."""
# Only categorize the failure as a worker preemption if the cancellation
# manager did not attempt to cancel the blocking operations.
if _is_worker_failure(e) and (
not self._cluster._closure_queue._cancellation_mgr.is_cancelled):
return
raise e
WorkerPreemptionHandler 有一个后台线程 _preemption_handler_thread。
self._preemption_handler_thread = threading.Thread(
target=self._preemption_handler,
name="WorkerPreemptionHandler",
daemon=True)
self._preemption_handler_thread.start()
_preemption_handler 会进行必要的错误处理。
def _preemption_handler(self):
"""A loop that handles preemption.
This loop waits for signal of worker preemption and upon worker preemption,
it waits until all workers are back and updates the cluster about the
restarted workers.
"""
assert self._should_preemption_thread_run
while True:
self._cluster_due_for_update_or_finish.wait()
if not self._should_preemption_thread_run:
break
with self._cluster_update_lock:
try:
context.context().update_server_def(self._server_def)
# Cluster updated successfully, clear the update signal, and notify
# all workers that they are recovered from failure.
self._worker_up_cond.notify_all()
# The check for _should_preemption_thread_run is necessary since the
# stop may have already set _cluster_due_for_update_or_finish.
if self._should_preemption_thread_run:
self._cluster_due_for_update_or_finish.clear()
except Exception as e:
try:
self._validate_preemption_failure(e)
except Exception as ps_e:
# In this case, a parameter server fails. So we raise this error to
# the caller of wait_on_failure .
self._error_from_recovery = ps_e
self._worker_up_cond.notify_all()
if self._should_preemption_thread_run:
self._cluster_due_for_update_or_finish.clear()
# NOTE: Since the first RPC (GetStatus) of update_server_def is
# currently blocking by default, error should only happen if:
# (1) More workers failed while waiting for the previous workers to
# come back;
# (2) Worker failed when exchanging subsequent RPCs after the first
# RPC returns.
# Consider adding backoff retry logic if we see the error logged
# too frequently.
依据前面的代码,我们总结出来问题点如下:
-
Worker 如何知道使用哪些设备?答案是:在集群建立工作者时候,会给每一个工作者设定一个设备。
-
如何具体执行用户函数?答案是:在工作者运行 Closure 时候,会在指定运行在本工作者设备上,然后运行指定的方法(Self._function)。Self._function 是用户自定义的 function,其中可以使用 strategy.run 把训练方法分发到远端工作者进行训练。
-
如何获取数据?答案是:为每个工作者建立一个 PerWorkerValues,PerWorkerValues 是一个容纳 value 列表的容器,每个工作者从对应 PerWorkerValues 之中获取数据。
tensorflow源码解析之distributed_runtime
TensorFlow分布式训练
- TensorFlow内核剖析
- 源代码
Tensorflow分布式原理理解
TensorFlow架构与设计:概述
Tensorflow 跨设备通信
TensorFlow 篇 | TensorFlow 2.x 分布式训练概览