从其他语言转入Go语言的同学经常会陷入一个思考:如何创建一个单例?
有些同学可能会把其它语言中的双检锁模式移植过来,双检锁模式也称为懒汉模式,首次用到的时候才创建实例。大部分人首次用Golang写出来的实例大概是这样的:
type Conn struct {
Addr string
State int
}
var c *Conn
var mu sync.Mutex
func GetInstance() *Conn {
if c == nil {
mu.Lock()
defer mu.Unlock()
if c == nil {
c = &Conn{"127.0.0.1:8080", 1}
}
}
return c
}
这里先解释下这段代码的执行逻辑(已经清楚的同学可以直接跳过):
GetInstance用于获取结构体Conn的一个实例,其中:先判断c是否为空,如果为空则加锁,加锁之后再判断一次c是否为空,如果还为空,则创建Conn的一个实例,并赋值给c。这里有两次判空,所以称为双检,需要第二次判空的原因是:加锁之前可能有多个线程/协程都判断为空,这些线程/协程都会在这里等着加锁,它们最终也都会执行加锁操作,不过加锁之后的代码在多个线程/协程之间是串行执行的,一个线程/协程判空之后创建了实例,其它线程/协程在判断c是否为空时必然得出false的结果,这样就能保证c仅创建一次。而且后续调用GetInstance时都会仅执行第一次判空,得出false的结果,然后直接返回c。这样每个线程/协程最多只执行一次加锁操作,后续都只是简单的判断下就能返回结果,其性能必然不错。
了解Java的同学可能知道Java中的双检锁是非线程安全的,这是因为赋值操作中的两个步骤可能会出现乱序执行问题。这两个步骤是:对象内存空间的初始化和将内存地址设置给变量。因为编译器或者CPU优化,它们的执行顺序可能不确定,先执行第2步的话,锁外边的线程很有可能访问到没有初始化完毕的变量,从而引发某些异常。针对这个问题,Java以及其它一些语言中可以使用volatile来修饰变量,实际执行时会通过插入内存栅栏阻止指令重排,强制按照编码的指令顺序执行。
那么Go语言中的双检锁是安全的吗?
答案是也不安全。
先来看看指令重排问题:
在Go语言规范中,赋值操作分为两个阶段:第一阶段对赋值操作左右两侧的表达式进行求值,第二阶段赋值按照从左至右的顺序执行。(参考:https://golang.google.cn/ref/spec#Assignments)
说的有点抽象,但没有提到赋值存在指令重排的问题,隐约感觉不会有这个问题。为了验证,让我们看一下上边那段代码中赋值操作的伪汇编代码:
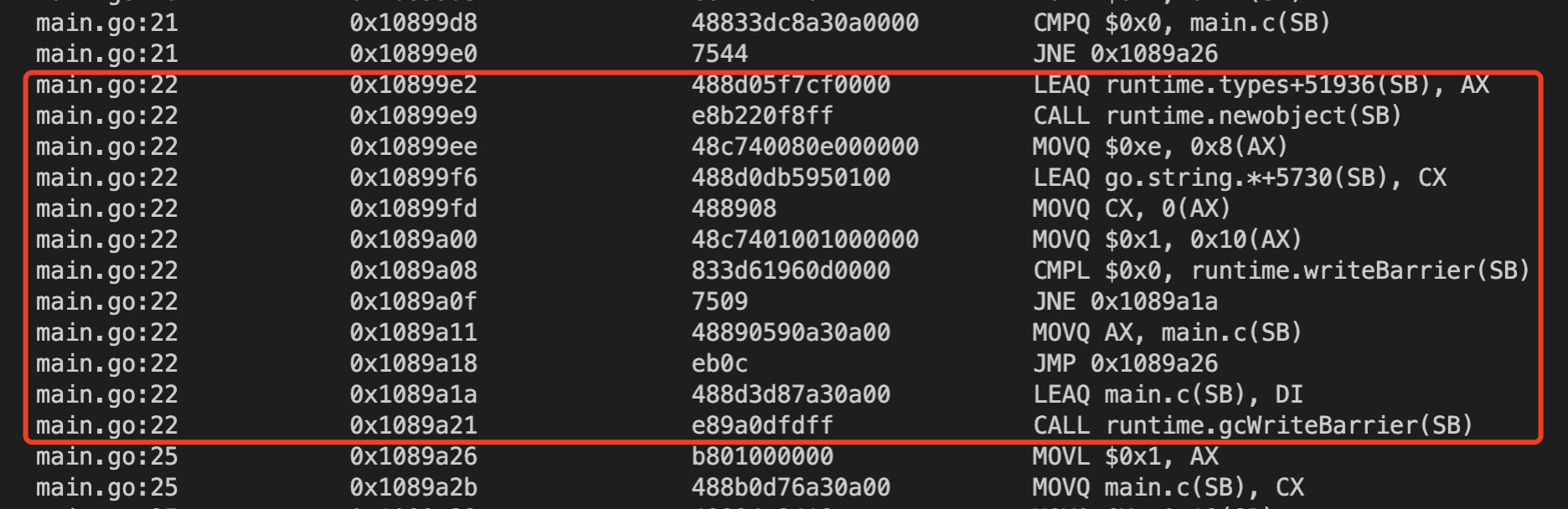
红框圈出来的部分对应的代码是: c = &Conn{"127.0.0.1:8080", 1}
其中有一行:CMPL $0x0, runtime.writeBarrier(SB) ,这个指令就是插入一个内存栅栏。前边是要赋值数据的初始化,后边是赋值操作。如此看,赋值操作不存在指令重排的问题。
既然赋值操作没有指令重排的问题,那这个双检锁怎么还是不安全的呢?
在Golang中,对于大于单个机器字的值,读写它的时候是以一种不确定的顺序多次执行单机器字的操作来完成的。机器字大小就是我们通常说的32位、64位,即CPU完成一次无定点整数运算可以处理的二进制位数,也可以认为是CPU数据通道的大小。比如在32位的机器上读写一个int64类型的值就需要两次操作。(参考:https://golang.google.cn/ref/mem#tmp_2)
因为Golang中对变量的读和写都没有原子性的保证,所以很可能出现这种情况:锁里边变量赋值只处理了一半,锁外边的另一个goroutine就读到了未完全赋值的变量。所以这个双检锁的实现是不安全的。
Golang中将这种问题称为data race,说的是对某个数据产生了并发读写,读到的数据不可预测,可能产生问题,甚至导致程序崩溃。可以在构建或者运行时检查是否会发生这种情况:
$ go test -race mypkg // to test the package
$ go run -race mysrc.go // to run the source file
$ go build -race mycmd // to build the command
$ go install -race mypkg // to install the package
另外上边说单条赋值操作没有重排序的问题,但是重排序问题在Golang中还是存在的,稍不注意就可能写出BUG来。比如下边这段代码:
a=1
b=1
c=a+b
在执行这段程序的goroutine中并不会出现问题,但是另一个goroutine读取到b1时并不代表此时a1,因为a=1和b=1的执行顺序可能会被改变。针对重排序问题,Golang并没有暴露类似volatile的关键字,因为理解和正确使用这类能力进行并发编程的门槛比较高,所以Golang只是在一些自己认为比较适合的地方插入了内存栅栏,尽量保持语言的简单。对于goroutine之间的数据同步,Go提供了更好的方式,那就是Channel,不过这不是本文的重点,这里就不介绍了。
sync.Once的启示还是回到最开始的问题,如何在Golang中创建一个单例?
很多人应该会被推荐使用 sync.Once ,这里看下如何使用:
type Conn struct {
Addr string
State int
}
var c *Conn
var once sync.Once
func setInstance() {
fmt.Println("setup")
c = &Conn{"127.0.0.1:8080", 1}
}
func doPrint() {
once.Do(setInstance)
fmt.Println(c)
}
func loopPrint() {
for i := 0; i < 10; i++ {
go doprint()
}
}
这里重用上文的结构体Conn,设置Conn单例的方法是setInstance,这个方法在doPrint中被once.Do调用,这里的once就是sync.Once的一个实例,然后我们在loopPrint方法中创建10个goroutine来调用doPrint方法。
按照sync.Once的语义,setInstance应该近执行一次。可以实际执行下看看,我这里直接贴出结果:
setup
&{127.0.0.1:8080 1}
&{127.0.0.1:8080 1}
&{127.0.0.1:8080 1}
&{127.0.0.1:8080 1}
&{127.0.0.1:8080 1}
&{127.0.0.1:8080 1}
&{127.0.0.1:8080 1}
&{127.0.0.1:8080 1}
&{127.0.0.1:8080 1}
&{127.0.0.1:8080 1}
无论执行多少遍,都是这个结果。那么sync.Once是怎么做到的呢?源码很短很清楚:
type Once struct {
done uint32
m Mutex
}
func (o *Once) Do(f func()) {
if atomic.LoadUint32(&o.done) == 0 {
o.doSlow(f)
}
}
func (o *Once) doSlow(f func()) {
o.m.Lock()
defer o.m.Unlock()
if o.done == 0 {
defer atomic.StoreUint32(&o.done, 1)
f()
}
}
Once是一个结构体,其中第一个字段标识是否执行过,第二个字段是一个互斥量。Once仅公开了一个Do方法,用于执行目标函数f。
这里重点看下目标函数f是怎么被执行的?
- Do方法中第一行是判断字段done是否为0,为0则代表没执行过,为1则代表执行过。这里用了原子读,写的时候也要原子写,这样可以保证读写不会同时发生,能够读到当前最新的值。
- 如果done为0,则调用doSLow方法,从名字我们就可以体会到这个方法比较慢。
- doSlow中首先会加锁,使用的是Once结构体的第二个字段。
- 然后再判断done是否为0,注意这里没有使用原子读,为什么呢?因为锁中的方法是串行执行的,不会发生并发读写。
- 如果done为0,则调用目标函数f,执行相关的业务逻辑。
- 在执行目标函数f前,这里还声明了一个defer:defer atomic.StoreUint32(&o.done, 1) ,使用原子写改变done的值为1,代表目标函数已经执行过。它会在目标函数f执行完毕,doSlow方法返回之前执行。这个设计很精妙,精确控制了改写done值的时机。
可以看出,这里用的也是双检锁的模式,只不过做了两个增强:一是使用原子读写,避免了并发读写的内存数据不一致问题;二是在defer中更改完成标识,保证了代码执行顺序,不会出现完成标识更改逻辑被编译器或者CPU优化提前执行。
需要注意,如果目标函数f中发生了panic,目标函数也仅执行一次,不会执行多次直到成功。
安全的双检锁有了对sync.Once的理解,我们可以改造之前写的双检锁逻辑,让它也能安全起来。
type Conn struct {
Addr string
State int
}
var c *Conn
var mu sync.Mutex
var done uint32
func getInstance() *Conn {
if atomic.LoadUint32(&done) == 0 {
mu.Lock()
defer mu.Unlock()
if done == 0 {
defer atomic.StoreUint32(&done, 1)
c = &Conn{"127.0.0.1:8080", 1}
}
}
return c
}
改变的地方就是sync.Once做的两个增强;原子读写和defer中更改完成标识。
当然如果要做的工作仅限于此,还不如直接使用sync.Once。
有时候我们需要的单例不是一成不变的,比如在ylog中需要每小时创建一个日志文件的实例,再比如需要为每一个用户创建不同的单例;再比如创建实例的过程中发生了错误,可能我们还会期望再执行实例的创建过程,直到成功。这两个需求是sync.Once无法做到的。
处理panic这里在创建Conn的时候模拟一个panic。
i:=0
func newConn() *Conn {
fmt.Println("newConn")
div := i
i++
k := 10 / div
return &Conn{"127.0.0.1:8080", k}
}
第1次执行newConn时会发生一个除零错误,并引发 panic。再执行时则可以正常创建。
panic可以通过recover进行处理,因此可以在捕捉到panic时不更改完成标识,之前的getInstance方法可以修改为:
func getInstance() *Conn {
if atomic.LoadUint32(&done) == 0 {
mu.Lock()
defer mu.Unlock()
if done == 0 {
defer func() {
if r := recover(); r == nil {
defer atomic.StoreUint32(&done, 1)
}
}()
c = newConn()
}
}
return c
}
可以看到这里只是改了下defer函数,捕捉不到panic时才去更改完成标识。注意此时c并没有创建成功,会返回零值,或许你还需要增加其它的错误处理。
处理error如果业务代码不是抛出panic,而是返回error,这时候怎么处理?
可以将error转为panic,比如newConn是这样实现的:
func newConn() (*Conn, error) {
fmt.Println("newConn")
div := i
i++
if div == 0 {
return nil, errors.New("the divisor is zero")
}
k := 1 / div
return &Conn{"127.0.0.1:8080", k}, nil
}
我们可以再把它包装一层:
func mustNewConn() *Conn {
conn, err := newConn()
if err != nil {
panic(err)
}
return conn
}
如果不使用panic,还可以再引入一个变量,有error时对它赋值,在defer函数中增加对这个变量的判断,如果有错误值,则不更新完成标识位。代码也比较容易实现,不过还要增加变量,感觉复杂了,这里就不测试这种方法了。
有范围的单例前文提到过有时单例不是一成不变的,我这里将这种单例称为有范围的单例。
这里还是复用前文的Conn结构体,不过需求修改为要为每个用户创建一个Conn实例。
看一下User的定义:
type User struct {
done uint32
Id int64
mu sync.Mutex
c *Conn
}
其中包括一个用户Id,其它三个字段还是用于获取当前用户的Conn单例的。
再看看getInstance函数怎么改:
func getInstance(user *User) *Conn {
if atomic.LoadUint32(&user.done) == 0 {
user.mu.Lock()
defer user.mu.Unlock()
if user.done == 0 {
defer func() {
if r := recover(); r == nil {
defer atomic.StoreUint32(&user.done, 1)
}
}()
user.c = newConn()
}
}
return user.c
}
这里增加了一个参数 user,方法内的逻辑基本没变,只不过操作的东西都变成user的字段。这样就可以为每个用户创建一个Conn单例。
这个方法有点泛型的意思了,当然不是泛型。
有范围单例的另一个示例:在ylog中需要每小时创建一个日志文件用于记录当前小时的日志,在每个小时只需创建并打开这个文件一次。
先看看Logger的定义(这里省略和创建单例无关的内容。):
type FileLogger struct {
lastHour int64
file *os.File
mu sync.Mutex
...
}
lastHour是记录的小时数,如果当前小时数不等于记录的小时数,则说明应该创建新的文件,这个变量类似于sync.Once中的done字段。
file是打开的文件实例。
mu是创建文件实例时需要加的锁。
下边看一下打开文件的方法:
func (l *FileLogger) ensureFile() (err error) {
curTime := time.Now()
curHour := getTimeHour(curTime)
if atomic.LoadInt64(&l.lastHour) != curHour {
return l.ensureFileSlow(curTime, curHour)
}
return
}
func (l *FileLogger) ensureFileSlow(curTime time.Time, curHour int64) (err error) {
l.mu.Lock()
defer l.mu.Unlock()
if l.lastHour != curHour {
defer func() {
if r := recover(); r == nil {
atomic.StoreInt64(&l.lastHour, curHour)
}
}()
l.createFile(curTime, curHour)
}
return
}
这里模仿sync.Once中的处理方法,有两点主要的不同:数值比较不再是0和1,而是每个小时都会变化的数字;增加了对panic的处理。如果打开文件失败,则还会再次尝试打开文件。
要查看完整的代码请访问Github:https://github.com/bosima/ylog/tree/1.0
双检锁的性能从原理上分析,双检锁的性能要好过互斥锁,因为互斥锁每次都要加锁;不使用原子操作的双检锁要比使用原子操作的双检锁好一些,毕竟原子操作也是有些成本的。那么实际差距是多少呢?
这里做一个Benchmark Test,还是处理上文的Conn结构体,为了方便测试,定义一个上下文:
type Context struct {
done uint32
c *Conn
mu sync.Mutex
}
编写三个用于测试的方法:
func ensure_unsafe_dcl(context *Context) {
if context.done == 0 {
context.mu.Lock()
defer context.mu.Unlock()
if context.done == 0 {
defer func() { context.done = 1 }()
context.c = newConn()
}
}
}
func ensure_dcl(context *Context) {
if atomic.LoadUint32(&context.done) == 0 {
context.mu.Lock()
defer context.mu.Unlock()
if context.done == 0 {
defer atomic.StoreUint32(&context.done, 1)
context.c = newConn()
}
}
}
func ensure_mutex(context *Context) {
context.mu.Lock()
defer context.mu.Unlock()
if context.done == 0 {
defer func() { context.done = 1 }()
context.c = newConn()
}
}
这三个方法分别对应不安全的双检锁、使用原子操作的安全双检锁和每次都加互斥锁。它们的作用都是确保Conn结构体的实例存在,如果不存在则创建。
使用的测试方法都是下面这种写法,按照计算机逻辑处理器的数量并行运行测试方法:
func BenchmarkInfo_DCL(b *testing.B) {
context := &Context{}
b.ResetTimer()
b.RunParallel(func(pb *testing.PB) {
for pb.Next() {
ensure_dcl(context)
processConn(context.c)
}
})
}
先看一下Benchmark Test的结果:

可以看到使用双检锁相比每次加锁的提升是两个数量级,这是正常的。
而不安全的双检锁和使用原子操作的安全双检锁时间消耗相差无几,为什么呢?
主要原因是这里写只有1次,剩下的全是读。即使使用了原子操作,绝大部分情况下CPU读数据的时候也不用在多个核心之间同步(锁总线、锁缓存等),只需要读缓存就可以了。这也从一个方面证明了双检锁模式的意义。
另外上文提到过Go读写超过一个机器字的变量时是非原子的,那如果读写只有1个机器字呢?在64位机器上读写int64本身就是原子操作,也就是说读写应该都只需1次操作,不管用不用atomic方法。这可以在编译器文档或者CPU手册中验证。(Reference:https://preshing.com/20130618/atomic-vs-non-atomic-operations/)
不过这两个分析不是说我们使用原子操作没有意义,不安全双检锁的执行结果是没有Go语言规范保证的,上边的结果只是在特定编译器、特定平台下的基准测试结果,不同的编译器、CPU,甚至不同版本的Go都不知道会出什么幺蛾子,运行的效果也就无法保证。我们不得不考虑程序的可移植性。
以上就是本文主要内容,如有问题欢迎反馈。完整代码已经上传到Github,欢迎访问:https://github.com/bosima/go-demo/tree/main/double-check-locking
收获更多架构知识,请关注微信公众号 萤火架构。原创内容,转载请注明出处。
