⭐为什么要划分测试集与训练集? 用测试集度量模型对未见过数据的泛化性能 ⭐交叉验证 数据被多次划分,需要训练多个模型 最常用K折交叉验证 k是用户指定的数字,通常取0/5, 5折
⭐为什么要划分测试集与训练集?
- 用测试集度量模型对未见过数据的泛化性能
⭐交叉验证
- 数据被多次划分,需要训练多个模型
- 最常用K折交叉验证
-
k是用户指定的数字,通常取0/5,
-
5折交叉验证:数据划分为5部分,每一部分叫做折。每一折依次轮流作为测试集,其余做训练集
mglearn.plots.plot_cross_validation()
-

利用model_selection中的cross_val_score(模型,训练数据,真实标签)
#在iris数据上,利用logisticregre进行评估
from sklearn.linear_model import LogisticRegression
from sklearn.datasets import load_iris
from sklearn.model_selection import cross_val_score
iris = load_iris()
lrg = LogisticRegression()
scores = cross_val_score(lrg,iris.data,iris.target)
print("cross_validation scores:{}".format(scores))
'''
`cross_validation scores:[0.96666667 1. 0.93333333 0.96666667 1. ]`
'''
默认情况下,cross_val_score执行3折交叉验证,可通过修改cv值改变折数
#总结交叉验证精度:计算平均值
print("Average cross-validation:{:.2f}".format(scores.mean()))
'''
`Average cross-validation:0.97`
'''
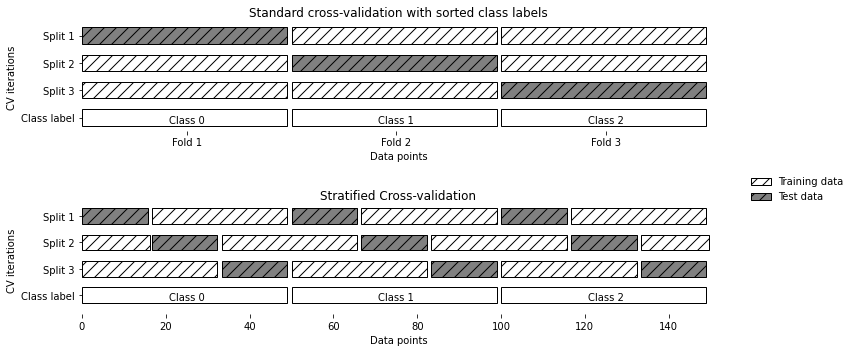
⭐sklearn里面的交叉验证
-
分类问题时使用:分层交叉验证
- 使每个折中类别之间的比例与整个数据集中的比例相同
-
回归问题:标准k折交叉验证
mglearn.plots.plot_stratified_cross_validation()
⭐可以用cv来调节cross_val_score的折数
-
sklearn还提供一个交叉验证分离器(cross_validatoin splitter)作为cv参数
#在分类数据集上使用标准K折交叉验证 #需要从model_selection导入KFold分离器类,并将其实例化 from sklearn.model_selection import KFold kf = KFold(n_splits=5) #5折 scores = cross_val_score(lrg,iris.data,iris.target,cv=kf) print("cross_validation scores:{}".format(scores)) ''' `cross_validation scores:[1. 1. 0.86666667 0.93333333 0.83333333]` ''' kf = KFold(n_splits=3) #3折 scores = cross_val_score(lrg,iris.data,iris.target,cv=kf) print("cross_validation scores:{}".format(scores)) ''' `cross_validation scores:[0. 0. 0.]` '''