MySQL优化器在基于成本的计算和基于规则的SQL优化会生成一个所谓的执行计划,我们就可以使用执行计划查看MySQL对该语句具体的执行方式。
介绍这个好啰嗦就是了,我们可以通过这个优化器展示的执行计划,查看优化器对我们的SQL进行优化的步骤,连接转换成单表访问时的优化。以及对于之前知识的复习了属于是,比如访问方式,索引的选择,半连接等SQL语句优化。
mysql> explain select * from mall.ums_admin;
+----+-------------+-----------+------------+------+---------------+------+---------+------+------+----------+-------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-----------+------------+------+---------------+------+---------+------+------+----------+-------+
| 1 | SIMPLE | ums_admin | NULL | ALL | NULL | NULL | NULL | NULL | 5 | 100.00 | NULL |
+----+-------------+-----------+------------+------+---------------+------+---------+------+------+----------+-------+
1 row in set, 1 warning (0.00 sec)
上述是我们使用explain使用的简单小例子。下面是每列的简单描述。

我们接下来就是对于Explain中展示的列进行介绍,回涉及到之前的SQL成本和语句优化。
table列对于每个SQL语句来说,不管是不是使用连接的多表查询,我们最后都会变成执行多个单表查询的语句。所以table列就指明了当前执行某个计划的表是哪一个。就比如上面例子的单表查询的SQL。
ID列会有以下几种情况
-
单表查询,此时的ID列就为1。
-
连接查询,此时对于两个表的连接查询ID列都为1,MySQL视在前面的表就是作为驱动表,在后面的表就是作为被驱动表。

-
子查询,有多种情况
- 当子查询不能被优化(前面提到的物化表转连接,半连接)时,每次出现一次SELECT关键字时,就会再分配一个独立的ID,即ID加一。

- 当子查询能被优化为连接时(物化表不能转连接的情况也不能优化哦),就会对SQL语句进行重写优化,就会被视为连接,这是ID列就和外层相等咯。

-
UNION连表,就是出现一个select就再分配一个ID值。稍微有点特殊对于UNION ALL。

首先呢是因为UNION关键字会对合并的结果集进行去重,进行去重就得创建一个临时表来进行去重,第三行是一个临时表。但是呢UNION ALL不去重就不会出现第三行记录。


就是简单的单表查询或者连接查询。
PRIMARY就是UNION或UNION ALL或子查询的情况下,最左边的select就是PRIMARY类型的。

就是UNION的时候除了最左边的SELECT是PRIMARY类型,其他的SELECT都是UNION。
UNION RESULTUNION的结果就会创建一个临时表进行去重,临时表就是这个select_type。
SUBQUERY- 子查询不能转换为半连接
- 该子查询是不相关子查询
- 子查询就会考虑使用物化的方案(如果数量很少就不会物化)
以上三个条件成立,此时子查询的第一个select部分的select_type就是SUBQUERY。如果物化的话,子查询只会执行一次,应该不用多说了。
DEPENDENT SUBQUERY- 子查询不能转换为半连接
- 子查询是相关子查询
以上条件成立,此时子查询的第一个select部分的select_type就是DEPENDENT SUBQUERY。相关外层查询会不断传参然后一直进行子查询。
DEPENDENT UNIONUNION中除了最左边的select部分,被union连接的小查询的select_type 都是DEPENDENT UNION。
DERIVED采用物化的方式执行的派生表,其中的子查询的select_type就是DERIVED。

当子查询是物化后转连接的方式,就是首先子查询是不相关子查询,然后子查询执行物化,优化成连接的方式和外层查询。此时子查询的select_type就是MATERIALIZED。

一般情况下都为null。
type列就是介绍访问当前行的表的访问方式。
我们之前学习的有
- const 主键或唯一索引等值查询
- ref 二级索引等值查询
- ref_or_null 二级索引等值查询或null值
- range 范围查询
- index 使用二级索引进行结果覆盖
- all 全表扫描
新的
- system 当表中只有一条记录,且该表的存储引擎的统计数据是精确的(MYISAM、MEMORY),此时访问就是system。
- eq_ref 连接查询时,对于被驱动表是使用主键或唯一索引进行访问的,被驱动表的访问方式就是eq_ref。
- index_merge 索引合并,就是intersection索引交集或者union索引并集,sort_union排序并集。
- unique_subquery 就是优化器将外层查询的in优化为exists,子查询可以使用主键或唯一索引进行查询,此时子查询就是unique_subquery 。???
- index_subquery 就是上面的变种,此时子查询使用普通的二级索引就是这个访问方式。
possible_key就是SQL可以用到的索引。
key就是优化器计算成本后决定使用的索引列。
key_len列就是使用的索引的索引记录的长度。有三部分相加而成。
- 如果是固定长度的,int这类的就是其的固定长度4。如果是变长的,比如varchar(100)且字符集utf8的就是最大长度300。
- 能不能为null值,如果可以需要1字节。
- 记录变长字段的长度,默认就是2字节,变长字段需要添加(字符集变长也需要添加)。
对于上面三部分,前面已经讲得很清楚了。
如果是varchar(100)可以为null的列,就需要300字节数据最大长度+1字节的非null+2字节记录长度,总长度就是303字节。
对于联合索引来说,用几个索引这个值就根据索引进行叠加上去,606就是俩varchar(100)可以为null的字段的联合索引。
ref列就是当我们使用索引进行匹配的时候,索引列具体等值匹配的是什么东西,常数值还是一个列等等。

代表优化器经过预测具体要扫描表或者索引多少行。
filter列代表驱动表的扇出比例,比如驱动表经过自身查询条件后预计会有多少记录数符合条件,输出出来。
对于单表来说这个字段没有意义,但是对于连接查询来说,可以预计被驱动表会执行多少次,即驱动表的扇出值。
extra列就是优化器为我们提供额外信息,来帮助我们分析语句。
-
No tables used
- 表示查询语句没有from,没有从表被使用到。
-
Impossible where
- 顾名思义,不可能满足的where语句,如1 != 1这种永远不可能满足
-
No matching min/max row
- 使用min和max聚集函数但是where语句没有能匹配的记录。
-
Using index
- 就是索引覆盖嘛。忘了可以回前面SQL优化文章看看
-
Using index condition
- 就是索引一个条件能使用,一个条件不能使用,导致我们使用索引先进行一个条件的查询,然后再对查询结果进行另外一个条件的过滤,然后再回表。
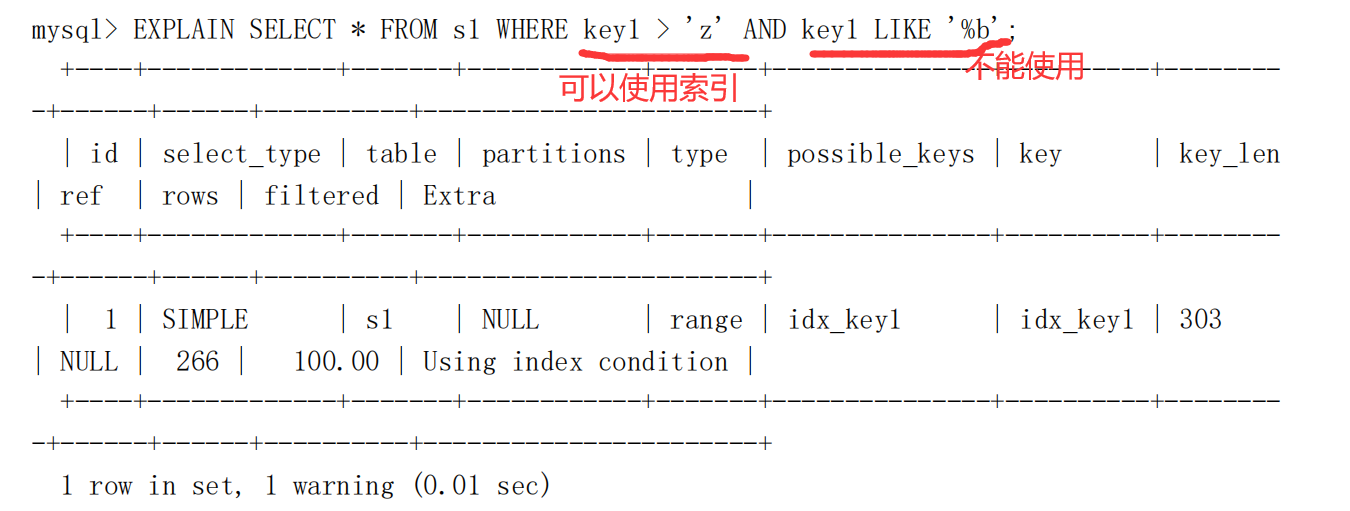
-
Using where
- 使用全表扫描或索引扫描,然后语句中有where的普通条件需要一条一条进行过滤,通常是没有使用索引的列,就会出现Using where的备注。
-
Using join buffer
- 我们使用join buffer加快驱动表对于被驱动表的连接。
-
Not exists
- 当进行外连接的时候,被驱动表的搜索条件为某个列 is null 但是列本身是not null的,这时就会出现not exists
-
Using intersect(...) ,Using union(...),Using sort_union(...)
- 当出现着这个备注就表示使用了索引合并。
-
Zero limit
- 出现limit 0,这种不要结果的SQL。
-
Using filesort
- 当无法使用索引排序,就会将数据在内存(数据量少的时候)或者在磁盘(数据量多的时候)进行对应条件的排序。这是十分耗时的,这是能用索引尽量用索引。
-
Using temporary
- 使用了临时表
-
Start temporary , End temporary
- 就是查询优化器使用半连接优化时,使用的是临时表对连接结果去重的方案实现半连接的时候,驱动表就会在extra中显示Start temporary,而被驱动表显示End temporary。
-
LooseScan
- 就是我们使用半连接的LooseScan的策略实现时,就会在驱动表中出现这个。
-
FirstMatch
- 忘了去SQL优化看了一下,就是最笨的那个驱动表一条一条匹配被驱动表的方式,就会在被驱动表显示此注释。