Hadoop是Apache旗下的一个用java语言实现开源软件框架,是一个开发和运行处理大规模数据的软件平台。允许使用简单的编程模型在大量计算机集群上对大型数据集进行分布式处理。狭义上说,Hadoop指Apache这款开源框架,它的核心组件有:
HDFS(分布式文件系统):解决海量数据存储.
YARN(作业调度和集群资源管理的框架):解决资源任务调度。
MAPREDUCE(分布式运算编程框架):解决海量数据计算。
广义上来说,Hadoop通常是指一个更广泛的概念——Hadoop生态圈(一图看懂大数据生态圈)
扩容能力(Scalable):Hadoop是在可用的计算机集群间分配数据并完成计算任务的,这些集群可用方便的扩展到数以千计的节点中。
成本低(Economical):Hadoop通过普通廉价的机器组成服务器集群来分发以及处理数据,以至于成本很低。
高效率(Efficient):通过并发数据,Hadoop可以在节点之间动态并行的移动数据,使得速度非常快。
可靠性(Rellable):能自动维护数据的多份复制,并且在任务失败后能自动地重新部署(redeploy)计算任务。所以Hadoop的按位存储和处理数据的能力值得人们信赖。
3 Hadoop历史版本与架构1.x版本系列:Hadoop版本当中的第二代开源版本,主要修复0.x版本的一些bug等,该版本已被淘汰
2.x版本系列:架构产生重大变化,引入了yarn平台等许多新特性,是现在使用的主流版本。
3.x版本系列:对HDFS、MapReduce、YARN都有较大升级,还新增了Ozone key-value存储。
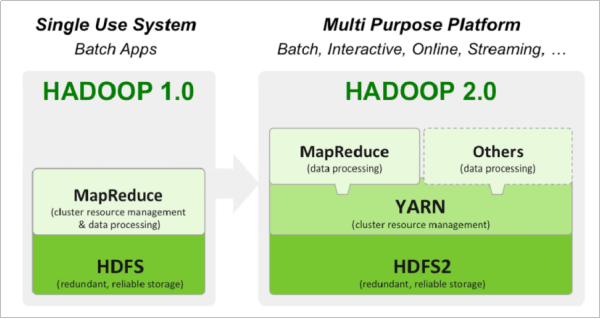
架构:Hadoop在1.X版本的时候只有HDFS和MapReduce。在Hadoop2.X开始,中间加入了Yarn调度层做资源调度工作。如下图:一图读懂Hadoop架构。
由于Hadoop 2.0是基于JDK 1.7开发的,而JDK 1.7在2015年4月已停止更新,这直接迫使Hadoop社区基于JDK 1.8重新发布一个新的Hadoop版本,即Hadoop 3.0。Hadoop 3.0中引入了一些重要的功能和优化,包括HDFS 可擦除编码、多Namenode支持、MR Native Task优化、YARN基于cgroup的内存和磁盘IO隔离、YARN container resizing等。
Apache Hadoop 项目组最新消息,Hadoop3.x以后将会调整方案架构,将Mapreduce 基于内存+io+磁盘,共同处理数据。改变最大的是hdfs,hdfs 通过最近block块计算,根据最近计算原则,本地block块,加入到内存,先计算,通过IO,共享内存计算区域,最后快速形成计算结果。
4.1 Hadoop 3.0新特性
Hadoop 3.0在功能和性能方面,对Hadoop内核进行了多项重大改进。
(1)通用性:
① 精简Hadoop内核,包括剔除过期的API和实现,将默认组件实现替换成最高效的实现。
② Classpath isolation:以防止不同版本jar包冲突。
③ Shell脚本重构: Hadoop 3.0对Hadoop的管理脚本进行了重构,修复了大量bug,增加了新特性。
(2)HDFS
Hadoop3.x中Hdfs在可靠性和支持能力上作出很大改观:
① HDFS支持数据的擦除编码,这使得HDFS在不降低可靠性的前提下,节省一半存储空间。
② 多NameNode支持,即支持一个集群中,一个active、多个standby namenode部署方式。注:多ResourceManager特性在Hadoop 2.0中已经支持。
(3)HDFS纠删码
在Hadoop3.X中,HDFS实现了Erasure Coding这个新功能。Erasure coding纠删码技术简称EC,是一种数据保护技术.最早用于通信行业中数据传输中的数据恢复,是一种编码容错技术。通过在原始数据中加入新的校验数据,使得各个部分的数据产生关联性。在一定范围的数据出错情况下,通过纠删码技术都可以进行恢复。Hadoop-3.0之前,HDFS存储方式为每一份数据存储3份,这也使得存储利用率仅为1/3,Hadoop-3.0引入纠删码技术(EC技术),实现1份数据+0.5份冗余校验数据存储方式。与副本相比纠删码是一种更节省空间的数据持久化存储方法。标准编码(比如Reed-Solomon(10,4))会有1.4 倍的空间开销;而HDFS副本则会有3倍的空间开销。
(4)支持多个NameNodes
最初的HDFS NameNode high-availability实现仅仅提供了一个active NameNode和一个Standby NameNode;并且通过将编辑日志复制到三个JournalNodes上,这种架构能够容忍系统中的任何一个节点的失败。 然而,一些部署需要更高的容错度。我们可以通过这个新特性来实现,其允许用户运行多个Standby NameNode。比如通过配置三个NameNode和五个JournalNodes,这个系统可以容忍2个节点的故障,而不是仅仅一个节点。
(5) MapReduce
Hadoop3.X中的MapReduce较之前的版本作出以下更改:
① Tasknative优化:为MapReduce增加了C/C++的map output collector实现(包括Spill,Sort和IFile等),通过作业级别参数调整就可切换到该实现上。对于shuffle密集型应用,其性能可提高约30%。
② MapReduce内存参数自动推断。在Hadoop 2.0中,为MapReduce作业设置内存参数非常繁琐,一旦设置不合理,则会使得内存资源浪费严重,在Hadoop3.0中避免了这种情况。
Hadoop3.x中的MapReduce添加了Map输出collector的本地实现,对于shuffle密集型的作业来说,这将会有30%以上的性能提升。
(6)YARN 资源类型
YARN 资源模型(YARN resource model)已被推广为支持用户自定义的可数资源类型(support user-defined countable resource types),不仅仅支持 CPU 和内存。比如集群管理员可以定义诸如 GPUs、软件许可证(software licenses)或本地附加存储器(locally-attached storage)之类的资源。YARN 任务可以根据这些资源的可用性进行调度。
(7)其他
在Hadoop3.x之前,多个Hadoop服务的默认端口都属于Linux的临时端口范围(32768-61000)。这就意味着用户的服务在启动的时候可能因为和其他应用程序产生端口冲突而无法启动。现在这些可能会产生冲突的端口已经不再属于临时端口的范围,这些端口的改变会影响NameNode, Secondary NameNode, DataNode以及KMS。与此同时,官方文档也进行了相应的改变,具体可以参见 HDFS-9427以及HADOOP-12811。
- Namenode ports: 50470 --> 9871, 50070--> 9870, 8020 --> 9820
- Secondary NN ports: 50091 --> 9869,50090 --> 9868
- Datanode ports: 50020 --> 9867, 50010--> 9866, 50475 --> 9865, 50075 --> 9864
- Kms server ports: 16000 --> 9600 (原先的16000与HMaster端口冲突)
Hadoop集群具体来说包含两个集群:HDFS集群和YARN集群,两者逻辑上分离,但物理上常在一起。
HDFS集群负责海量数据的存储,集群中的角色主要有:
- NameNode、DataNode、SecondaryNameNode
YARN集群负责海量数据运算时的资源调度,集群中的角色主要有:
- ResourceManager、NodeManager
mapreduce是一个分布式运算编程框架。是应用程序开发包,由用户按照编程规范进行程序开发,后打包运行在HDFS集群上,并且受到YARN集群的资源调度管理。
(2) 集群部署方式
- standalone mode(独立模式):独立模式又称为单机模式,仅1个机器运行1个java进程,主要用于调试。
-
Pseudo-Distributed mode(伪分布式模式):伪分布模式也是在1个机器上运行HDFS的NameNode和DataNode、YARN的 ResourceManger和NodeManager,但分别启动单独的java进程,主要用于调试。
-
Cluster mode(群集模式):集群模式主要用于生产环境部署。会使用N台主机组成一个Hadoop集群。这种部署模式下,主节点和从节点会分开部署在不同的机器上。
(3) Hadoop集群架构模型
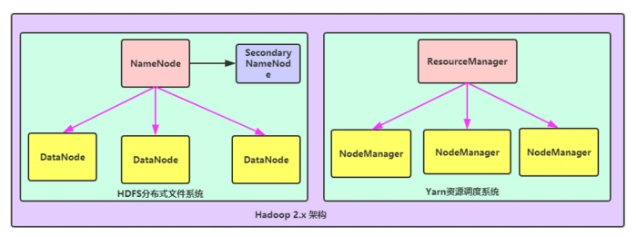
- 第一种:NameNode与ResourceManager单节点架构模型
文件系统核心模块:
NameNode:集群当中的主节点,主要用于管理集群当中的各种数据。
secondaryNameNode:主要能用于hadoop当中元数据信息的辅助管理。
DataNode:集群当中的从节点,主要用于存储集群当中的各种数据。
数据计算核心模块:
ResourceManager:接收用户的计算请求任务,并负责集群的资源分配。
NodeManager:负责执行主节点APPmaster分配的任务。
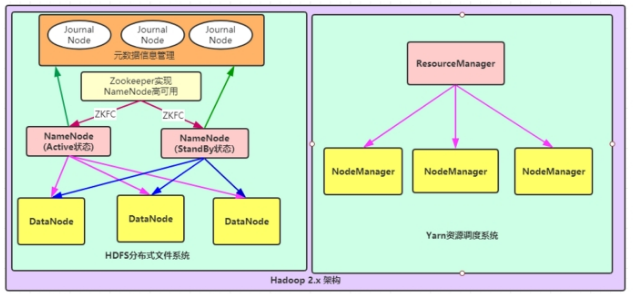
- 第二种:NameNode高可用与ResourceManager单节点架构模型
文件系统核心模块:
NameNode:集群当中的主节点,主要用于管理集群当中的各种数据,其中NameNode可以有两个,形成高可用状态。
DataNode:集群当中的从节点,主要用于存储集群当中的各种数据。
JournalNode:文件系统元数据信息管理。
数据计算核心模块:
ResourceManager:接收用户的计算请求任务,并负责集群的资源分配,以及计算任务的划分。
NodeManager:负责执行主节点ResourceManager分配的任务。
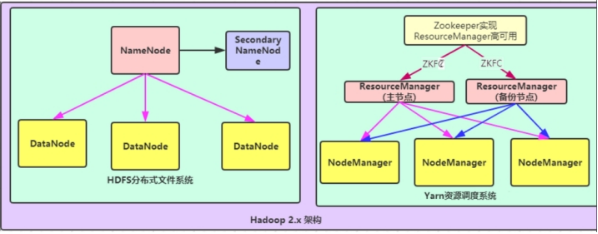
- 第三种:NameNode单节点与ResourceManager高可用架构模型
文件系统核心模块:
NameNode:集群当中的主节点,主要用于管理集群当中的各种数据。
secondaryNameNode:主要能用于hadoop当中元数据信息的辅助管理。
DataNode:集群当中的从节点,主要用于存储集群当中的各种数据。
数据计算核心模块:
ResourceManager:接收用户的计算请求任务,并负责集群的资源分配,以及计算任务的划分,通过zookeeper实现ResourceManager的高可用。
NodeManager:负责执行主节点ResourceManager分配的任务。
-
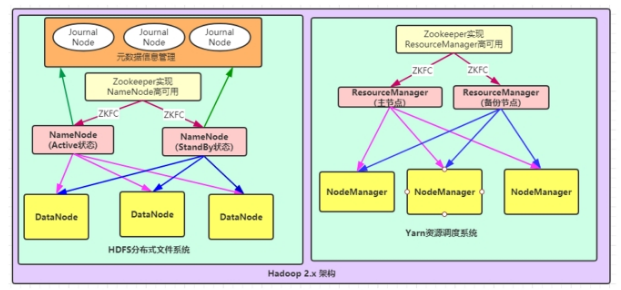
第四种:NameNode与ResourceManager高可用架构模型
搭建过程查看另外一篇文章( HDFS High Availability(HA)高可用配置 )
文件系统核心模块:
NameNode:集群当中的主节点,主要用于管理集群当中的各种数据,一般都是使用两个,实现HA高可用
JournalNode:元数据信息管理进程,一般都是奇数个
DataNode:从节点,用于数据的存储
数据计算核心模块:
ResourceManager:Yarn平台的主节点,主要用于接收各种任务,通过两个,构建成高可用
NodeManager:Yarn平台的从节点,主要用于处理ResourceManager分配的任务
以上就是Hadoop的详细介绍,接下来就让我们实战吧,我们准备三台虚拟机。
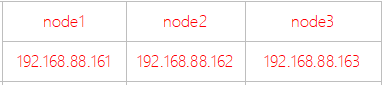
准备工作:实现虚拟机之间的SSH免密登录(参考文章)
在三台主机上分别创建目录:
mkdir -p /export/server/
mkdir -p /export/data/
mkdir -p /export/software/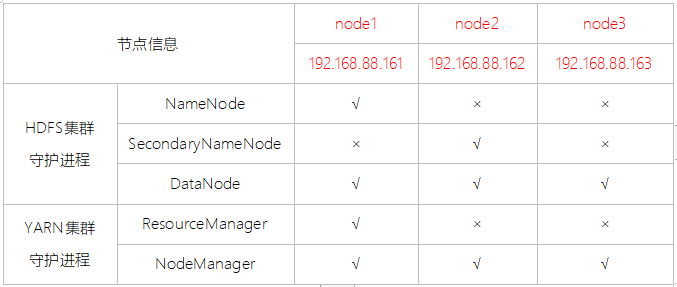
(1)解压Hadoop安装包
自行复制链接下载:http://archive.apache.org/dist/hadoop/core/hadoop-3.1.4/hadoop-3.1.4.tar.gz
上传下载的Hadoop3.1.4包到 /export/software/ 目录下。上传方式多种,这里就不做展示,然后解压。解压命令:
cd /opt/export/software
tar -zxvf hadoop-3.1.4-bin-snappy-CentOS7.tar.gz -C /export/server/在Hadoop3.1.4文件中创建用于存放数据的data目录:
mkdir -p /export/server/hadoop-3.1.4/data(2)编辑配置文件
- 配置NameNode(core-site.xml)
hadoop的核心配置文件,有默认的配置项core-default.xml。在该文件中的<configuration>标签中添加配置。
core-default.xml与core-site.xml的功能是一样的,如果在core-site.xml里没有配置的属性,则会自动会获取core-default.xml里的相同属性的值。
cd /export/server/hadoop-3.1.4/etc/hadoop
vim core-site.xml
#-------------------------------------------------------------
#在第19行<configuration></configuration>之间添加配置,以下内容:
<!-- 默认文件系统的名称。通过URI中schema区分不同文件系统。-->
<!-- file:///本地文件系统 hdfs:// hadoop分布式文件系统 gfs://。-->
<!-- hdfs文件系统访问地址:http://nn_host:8020。-->
<property>
<name>fs.defaultFS</name>
<value>hdfs://node1:8020</value>
</property>
<!-- hadoop本地数据存储目录 format时自动生成 -->
<property>
<name>hadoop.tmp.dir</name>
<value>/export/server/hadoop-3.1.4/data</value>
</property>
<!-- 在Web UI访问HDFS使用的用户名。-->
<property>
<name>hadoop.http.staticuser.user</name>
<value>root</value>
</property>- 配置HDFS路径(hdfs-site.xml)
HDFS的核心配置文件,主要配置HDFS相关参数,有默认的配置项hdfs-default.xml。在该文件中的<configuration>标签中添加配置。
hdfs-default.xml与hdfs-site.xml的功能是一样的,如果在hdfs-site.xml里没有配置的属性,则会自动会获取hdfs-default.xml里的相同属性的值。
vim hdfs-site.xml
#-------------------------------------------------------------
#在第20行<configuration></configuration>之间添加配置,以下内容:
<!-- 设定SNN运行主机和端口。-->
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>node2:9868</value>
</property>- 配置YARN(yarn-site.xml)
YARN的核心配置文件,在该文件中的<configuration>标签中添加配置。
vim yarn-site.xml
#-----------------------------------------------------------
#在第18行<configuration></configuration>之间添加配置,以下内容:
<!-- yarn集群主角色RM运行机器。-->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>node1</value>
</property>
<!-- NodeManager上运行的附属服务。需配置成mapreduce_shuffle,才可运行MR程序。-->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<!-- 每个容器请求的最小内存资源(以MB为单位)。-->
<property>
<name>yarn.scheduler.minimum-allocation-mb</name>
<value>512</value>
</property>
<!-- 每个容器请求的最大内存资源(以MB为单位)。-->
<property>
<name>yarn.scheduler.maximum-allocation-mb</name>
<value>2048</value>
</property>
<!-- 容器虚拟内存与物理内存之间的比率。-->
<property>
<name>yarn.nodemanager.vmem-pmem-ratio</name>
<value>4</value>
</property>-
配置MapReduce(mapred-site.xml)
MapReduce的核心配置文件,Hadoop默认只有个模板文件mapred-site.xml.template,需要使用该文件复制出来一份mapred-site.xml文件。在该文件中的<configuration>标签中添加配置。
vim mapred-site.xml
#------------------------------------------------------------
#在第20行<configuration></configuration>之间添加配置,以下内容:
<!-- mr程序默认运行方式。yarn集群模式 local本地模式-->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<!-- MR App Master环境变量。-->
<property>
<name>yarn.app.mapreduce.am.env</name>
<value>HADOOP_MAPRED_HOME=${HADOOP_HOME}</value>
</property>
<!-- MR MapTask环境变量。-->
<property>
<name>mapreduce.map.env</name>
<value>HADOOP_MAPRED_HOME=${HADOOP_HOME}</value>
</property>
<!-- MR ReduceTask环境变量。-->
<property>
<name>mapreduce.reduce.env</name>
<value>HADOOP_MAPRED_HOME=${HADOOP_HOME}</value>
</property> <property>
<name>mapreduce.reduce.env</name>
<value>HADOOP_MAPRED_HOME=${HADOOP_HOME}</value>
</property>- workers文件配置
配合一键启动脚本如start-dfs.sh、stop-yarn.sh用来进行集群启动。这时候workers文件里面的主机标记的就是从节点角色所在的机器。
vim /export/server/hadoop-3.1.4/etc/hadoop/workers
#----------------------------------
# 删除第一行localhost,然后添加以下三行
node1
node2
node3- 修改hadoop.env环境变量
文件中设置的是Hadoop运行时需要的环境变量。JAVA_HOME是必须设置的,即使我们当前的系统中设置了JAVA_HOME,它也是不认识的,因为Hadoop即使是在本机上执行,它也是把当前的执行环境当成远程服务器。
#hadoop.env文件
vim /export/server/hadoop-3.1.4/etc/hadoop/hadoop-env.sh
#修改第54行为:
#备注:JavaJDK版本配置在/etc/profile的JAVA_HOME=/export/server/jdk1.8.0_60 这里配置自己服务器java的JDK的版本
export JAVA_HOME=/export/server/jdk1.8.0_60
export HDFS_NAMENODE_USER=root
export HDFS_DATANODE_USER=root
export HDFS_SECONDARYNAMENODE_USER=root
export YARN_RESOURCEMANAGER_USER=root
export YARN_NODEMANAGER_USER=root- 配置环境变量
vim /etc/profile
#打开配置文件后新增如下配置。
export HADOOP_HOME=/export/server/hadoop-3.1.4
export PATH=$PATH:${HADOOP_HOME}/bin:${HADOOP_HOME}/sbin
#保存配置文件后需要刷新配置文件
source /etc/profile-
分发配置好的Hadoop安装文件和环境变量
#进入Hadoop安装目录
cd /export/server/
#分发给Node2和Node3,
scp -r hadoop-3.1.4 node2:$PWD
scp -r hadoop-3.1.4 node3:$PWD
scp /etc/profile node2:/etc
scp /etc/profile node3:/etc
#在Node2和Node3主机上执行刷新配置文件
source /etc/profile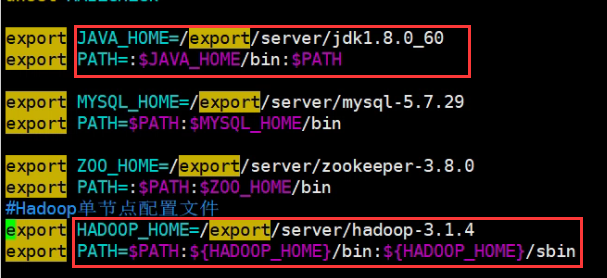
(3) 格式化HDFS
首次启动HDFS时,必须对其进行格式化操作。本质上是一些清理和准备工作,因为此时的HDFS在物理上还是不存在的。只需要在node1上进行格式化,只能格式化一次
cd /export/server/hadoop-3.1.4
bin/hdfs namenode -format使用以下方式启动Hadoop,建议方式三一键启动。必须启动Hadoop才能访问网页。
(1)集群启动和关闭-方式一
注意:如果在启动之后,有些服务没有启动成功,则需要查看启动日志,Hadoop的启动日志在每台主机的/export/server/hadoop-x.x.x/logs/目录,需要根据哪台主机的哪个服务启动情况去对应的主机上查看相应的日志,以下是node1主机的日志目录。
- ①-启动HDFS集群
#-- 选择node1节点启动NameNode节点
hdfs --daemon start namenode
#-- 在所有节点上启动DataNode
hdfs --daemon start datanode
#-- 在node2启动Secondary NameNode
hdfs --daemon start secondarynamenode- ①- 启动YARN集群
#-- 选择node1节点启动ResourceManager节点
yarn --daemon start resourcemanager
#-- 在所有节点上启动NodeManager
yarn --daemon start nodemanager- ①-关闭HDFS集群
#-- 关闭NameNode
hdfs --daemon stop namenode
#-- 每个节点关闭DataNode
hdfs --daemon stop datanode
#-- 关闭Secondary NameNode
hdfs --daemon stop secondarynamenode- ①-关闭YARN集群
#-- 每个节点关闭ResourceManager
yarn --daemon stop resourcemanager
#-- 每个节点关闭NodeManager
yarn --daemon stop nodemanager(2)集群启动和关闭-方式2
- ②-HDFS集群一键脚本
#启动dfs
start-dfs.sh
#关闭dfs
stop-dfs.sh- ②-YARN集群一键脚本
#启动Yarn
start-yarn.sh
#关闭Yarn
stop-yarn.sh#-- 一键启动HDFS、YARN
start-all.sh
#-- 一键关闭HDFS、YARN
stop-all.sh(4)配置windows域名映射
- 以管理员身份打开C:\Windows\System32\drivers\etc目录下的hosts文件
- 在文件最后添加以下映射域名和ip映射关系
192.168.88.161 node1
192.168.88.162 node2
192.168.88.163 node3测试映射是否生效,在CMD界面中输入
ping node1
ping node2(5)访问WebUI
NameNode: http://node1:9870
YARN: http://node1:8088
(1) 使用HDFS
从Linux本地上传一个文本文件到hdfs的/目录
#在/export/data/目录中创建a.txt文件,并写入数据
cd /export/data/
touch a.txt
echo "hello" > a.txt
#将a.txt上传到HDFS的根目录
hadoop fs -put a.txt /通过页面查看, 通过NameNode页面.进入HDFS:http://node1:9870/
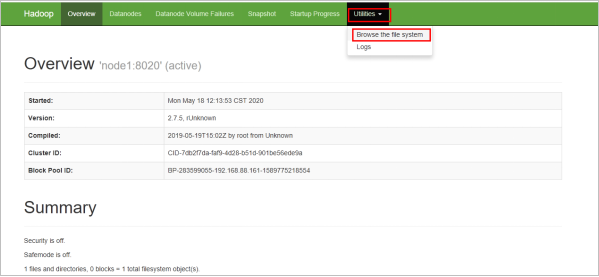
查看文件是否创建成功.
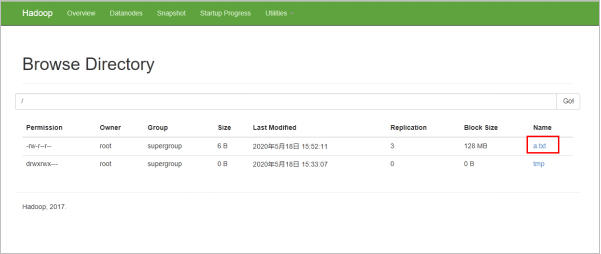
(2)运行mapreduce程序
在Hadoop安装包的share/hadoop/mapreduce下有官方自带的mapreduce程序。我们可以使用如下的命令进行运行测试。(示例程序jar:hadoop-mapreduce-examples-3.1.4.jar计算圆周率)
关于圆周率的估算,感兴趣的可以查询资料蒙特卡洛方法来计算Pi值,计算命令中2表示计算的线程数,1000表示投点数,该值越大,则计算的pi值越准确。
yarn jar /export/server/hadoop-3.1.4/share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.5.jar pi 2 1000(3) 测试写入速度
#1.启动YARN集群
start-yarn.sh
#2.启动写入基准测试
hadoop jar /export/server/hadoop-3.1.4/share/hadoop/mapreduce/hadoop-mapreduce-client-jobclient-3.1.4-tests.jar TestDFSIO -write -nrFiles 10 -fileSize 10MB我们可以看到Hadoop启动了一个MapReduce作业来运行benchmark测试。等待约2-5分钟,MapReduce程序运行成功后,就可以查看测试结果了。
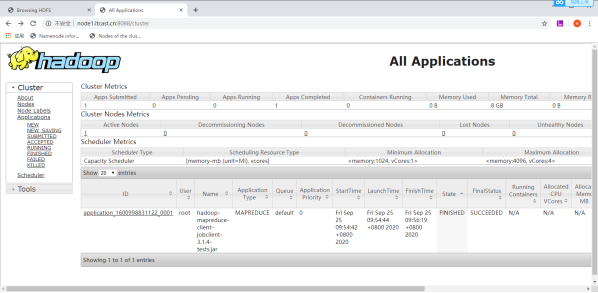
测试hdfs的读取文件性能,在HDFS文件系统中读入10个文件,每个文件10M
#测试读取
hadoop jar /export/server/hadoop-3.1.4/share/hadoop/mapreduce/hadoop-mapreduce-client-jobclient-3.1.4-tests.jar TestDFSIO -read -nrFiles 10 -fileSize 10MB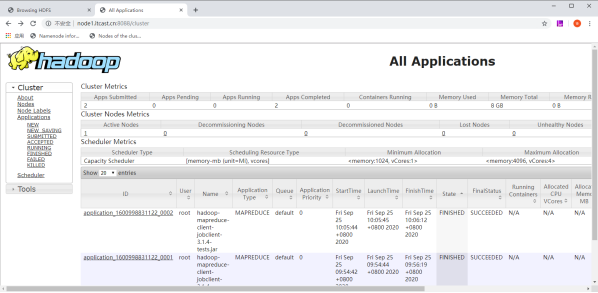
测试期间,会在HDFS集群上创建 /benchmarks目录,测试完毕后,我们可以清理该目录。
#清理测试数据
hdfs dfs -ls -R /benchmarks
hadoop jar /export/server/hadoop-3.1.4/share/hadoop/mapreduce/hadoop-mapreduce-client-jobclient-3.1.4-tests.jar TestDFSIO -clean至此,整篇的Hadoop介绍以及单节点部署介绍完毕,后期会写Hive,敬请期待吧,欢迎留言探讨。
【转自:香港高防 http://www.558idc.com/stgf.html转载请说明出处】