kafka日志文件是以patition在物理存储上分割的
是topic物理上的分组,一个topic可以分为多个partition,每个partition是一个有序的队列
是以文件夹的形式存储在具体Broker本机上
LEO表示每个partition的log最后一条Message的位置
HW(HighWatermark) 表示partition各个replicas(用于分布式存储的副本分片)数据间同步且一致的offset位置,即表示all replicas已经commit的位置 HW之前的数据才是Commit后的,对消费者才可见
Segment 每个partition又由多个segment file组成 我们说的kafka日志文件就是说的segment,下面我们主要讨论一下segment文件的结构 Segment 日志目录以及文件组成 每个partition又由多个segment file组成 segment file 由2种文件组成组成,分别为index file(索引文件)和log file(日志文件) 日志文件的文件后缀为 *.log 索引文件的文件后缀为 *.index、*.timeindex 命名规则:partition的第一个segment从0开始,后续每个segment文件名为上一个segment文件最后一条消息的offset+1 (offset后文会提到) 下图能比较清晰的反应出来partition、segment、和文件的关系,以及在分布式系统中是如何体现的
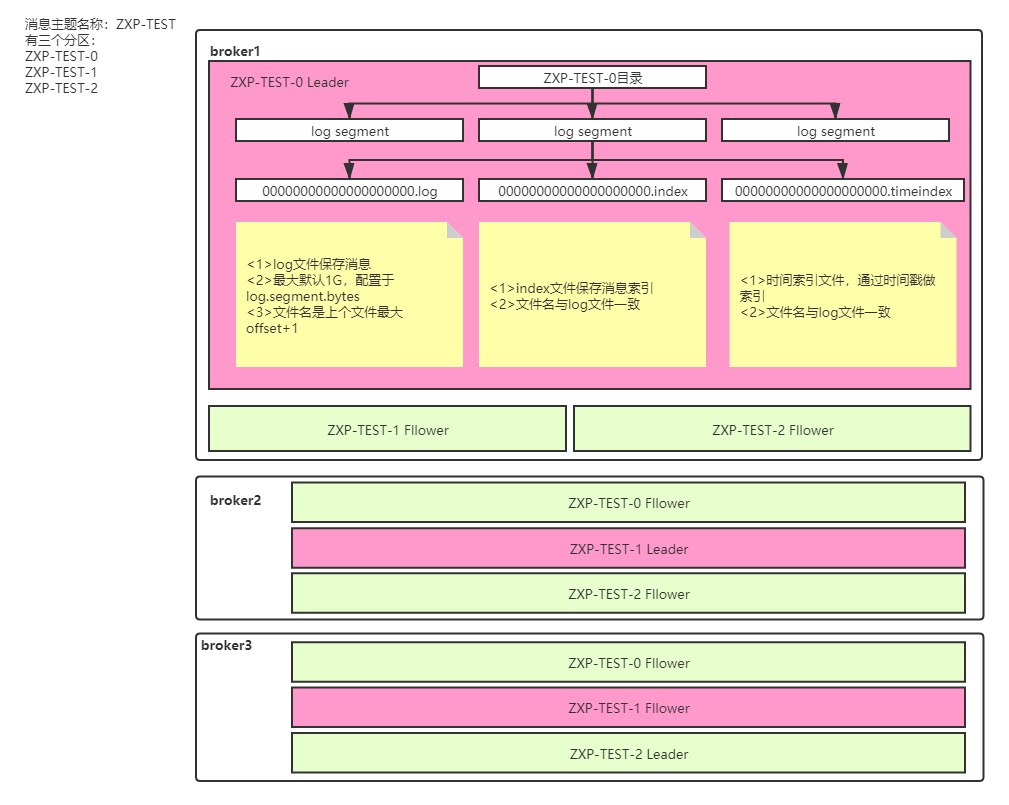
从微观即一个partition看:
消息主题是ZXP-TEST
此消息有3个partition(创建主题时指定),每个partition会有一个自己的目录
每个partion的目录下都会有segment文件,比如第一个segment文件由三个文件组成:00000000000000000000.log、00000000000000000000.index、00000000000000000000.timeindex
三个文件的作用如上图,其中当log文件达到最大值,会新生成一套segment文件,文件都是追加写,所以写性能会比较高
我们再来从宏观即3台broker看:
broker1中partion ZXP-TEST-0是leader
broker1中partion ZXP-TEST-1是follower
broker1中partion ZXP-TEST-2是follower
那么ZXP-TEST-0对应的follower在broker2、broker3(副本数由启动参数offsets.topic.replication.factor决定)
ZXP-TEST-1对应的leader在broker2
注意:同一台broker中不能存放同一个partition的主从分片,这点很多分布式系统都有此设计
offset与position
offset偏移量:代表第几个消息
position位置:代表消息在磁盘的物理位置
其中日志文件命名中的偏移量是offset不是position,否则无法根据offset轻松找到在哪个日志文件中
日志文件内部数据结构 日志索引文件
由offset、position组成
bin/kafka-run-class.sh kafka.tools.DumpLogSegments --files 00000000000000000000.index # 也能印证日志文件命名中的偏移量是offset不是position offset:5083 position:1072592768

索引文件是有序的,可以快速根据offset寻找position,position可以快速从log文件定位消息体
时间索引文件由timestamp、offset组成
bin/kafka-run-class.sh kafka.tools.DumpLogSegments --files 00000000000000000000.timeindex timestamp: 1603703296169 offset: 5083
时间索引文件也是有序的
日志文件 组成如下bin/kafka-run-class.sh kafka.tools.DumpLogSegments --files 00000000000000000000.log baseoffset:5083 position: 1072592768 CreateTime: 1603703296169

如何通过索引定位消息
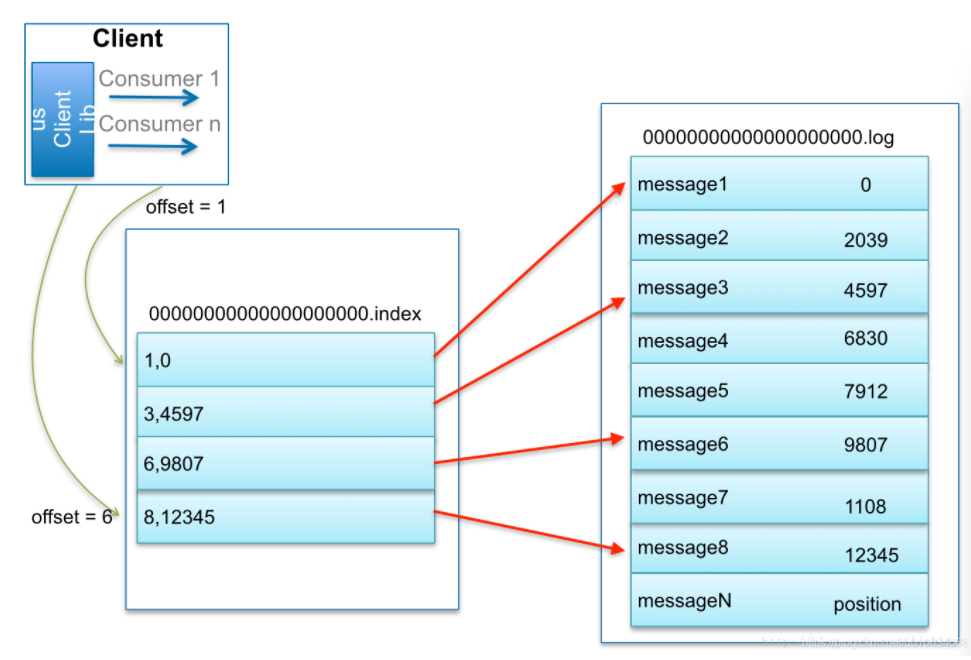
找offset为7的消息
1、首先是用二分查找确定它是在哪个LogSegment中,自然是在第一个Segment中(日志文件命名中的偏移量是offset不是position)
2、打开这个Segment的index文件,也是用二分查找找到offset小于或者等于指定offset的索引条目中最大的那个offset。自然offset为6的那个索引是我们要找的,通过索引文件我们知道offset为6的Message在数据文件中的位置为9807。(Kafka 中的索引文件,以稀疏索引(sparse index)的方式构造消息的索引,它并不保证每个消息在索引文件中都有对应的索引项)
3、打开数据文件,从位置为9807的那个地方开始顺序扫描直到找到offset为7的那条Message(找到第6个消息后根据position+消息大小向后找直到找到) 与rocketMQ的对比关于rocketmq的日志存储可以参考我的另一篇文章《快速弄明白RocketMQ的CommitLog、ConsumeQueue、indexFile、offsetTable 以及多种偏移量对比》
日志文件清理 Kafka将数据持久化到了硬盘上,为了控制磁盘容量,需要对过去的消息进行清理(segment文件) 清理策略
1、内部有个定时任务检测删除日志,默认是5分钟 log.retention.check.interval.ms
2、支持配置策略对数据清理
3、根据segment单位进行定期清理
log.cleaner.enable=true log.cleaner.threads = 2 (清理线程数配置) log.cleanup.policy=delete #清理超过指定时间的消息,默认是168小时,7天, #还有log.retention.ms, log.retention.minutes, log.retention.hours,优先级高到低 log.retention.hours=168 #超过指定大小后,删除旧的消息,下面是1G的字节数,-1就是没限制 log.retention.bytes=1073741824
基于【时间删除】 日志说明 每个日志段文件都维护一个最大时间戳字段,每次日志段写入新的消息时,都会更新该字段 一个日志段segment写满了被切分之后,就不再接收任何新的消息,最大时间戳字段的值也将保持不变 kafka通过将当前时间与该最大时间戳字段进行比较,从而来判定是否过期 基于【大小超过阈值】 删除日志 说明 假设日志段大小是500MB,当前分区共有4个日志段文件,大小分别是500MB,500MB,500MB和10MB 10MB那个文件就是active日志段。 此时该分区总的日志大小是3*500MB+10MB=1500MB+10MB 如果阈值设置为1500MB,那么超出阈值的部分就是10MB,小于日志段大小500MB,故Kafka不会执行任何删除操作,即使总大小已经超过了阈值; 如果阈值设置为1000MB,那么超过阈值的部分就是500MB+10MB > 500MB,此时Kafka会删除最老的那个日志段文件 注意:超过阈值的部分必须要大于一个日志段的大小才会删除 删除日志时不考虑,是不是还有未消费的数据,对于一个topic随时也有可能增加新的消费者 【本文由:高防服务器ip http://www.558idc.com/gfip.html 复制请保留原URL】