 本篇重点讲述导入数据到StarRocks几种方式,也通过一个flink-connector-starrocks的简单示例代码了解其导入过程,进而学习数组类型的使用、分布式实现本地Join的使用,最后抛出外部表的使用大门
数据导入
总览
概述
本篇重点讲述导入数据到StarRocks几种方式,也通过一个flink-connector-starrocks的简单示例代码了解其导入过程,进而学习数组类型的使用、分布式实现本地Join的使用,最后抛出外部表的使用大门
数据导入
总览
概述
数据导入功能是将原始数据按照相应的模型进行清洗转换并加载到StarRocks中,方便查询使用。StarRocks提供了多种导入方式,用户可以根据数据量大小、导入频率等要求选择最适合自己业务需求的导入方式。
- 离线数据导入,如果数据源是Hive/HDFS,推荐采用Broker Load导入, 如果数据表很多导入比较麻烦可以考虑使用Hive外表直连查询,性能会比Broker load导入效果差,但是可以避免数据搬迁,如果单表的数据量特别大,或者需要做全局数据字典来精确去重可以考虑Spark Load导入。
- 实时数据导入,日志数据和业务数据库的binlog同步到Kafka以后,优先推荐通过Routine load 导入StarRocks,如果导入过程中有复杂的多表关联和ETL预处理可以使用Flink处理以后用stream load写入StarRocks,我们有标准的Flink-connector可以方便Flink任务使用。
- 程序写入StarRocks,推荐使用Stream Load,可以参考例子中有Java/Python的demo。
- 文本文件导入推荐使用 Stream load
- Mysql数据导入,推荐使用Mysql外表,insert into new_table select * from external_table 的方式导入
- 其他数据源导入,推荐使用DataX导入,我们提供了DataX-starrocks-writer
- StarRocks内部导入,可以在StarRocks内部使用insert into tablename select的方式导入,可以跟外部调度器配合实现简单的ETL处理。
- 用户可以通过设置参数来限制单个导入作业的内存使用,以防止导入占用过多的内存而导致系统OOM。
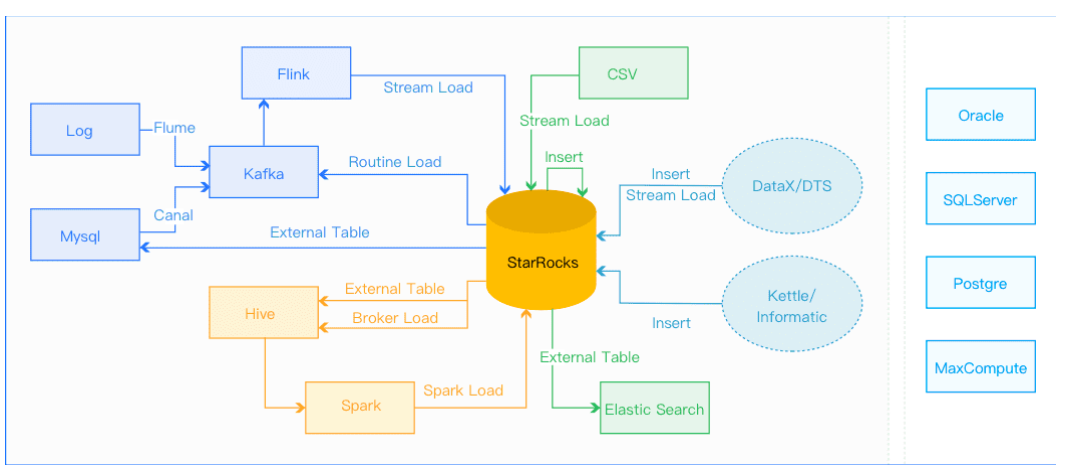
导入执行流程,一个导入作业主要分为5个阶段:
- PENDING:非必须。该阶段是指用户提交导入作业后,等待FE调度执行。Broker Load和Spark Load包括该步骤。
- ETL:非必须。该阶段执行数据的预处理,包括清洗、分区、排序、聚合等。Spark Load包括该步骤,它使用外部计算资源Spark完成ETL。
- LOADING:该阶段先对数据进行清洗和转换,然后将数据发送给BE处理。当数据全部导入后,进入等待生效过程,此时导入作业状态依旧是LOADING。
- FINISHED:在导入作业涉及的所有数据均生效后,作业的状态变成 FINISHED,FINISHED后导入的数据均可查询。FINISHED是导入作业的最终状态。
- CANCELLED:在导入作业状态变为FINISHED之前,作业随时可能被取消并进入CANCELLED状态,如用户手动取消或导入出现错误等。CANCELLED也是导入作业的一种最终状态。
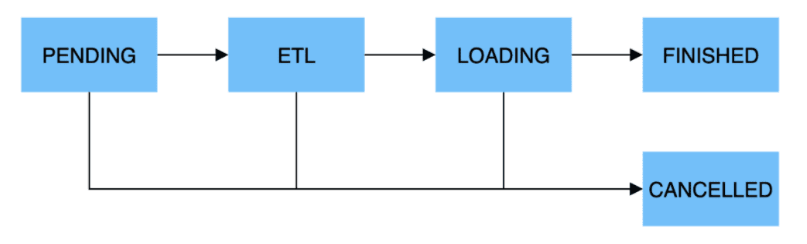
- 同步导入
- 同步导入方式即用户创建导入任务,StarRocks 同步执行,执行完成后返回导入结果。用户可通过该结果判断导入是否成功。
- 同步类型的导入方式有:Stream Load,Insert。
- 异步导入
- 异步导入方式即用户创建导入任务后,StarRocks直接返回创建成功。创建成功不代表数据已经导入成功。导入任务会被异步执行,用户在创建成功后,需要通过轮询的方式发送查看命令查看导入作业的状态。如果创建失败,则可以根据失败信息,判断是否需要再次创建。
- 异步类型的导入方式有:Broker Load, Spark Load。
- HDFS导入:源数据存储在HDFS中,数据量为几十GB到上百GB时,可采用Broker Load方法向StarRocks导入数据。源数据存储在HDSF中,数据量达到TB级别时,可采用Spark Load方法向StarRocks导入数据。
- 本地文件导入:数据存储在本地文件中,数据量小于10GB,可采用Stream Load方法将数据快速导入StarRocks系统。
- Kafka导入:数据来自于Kafka等流式数据源,需要向StarRocks系统导入实时数据时,可采用Routine Load方法。
- Insert Into导入:手工测试及临时数据处理时可以使用
Insert Into方法向StarRocks表中写入数据。
- StarRocks支持从本地直接导入数据,支持CSV文件格式。数据量在10GB以下。
- Stream Load 是一种同步的导入方式,用户通过发送 HTTP 请求将本地文件或数据流导入到 StarRocks 中。
- Stream Load 同步执行导入并返回导入结果。用户可直接通过请求的返回值判断导入是否成功。
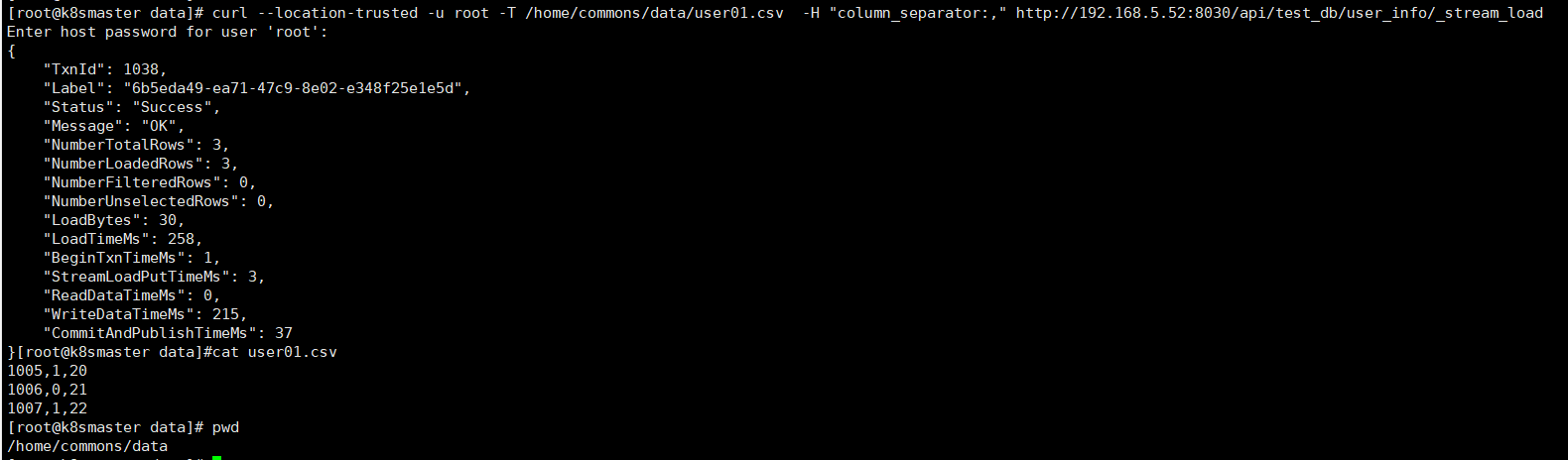
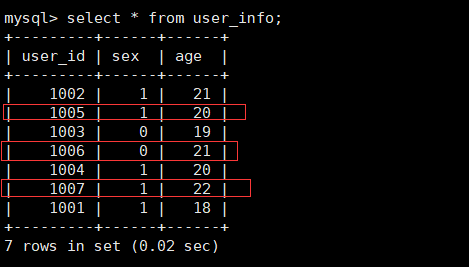
准备数据插入前面已创建好的user_info表
curl --location-trusted -u root -T /home/commons/data/user01.csv -H "column_separator:," http://192.168.5.52:8030/api/test_db/user_info/_stream_load
# 也可以通过-H "label:labelname"设置标签名称
- StarRocks支持从Apache HDFS、Amazon S3等外部存储系统导入数据,支持CSV、ORCFile、Parquet等文件格式。数据量在几十GB到上百GB 级别。
- 在Broker Load模式下,通过部署的Broker程序,StarRocks可读取对应数据源(如HDFS, S3)上的数据,利用自身的计算资源对数据进行预处理和导入。这是一种异步的导入方式,用户需要通过MySQL协议创建导入,并通过查看导入命令检查导入结果。
首先需要先部署好Broker,如果有特殊的 hdfs 配置,复制线上的 hdfs-site.xml 到 Broker的conf 目录下,将hdfs-site.xml分发到三台Broker节点的conf 目录, 重新启动Broker,这样就完成了前置环境条件
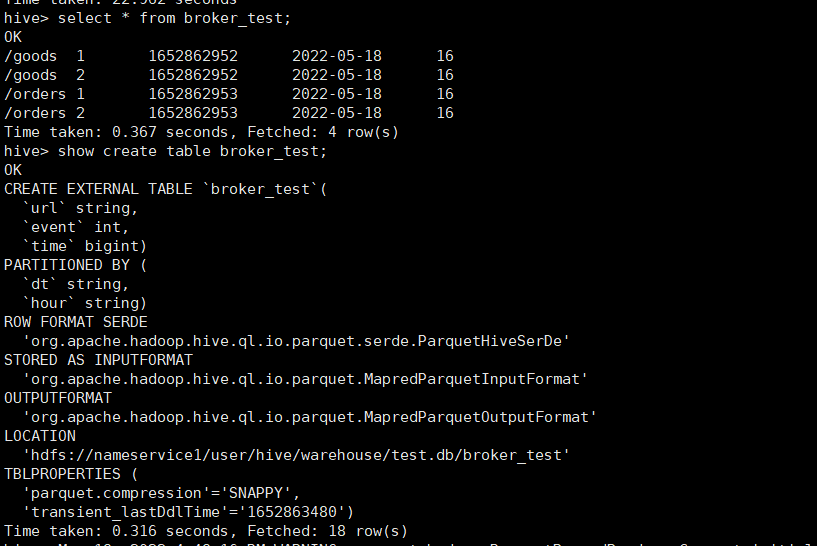
在HIve中创建broker_test,并且导入数据
CREATE EXTERNAL TABLE broker_test(
`url` string,
`event` int,
`time` bigint)
PARTITIONED by (
`dt` string,
`hour` string)
ROW FORMAT DELIMITED
STORED AS PARQUET
TBLPROPERTIES('parquet.compression'='SNAPPY');
insert into broker_test PARTITION(dt='2022-05-18',hour='16')
values ('/goods',1,1652862952),
('/goods',2,1652862952),
('/orders',1,1652862953),
('/orders',2,1652862953);
执行查看结果,hive表已有数据
在StarRocks中test_db数据库中也创建表broker_test
CREATE TABLE IF NOT EXISTS broker_test (
url DATETIME ,
event INT ,
time BIGINT,
dt varchar(20),
hour varchar(20)
)
DUPLICATE KEY(url)
DISTRIBUTED BY HASH(url) BUCKETS 8;
StarRocks中test_db数据库也创建broker_test_label1
LOAD LABEL broker_test_label1
(
DATA INFILE("hdfs://nameservice1/user/hive/warehouse/test.db/broker_test/dt=2022-05-18/hour=16/*")
INTO TABLE broker_test
FORMAT AS "parquet"
(url,EVENT,TIME)
SET
(
url=url,
EVENT=EVENT,
TIME=TIME,
dt='2022-05-18',
HOUR='16'
)
)
WITH BROKER 'broker1'
PROPERTIES
(
"timeout" = "3600"
);
Broker Load导入是异步的,用户可以在SHOW LOAD命令中指定Label来查询对应导入作业的执行状态,查询结果Job已经完成
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-1sfUd01g-1652972070699)(http://www.itxiaoshen.com:3001/assets/1652866964727KZ3cc7Bz.png)]
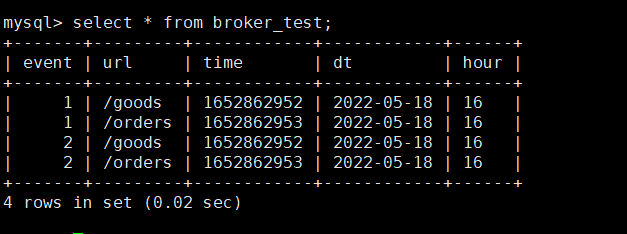
查看StarRocks的test_db数据库的broker_test,4条数据已经完整导入了
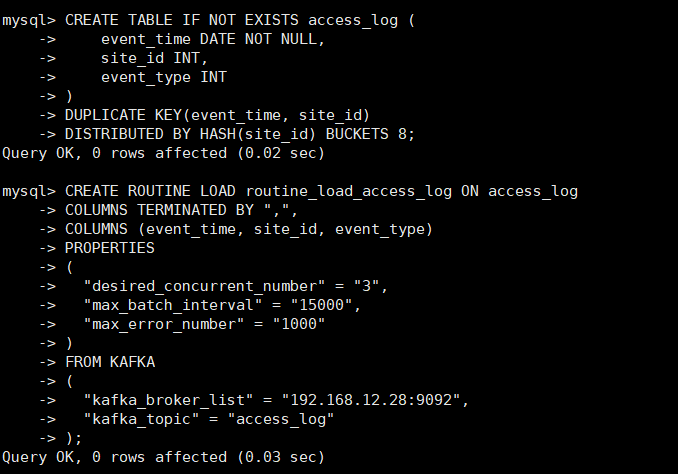
从一个本地 Kafka 集群导入 CSV 数据,创建ROUTINE LOAD的任务
CREATE TABLE IF NOT EXISTS site_test (
site_id INT,
event_type INT
)
DUPLICATE KEY(site_id)
DISTRIBUTED BY HASH(site_id) BUCKETS 8;
CREATE ROUTINE LOAD routine_load_site_test ON site_test
COLUMNS TERMINATED BY ",",
COLUMNS (site_id, event_type)
PROPERTIES
(
"desired_concurrent_number" = "3",
"max_batch_interval" = "5000",
"max_error_number" = "1000"
)
FROM KAFKA
(
"kafka_broker_list" = "192.168.12.27:9092,192.168.12.28:9092,192.168.12.29:9092",
"kafka_topic" = "site_test",
"property.kafka_default_offsets" = "OFFSET_BEGINNING"
);
使用kafka生产者或者程序往site_test的Topic发送数据,也支持Json格式,配置属性增加json配置。
CREATE ROUTINE LOAD routine_load_site_test ON site_test
COLUMNS TERMINATED BY ",",
COLUMNS (site_id, event_type)
PROPERTIES (
"format"="json",
"json_root"="$.data",
"desired_concurrent_number"="1",
"strip_outer_array" ="true",
"max_error_number"="1000"
)
FROM KAFKA (
"kafka_broker_list"= "192.168.12.27:9092,192.168.12.28:9092,192.168.12.29:9092",
"kafka_topic" = "site_test"
);
StarRocks 提供 flink-connector-starrocks,导入数据至 StarRocks,相比于 Flink 官方提供的 flink-connector-jdbc,导入性能更佳。 flink-connector-starrocks 的内部实现是通过缓存并批量由 stream load 导入。
Flink DataStream API示例我们使用上一篇创建好的article表来插入测试,创建flink-demo工程,Pom文件引入
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>cn.itxs</groupId>
<artifactId>flink-demo</artifactId>
<version>1.0-SNAPSHOT</version>
<properties>
<maven.compiler.source>8</maven.compiler.source>
<maven.compiler.target>8</maven.compiler.target>
<flink.version>1.14.4</flink.version>
<scala.version>2.12</scala.version>
</properties>
<dependencies>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-java</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-streaming-java_${scala.version}</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-clients_${scala.version}</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>com.starrocks</groupId>
<artifactId>flink-connector-starrocks</artifactId>
<version>1.2.1_flink-1.14_2.12</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-jdbc_${scala.version}</artifactId>
<version>${flink.version}</version>
<scope>provided</scope>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-table-common</artifactId>
<version>${flink.version}</version>
<scope>provided</scope>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-table-api-java</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-table-api-java-bridge_${scala.version}</artifactId>
<version>${flink.version}</version>
<scope>provided</scope>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-table-planner-blink_${scala.version}</artifactId>
<version>1.13.6</version>
<scope>test</scope>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-table-planner_${scala.version}</artifactId>
<version>${flink.version}</version>
<scope>provided</scope>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-table</artifactId>
<version>${flink.version}</version>
<type>pom</type>
<scope>provided</scope>
</dependency>
<dependency>
<groupId>com.google.code.gson</groupId>
<artifactId>gson</artifactId>
<version>2.9.0</version>
</dependency>
<dependency>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-api</artifactId>
<version>1.7.25</version>
</dependency>
<dependency>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-log4j12</artifactId>
<version>1.7.25</version>
</dependency>
<dependency>
<groupId>org.apache.logging.log4j</groupId>
<artifactId>log4j-to-slf4j</artifactId>
<version>2.14.0</version>
</dependency>
</dependencies>
</project>
创建DataStream API示例StarRocksDataStreamDemo.java
package starrocks;
import com.google.gson.Gson;
import com.starrocks.connector.flink.StarRocksSink;
import com.starrocks.connector.flink.table.sink.StarRocksSinkOptions;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import java.util.Arrays;
public class StarRocksDataStreamDemo {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
StarRocksDataStreamDemo starRocksDataStreamDemo = new StarRocksDataStreamDemo();
starRocksDataStreamDemo.useStream(env);
env.execute();
}
public void useStream(StreamExecutionEnvironment env){
Gson gson = new Gson();
DataStreamSource<String> ds = env.fromCollection(Arrays.asList(gson.toJson(new Article(1, 1, 1, "flink")),
gson.toJson(new Article(2, 2, 2, "java")),
gson.toJson(new Article(3, 3, 3, "starrocks"))));
ds.addSink(
StarRocksSink.sink(
// the sink options
StarRocksSinkOptions.builder()
.withProperty("jdbc-url", "jdbc:mysql://192.168.5.52:9030")
.withProperty("load-url", "192.168.5.52:8030")
.withProperty("username", "root")
.withProperty("password", "")
.withProperty("table-name", "article")
.withProperty("database-name", "test_db")
.withProperty("sink.properties.format", "json")
.withProperty("sink.properties.strip_outer_array", "true")
.build()
)
);
}
}
本地运行main方法前在启动配置中勾上Include dependencies with "Provided" scope
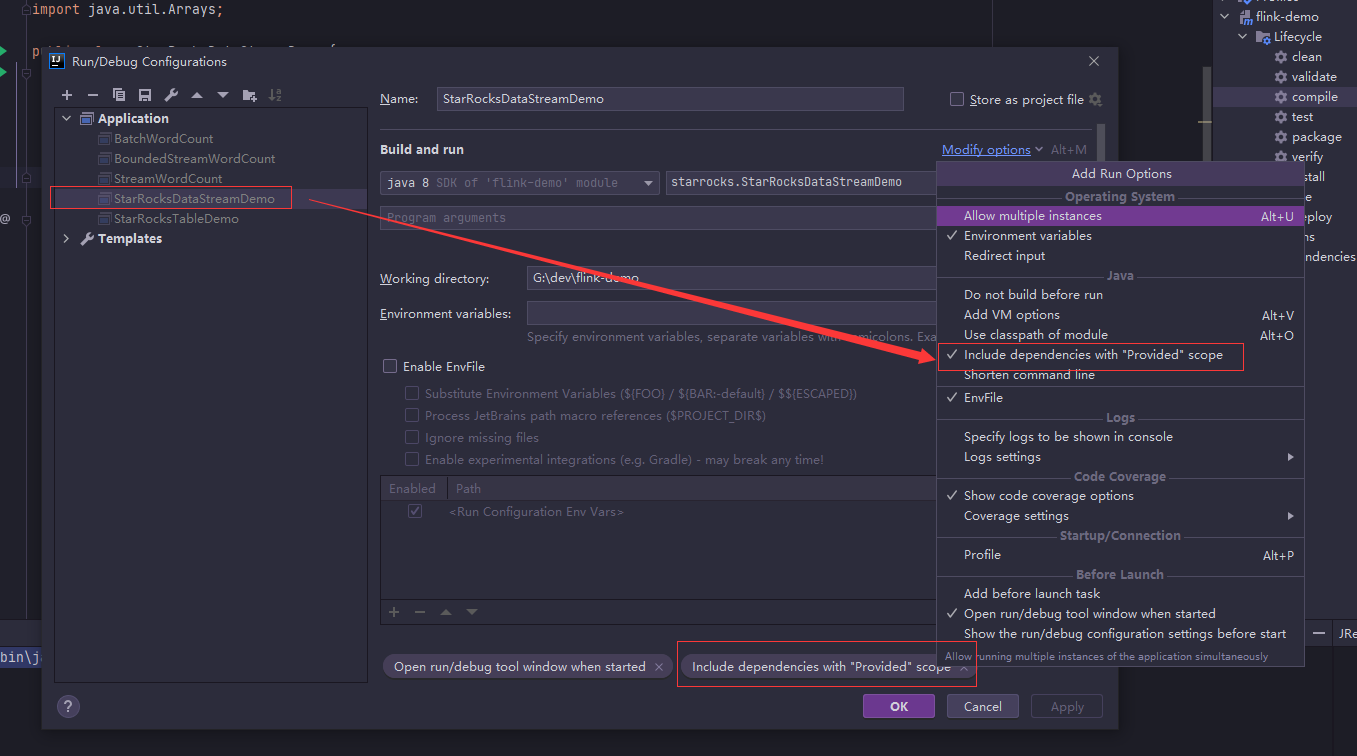
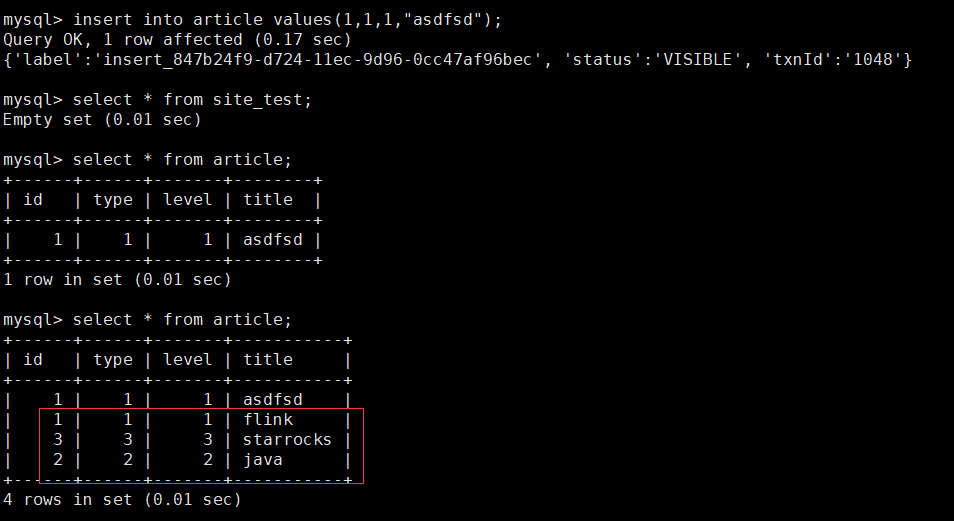
查看三条数据已成功导入article表里
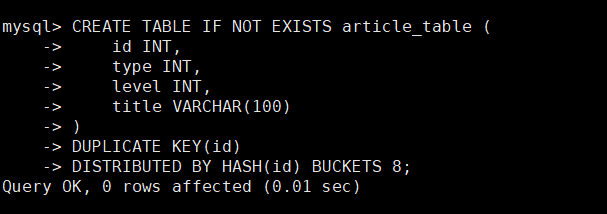
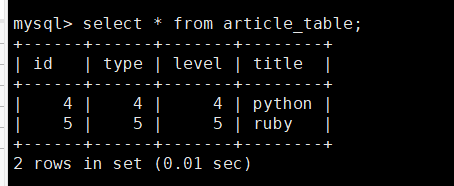
StarRocks中先创建表article_table
CREATE TABLE IF NOT EXISTS article_table (
id INT,
type INT,
level INT,
title VARCHAR(100)
)
DUPLICATE KEY(id)
DISTRIBUTED BY HASH(id) BUCKETS 8;
创建Article pojo类
package starrocks;
public class Article {
private int id;
private int type;
private int level;
private String title;
public Article(int id, int type, int level, String title) {
this.id = id;
this.type = type;
this.level = level;
this.title = title;
}
}
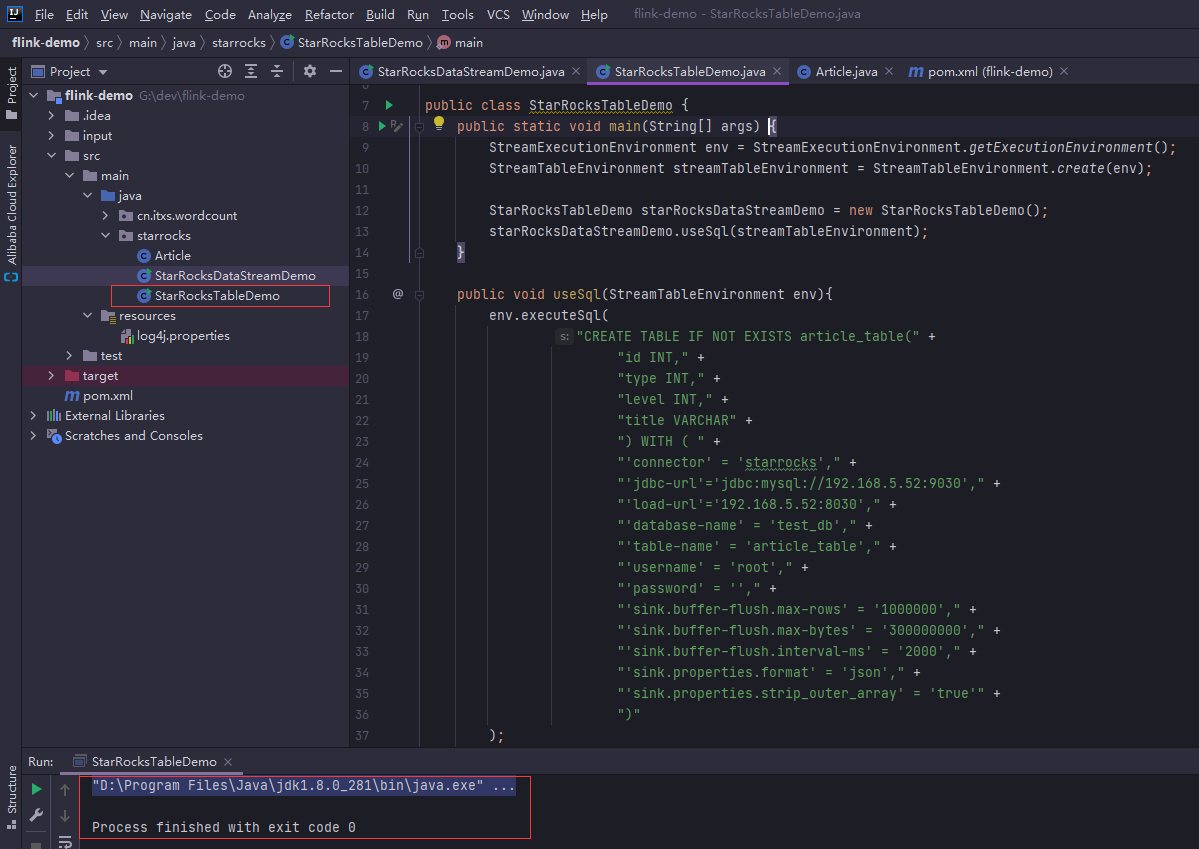
创建StarRocksTableDemo.java
package starrocks;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.table.api.bridge.java.StreamStatementSet;
import org.apache.flink.table.api.bridge.java.StreamTableEnvironment;
public class StarRocksTableDemo {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
StreamTableEnvironment streamTableEnvironment = StreamTableEnvironment.create(env);
StarRocksTableDemo starRocksDataStreamDemo = new StarRocksTableDemo();
starRocksDataStreamDemo.useSql(streamTableEnvironment);
}
public void useSql(StreamTableEnvironment env){
env.executeSql(
"CREATE TABLE IF NOT EXISTS article_table(" +
"id INT," +
"type INT," +
"level INT," +
"title VARCHAR" +
") WITH ( " +
"'connector' = 'starrocks'," +
"'jdbc-url'='jdbc:mysql://192.168.5.52:9030'," +
"'load-url'='192.168.5.52:8030'," +
"'database-name' = 'test_db'," +
"'table-name' = 'article_table'," +
"'username' = 'root'," +
"'password' = ''," +
"'sink.buffer-flush.max-rows' = '1000000'," +
"'sink.buffer-flush.max-bytes' = '300000000'," +
"'sink.buffer-flush.interval-ms' = '2000'," +
"'sink.properties.format' = 'json'," +
"'sink.properties.strip_outer_array' = 'true'" +
")"
);
StreamStatementSet statementSet = env.createStatementSet();
statementSet.addInsertSql("insert into article_table values(4,4,4,'python'),"+
"(5,5,5,'ruby')");
statementSet.execute();
}
}
记得和前面一样设置启动配置勾选然后本地运行main,正常执行完毕
查看StarRocks的article_table表数据,数据已成功插入表中
数组,作为数据库的一种扩展类型,在 PG、ClickHouse、Snowflake 等系统中都有相关特性支持,可以广泛的应用于 A/B Test 对比、用户标签分析、人群画像等场景。StarRocks 当前支持了 多维数组嵌套、数组切片、比较、过滤等特性。
数组列的定义形式为 ARRAY,其中 TYPE 是数组元素类型,默认 nullable,暂时不支持指定元素类型为 NOT NULL,但是也可以定义数组本身为 NOT NULL。数组类型有以下限制:
- 只能在 duplicate table 中定义数组列(2.1版本开始支持 Primary key 和 Unique key 中使用数组类型)
- 数组列不能作为 key 列(以后可能支持)
- 数组列不能作为 distribution 列
- 数组列不能作为 partition 列
-- 一维数组
create table array_test(
f0 INT,
f1 ARRAY<INT>
)
duplicate key(f0)
distributed by hash(f0) buckets 3; -- 以分3个桶为例。
-- 定义嵌套数组
create table nest_array_test(
f0 INT,
f1 ARRAY<ARRAY<VARCHAR(10)>>
)
duplicate key(f0)
distributed by hash(f0) buckets 3;
使用SELECT语句构造数组
- 可以在 SQL 中通过中括号( "[" 和 "]" )来构造数组常量,每个数组元素通过逗号(",")分割。如select [1, 2, 3] as numbers;
- 当数组元素具有不同类型时,StarRocks 会自动推导出合适的类型(supertype) select [12, "100"]; -- 结果是 ["12", "100"]
- 可以使用尖括号(
<>)显示声明数组类型.select ARRAY["12", "100"]; -- 结果是 [12, 100] - 元素中可以包含NULL。select [1, NULL];
# 插入一维数组类型数据和访问数组数据
INSERT INTO array_test VALUES(1, [1,2,3]);
select f1[3] from array_test;
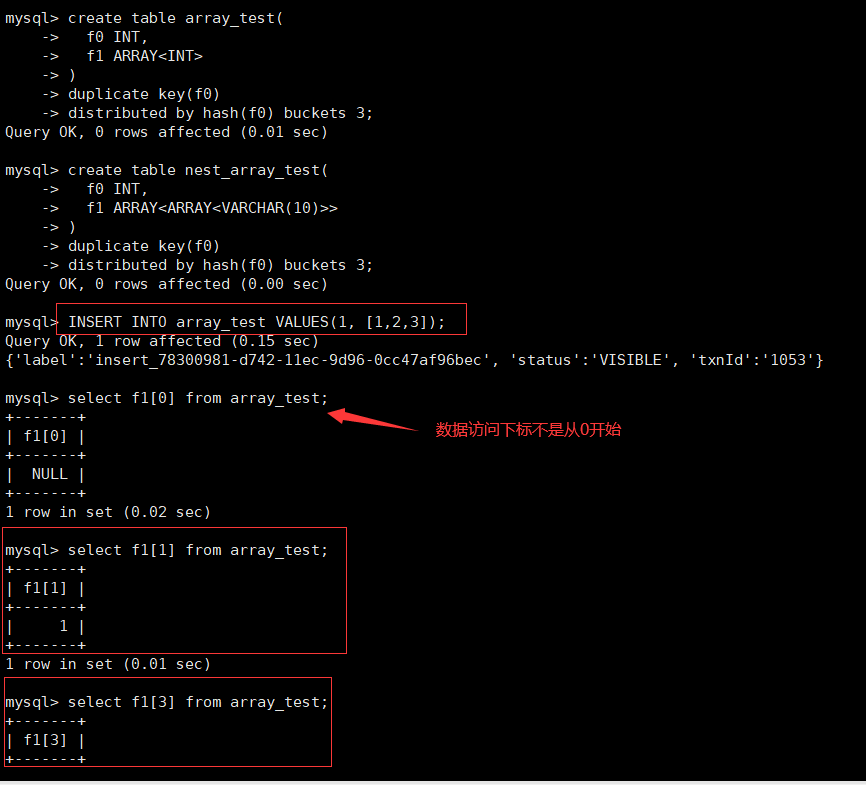
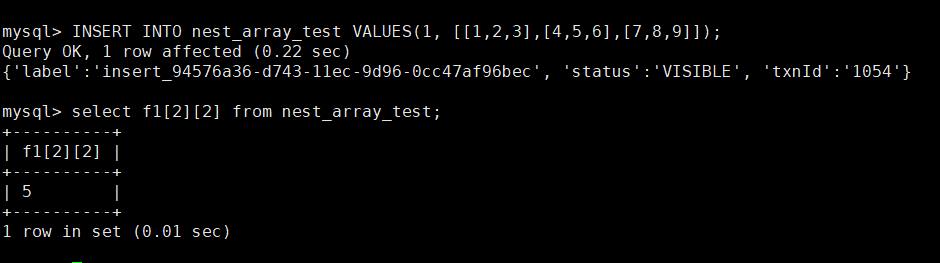
# 插入嵌套数组数组类型数据和访问数组数据
INSERT INTO nest_array_test VALUES(1, [[1,2,3],[4,5,6],[7,8,9]]);
select f1[2][2] from nest_array_test;
Colocate Join 功能,属于分布式系统实现 Join 数据分布的策略之一。 能够减少数据分布在多个节点引起的 Join 时的数据移动和网络传输,从而提高查询性能。 Colocate Join 使用 Colocation Group(CG)管理一组表 ,同一 CG 内的表 Colocation Group Schema(CGS)相同,即表对应的分桶副本具有一致的分桶键、副本数量和副本放置方式 。这样可以保证同一 CG 内,表的数据分布在相同一组 BE 节点上。当 Join 列为分桶键时,计算节点只需做本地 Join,因而可以减少数据在节点间的传输耗时,提高查询性能。 因此,Colocation Join,相对于其他 Join,例如 Shuffle Join 和 Broadcast Join,可以避免数据网络传输开销,提高查询性能。
- Colocation Group(CG):一个 CG 中会包含一张及以上的 Table。一个CG内的 Table 有相同的分桶方式和副本放置方式,使用 Colocation Group Schema 描述。
- Colocation Group Schema(CGS): 包含 CG 的分桶键,分桶数以及副本数等信息。
- 创建 Colocation 表
建表时,可以在 PROPERTIES 中指定属性 "colocate_with" = "group_name",表示这个表是一个 Colocate Join 表,并且归属于一个指定的 Colocation Group
CREATE TABLE tbl (k1 int, v1 int sum)
DISTRIBUTED BY HASH(k1)
BUCKETS 8
PROPERTIES(
"colocate_with" = "group1"
);
为了使得 Table 能够有相同的数据分布,同一 CG 内的 Table 必须保证下列约束:
- 同一 CG 内的 Table 的分桶键的类型、数量和顺序完全一致,并且桶数一致,这样才能保证多张表的数据分片能够一一对应地进行分布控制。分桶键,即在建表语句中
DISTRIBUTED BY HASH(col1, col2, ...)中指定一组列。分桶键决定了一张表的数据通过哪些列的值进行 Hash 划分到不同的 Bucket Seq 中。同 CG 的 table 的分桶键的名字可以不相同,分桶列的定义在建表语句中的出现次序可以不一致,但是在DISTRIBUTED BY HASH(col1, col2, ...)的对应数据类型的顺序要完全一致。 - 同一个 CG 内所有表的所有分区(Partition)的副本数必须一致。如果不一致,可能出现某一个 Tablet 的某一个副本,在同一个 BE 上没有其他的表分片的副本对应。
- 同一个 CG 内所有表的分区键,分区数量可以不同。
同一个CG中的所有表的副本放置满足:
- CG中所有 Table 的 Bucket Seq 和 BE 节点的映射关系和 Parent Table 一致。
- Parent Table 中所有 Partition 的 Bucket Seq 和 BE 节点的映射关系和第一个 Partition 一致。
- Parent Table 第一个 Partition 的 Bucket Seq 和 BE 节点的映射关系利用原生的 Round Robin 算法决定。
CG内表的一致的数据分布定义和子表副本映射,能够保证分桶键取值相同的数据行一定在相同BE上,因此当分桶键做join列时,只需本地join即可。
- 删除 Colocation 表:当 Group 中最后一张表彻底删除后(彻底删除是指从回收站中删除。通常,一张表通过
DROP TABLE命令删除后,会在回收站默认停留一天的时间后,再删除),该 Group 也会被自动删除。
简单示例我们创建相同结构的两张表ctbl1和ctbl2
CREATE TABLE `ctbl1` (
`f1` date NOT NULL COMMENT "",
`f2` int(11) NOT NULL COMMENT "",
`f3` int(11) SUM NOT NULL COMMENT ""
) ENGINE=OLAP
AGGREGATE KEY(`f1`, `f2`)
DISTRIBUTED BY HASH(`f2`) BUCKETS 8
PROPERTIES (
"colocate_with" = "group1"
);
CREATE TABLE `ctbl2` (
`f1` date NOT NULL COMMENT "",
`f2` int(11) NOT NULL COMMENT "",
`f3` int(11) SUM NOT NULL COMMENT ""
) ENGINE=OLAP
AGGREGATE KEY(`f1`, `f2`)
DISTRIBUTED BY HASH(`f2`) BUCKETS 8
PROPERTIES (
"colocate_with" = "group1"
);

EXPLAIN SELECT * FROM ctbl1 INNER JOIN ctbl2 ON (ctbl1.f2 = ctbl2.f2);
执行查询查看分析计划,Colocation Join 生效 Hash Join 节点会显示 colocate: true。
StarRocks 支持以外部表的形式,接入其他数据源。外部表指的是保存在其他数据源中的数据表,而 StartRocks 只保存表对应的元数据,并直接向外部表所在数据源发起查询。目前 StarRocks 已支持的第三方数据源包括 MySQL、ElasticSearch、Hive、StarRocks、Apache Iceberg 和 Apache Hudi。对于 StarRocks 数据源,现阶段只支持 Insert 写入,不支持读取,对于其他数据源,现阶段只支持读取,还不支持写入。
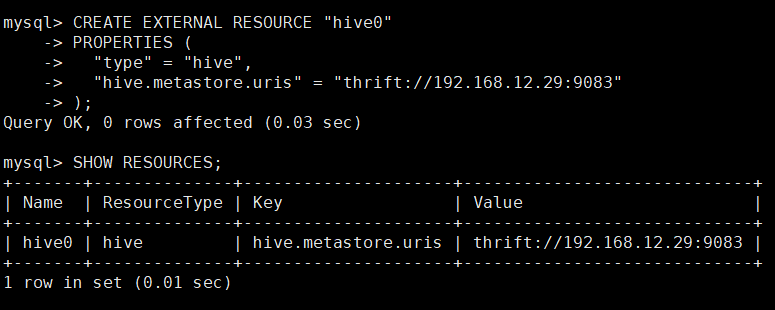
CREATE EXTERNAL RESOURCE "hive0"
PROPERTIES (
"type" = "hive",
"hive.metastore.uris" = "thrift://192.168.12.29:9083"
);
-- 查看 StarRocks 中创建的资源
SHOW RESOURCES;
-- 删除名为 hive0 的资源
DROP RESOURCE "hive0";
执行hive表的创建和插入一条测试数据
CREATE TABLE external_test(
`url` string,
`event` int,
`time` bigint)
ROW FORMAT DELIMITED
STORED AS PARQUET
TBLPROPERTIES('parquet.compression'='SNAPPY');
insert into external_test values('/user',1,1652862952);
执行结果如下
StarRocks中创建hive的外部表external_test
-- 例子:创建 hive0 资源对应的 Hive 集群中 test 数据库下的 broker_test 表的外表
CREATE EXTERNAL TABLE `external_test` (
`url` varchar(200),
`event` int,
`time` bigint
) ENGINE=HIVE
PROPERTIES (
"resource" = "hive0",
"database" = "test",
"table" = "external_test"
);
# 查询外表数据
select count(*) from external_test;
其他还有很多种外部表,MySQL 外部表、ElasticSearch 外部表、StarRocks 外部表、Apache Iceberg 外表、Apache Hudi 外表,后续有时间再补充
**本人博客网站 **IT小神 www.itxiaoshen.com