这节课是巡安似海PyHacker编写指南的《打造网站Cms识别工具》喜欢用Python写脚本的小伙伴可以跟着一起写一写呀。编写环境:Python2.x 这节课是巡安似海PyHacker编写指南的《 打造网站Cms识
 这节课是巡安似海PyHacker编写指南的《打造网站Cms识别工具》喜欢用Python写脚本的小伙伴可以跟着一起写一写呀。编写环境:Python2.x
这节课是巡安似海PyHacker编写指南的《打造网站Cms识别工具》喜欢用Python写脚本的小伙伴可以跟着一起写一写呀。编写环境:Python2.x
这节课是巡安似海PyHacker编写指南的《打造网站Cms识别工具》
喜欢用Python写脚本的小伙伴可以跟着一起写一写呀。
编写环境:Python2.x
00x1:
需要用到的模块如下:
import hashlib import requests
00x2:
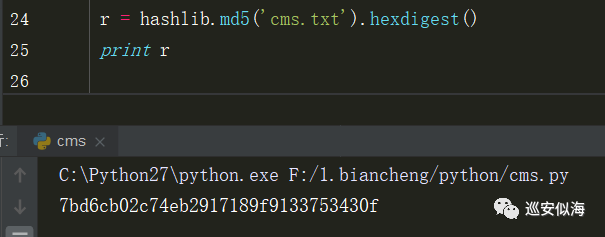
首先利用hashlib.md5().hexdigest()进行获取md5
r = hashlib.md5('cms.txt').hexdigest()
print r
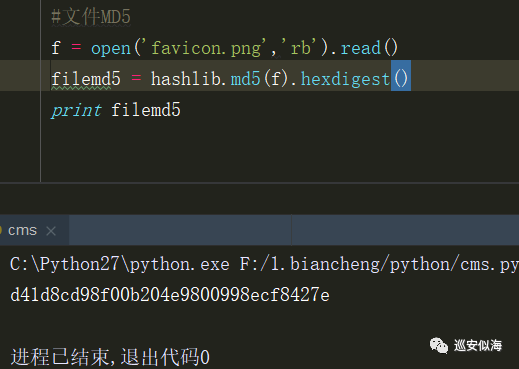
获取文件md5:
f = open('favicon.png','rb').read()
filemd5 = hashlib.md5(f).hexdigest()
print filemd5
00x3:
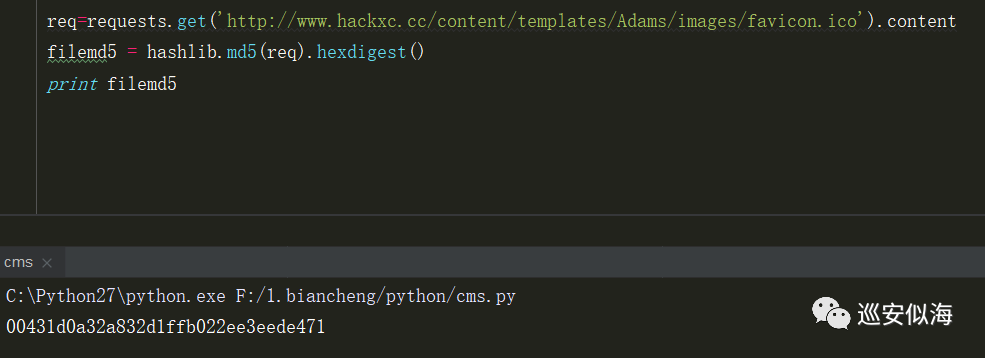
获取网站文件的md5:
req=requests.get('http://www.hackxc.cc/content/templates/Adams/images/favicon.ico').content
filemd5 = hashlib.md5(req).hexdigest()
print filemd5
00x4:
下面开始整理一下cms.txt
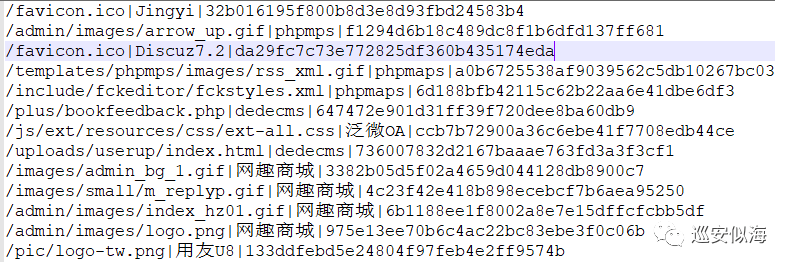
Cms字典处理:
data=[]
def cmslist():
file = open("cms.txt")
for line in file:
str = line.strip().split("|")
ls_data={}
if len(str)==3:#判断是否为正确cms格式
ls_data['url']=str[0]
ls_data['name'] = str[1]
ls_data['md5'] = str[2]
data.append(ls_data)
file.close( )
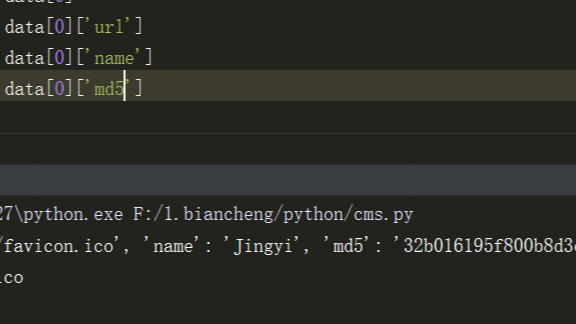
因为本身是一个字典形式的列表
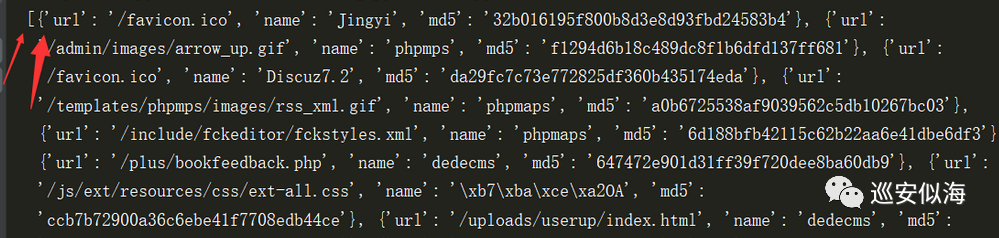
看下面这个图大家就懂了
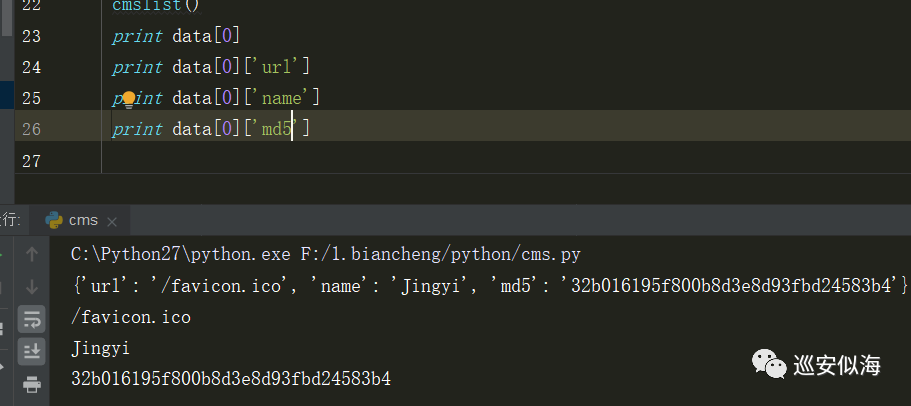
00x5:
接着进行遍历cms列表
def cms():
for cms in data:
try:
req = requests.get('http://127.0.0.1%s'%cms['url'])
print req.url
except:
pass
if req.status_code == 200:
filemd5 = hashlib.md5(req.content).hexdigest()
if filemd5 == cms['md5']:
print cms['name']
break
简单调试:执行成功自动跳出循环
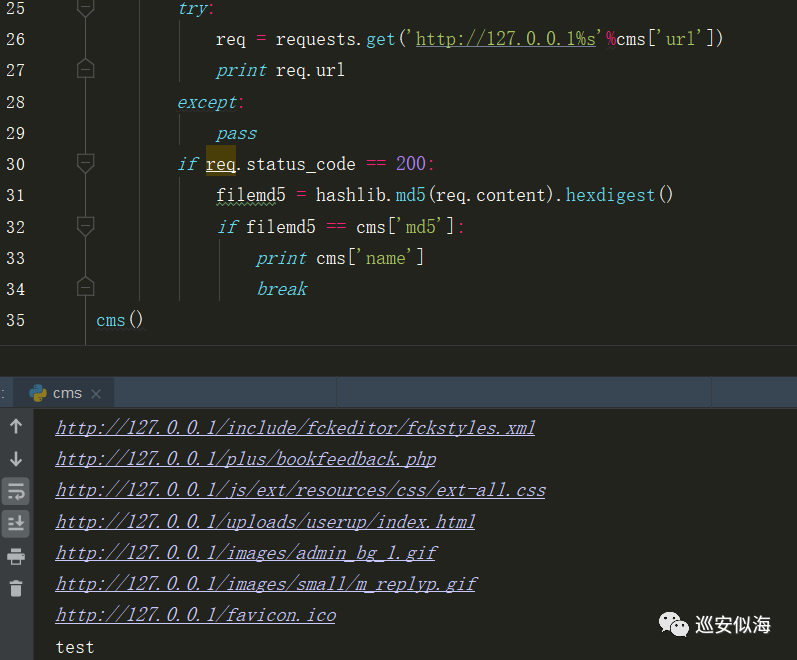
00x6:
完整代码:
#!/usr/bin/python
#-*- coding:utf-8 -*-
import requests
import hashlib
data=[]
def cmslist():
file = open(r"cms.txt")
for line in file:
str = line.strip().split("|")
ls_data={}
if len(str)==3:#判断是否为正确cms格式
ls_data['url']=str[0]
ls_data['name'] = str[1]
ls_data['md5'] = str[2]
data.append(ls_data)
file.close( )
def cms(url):
headers = {'User-Agent':'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/65.0.3314.0 Safari/537.36 SE 2.X MetaSr 1.0'}
for cms in data:
urlx = url+cms['url']
try:
req = requests.get(urlx,headers=headers,timeout=2)
print urlx
except:
pass
try:
if req.status_code == 200:
filemd5 = hashlib.md5(req.content).hexdigest()
if filemd5 == cms['md5']:
print '\n[*]cms:',cms['name']
break
except:
pass
def main():
cmslist()
url =raw_input("\nurl:")
if url == "":
sys.exit(1)
print ""
if 'http' not in url:
url = 'http://'+url
cms(url)
if __name__ == '__main__':
main()
00x7:
如果想对文件内多个url进行cms检测
def main():
cmslist()
f = open('url.txt','r')
for url in f:
url = url.strip()
if 'http' not in url:
url = 'http://'+url
cms(url)
喜欢的关注一下叭~
