初学爬虫,学习一下三方库的使用以及简单静态网页的分析。就跟着视频写了一个爬取豆瓣Top250排行榜的爬虫。 网页分析 我个人感觉写爬虫最重要的就是分析网页,找到网页的规律,
初学爬虫,学习一下三方库的使用以及简单静态网页的分析。就跟着视频写了一个爬取豆瓣Top250排行榜的爬虫。
网页分析我个人感觉写爬虫最重要的就是分析网页,找到网页的规律,找到自己需要内容所在的地方,细化到他在哪个div里面,在哪个class里面,在哪个a标签里面。

从上面的图中可以看出,有很多信息。包括电影名、英文名、简介、评价、评价人数、相关信息
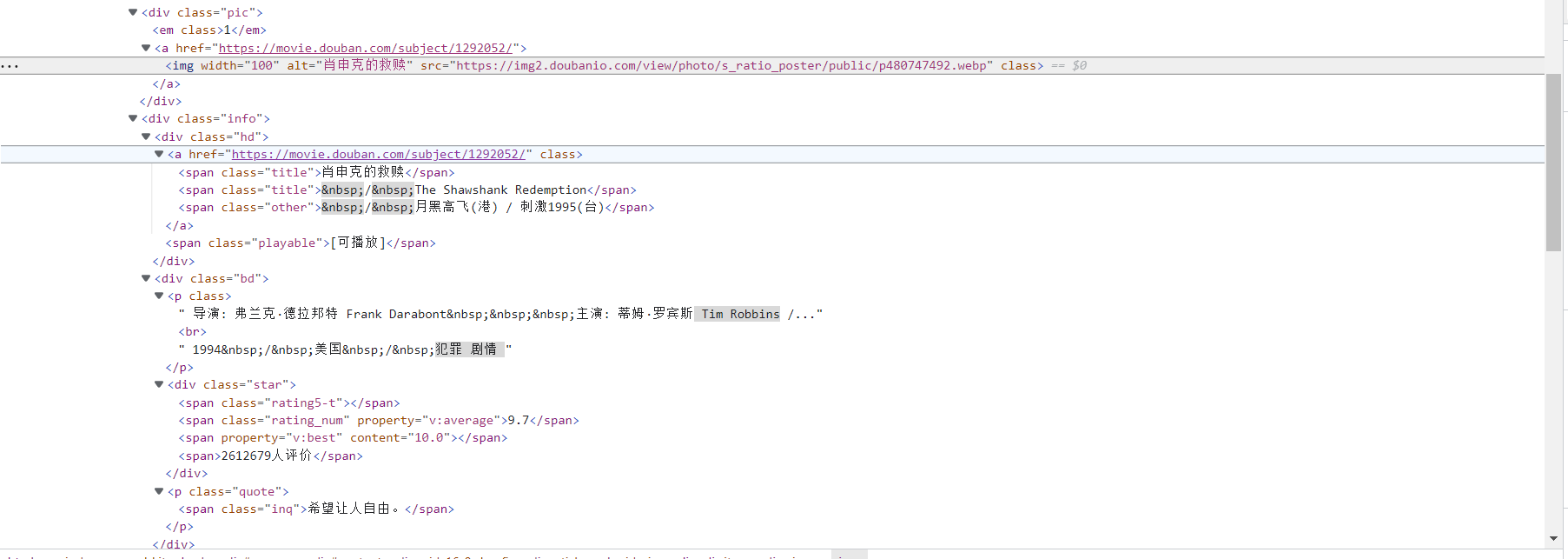
当我们打开控制台,可以看到电影的链接、图片的链接。
可以看到电影名在一个span里面、概况在一个p标签里面、评价在一个div里面的一个span中等等。
找到我们需要信息的位置,其实每一个电影项的信息都是在相同的标签里面,每一页都25个项,一共有10页,每一页的链接后缀https://movie.douban.com/top250?start=25只需要更改start后面的数字,我们可以用一个循环来解决爬取多页。
爬取流程 一、引入第三方库
我们需要访问目的网址,进行正则分析,操作excel、保存到数据库等等都需要用到三方库。
from bs4 import BeautifulSoup #网页解析
import re #正则表表达式文字匹配
import urllib.request,urllib.error #指定url,获取网页数据
import xlwt #进行excel操作
import sqlite3 #进行SQLite数据库操作
import pymysql.cursors #连接mysql数据库
二、访问目标网址
我们通过request库进行访问目标网页,并返回网页的全部源代码以字符串的形式保存。
访问的时候我们需要查看网页是通过什么方式返回的请求。
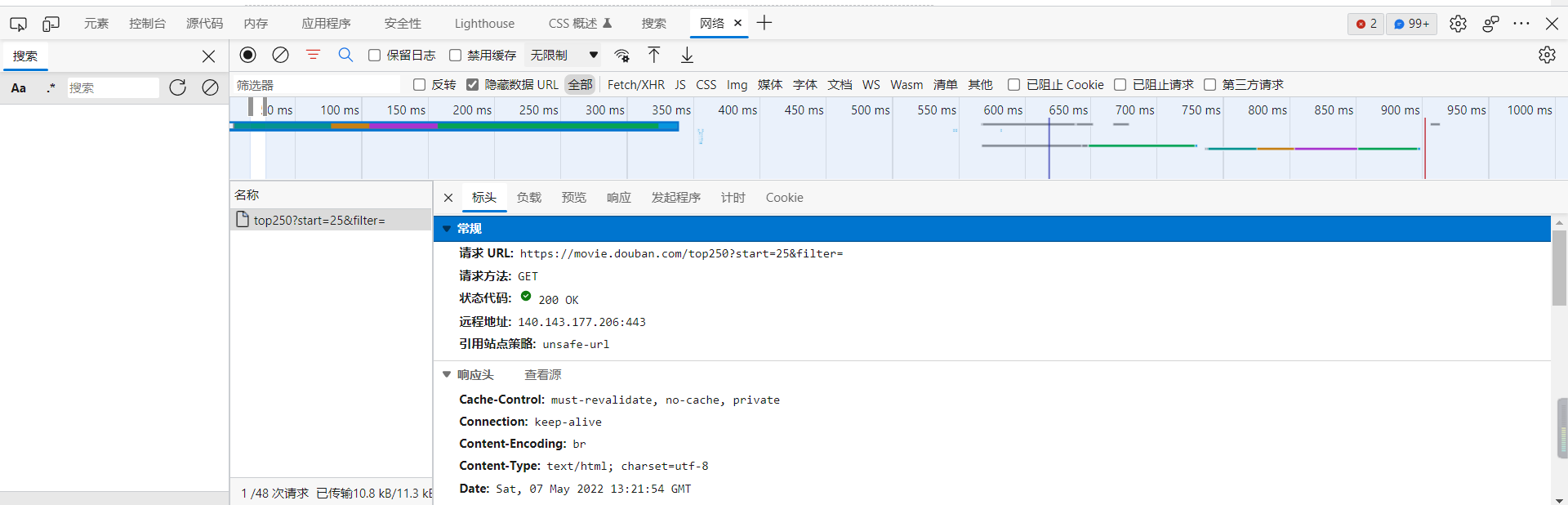
我们发现是get请求,只要url和请求头就可以。如果是post请求,需要封装data数据。
def askURL(url):
head = { #伪装请求头,模拟浏览器访问
"User-Agent":" Mozilla / 5.0(Linux;Android6.0;Nexus5 Build / MRA58N) AppleWebKit / 537.36(KHTML, likeGecko) Chrome / 99.0.4844.51Mobile Safari / 537.36"
}
request = urllib.request.Request(url,headers=head)
html = ""
try:
response = urllib.request.urlopen(request)
html = response.read().decode('utf-8')
#print(html)
except urllib.error.URLError as e:
if hasattr(e,"code"):
print(e.code)
if hasattr(e,"reason"):
print(e.reason)
return html #返回爬到所有的html数据
三、正则匹配数据
我们获取到全部网页源代码后还需要匹配到我们自己需要的数据,在标签中把数据提取出来。
正则表达式:
findlink = re.compile(r'a href="(.*?)">') #电影链接
findImageSrc = re.compile(r'<img.*src="(.*?)"',re.S) #re.S让换行符包含着其中 #图片链接
findTitle = re.compile(r'<span class="title">(.*)</span>') #标题
findRating = re.compile(r'<span class="rating_num" property="v:average">(.*)</span>') #评分
findJudge = re.compile(r'<span>(\d*)人评价</span>') #人数
findInq = re.compile(r'<span class="inq">(.*)</span>') #概况
findBd = re.compile(r'<p class="">(.*?)</p>',re.S) #相关信息
提取匹配数据并保存到列表中。
def getdata(baseurl):
datalist = [] #2 解析数据
for i in range(0,10):
url = baseurl + str(i*25)
html = askURL(url)
soup = BeautifulSoup(html,"html.parser")
for item in soup.find_all('div',class_="item"):
#print(item)
data = []
item = str(item)
link = re.findall(findlink,item)[0]
data.append(link)
image = re.findall(findImageSrc,item)[0]
data.append(image)
title = re.findall(findTitle,item)
if(len(title )==2):
ctitle = title[0]
data.append(ctitle)
otitle = title[1].replace("/","")
data.append(otitle.strip())
else:
data.append(title[0])
data.append(" ")
rating = re.findall(findRating,item)[0] #添加评分
data.append(rating)
judgeNum = re.findall(findJudge,item)[0] #添加评价人数
data.append(judgeNum)
inq = re.findall(findInq,item)
if len(inq) != 0:
inq = inq[0].replace("。","")
data.append(inq)
else:
data.append("")
bd = re.findall(findBd,item)[0]
bd = re.sub('<br(\s+)?/>(\s+)?'," ",bd)
bd = re.sub('/'," ",bd)
bd = re.sub('\xa0', " ", bd)
bd = re.sub('\n', " ", bd)
data.append(bd.strip())
datalist.append(data)
print(datalist)
return datalist
四、保存数据到excel中
def saveData(datalist,savepath):
print("save...")
book = xlwt.Workbook(encoding="utf-8",style_compression=0)
sheet = book.add_sheet('豆瓣电影Top250',cell_overwrite_ok=True)
col = ("电影详情链接","图片链接","影片中文名","影片外国名","评分","评价数","概况","相关信息") #创建列
for i in range(0,8):
sheet.write(0,i,col[i])
for i in range(0,250): #保存数据
print("第%d条"%(i+1))
data = datalist[i]
for j in range(0,8):
sheet.write(i+1,j,data[j])
book.save(savepath)
五、保存到MYSQL中(附加,可以不用)
def conn(datalist):
conn = pymysql.connect(host='localhost',user='root',password='1767737316.',database='douban',cursorclass=pymysql.cursors.DictCursor)
cursor = conn.cursor()
for i in range(0,250):
list = datalist[i]
data1 = tuple(list)
sql = 'insert into top250(电影详情链接,图片链接,影片中文名,影片外国名,评分,评价数,概况,相关信息) values(%s,%s,%s,%s,%s,%s,%s,%s)'
# (2)准备数据
# (3)操作
try:
cursor.execute(sql, data1)
conn.commit()
except Exception as e:
print('插入数据失败', e)
conn.rollback() # 回滚
# 关闭游标
# cursor.close()
# 关闭连接
# conn.close()
六、程序入口
if __name__ == "__main__":
main()
print("爬取完毕!")
print("保存到数据库!")
完整源代码
# -*- coding = utf-8 -*-
# @Time : 2022/4/24 16:08
# @Author :王敬博
# @File : spider.py
# @Software: PyCharm
from bs4 import BeautifulSoup #网页解析
import re #正则表表达式文字匹配
import urllib.request,urllib.error #指定url,获取网页数据
import xlwt #进行excel操作
import sqlite3 #进行SQLite数据库操作
import pymysql.cursors
findlink = re.compile(r'a href="(.*?)">') #电影链接
findImageSrc = re.compile(r'<img.*src="(.*?)"',re.S) #re.S让换行符包含着其中 #图片链接
findTitle = re.compile(r'<span class="title">(.*)</span>') #标题
findRating = re.compile(r'<span class="rating_num" property="v:average">(.*)</span>') #评分
findJudge = re.compile(r'<span>(\d*)人评价</span>') #人数
findInq = re.compile(r'<span class="inq">(.*)</span>') #概况
findBd = re.compile(r'<p class="">(.*?)</p>',re.S) #相关信息
def main():
baseurl = "https://movie.douban.com/top250?start="
datalist = getdata(baseurl)
print(datalist)
#1 爬取网页
savepath = ".\\豆瓣电影Top250.xls"
saveData(datalist,savepath)
conn(datalist)
def askURL(url):
head = {
"User-Agent":" Mozilla / 5.0(Linux;Android6.0;Nexus5 Build / MRA58N) AppleWebKit / 537.36(KHTML, likeGecko) Chrome / 99.0.4844.51Mobile Safari / 537.36"
}
request = urllib.request.Request(url,headers=head)
html = ""
try:
response = urllib.request.urlopen(request)
html = response.read().decode('utf-8')
#print(html)
except urllib.error.URLError as e:
if hasattr(e,"code"):
print(e.code)
if hasattr(e,"reason"):
print(e.reason)
return html
#爬取网页
def getdata(baseurl):
datalist = [] #2 解析数据
for i in range(0,10):
url = baseurl + str(i*25)
html = askURL(url)
soup = BeautifulSoup(html,"html.parser")
for item in soup.find_all('div',class_="item"):
#print(item)
data = []
item = str(item)
link = re.findall(findlink,item)[0]
data.append(link)
image = re.findall(findImageSrc,item)[0]
data.append(image)
title = re.findall(findTitle,item)
if(len(title )==2):
ctitle = title[0]
data.append(ctitle)
otitle = title[1].replace("/","")
data.append(otitle.strip())
else:
data.append(title[0])
data.append(" ")
rating = re.findall(findRating,item)[0] #添加评分
data.append(rating)
judgeNum = re.findall(findJudge,item)[0] #添加评价人数
data.append(judgeNum)
inq = re.findall(findInq,item)
if len(inq) != 0:
inq = inq[0].replace("。","")
data.append(inq)
else:
data.append("")
bd = re.findall(findBd,item)[0]
bd = re.sub('<br(\s+)?/>(\s+)?'," ",bd)
bd = re.sub('/'," ",bd)
bd = re.sub('\xa0', " ", bd)
bd = re.sub('\n', " ", bd)
data.append(bd.strip())
datalist.append(data)
print(datalist)
return datalist
#3 保存数据
def saveData(datalist,savepath):
print("save...")
book = xlwt.Workbook(encoding="utf-8",style_compression=0)
sheet = book.add_sheet('豆瓣电影Top250',cell_overwrite_ok=True)
col = ("电影详情链接","图片链接","影片中文名","影片外国名","评分","评价数","概况","相关信息")
for i in range(0,8):
sheet.write(0,i,col[i])
for i in range(0,250):
print("第%d条"%(i+1))
data = datalist[i]
for j in range(0,8):
sheet.write(i+1,j,data[j])
book.save(savepath)
def conn(datalist):
conn = pymysql.connect(host='localhost',user='root',password='1767737316.',database='douban',cursorclass=pymysql.cursors.DictCursor)
cursor = conn.cursor()
for i in range(0,250):
list = datalist[i]
data1 = tuple(list)
sql = 'insert into top250(电影详情链接,图片链接,影片中文名,影片外国名,评分,评价数,概况,相关信息) values(%s,%s,%s,%s,%s,%s,%s,%s)'
# (2)准备数据
# (3)操作
try:
cursor.execute(sql, data1)
conn.commit()
except Exception as e:
print('插入数据失败', e)
conn.rollback() # 回滚
# 关闭游标
# cursor.close()
# 关闭连接
# conn.close()
if __name__ == "__main__":
main()
print("爬取完毕!")
print("保存到数据库!")
效果截图
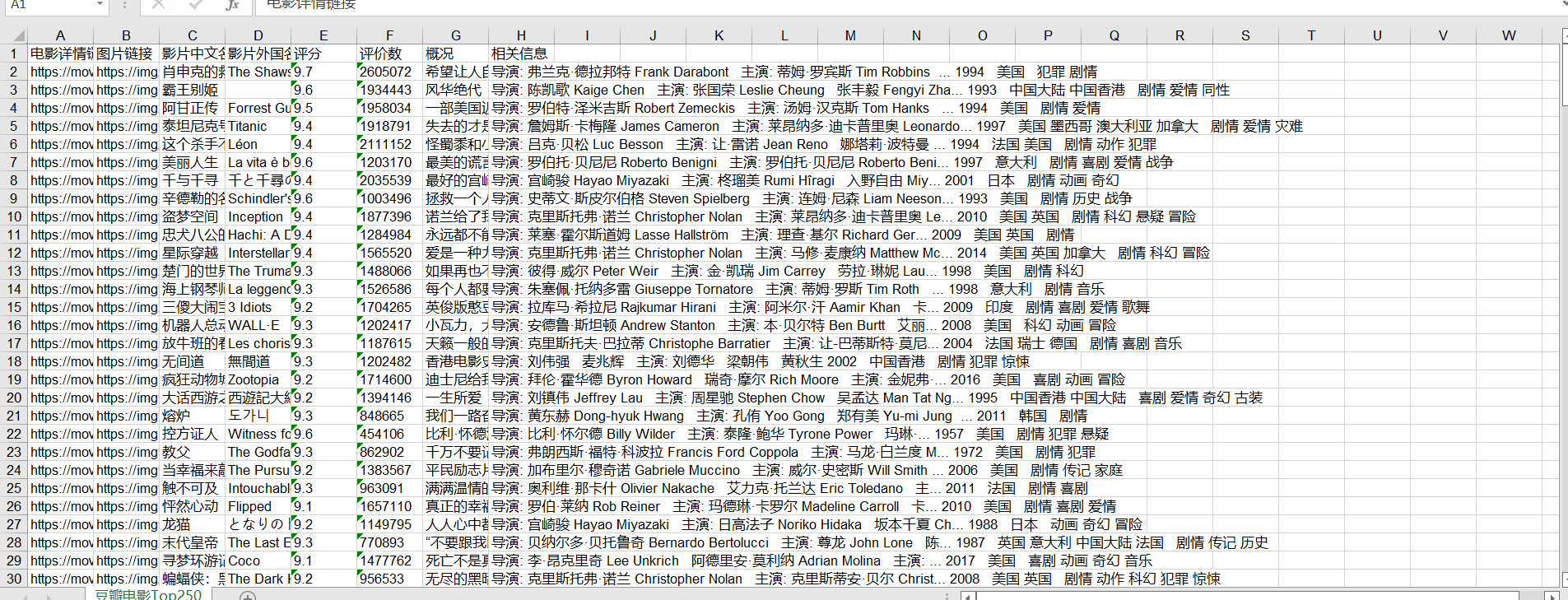
到这里就结束了,如果有问题可以问我,如果觉得对你有帮助的话可以点个赞哦!